本发明涉及语音合成技术领域,特别涉及一种基于变分自编码器的语音刺激连续统合成方法及装置。
背景技术:
在语音感知研究中,合成的语音连续统的质量对实验结果有重要的影响。常见的合成方法是手动修改自然语音的关键声学参数,即:首先从口语中提取相关的声学参数;之后根据数学公式在相关声学参数之间进行插值操作;最后使用声码器将插值得到的参数序列转换回语音信号。这一传统方法直接修改关键的声学线索,较难实现两个语音范畴之间全局和平滑的过渡,生成的语音听起来可能不自然。
例如,在现有语音感知研究中,通常使用手动修改种子音节声学参数的方法合成两个语音范畴间的连续统,来探究语音的范畴感知机制。这一方法有几个关键的局限性。首先,当两个语音范畴在多个声学维度上不同时(例如,英语中/r/和/l/在第一、第二和第三共振峰都不同),合成的语音连续统有可能听起来不自然。其次,由于声学参数是连续变化的物理量,直接对关键的声学特征进行手工插值可能会掩盖细微但重要的动态变化特征,而这些动态变化可能是听众辨别两个语音范畴的重要线索,由于合成的连续统质量上的缺陷,这些线索都不会出现在随后的感知实验中。
技术实现要素:
本发明的目的在于提供一种基于变分自编码器的语音刺激连续统合成方法及装置,通过深度学习模型来合成感知实验中所需要的语音刺激连续统,解决手动修改可能造成的信息损失和不自然的问题。
为解决上述技术问题,本发明的实施例提供如下方案:
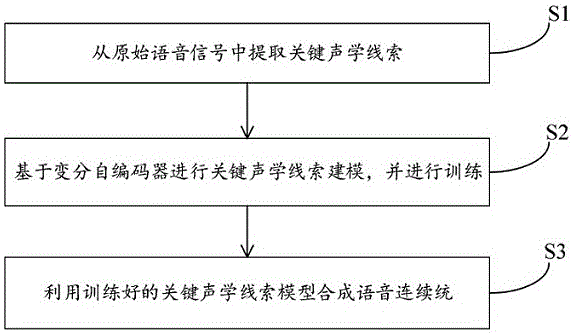
一方面,提供了一种基于变分自编码器的语音刺激连续统合成方法,包括以下步骤:
s1、从原始语音信号中提取关键声学线索;
s2、基于变分自编码器进行关键声学线索建模,并进行训练;
s3、利用训练好的关键声学线索模型合成语音连续统。
优选地,所述步骤s1中,使用world声码器提取基频作为关键声学线索,并对提取的基频包络进行归一化预处理。
优选地,所述步骤s2中,变分自编码器的编码和解码都采用带有门控结构的全卷积神经网络对所述关键声学线索进行建模。
优选地,所述步骤s3包括:
给定两个语音刺激范畴,提取两个语音刺激范畴的关键声学线索;
将提取的两个关键声学线索送入训练好的关键声学线索模型,通过所述关键声学线索模型学习两个关键声学线索对应的隐空间分布;
在两个隐空间分布之间进行连续重采样,得到两个关键声学线索之间逐渐过渡的语音刺激样本;
通过world声码器将所述语音刺激样本还原回波形信号。
一方面,提供了一种基于变分自编码器的语音刺激连续统合成装置,包括:
提取模块,用于从原始语音信号中提取关键声学线索;
模型建立模块,用于基于变分自编码器进行关键声学线索建模,并进行训练;
合成模块,用于利用训练好的关键声学线索模型合成语音连续统。
优选地,所述提取模块中,使用world声码器提取基频作为关键声学线索,并对提取的基频包络进行归一化预处理。
优选地,所述模型建立模块中,变分自编码器的编码和解码都采用带有门控结构的全卷积神经网络对所述关键声学线索进行建模。
优选地,所述合成模块具体用于:
给定两个语音刺激范畴,提取两个语音刺激范畴的关键声学线索;
将提取的两个关键声学线索送入训练好的关键声学线索模型,通过所述关键声学线索模型学习两个关键声学线索对应的隐空间分布;
在两个隐空间分布之间进行连续重采样,得到两个关键声学线索之间逐渐过渡的语音刺激样本;
通过world声码器将所述语音刺激样本还原回波形信号。
本发明实施例提供的技术方案带来的有益效果至少包括:
(1)给语音感知实验提供了新的技术路线,可以采用当前比较流行且合成质量比较高的深度学习技术来产生连续统刺激。
(2)简化了语音感知实验的流程。一般的语音感知实验所需的实验刺激,需要繁琐的手工操作,而本发明提出的方法可以让模型自动生成所需要的实验刺激。
(3)解决了现有技术中手动修改可能造成的信息损失和不自然的问题,提高了合成的连续统质量。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的基于变分自编码器的语音刺激连续统合成方法的流程图;
图2是本发明实施例提供的基于vae的关键声学线索建模(以基频为例)示意图;
图3是本发明实施例提供的vae示意图;
图4是本发明实施例提供的glu示意图;
