本发明属于声纹验证技术领域,涉及一种基于应用场景进行声纹快速验证的方法及其应用,特别涉及一种基于不同应用场景设定声纹得分进而完成声纹快速验证的方法及其应用。
背景技术:
近年来随着技术的不断进步,线上服务越来越成为了人们生活的日常,银行、证券、保险等行业的线上服务不断上线,由于安全的需要,近年来证券行业开始实施投资者适当性管理办法,办法要求在行业全面推行双录。双录主要是对客户办理业务的过程,特别是风险揭示过程进行留底,用这样的方式可以规范金融销售的行为,同时也为日后争议提供依据。远程双录具体是指投资者通过网络线上办理业务时,需要同步录音、录像,以规范业务办理、加强投资者保护。
声纹指语音波形中反映说话人生理和行为信息的声学参数特征,每个人的声纹具有唯一性、独特性,可用于进行身份识别。与指纹、人脸、虹膜等生物特征相比,声纹具有非接触获取、采集成本低、便于远程认证的优点。
声纹识别是一项提取说话人声音特征和说话内容信息,自动核验说话人身份的技术,在基于网络、电话的远程身份认证中有着得天独厚的的优势。
经过证券公司几年对金融科技的持续投入,在互联网端、移动终端等多渠道布局,投资者也倾向于通过app来开户或者预约开通业务权限,目前对个人客户的多数办理需求已经实现了线上化支持,往往可以通过进行客户远程身份认证进而对个人客户进行远程授权,以方便个人客户进行线上办理业务。但是当前的身份认证均采用同一标准,其虽然具有安全性好的特点,但相对而已其对数据的调用量更大,对服务器要求较高,同时其处理速度较慢,一定程度上影响了客户用户体验,如客户登录账号等低风险操作也需要进行最高等级的声纹身份认证。
因此,开发一种基于应用场景进行声纹快速验证的方法极具现实意义。
技术实现要素:
本发明的目的在于克服现有声纹验证数据处理量较大、未基于应用场景设计且用户体验较差的缺陷,提供一种基于应用场景进行声纹快速验证的方法及其应用。
为实现上述目的,本发明提供如下技术方案:
一种基于应用场景进行声纹快速验证的方法,应用于电子设备,其步骤如下:
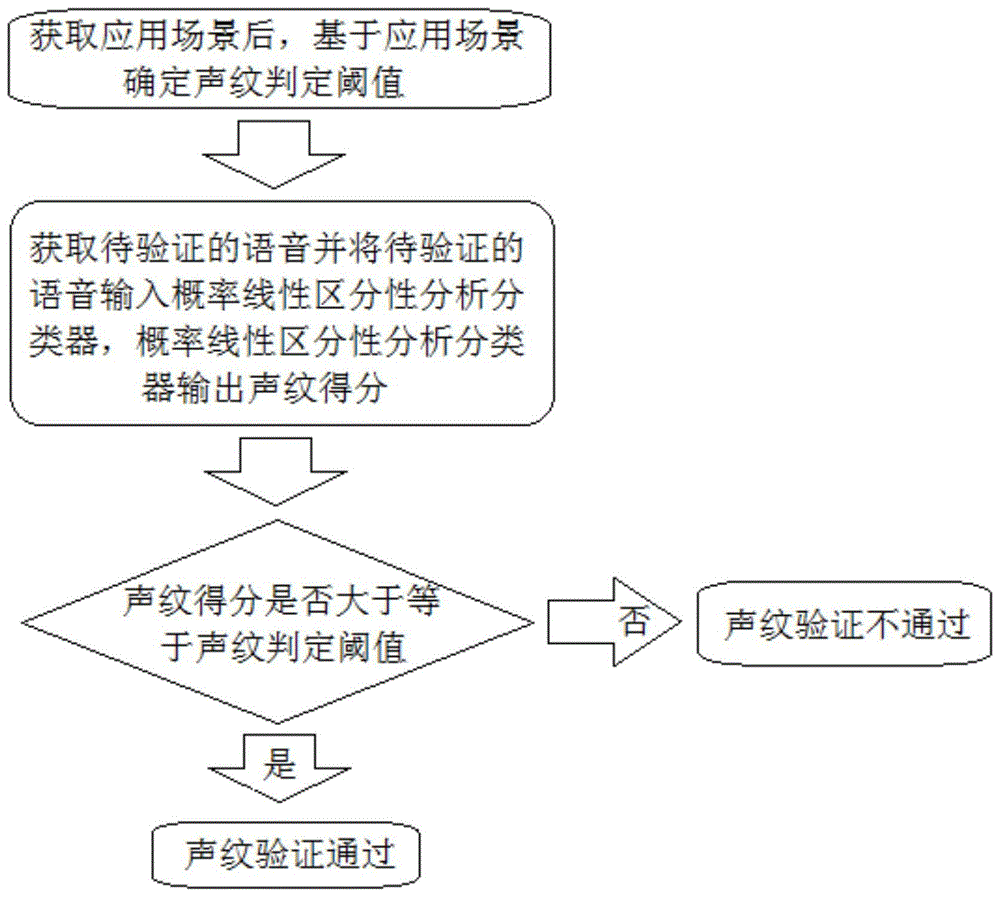
(1)获取应用场景后,基于应用场景确定声纹判定阈值;
(2)获取待验证的语音并将待验证的语音输入概率线性区分性分析(plda)分类器,概率线性区分性分析(plda)分类器输出声纹得分;
(3)判断步骤(2)获取的声纹得分是否大于等于步骤(1)确定的声纹判定阈值,如是则声纹验证通过,反之则声纹验证不通过;
所述概率线性区分性分析(plda)分类器的训练过程为以身份已知的语音为输入,以该语音的声纹得分为理论输出,不断调整参数的过程,训练的终止条件为声纹验证的准确率与预定的声纹得分匹配(具体地,声纹验证的准确率与预定的声纹得分匹配是指声纹验证的准确率为99%与声纹得分为80分匹配,训练的目标是使得相同说话人的特征值相识度越来越好,不同说话人的特征值差异越来越大)。
本发明的基于应用场景进行声纹快速验证的方法,采用概率线性区分性分析(plda)分类器获取声纹得分,plda采用大量的跨信道、一人多条数据训练而成,比一般的余弦(cosine)距离区分性、鲁棒性更好,为了便于计算评估,得分采用百分制,得分越高代表相似度越高,同时本发明针对不同的场景对声纹的严谨性要求不一样的这一问题,针对不同场景设定不同的声纹判定阈值(声纹判定阈值即是基于具体的场景测试集得到的较优经验值)。比如,在双录场景中,是利用声纹识别结果值辅助人工进行判断决策,这属于较宽松的应用场景,相对声纹准确率要求会有所降低。对此,本发明可在双录业务存量数据随机选取100人,每人2条语音作为测试集,1条用于声纹登记,1条用于声纹验证,正负样本进行交叉测试,根据该场景下声纹验证准确率99%为目标作为基准,反推得出声纹得分阈值为80分。那么得分超过80分的,则认定声纹验证通过,低于80分则不通过。
