本发明涉及语音识别技术领域,尤其涉及一种智能语音识别处理方法及系统。
背景技术:
随着互联网技术的发展,使用语音进行人机交互的智能设备越来越多,现有的语音交互系统有siri、小蜜、cortana、小冰、度秘等,语音人机交互相比较于传统的手动输入人机交互而言具备便捷高效的特点,具有广泛的应用场景,如何提升智能设备人机交互语音识别的准确率,成为当下需要急需解决的技术问题。
技术实现要素:
本发明的目的在于提供一种智能语音识别处理方法及系统,能够提升智能设备人机交互语音识别的准确率。
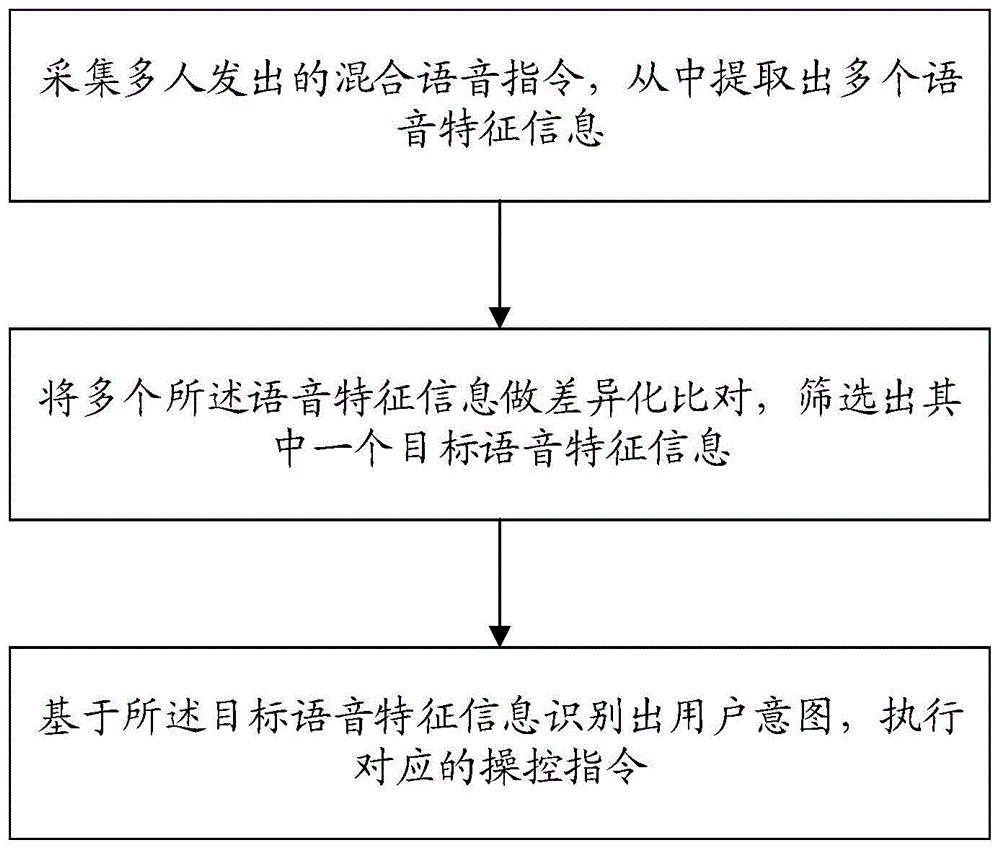
为了实现上述目的,本发明的一方面提供一种智能语音识别处理方法,包括:
采集多人发出的混合语音指令,从中提取出多个语音特征信息;
将多个所述语音特征信息做差异化比对,筛选出其中一个目标语音特征信息;
基于所述目标语音特征信息识别出用户意图,执行对应的操控指令。
优选地,从中提取出多个语音特征信息的方法包括:
对所述混合语音指令进行特征提取;
根据提取的所述特征进行语音分离,得到所述多个语音特征信息。
较佳地,将多个所述语音特征信息做差异化比对,筛选出其中一个目标语音特征信息的方法包括:
计算全部所述语音特征信息的差异化均值;
分别基于每个所述语音特征信息以及所述差异化均值,计算出各所述语音特征信息对应的差异值;
筛选出最大差异值对应的所述语音特征信息,定义为目标语音特征信息。
优选地,在基于所述目标语音特征信息识别出用户意图,并执行与所述用户意图一致的操控指令之前还包括:
训练语音语料知识库,所述语音语料知识库包括多个语音特征信息和与语音特征信息对应的意图类别;
分别对每个语音特征信息进行向量化计算,得到每个语音特征信息的向量;
对每个语音特征信息的向量及对应的意图类别进行分类模型训练,获取意图分类模型;
从所述语音语料知识库中获取关键词,对所述关键词进行训练构建词向量模型。
优选地,基于所述目标语音特征信息识别出用户意图的方法包括:
将所述目标语音特征信息进行预处理和文本处理提取多个关键词;
计算各所述关键词的tf-idf值,得所述目标语音特征信息向量;
使用所述词向量模型搜寻所述目标语音特征信息向量中的0项词,以及匹配所述词向量模型中与所述0项词词义最接近的相似词;
将所述相似词乘以cosine相似度替换所述0项词,所述0项词为在所述目标语音特征信息中出现而未在所述词向量模型中出现的关键词;
计算替换后的所述目标语音特征信息向量,将其输入所述意图分类模型得到所述目标语音特征信息向量的用户意图。
较佳地,执行对应的操控指令之前还包括:
根据识别出的用户意图,结合获取的用户动作指令,生成对应的操控指令。
与现有技术相比,本发明提供的智能语音识别处理方法具有以下有益效果:
本发明提供的智能语音识别处理方法中,通过麦克采集由多人发出的混合语音指令,从混合语音指令中提取出多个语音特征信息,然后对多个语音指令的语音特征信息进行差异化对比,并根据差异化对比的结果确定其中的目标语音特征信息,最终基于目标语音特征信息识别出用户意图,执行与用户意图对应的操作。可见,本发明可以有效解决在多人说话场景下语言识别效果差导致难以准确执行用户下的效果。
本发明的第二方面提供一种智能语音识别处理系统,包括:
语音采集单元,用于采集多人发出的混合语音指令,从中提取出多个语音特征信息;
语音筛选单元,用于将多个所述语音特征信息做差异化比对,筛选出其中一个目标语音特征信息;
意图识别单元,用于基于所述目标语音特征信息识别出用户意图,执行对应的操控指令。
优选地,所述语音采集单元包括:
特征提取模块,用于对所述混合语音指令进行特征提取;
