本发明涉及人工智能技术领域,具体涉及一种应用于多人混杂场景下的模糊语句识别方法及系统。
背景技术:
在自然语言处理中,模糊语句指的主要是含有同音或近音字、错误用字、多余字的语句,容易造成语言处理模型识别不清、无法处理的现象。目前的营业厅机器人客服往往处在一个多人同时说话的混杂场景中,导致机器人客服无法准确获取正在与之交互的用户想表达的信息,服务质量大大降低。因此,如何将模糊语句转化为语义准确的语句显得尤为重要。现有的解决方案大多在语音识别阶段提取用户语句或基于规则处理模糊语句文本,举例如下:
(1)将各种噪声估计方法结合如最小值跟踪噪声估计,mcra,imcra等(熊晶,何兴,李晋升.基于大小窗双向并行最小值搜索的imcra算法[j].信息通信,2015,(3).53-55.),然后使用神经网络模型去除语音中的噪声。这种方法的缺点在于:当用户处在弱噪声环境下,去噪处理将不可避免的对语音有所损伤,只有在十分恶劣的环境下,才会起到非常明显的作用。
(2)使用声纹识别技术,通过分析不同用户的声纹以及声音强弱程度,从混杂语音中提取出用户的语音(林暧辉,张伟颂,徐毓文.浅议声纹鉴定中噪声对语音频谱特征的影响及降噪处理[j].黑龙江科技信息,2015,(36).129-130.)。采用此方法的缺点在于:在对用户声纹进行记录时可能会混入噪声,导致后续无法与用户的声纹进行匹配。
(3)请语言学专家制定一系列规则,然后使用规则对模糊语句文本进行分析、判定,最终得到语义准确的文本(张晴晴,潘接林.模糊发音字典在方言口音语音识别中的应用[c].//第八届全国人机语音通讯学术会议(ncmmsc8).:153-156.)。这种方法具有很大的局限性,语言专家无法穷举规则,当模糊语句无法与规则匹配时,就无法将其转化为语义准确的语句。
技术实现要素:
本发明的目的在于提供一种应用于多人混杂场景下的模糊语句识别及系统,主要解决多人混杂场景下,环境中各种噪声、多人言语嘈杂导致模糊语句无法被正确识别的问题。本发明利用多层编码器充分学习拼音级的文本错误特征以及拼音和文本上下文之间的联系,对模糊语句文本进行拼音级文本纠错,提高了语义级错误检测的准确率。
本发明至少通过如下技术方案之一实现。
一种应用于多人混杂场景下的模糊语句识别方法,包括以下步骤:
s1、实时采集语音信号并转化为模糊语句文本并进行预处理;
s2、使用端到端拼音级文本纠错模型对所述模糊语句文本进行拼音级文本纠错,以获取拼音级无错文本;
s3、对所述拼音级无错文本进行语义级文本错误检测,以获取出错字体的位置;
s4、对文本进行语义级纠正,以获取到语义清晰的文本。
优选的,所述端到端拼音级文本纠错模型包括拼音纠错预训练模型和拼音转汉字预训练模型;所述拼音纠错预训练模型通过全连接层与所述拼音转汉字预训练模型相连,构成端到端拼音级文本纠错模型;
拼音纠错预训练模型和拼音转汉字预训练模型均包括拼音嵌入层和多个编码器;
所述拼音纠错预训练模型使用模糊音数据进行训练;
所述拼音转汉字预训练模型使用拼音-汉字数据进行训练;所述模糊音数据和拼音-汉字数据均从现代汉语词典中挑选得到。
优选的,所述拼音纠错预训练模型的拼音嵌入层,具体为:在拼音字典中查询文本中的词组对应的拼音;若能够查询到词组对应的拼音,则记录查询结果;若无法查询到词组对应的拼音,则将对应词组的语音信息转化为拼音并记录。
优选的,所述拼音纠错预训练模型将文本转化为拼音包括以下步骤:
