本发明属于语音识别技术领域,具体涉及一种零多通道盲声源分离方法。
背景技术:
盲声源分离是在未知记录环境、混合系统和声源位置的先验条件下,从接收到的混合声源中分离出原始源信号。盲声源分离的一种典型方法是基于概率模型的无监督学习,可以分为单通道源分离和多通道源分离,对于多通道源分离方法通常由一个表示源图像时频结构的源模型以及代表其通道间协方差结构的空间模型组成。广泛使用的源模型是基于非负矩阵分解(nmf)的低秩模型来缓解排列问题,空间模型中每个源的时频点通常被假设为多元复数高斯。
多通道源分离的代表是多通道非负矩阵分解(mnmf),它包含一个低秩的源模型和一个满秩的空间模型。这个满秩的空间模型能够代表多种声源在回声条件下的方向性,但是多通道非负矩阵分解由于需要迭代估计大量无约束的空间协方差矩阵,所以会趋向于陷入不良的局部最优。为了解决这个问题,学者们提出了独立低秩矩阵分析方法(ilrma),其假设空间模型的秩为1,对于定向源表现较好,本质上讲,独立低秩矩阵分析方法的空间模型和源模型分别是独立的矢量分析和非负矩阵分解,是通过迭代进行优化的。
基于非负矩阵分解的方法,如多通道非负矩阵分解,独立低秩矩阵分析以及其变体都使用非负矩阵分解将给定的频谱分解为几个谱基矩阵和时间激活矩阵。尽管源图像的空间特性为分解的唯一性约束nmf的碱基,但却无法保证每个声源的谱内容是可辨别的,需要具有提高源分离性能的潜力。
技术实现要素:
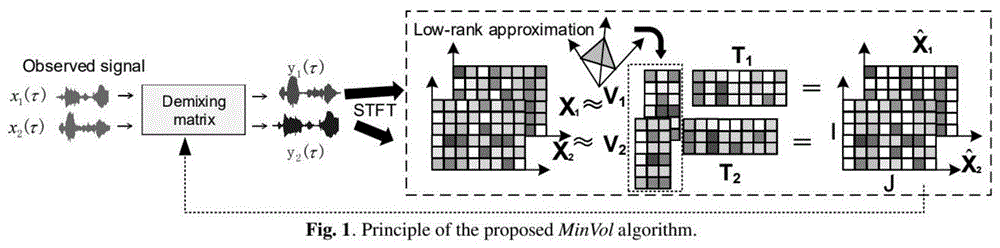
为了克服现有技术的不足,本发明提供了一种基于最小体积约束的多通道盲声源分离方法,首先将接受到的多通道混合信号通过解混合矩阵,得到声源的近似估计,再通过短时傅里叶变换得到估计的每个通道时频图矩阵,然后通过最小体积约束的独立低秩矩阵分析,最终更新解混合矩阵。本发明显著提高了混响环境中估计的声源信号失真比,保证了混和声源信号在重构过程中的鲁棒性和可识别性。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:多通道盲声源分离问题公式化表示;
假设多通道混合声源的短时傅立叶变换stft为
声源表示为
假设每个声源都是点源,混合声源与每个声源具有以下联系:
xij=aisij(1)
其中ai是在第i个频点的混合矩阵;
待求解分离信号yij表示为:
yij=wixij(2)
其中wi为(ai)-1的估计,表示为wi=[wi,1,…,wi,m]h,h表示埃尔米特转置;
步骤2:通过xij=xijxijh对声源功率谱进行建模,并使用非负矩阵分解xij:
其中k是基向量的数量,vik,n是频谱基础矩阵
将所有声源在全部频带上的频段ri,n完整表示为一个张量
步骤3:最小体积多通道声源分离;
采用基于最小体积的多通道非负矩阵分解,定义目标函数为:
其中1是一个全1向量,vol(vn)表示最小体积正则化:
其中,δ为正常数,ik是k维的单位矩阵,
步骤4:以式(4)作为目标函数进行训练,求得wi,最终得到分离信号yij,实现多通道盲声源的分离。
优选地,所述δ=0.5。
本发明的有益效果如下:
1、本发明方法的最小体积约束显著提高了混响环境中估计的声源信号失真比。
2、本发明方法保证了混和声源信号在重构过程中的鲁棒性和可识别性。
附图说明
图1为本发明方法结构示意图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
如图1所示,一种基于最小体积约束的多通道盲声源分离方法,包括以下步骤:
步骤1:多通道盲声源分离问题公式化表示;
假设多通道混合声源的短时傅立叶变换stft为
声源表示为
假设每个声源都是点源,混合声源与每个声源具有以下联系:
