本发明涉及氦语音解读技术,更为具体地说涉及一种基于词库学习的饱和潜水氦语音解读方法。
背景技术:
21世纪是海洋经济时代,我们将要从海洋中获取人类所需的50%以上的清洁能源和生产资料。饱和潜水在航海作业、海洋开发、军事海洋、海上救援等领域有着及其重要的应用价值,是海洋经济发展不可或缺的组成部分。
由于深海作业环境和作业内容的特殊性,海洋中的许多工作还不能由载人深海潜水器或水下机器人去完成,需要潜水员直接下水、暴露在深海高压环境下应用饱和潜水技术进行作业。为了满足潜水员在深海高压环境下的生理需求,目前潜水员基本上都采用氦氧混合气体作为潜水员饱和潜水作业时的呼吸气体。当潜水作业深度超过50米时,潜水员的语音通话失真明显;当潜水作业深度超过100米时,潜水员的语音通话开始严重失真,正常的语音变成奇异的“鸭叫”-氦语音,很难听懂潜水员的语音通话,造成潜水舱内外和潜水员之间联系困难,直接影响到潜水员的深海作业,甚至威胁到潜水员的生命。因此,迫切需要解决深海饱和潜水员的语音通信问题-氦语音解读问题。
目前,国内外现有的饱和潜水氦语音解读器都是通过潜水舱中的氦语音解读器,人工调整解读器的频域或时延特性对氦语音进行解读的,无法自适应饱和潜水作业深度,并且解读效果不理想,当潜水深度大于200米以后,氦语音解读器解读质量迅速下降,特别当潜水员的潜水深度在变化时,无法有效解读潜水员的氦语音。基于人工智能的饱和潜水氦语音解读技术目前国内外都处于刚刚起步阶段,鲜见实用的技术方案。如何充分利用人工智能机器学习的能力,结合饱和潜水场景潜水员和工作语言的特殊性,有效解读氦语音,是一个尚未解决的技术难题。
技术实现要素:
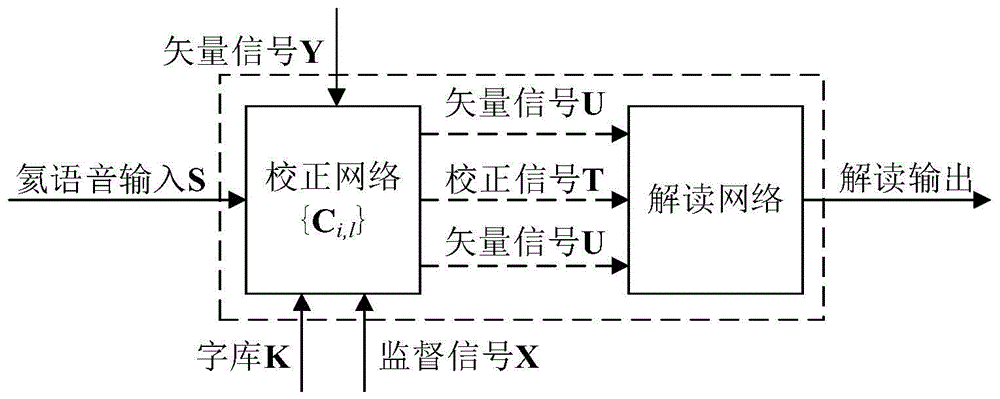
本发明的目的在于解决上述难题。考虑到饱和潜水场景下,潜水员的人群是特定的,在潜水作业时潜水员的工作语言是有限的,本发明充分利用了潜水员个体语音信号特征和工作语言词库词汇信息,提出一种基于词库学习的氦语音解读方法。在该方法中,首先根据饱和潜水作业规范要求建立潜水员常用工作语言词库,由潜水员分别在正常大气压环境下和饱和潜水作业对应环境下朗读工作语言词库,生成校正网络机器学习的监督信号和矢量信号,校正网络采用监督学习算法对不同潜水员在不同潜水深度的氦语音进行学习得到校正网络参数集;其次,潜水员在潜水作业时将其氦语音信号与校正网络的矢量信号进行拟合,选择拟合度最高的矢量信号所对应的网络参数作为校正网络的参数,对潜水员的氦语音进行校正得到校正语音信号;然后,将校正得到的语音信号与常用工作语言词库进行拟合,并按拟合度高低进行筛选,生成解读网络机器学习的监督信号和矢量信号,解读网络采用监督学习算法对校正语音信号进行进一步学习;最后,解读网络对校正语音信号进行解读,完成氦语音的完备解读。该方法充分利用了对潜水员在不同环境下个体语音信号特征和工作语言词库词汇信息,采用机器学习算法校正和解读氦语音,大大提高了氦语音解读的准确性。
上述目的通过下述技术方案予以实现:本发明一种基于词库学习的饱和潜水氦语音解读方法,所述方法包括至少1个潜水员、1个氦语音校正网络和1个氦语音解读网络,潜水员的氦语音信号为s,所述氦语音解读技术包括如下步骤:
第一阶段-——校正网络学习:
步骤1、词库信号构建——根据饱和潜水作业规范要求,构建潜水员饱和潜水作业常用工作语言文词库k;