a、设需要转化为拼音的文本为s,则有:
其中,wn是文本中的词组,n是文本中的词组个数;
s=(w1,w2,…,wi…,wn)
b、根据词语字典dictionary,查询词组wi对应的拼音
其中,i是词组的序号;
c、根据词组的语音信息ti,在数据库database中匹配对应的拼音
d、当步骤b无法查询到词组的拼音
其中,μ表示词组wi对应的拼音
e、i变为i 1,重复步骤b~步骤d。
优选的,所述拼音纠错预训练模型的编码器包括单头自注意力层和全连接层,具体拼音纠错包括以下步骤:
1)、将拼音嵌入层输出的拼音向量ei与拼音位置向量ki相加,作为编码器的输入向量xi:
xi=ei ki
其中,n为句子中字的个数,xn为句子中每一个字的向量表示,x为输入句子的矩阵表示;
2)、根据单头自注意力机制计算输入矩阵x内部向量的关联矩阵z:
q=xwq
k=xwk
v=xwv
z=attention(q,k,v)×wo
其中,wq、wk、wv、wo为随机初始化的矩阵,通过训练迭代调整,q表示查询矩阵,k表示关键词矩阵,v表示值矩阵;
3)、将关联矩阵z与输入矩阵x相加,然后使用layernorm(层归一化)函数进行层归一化:
z=layernorm(z x)
4)、将层归一化后的关联矩阵z输入全连接层,对全连接层的输出t再进行层归一化得到矩阵y:
t=zwf bf
y=layernorm(t)
其中,wf是全连接层的权重矩阵,bf是全连接层的偏置向量;
5)、若当前编码器不是最后一个编码器,则将矩阵y输入下个编码器,重复步骤b~步骤d;若当前编码器是最后一个编码器,则将编码器输出连接softmax层,得到拼音纠错结果。
优选的,所述语义级错误检测预训练模型包括双向连接的长短时记忆网络;所述双向连接的长短时记忆网络使用普通文本以及领域相关知识文本进行无监督训练;所述条件随机场层使用带有标注信息的文本进行有监督训练。
优选的,双向连接的长短时记忆网络为:
it=σ(wi·[ht-1,xt] bi)
ft=σ(wf·[ht-1,xt] bf)
ot=σ(wo·[ht-1,xt] bo)
ct=ft·ct-1 it·tanh(wc·[ht-1,xt] bc)
ht=ot·tanh(ct)
其中,it、ft、ot、ct分别表示t时刻输入门,遗忘门,输出门和lstm单元的输出,xt表示t时刻的输入向量,ht-1表示t-1时刻的隐藏层向量,ht表示t时刻的隐藏层向量,σ表示sigmoid激活函数,wi和bi表示输入门结构中的权值矩阵和偏置向量,wf和bf表示遗忘门结构中的权值矩阵和偏置向量,wo和bo表示输出门结构中的权值矩阵和偏置向量,wc和bc表示权重矩阵和偏置向量属于遗忘门结构中的权值矩阵和偏置向量;
双向连接的lstm网络有两个方向相反的并行层,其在t时刻的输出ct为:
其中
所述双向连接的长短时记忆网络与条件随机场层相连,以获取文本中每个字的出错概率,具体为:
结合双向连接的长短时记忆网络与条件随机场,根据词序列x以及双向lstm网络输出的标注序列y=(y1,y2,…,yn),预测错误检测结果s(x,y):
其中,a为状态转移矩阵,
优选的,所述对文本进行语义级纠正,包括以下步骤:
获取经过步骤s2和步骤s3得到的文本;
根据步骤s3错误检测的结果,对每个出错概率超过阈值的字分别进行遮掩处理;
将所述经过遮掩处理的文本输入到knowledge-roberta预训练模型中,knowledge-roberta预训练模型将预测字典中所有字出现在被遮掩位置的概率;