本发明针对不同应用场景设定不同的阈值,一方面缓解了数据处理量过大的问题,另一方面能够大大提高验证数据,改善用户体验,差异化阈值的设定在保证使用安全性的同时大大改善了用户体验,极具应用前景。
作为优选的技术方案:
如上所述的一种基于应用场景进行声纹快速验证的方法,所述声纹得分采用百分制。
如上所述的一种基于应用场景进行声纹快速验证的方法,所述声纹判定阈值是应用场景对应的语音测试集测试得到的经验值。
此外,本发明还提供了采用如上所述的一种基于应用场景进行声纹快速验证的方法的电子设备,包括一个或多个处理器、一个或多个存储器、一个或多个程序、用于获取待验证的语音的语音收集装置;
所述一个或多个程序被存储在所述存储器中,当所述一个或多个程序被所述处理器执行时,使得所述电子设备执行如上所述的基于应用场景进行声纹快速验证的方法。
有益效果:
本发明的基于应用场景进行声纹快速验证的方法,针对不同应用场景设定不同的阈值,一方面缓解了数据处理量过大的问题,另一方面能够大大提高验证数据,改善用户体验,差异化阈值的设定在保证使用安全性的同时大大改善了用户体验,极具应用前景。
附图说明
图1为本发明的基于应用场景进行声纹快速验证的方法的流程图。
具体实施方式
下面结合附图,对本发明的具体实施方式做进一步阐述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例1
一种基于应用场景进行声纹快速验证的方法,应用于电子设备,其步骤如图1所示:
(1)获取应用场景后,基于应用场景确定声纹判定阈值;
(2)获取待验证的语音并将待验证的语音输入概率线性区分性分析分类器,概率线性区分性分析分类器输出声纹得分;
(3)判断步骤(2)获取的声纹得分是否大于等于步骤(1)确定的声纹判定阈值,如是则声纹验证通过,反之则声纹验证不通过;
概率线性区分性分析分类器的训练过程为以身份已知的语音为输入,以该语音的声纹得分为理论输出,不断调整参数的过程,声纹得分采用百分制,声纹验证的准确率为99%与声纹得分为80分匹配,训练的目标是使得相同说话人的特征值相识度越来越好,不同说话人的特征值差异越来越大;
声纹判定阈值是应用场景对应的语音测试集输入训练好的概率线性区分性分析分类器后测试得到的经验值。
经验证,本发明的基于应用场景进行声纹快速验证的方法,针对不同应用场景设定不同的阈值,一方面缓解了数据处理量过大的问题,另一方面能够大大提高验证数据,改善用户体验,差异化阈值的设定在保证使用安全性的同时大大改善了用户体验,极具应用前景。
实施例2
一种电子设备,包括一个或多个处理器、一个或多个存储器、一个或多个程序、用于获取待验证的语音的语音收集装置;
一个或多个程序被存储在存储器中,当一个或多个程序被处理器执行时,使得电子设备执行与实施例1相同的基于应用场景进行声纹快速验证的方法。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应该理解,这些仅是举例说明,在不违背本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