步骤2、监督信号生成——在正常大气压环境下,潜水员i朗读词库k中的文字获得监督信号xi,从而生成校正网络机器学习监督信号集x={xi},i=1,2,…,i,i为潜水员的人数;
步骤3、矢量信号生成——潜水员i分别在饱和潜水深度h1,h2,h3,…hl,…,hl对应的环境下朗读词库k中的文字获得矢量信号yi.l,l=1,2,…,l,从而生成校正网络机器学习的矢量信号集y={yi.l},l为饱和潜水深度的序号;
步骤4、校正网络学习——以矢量信号yi.l作为输入信号,以监督信号xi作为期望输出信号,校正网络进行监督学习,形成与矢量信号yi.l相对应的校正网络参数集c={ci.l};
第二阶段-——氦语音解读:
步骤5、校正网络参数选取——将潜水员饱和潜水作业时的工作语音s(氦语音)与矢量信号集y中所有矢量信号yi.l进行拟合,选择一个拟合度最高的矢量信号yn.l所对应的参数cn,l作为校正网络的网络参数;
步骤6、氦语音校正——将氦语音信号s作为校正网络(此时,校正网络的网络参数为cn,l)的输入信号,对氦语音信号s进行校正,生成校正语音信号t;
步骤7、解读网络学习——将校正语音信号t中的语音与校正网络机器学习监督信号集x中监督信号按文字进行逐一比较,计算他们之间的拟合度,在监督信号集x中选取拟合度最高的文字对应的语音与校正语音信号t文字对应的语音相匹配成组,并将这些匹配成组的语音按拟合度高低顺序排序,选取拟合度前p%的组合,所述组合中校正语音信号t的语音作为解读网络机器学习的矢量信号u,所述组合中监督信号集x的文字对应的语音作为解读网络机器学习的监督信号v,解读网络进行监督学习;
步骤8、氦语音解读——以校正语音信号t作为解读网络的输入信号,完成氦语音s的解读。
本发明还具有如下特征:
1、所述步骤1中,所构建的潜水员饱和潜水作业常用工作语言文词库k是根据氦语音解读器使用单位饱和潜水作业规范要求进行设置的,不同的使用单位,常用工作语言文词库k会有所不同;
2、所述步骤2中,每一个潜水员都有一个监督信号,不同的潜水员,由于他们的发音不一样,其监督信号也不一样;
3、所述步骤3中,氦语音测试点深度h1,h2,h3,…,hl要求均匀覆盖打捞潜水作业的预设深度,但也可以非均匀覆盖打捞潜水作业的预设深度;
4、所述步骤3中,测试点的个数由预设打捞潜水作业深度和测试点间隔决定的,测试点间隔越细,氦语音解读越完备,但生成矢量信号的时间越长,氦语音解读复杂性越高;
5、所述步骤3中,每一个潜水员在每一个测试点(不同潜水深度)都有一个对应的矢量信号;
6、所述步骤4中,所采用的学习算法可以是任何一种形式的监督学习算法,也可以是任何一种形式半监督学习算法;
7、所述步骤4中,校正网络结构是与步骤4所选用的学习算法相对应的;
8、所述步骤5中,所采用的拟合度评价指标是氦语音s与矢量信号yi.l之间的欧氏距离,但也可以是均值、方差等其它评价指标;
9、所述步骤7中,所采用的拟合度评价指标是校正语音信号t与词库k中的词汇之间的欧氏距离,但也可以是均值、方差等其它评价指标;
10、所述步骤7中,词组筛选比例p与词库k设置的大小有关,词库k越大,潜水员工作时的通话词汇落在词库k中的概率越大,p也越大,氦语音解读也越完备;通常,词库k中的词汇在100个~300个之间,则p的大小选取在85~98之间;