判断所述被遮掩的字在knowledge-roberta预训练模型预测结果中的概率值是否大于或等于设定的阈值;若大于或等于设定的阈值,则保留被遮掩的字;若低于设定的阈值,则进一步判断模型预测结果中最高概率值是否大于或等于设定的阈值;
若所述最高概率值大于或等于设定的阈值,则将被遮掩的字替换为最高概率值对应的字;若所述最高概率值小于设定的阈值,则将被遮掩的字删除。
优选的,所述knowledge-roberta预训练模型,包括:对普通鲁棒优化的bert预训练模型的注意力机制进行修改,引入计算知识距离的函数kdistance;知识距离的大小与两个词在知识图谱中的欧式距离成正比;当两个词在知识图谱中的欧式距离接近0时,知识距离接近0;当两个词在知识图谱中的欧式距离大于设定的阈值时,知识距离接近无穷大。
所述的一种应用于多人混杂场景下的模糊语句识别方法的系统,包括:
语句采集模块,用于采集语音信号并将其转化为文字;
拼音级文本纠错模块,用于检测文本中的同音和近音字错误并修正;
语义级文本纠错模块,用于检测文本中的多余字和被错误使用字并修正;
输出模块,用于将识别后的语义清晰准确的文本输出。
本发明首先对模糊语句文本进行预处理,接着利用拼音字典结合语音信息将文本转化为拼音,然后将拼音输入到拼音纠错预训练模型中,识别语句中有误的拼音并进行纠正,最后使用拼音转文本模型将纠正后的拼音转化成文本。
与现有的技术相比,本发明的有益效果为:
拼音级文本纠错可以修正用户发音不标准对文本带来的影响,语义级文本纠错在拼音级文本纠错的基础上消除混杂场景下文本可能混入干扰字词的影响,两者结合即可实现模糊语句文本到语义准确文本的转化,相比语音识别处理模糊语音的方法抗干扰性更强。除此之外,拼音级文本纠错模块和语义级文本纠错模块均由经过大量数据训练的预训练模型组成,能够检测并修正绝大多数的文本错误,相比基于规则的模糊文本识别方法具有更广泛的适用性以及更低的人工开销。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是实施例示出的一种应用于多人混杂场景下的模糊语句识别方法的流程图;
图2是实施例示出的拼音级文本纠错模块示意图;
图3是实施例示出的语义级文本纠错模块示意图;
图4是实施例示出的一种应用于多人混杂场景下的模糊语句识别系统的示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
这里将详细地对示例性实施例进行说明,其示例表示在附图中。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
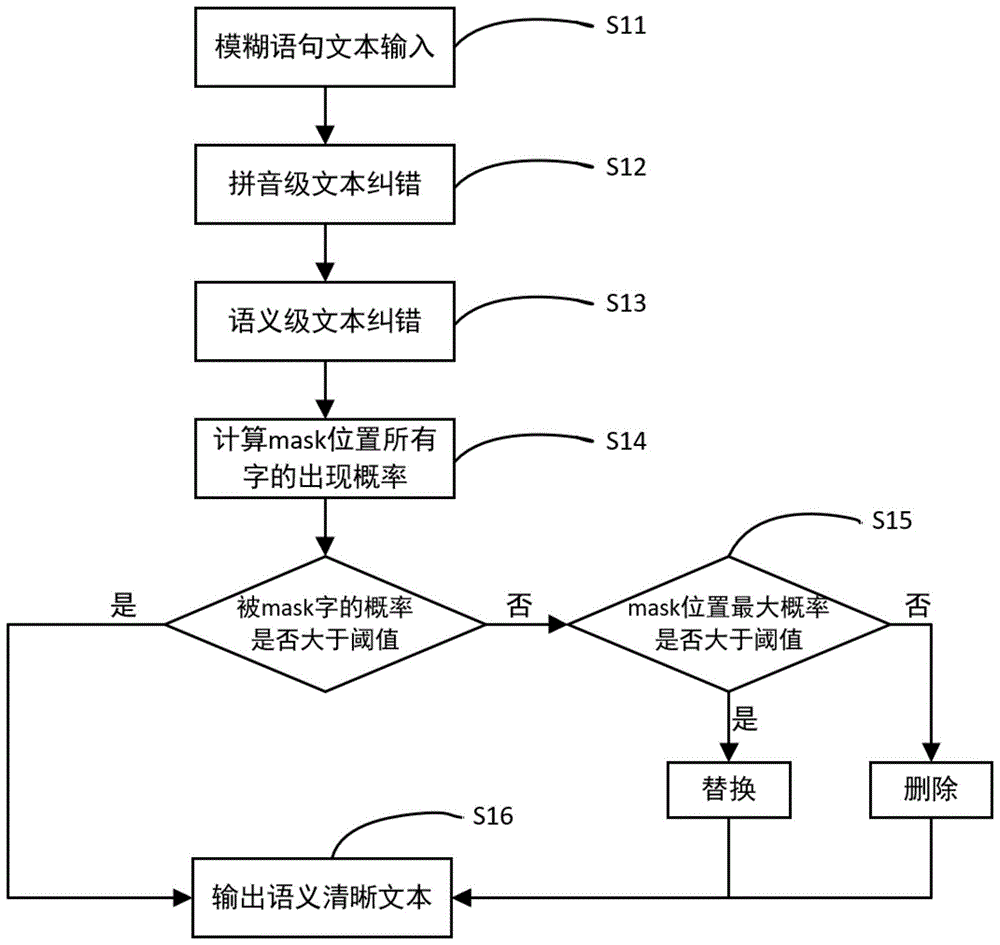
如图1所示的一种应用于多人混杂场景下的模糊语句识别方法,包括以下步骤:
步骤s1、将在多人混杂场景中采集到的语音信号转化为模糊语句文本,并进行预处理;所述预处理包括分词、替换、删除处理;
对所述模糊语句文本进行预处理,包括:
对所述模糊语句文本进行分词处理,以提高后续文本转拼音的准确率;
判断文本长度是否大于128,若大于则将文本分段,每段长度小于或等于128;
若文本长度小于128,则填充空字符直至长度等于128;
在具体实践中,所述将模糊语句文本进行分词处理,可以通过使用分词工具hanlp或在词语字典中搜索匹配将文本切分成多个词组。