xij=aisij(1)
其中ai是在第i个频点的混合矩阵;如果ai是可逆的并且m=n,就能找到一个分开矩阵(ai)-1恢复sij;
声源分离的问题就转化为寻找一个(ai)-1的估计,表示为wi=[wi,1,…,wi,m]h,将wi应用于xij时,获得了分离信号yij:
yij=wixij(2)
h表示埃尔米特转置,yij是sij的估计;
步骤2:通过xij=xijxijh对声源功率谱进行建模,并使用非负矩阵分解xij:
其中k是基向量的数量,vik,n是频谱基础矩阵
将所有声源在全部频带上的频段ri,n完整表示为一个张量
步骤3:最小体积多通道声源分离;
由于在(3)式中存在vn的几种有效解,因此mnmf源模型的分解不是唯一的。为了提高ilrma的可识别性,采用基于最小体积的多通道非负矩阵分解的方法(minvol)。minvol的原理如图1所示。
目标函数为:
其中1是一个全1向量,vol(vn)表示最小体积正则化:
其中,δ为一个小的正常数,ik是k维的单位矩阵,
使用最小体积多通道声源分离的原因是,最大限度地减小vn的体积使vn的列在单位单纯形内彼此尽可能接近。对于不同的数据分布假设,损失l的选择应有所不同。由于假设数据是乘法伽马分布,所以选择is散度作为损失。is散度是β散度家族中唯一具有尺度不变性质的散度。这表明低功率时频箱的分布与高功率时频箱的分布在散度计算时同样重要。
步骤4:以式(4)作为目标函数进行训练,求得wi,最终得到分离信号yij,实现多通道盲声源的分离。
具体实施例:
(1)数据准备:
根据sisec挑战的环境,构造了一个m=n=2,即麦克风个数和声源数都为2的多通道语音分离任务。使用华尔街日报(wsj0)语料库作为声源,评估了所有性别组合的比较方法。
生成两个测试条件,分别表示为条件1和条件2。在这两种情况下,房间大小都被设置为6×6×3米;两个说话者被安置在距离两个麦克风中心2米的地方。两种情况的区别是:(i)麦克风间距分别为5.66cm和2.83cm,(ii)两个说话者的入射角分别为40°和40°与40°和20°。使用图像源模型生成房间脉冲响应,混响时间t60从[130,150,200,250,300,350,400,450,500]ms中选择。对于每种性别组合和每种条件下的每个t60,生成了200个混合物进行评估。采样频率设置为16khz。
(2)数据处理:
最小体积约束的多通道盲声源分离算法(minvol)的δ参数设置为0.5。minvol对δ的选择不敏感,因为它只用于防止(5)式无穷大。比较了minvol与auxiva、mnmf和ilrma方法。对于每种方法,设置短时傅里叶变换(stft)的帧长度和帧移位分别为64ms与32ms。每一帧应用了汉明窗。默认情况下,在mnmf、ilrma和minvol中基向量的个数设置为10。评价指标为信号失真率(sdr)。
(3)对比结果
表1信号失真率(sdr)平均提高(db)
首先在消声环境中进行实验。比较几种方法对混合语音的平均sdr改进。本发明提出的minvol的性能明显优于mnmf。与auxiva和ilrma相比,minvol的sdr平均提高了约3db。然后比较了在混响环境下各方法的性能,minvol方法得到的sdr改善曲线始终高于对比方法得到的sdr改善曲线。
为了清楚地显示minvol相对于参考方法的总体改进,将不同性别组合的sdr改进和每种条件的t60取平均值。平均结果列于表1。从表中可以看出,在条件1中,所提出的minvol所带来的平均sdr提升比ilrma高2db,条件2中所带来的平均sdr提升比ilrma高3db。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