11、所述步骤7中,所采用的学习算法可以是任何一种形式的监督学习算法,例如k-近邻算法、决策树等,也可以是任何一种形式半监督学习算法,例如自训练算法、半监督支持向量机等;12、所述步骤7中,校正网络结构是与步骤7所选用的学习算法相对应的;
13、所述步骤6中,如果潜水员的语音失真不是很严重,校正语音信号t可以直接作为氦语音解读信号输出;
14、所述步骤1-步骤8中,步骤1-步骤4是潜水员在潜水舱中(潜水作业前期准备工作时)完成的,步骤5-步骤8是是潜水员在深海潜水作业时完成的;
15、所述步骤2中,校正网络的监督信号可以采用文字标签,此时潜水员不需要朗读词库k中的文字,直接采用词库k作为监督信号x;对应的,所述步骤6中所产生的校正语音信号t也是文字的,所述步骤8中所产生的氦语音解读信号也是文字的。
本发明方法在于氦语音的解读中,利用了潜水员在不同环境下个体语音信号特征和工作语言词库词汇信息以及人工智能网络的机器学习能力,从而产生以下的有益效果:
(1)通过学习潜水员工作语言词库词汇信息,减少了网络对机器学习样本数的要求,使得潜水员能够在潜水舱的潜水作业前期准备工作阶段完成校正网络的学习;
(2)通过学习潜水员在不同环境下个体语音信号特征,提高了机器学习网络的学习效率,消除了环境噪声对氦语音解读的影响,使得氦语音解读器在解读不同潜水深度的氦语音时具有自适应性;
(3)校正网络和解读网络相结合,提高了氦语音解读的准确性。
附图说明
图1是氦语音解读流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
在包括潜水员、氦语音校正网络和氦语音解读网络的系统中,首先根据饱和潜水作业规范要求建立潜水员常用工作语言词库,由潜水员分别在正常大气压环境下和饱和潜水作业对应环境下朗读工作语言词库,生成校正网络机器学习的监督信号和矢量信号,校正网络采用监督学习算法对不同潜水员在不同潜水深度的氦语音进行学习得到校正网络参数集;其次,潜水员在潜水作业时将其氦语音信号与校正网络的矢量信号进行拟合,选择拟合度最高的矢量信号所对应的网络参数作为校正网络的参数,对潜水员的氦语音进行校正得到校正语音信号;然后,将校正得到的语音信号与常用工作语言词库进行拟合,并按拟合度高低进行筛选,生成解读网络机器学习的监督信号和矢量信号,解读网络采用监督学习算法对校正语音信号进行进一步学习;最后,解读网络对校正语音信号进行解读,完成氦语音的完备解读。
第一阶段-——校正网络学习。
步骤1、词库信号构建——根据饱和潜水作业规范要求,构建潜水员饱和潜水作业常用工作语言文词库k。
在本例中,根据xx打捞局的饱和潜水作业规范要求,构建了由“潜水、夹板、温度、压力”等150个词汇组成的常用工作语言文词库k。
步骤2、监督信号生成——在正常大气压环境下,潜水员i朗读词库k中的文字获得监督信号xi,从而生成校正网络机器学习监督信号集x={xi},i=1,2,…,i,i为潜水员的人数。
在本例中,由2个潜水员分别朗读了词库k中的文字,生成校正网络机器学习监督信号(语音信号)集x1和x2(语音信号)。
步骤3、矢量信号生成——潜水员i分别在饱和潜水深度h1,h2,h3,…hl,…,hl对应的环境下朗读词库k中的文字获得矢量信号yi.l,l=1,2,…,l,从而生成校正网络机器学习的矢量信号集y={yi.l},l为饱和潜水深度的序号;。