本实施例中的模糊语句主要是指含有同音或近音字、错误使用字和多余字的语句,例如:为甚么,一个身份证,他我想问等,导致语言处理模型识别不清,无法给出正确响应。本实施例中的将语音信号转化为模糊语句文本是指通过语音识别技术讲语音转化为机器可以处理的文本。
步骤s2、使用端到端拼音级文本纠错模型对所述模糊语句文本进行拼音级文本纠错,以获取拼音级无错文本;
所述端到端拼音级文本纠错模型包括拼音纠错预训练模型和拼音转汉字预训练模型;所述拼音纠错预训练模型通过全连接层与所述拼音转汉字预训练模型相连,构成端到端拼音级文本纠错模型。
拼音纠错预训练模型和拼音转汉字预训练模型均包括拼音嵌入层和多个编码器;
所述拼音纠错预训练模型使用模糊音数据进行训练;
所述拼音转汉字预训练模型使用拼音-汉字数据进行训练;所述模糊音数据和拼音-汉字数据均从现代汉语词典中挑选得到;
所述拼音纠错预训练模型的拼音嵌入层用于将文本转化为拼音,具体为:在拼音字典中查询文本中的词组对应的拼音;若能够查询到词组对应的拼音,则记录查询结果;若无法查询到词组对应的拼音,则将对应词组的语音信息转化为拼音并记录。
具体实施步骤如下:
a、设需要转化为拼音的文本为s,文本中的词组为w,则有:
s=(w1,w2,…,wi…,wn)
其中,wn是文本中的词组,n是文本中的词组个数;
b、根据词语字典dictionary,查询词组wi对应的拼音
其中,i是词组的序号;
c、根据词组的语音信息ti,在数据库database中匹配对应的拼音
d、当步骤b无法查询到词组的拼音
其中,μ表示词组wi对应的拼音
e、i变为i 1,重复步骤b~步骤d。
使用拼音纠错预训练模型和拼音转汉字预训练模型,根据文本的拼音序列进行拼音级文本纠错。拼音纠错预训练模型和拼音转汉字预训练模型之间使用一个全连接层进行连接,两个模型可以分开训练也可以共同训练。
相比于现有的拼音转文本模型,所述端到端拼音级文本纠错模型优势在于能够更准确地将含有语义错误的拼音转化为文字,保证后续语义级文本纠错的准确度。端到端拼音级文本纠错模型的示意图如图2所示。
所述拼音纠错预训练模型包括拼音嵌入层和多个第一编码器;
使用大量模糊拼音数据对拼音纠错模型进行训练;使用训练后的拼音纠错模型读取文本拼音序列,输出纠正之后的拼音序列。
所述第一编码器可以从拼音序列中提取上下文特征,并结合训练时学习到的知识,对拼音序列进行纠错。
所述第一编码器包括单头自注意力层和全连接层;读取拼音嵌入层输出的拼音向量与拼音位置向量作为输入,通过自注意力层提取拼音序列中拼音之间的关联程度,然后与输入的向量相加并进行层归一化;将所述层归一化的结果输入到全连接层,获取全连接层的输出后进行层归一化,将结果输入到下一个第一编码器中;最后一个第一编码器连接softmax层,以获得纠正后的拼音序列。具体实施步骤如下:
1)、将拼音嵌入层输出的拼音向量ei与拼音位置向量ki相加,作为第一编码器的输入向量xi:
xi=ei ki
其中,n为句子中字的个数,xn为句子中每一个字的向量表示,x为输入句子的矩阵表示;
2)、根据单头自注意力机制计算输入矩阵x内部向量的关联矩阵z:
q=xwq
k=xwk
v=xwv
z=attention(q,k,v)×wo
其中,wq、wk、wv、wo为随机初始化的矩阵,通过训练迭代调整,q表示查询矩阵,k表示关键词矩阵,v表示值矩阵;