图5是本发明实施例提供的基于vae的语音刺激连续统合成(以基频为例)示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
本发明的实施例提供了一种基于变分自编码器的语音刺激连续统合成方法,如图1所示,所述方法包括以下步骤:
s1、从原始语音信号中提取关键声学线索。
本步骤中,使用world声码器提取基频作为关键声学线索,并对提取的基频包络进行归一化预处理。其中,关键声学线索又称关键声学参数或关键声学特征。
s2、基于变分自编码器(vae)进行关键声学线索建模,并进行训练。
本步骤中,变分自编码器的编码(encoder)和解码(decoder)都采用带有门控结构glu(gatedlinearunit)的全卷积神经网络对所述关键声学线索进行建模。
具体地,原始语音信号的关键声学线索提取和建模如图2所示,其中vae结构如图3所示,glu结构如图4所示。使用world声码器从原始语音信号riginaltone中提取关键声学线索,然后送入vae模型进行训练。
s3、利用训练好的关键声学线索模型合成语音连续统。
本步骤具体包括:
给定两个语音刺激范畴,提取两个语音刺激范畴的关键声学线索;
将提取的两个关键声学线索送入训练好的关键声学线索模型,通过所述关键声学线索模型学习两个关键声学线索对应的隐空间分布;
在两个隐空间分布之间进行连续重采样,得到两个关键声学线索之间逐渐过渡的语音刺激样本;
通过world声码器将所述语音刺激样本还原回波形信号。
具体地,语音刺激连续统的合成如图5所示。将两个语音刺激范畴tonea、toneb的关键声学线索送进训练好的vae模型中,通过在两个隐空间中重采样得到两个关键声学线索之间逐渐过渡的样本,最后通过world声码器还原回波形信号。
本发明的上述实施例中,使用基于变分自编码器(vae)的方法对原始语音信号关键声学线索的生成过程进行建模,而不是手动修改自然语音的关键声学参数。vae是生成模型,它是基于标准自编码器(ae,一种无监督的建模方法)的正则化版本。vae将数据(原始空间)压缩成低维变量(隐空间),同时保留尽可能多的信息;并且在隐空间中相邻的样本点对应的原始空间越相似,这就为连续统刺激的生成奠定了理论基础。
在语音刺激连续统合成中,给定一组关键声学线索(如基频),就可以在隐空间中得到动态声学线索(基频变化)的关键信息。此外,vae对隐空间进行了约束,使得原始数据不是由单点编码,而是编码为隐空间的标准正态分布。这样一来,训练的模型能够在学习到的分布中重新采样,从而产生原始数据中不存在的新样本。这一数据驱动的方法不直接对关键声学线索进行操作,而是在学习了关键声学线索的分布后进行重新取样,从而避免了人工插值可能造成的信息损失和不自然的问题。
相应地,本发明的实施例还提供了一种基于变分自编码器的语音刺激连续统合成装置,所述装置包括:
提取模块,用于从原始语音信号中提取关键声学线索;
模型建立模块,用于基于变分自编码器进行关键声学线索建模,并进行训练;
合成模块,用于利用训练好的关键声学线索模型合成语音连续统。
进一步地,所述提取模块中,使用world声码器提取基频作为关键声学线索,并对提取的基频包络进行归一化预处理。
进一步地,所述模型建立模块中,变分自编码器的编码和解码都采用带有门控结构的全卷积神经网络对所述关键声学线索进行建模。
进一步地,所述合成模块具体用于:
给定两个语音刺激范畴,提取两个语音刺激范畴的关键声学线索;
将提取的两个关键声学线索送入训练好的关键声学线索模型,通过所述关键声学线索模型学习两个关键声学线索对应的隐空间分布;
在两个隐空间分布之间进行连续重采样,得到两个关键声学线索之间逐渐过渡的语音刺激样本;
通过world声码器将所述语音刺激样本还原回波形信号。
本实施例的装置,可以用于执行图1所示方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
本发明针对语音感知实验,使用数据驱动的方式通过在隐空间中重采样合成所需要的连续统刺激,建模部分具有通用性,适用于语音信号中的各种声学线索。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