在本例中,饱和潜水作业深度范围为200米~250米,测试点间隔为10米,2个潜水员在潜水舱饱和潜水深度200米、210米、220米、230米、240米和250米对应的环境下,分别朗读词库k中的文字,生成校正网络机器学习矢量信号(语音信号)y1.1、y1.2、y1.3、y1.4、y1.5、y1.6、y2.1、y2.2、y3.3、y4.4、y5.5和y6.6。
步骤4、校正网络学习——以矢量信号yi.l作为输入信号,以监督信号xi作为期望输出信号,校正网络进行监督学习,形成与矢量信号yi.l相对应的校正网络参数集c={ci.l}。
在本例中,校正网络采用k-近邻算法进行监督学习。监督学习后,校正网络对应于不同的矢量信号y1.1、y1.2、y1.3、y1.4、y1.5、y1.6、y2.1、y2.2、y3.3、y4.4、y5.5和y6.6和监督信号x1和x2,生成了对应的校正网络参数c1.1、c1.2、c1.3、c1.4、c1.5、c1.6、c2.1、c2.2、c3.3、c4.4、c5.5和c6.6;当校正网络的输入矢量信号为y1.1、y1.2、y1.3、y1.4、y1.5、y1.6时,其监督信号为x12;当校正网络的输入矢量信号为y2.1、y2.2、y3.3、y4.4、y5.5、y6.6时,其监督信号为x2。
第二阶段-——氦语音解读。
步骤5、校正网络参数选取——将潜水员正常饱和潜水作业时的工作语音s(氦语音)与矢量信号集y中所有矢量信号yi.l进行拟合,选择一个拟合度最高的矢量信号yn.l所对应的网络参数cnl作为校正网络的网络参数。
在本例中,潜水员1在工作,因此将潜水员1的工作语音信号-氦语音s与所有矢量信号y1.1、y1.2、y1.3、y1.4、y1.5、y1.6、y2.1、y2.2、y3.3、y4.4、y5.5和y6.6分别进行拟合,选择了拟合度最高的矢量信号y1.3所对应的网络参数c1.3作为校正网络的网络参数,拟合时采用欧氏距离作为评价指标。
步骤6、氦语音校正——将氦语音信号s作为校正网络(此时,校正网络的网络参数为cn,l)的输入信号,对氦语音信号s进行校正,产生校正语音信号t。
在本例中,校正网络对氦语音信号s进行校正时所采用的校正网络参数为c1.3,产生的校正语音信号为t。
步骤7、解读网络学习——将校正语音信号t中的语音与校正网络机器学习监督信号集x中监督信号按文字进行逐一比较,计算他们之间的拟合度,在监督信号集x中选取拟合度最高的文字对应的语音与校正语音信号t文字对应的语音相匹配成组,并将这些匹配成组的语音按拟合度高低顺序排序,选取拟合度前p%的组合,所述组合中校正语音信号t的语音作为解读网络机器学习的矢量信号u,所述组合中监督信号集x的文字对应的语音作为解读网络机器学习的监督信号v,解读网络进行监督学习。
在本例中,采用欧氏距离将校正语音信号t与监督信号集x中监督信号按文字进行逐一比较,在监督信号集x中选取拟合度最高的文字对应的语音与校正语音信号t文字对应的语音相匹配成组,并将这些匹配成组的语音按拟合度高低顺序排序,选取拟合度前90%匹配组所对应的校正语音信号t中语音信号作为解读网络机器学习的矢量信号u,其对应的监督信号集x中的语音信号作为解读网络机器学习的监督信号v,解读网络进行监督学习,解读网络采用k-近邻算法进行监督学习。
步骤8、氦语音解读——以校正语音信号t作为解读网络的输入信号,完成氦语音s的解读。
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