3)、将关联矩阵z与输入矩阵x相加,然后使用layernorm(层归一化)函数进行层归一化:
z=layernorm(z x)
4)、将层归一化后的关联矩阵z输入全连接层,对全连接层的输出t再进行层归一化得到矩阵y:
t=zwf bf
y=layernorm(t)
其中,wf是全连接层的权重矩阵,bf是全连接层的偏置向量;
5)、若当前第一编码器不是最后一个第一编码器,则将矩阵y输入下个第一编码器,重复步骤b~步骤d;若当前第一编码器是最后一个第一编码器,则将第一编码器输出连接softmax层,得到拼音纠错结果。
所述拼音转汉字预训练模型包括拼音嵌入层和多个第二编码器;使用大量拼音-文本数据进行训练;读取拼音纠错预训练模型输出的拼音序列,输出文本序列;
所述第二编码器可以从拼音序列中提取上下文特征,并结合预训练时学习到的拼音与文本间的映射关系,将拼音序列转化为文本序列。
所述第二编码器与第一编码器结构基本一致,只是将单头自注意力层替换为多头注意力层,用于捕捉更多样的上下文关联状态信息,得到输入矩阵x内部向量的多头关联矩阵z,具体为:
zi=attention(xwiq,xwik,xwiv),1≤i≤n
z=concat(z1,z2,…,zn)×wo
其中,zi表示输入矩阵x内部向量的关联矩阵;concat表示将每个注意力头的计算结果zi依次拼接;n表示注意力头的个数;wiq、wik、wiv分别为每个注意力头独有的计算矩阵,初始为随机值,在训练过程中迭代调整。
步骤s3、使用语义级文本纠错模块对拼音级无错文本进行语义级文本错误检测,以获取可能出错的字的位置;
所述语义级文本纠错模块包括语义级错误检测预训练模型和语义级错误纠正模型;
对经过拼音级文本纠错后的文本,使用语义级文本纠错模块进行错误检测和错误纠正,如图3所示。
所述语义级错误检测预训练模型包括双向连接的长短时记忆网络;所述双向连接的长短时记忆网络使用大量普通文本以及领域相关知识文本进行无监督训练;所述条件随机场层使用带有标注信息的文本进行有监督训练。
所述双向连接的长短时记忆网络使用大量普通文本以及领域相关知识文本进行无监督训练;所述条件随机场层使用带有标注信息的文本进行有监督训练。lstm网络的计算过程包括:
it=σ(wi·[ht-1,xt] bi)
ft=σ(wf·[ht-1,xt] bf)
ot=σ(wo·[ht-1,xt] bo)
ct=ft·ct-1 it·tanh(wc·[ht-1,xt] bc)
ht=ot·tanh(ct)
其中,it、ft、ot、ct分别表示t时刻输入门,遗忘门,输出门和lstm单元的输出,xt表示t时刻的输入向量,ht-1表示t-1时刻的隐藏层向量,ht表示t时刻的隐藏层向量。σ表示sigmoid激活函数,wi和bi表示输入门结构中的权值矩阵和偏置向量,wf和bf表示遗忘门结构中的权值矩阵和偏置向量,wo和bo表示输出门结构中的权值矩阵和偏置向量,wc和bc表示权重矩阵和偏置向量属于遗忘门结构中的权值矩阵和偏置向量。
双向连接的lstm网络有两个方向相反的并行层,其在t时刻的输出ct为:
其中
所述双向连接的lstm网络直接与条件随机场层相连,以获取文本中每个字的出错概率,具体为:
结合双向lstm网络与条件随机场,根据词序列x以及双向lstm网络输出的标注序列y=(y1,y2,…,yn),预测错误检测结果s(x,y):
其中,a为状态转移矩阵,
作为一种优选地实施例,所述语义级错误检测预训练模型可以使用双向连接的gru(gatedrecurrentunit,门控循环单元)网络替代双向连接的lstm网络;所述双向连接的gru网络使用大量普通文本以及领域相关知识文本进行无监督训练;所述双向连接的gru网络在大规模的数据集上训练速度快于双向连接的lstm网络,但使用双向连接的gru网络训练出模型的语义级错误检测效果会略差于使用双向连接的lstm网络训练出的模型。
s4、利用语义级错误纠正模型对文本进行语义级纠正,以获取到语义清晰的文本。
所述对文本进行语义级纠正,包括以下步骤:
获取经过步骤s2拼音级文本纠错得到的拼音级无错文本;
对拼音级无错文本进行语义级文本错误检测;根据语义级文本错误检测的结果,对每个出错概率超过阈值的字分别进行遮掩(mask)处理;
将所述经过mask处理的文本输入到knowledge-roberta(融合领域专业知识的经过鲁棒优化的bert)预训练模型中,knowledge-roberta预训练模型将预测字典中所有字出现在被遮掩位置的概率;
判断所述被遮掩的字在knowledge-roberta预训练模型预测结果中的概率值是否大于或等于设定的阈值;若大于或等于设定的阈值,则保留被遮掩的字;若低于设定的阈值,则进一步判断模型预测结果中最高概率值是否大于或等于设定的阈值;若所述最高概率值大于或等于设定的阈值,则将被遮掩的字替换为最高概率值对应的字;若所述最高概率值小于设定的阈值,则将被遮掩的字删除,最后将获取到的语义清晰的文本输出。
所述knowledge-roberta预训练模型,包括:对普通roberta(鲁棒优化的bert)模型的注意力机制进行修改,引入计算知识距离的函数kdistance;知识距离的大小与两个词在知识图谱中的欧式距离成正比。
所述knowledge-roberta预训练模型是对普通roberta模型的注意力机制进行修改,具体为:引入计算知识距离的函数kdistance;知识距离的大小与两个词在知识图谱中的欧式距离成正比;当两个词在知识图谱中的欧式距离接近0时,它们的知识距离接近0;当两个词在知识图谱中的欧式距离大于设定的阈值时,它们的知识距离接近无穷大。
修改的roberta模型的注意力机制,具体为:
qj=xiwq
kj=xiwk
vj=xiwv
其中,wq、wk、wv为随机初始化的矩阵,通过训练迭代调整;qj表示查询矩阵的第j列向量,kj表示关键词矩阵的第j列向量,vj表示值矩阵的第j列向量,kjt表示关键词矩阵第j列向量kj的转置;xi为第i个字向量;dk为向量kj的维度;hi,j为衡量第i个字与第j个字关联程度的向量。
作为一种优选实施例,所述knowledge-roberta预训练模型可以使用fastbert(快速bert)模型替代roberta模型,构成knowledge-fastbert预训练模型;所述knowledge-fastbert预训练模型的网络结构相比knowledge-roberta预训练模型,在每层decoder(解码器)后都连接一个分类器预测样本标签,若预测结果的置信度很高就不进行后续计算,直接输出结果;所述knowledge-fastbert预训练模型相比knowledge-roberta预训练模型运行速度可以提升20%左右,但文本纠错的效果会略差于knowledge-roberta预训练模型。
作为一种优选实施例,所述knowledge-roberta预训练模型可以使用bert-wwm-chinese(wholewordmaskingforchinesebert,全字遮掩的中文版bert)模型替代roberta模型,构成knowledge-bert-wwm-chinese预训练模型;所述knowledge-bert-wwm-chinese预训练模型相比knowledge-roberta预训练模型,在预训练的过程中对可以组成一个词组的汉字同时进行遮掩(mask)处理,而不是对每个汉字单独进行遮掩处理;所述knowledge-bert-wwm-chinese预训练模型在训练之前需要消耗一定时间对训练文本进行分词处理;所述knowledge-bert-wwm-chinese预训练模型的文本纠错效果平均优于knowledge-roberta预训练模型,但也可能略差于knowledge-roberta预训练模型,效果的好坏取决于模型训练前对训练文本进行分词处理的准确度。
图4为本实施例示出的一种应用于多人混杂场景下的模糊语句识别系统100的示意框图,该系统100包括:
语句采集模块101,用于采集语音信号并将其转化为文字;
拼音级文本纠错模块102,用于检测文本中的同音和近音字错误并修正;
语义级文本纠错模块103,用于检测文本中的多余字和被错误使用字并修正;
相比现有的语义级文本纠错方法,所述语义级文本纠错模块使用双向长短时记忆网络结合条件随机场进行错误检测,使用knowledge-roberta预训练模型进行语义级错误纠正,更贴合具体场景的纠错需求,纠错准确率更高。语义级文本纠错模块的示意图如图3所示。
所述语义级文本纠错模块包括语义级文本错误检测模型和语义级错误纠正模型;
所述语义级文本错误检测模型包括双向连接的长短时记忆(lstm)网络和条件随机场层;
所述语义级错误纠正模型,具体为:输入经过拼音级文本纠错和语义级文本错误检测的文本;根据语义级文本错误检测的结果,对每个出错概率超过阈值的字分别进行遮掩处理;将所述经过遮掩处理的文本输入到knowledge-roberta预训练模型中,模型将预测字典中所有字出现在被遮掩位置的概率;判断所述被遮掩的字在模型预测结果中的概率值是否大于或等于设定的阈值;若大于或等于设定的阈值,则保留被遮掩的字;若低于设定的阈值,则进一步判断模型预测结果中最高概率值是否大于或等于设定的阈值;若所述最高概率值大于或等于设定的阈值,则将被遮掩的字替换为最高概率值对应的字;若所述最高概率值小于设定的阈值,则将被遮掩的字删除。
输出模块104,用于将识别后的语义清晰准确的文本输出。
需要说明的是,本实施例提供的这种应用于多人混杂场景下的模糊语句识别系统适用于公共场合的和希望在公共场合使用的语音交互装置中,所述语音交互装置包括但不限于:营业厅智能机器人、会议室智能投影仪、商场智能音箱、个人智能手环、个人智能手机等具有语音交互功能的智能设备。
具体实现中,本发明实施例所描述的语句采集模块101,拼音级文本纠错模块102,语义级文本纠错模块103,输出模块104可执行本发明实施例提供的多人混杂场景下的模糊语句识别方法的实施例中所描述的实施方式,这里不再赘述。
以上示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制。熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