语音分离模块,用于根据提取的所述特征进行语音分离,得到所述多个语音特征信息。
优选地,所述语音筛选单元包括:
第一计算模块,用于计算全部所述语音特征信息的差异化均值;
第二计算模块,用于分别每个所述语音特征信息以及所述差异化均值,计算出各所述语音特征信息对应的差异值;
筛选模块,用于筛选出最大差异值对应的所述语音特征信息,定义为目标语音特征信息。
与现有技术相比,本发明提供的智能语音识别处理系统的有益效果与上述技术方案提供的智能语音识别处理方法的有益效果相同,在此不做赘述。
本发明的第三方面提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行上述智能语音识别处理方法的步骤。
与现有技术相比,本发明提供的计算机可读存储介质的有益效果与上述技术方案提供的智能语音识别处理方法的有益效果相同,在此不做赘述。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例一中智能语音识别处理方法的流程示意图;
图2为本发明实施例二中智能语音识别处理系统的结构框图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其它实施例,均属于本发明保护的范围。
实施例一
请参阅图1,本实施例提供一种智能语音识别处理方法,包括:
采集多人发出的混合语音指令,从中提取出多个语音特征信息;将多个语音特征信息做差异化比对,筛选出其中一个目标语音特征信息;基于目标语音特征信息识别出用户意图,执行对应的操控指令。
本实施例提供的智能语音识别处理方法中,通过麦克采集由多人发出的混合语音指令,然后从混合语音指令中提取出多个语音特征信息,然后对多个语音指令的语音特征信息进行差异化对比,并根据差异化对比的结果确定其中的目标语音特征信息,最终基于目标语音特征信息识别出用户意图,执行与用户意图对应的操作。可见,本实施例可以有效解决在多人说话场景下语言识别效果差导致难以准确执行用户下的效果。
上述实施例中,从中提取出多个语音特征信息的方法包括:
对混合语音指令进行特征提取;根据提取的特征进行语音分离,得到多个语音特征信息。具体实施时,可以使用多人语音分离算法将混合语音指令中各个用户的语音特征信息分离。
上述实施例中,将多个语音特征信息做差异化比对,筛选出其中一个目标语音特征信息的方法包括:
计算全部语音特征信息的差异化均值;分别每个语音特征信息以及差异化均值,计算出各语音特征信息对应的差异值;筛选出最大差异值对应的语音特征信息,定义为目标语音特征信息。
具体实施时,可以预先配置语音特征的权重,语音特征包括语速、音色、音调和响度。假设语速为a、音色为b、音调为c、响度为d,混合语音指令中识别出语音特征信息1,语音特征信息2和语音特征信息3,语音特征信息1的语音特征为a1、b1、c1、d1,语音特征信息2的语音特征为a2、b2、c2、d2,语音特征信息3的语音特征为a3、b3、c3、d3,若事先设置的语速a的权重系数为k1、音色b的权重系数为k2,音调c的权重系数为k3,响度d的权重系数为k4,全部所述语音特征信息的差异化均值为a=(a1 a2 a3)/3,b=(b1 b2 b3)/3,c=(c1 c2 c3)/3,d=(d1 d2 d3)/3,然后计算语音特征信息1的差异值x1=k1(a1-a) k2(b1-b) k3(c1-c) k4(d1-d),计算语音特征信息2的差异值x2=k1(a2-a) k2(b2-b) k3(c2-c) k4(d2-d),计算语音特征信息3的差异值x3=k1(a3-a) k2(b3-b) k3(c3-c) k4(d3-d),然后比较x1、x2和x3的绝对值大小,挑选出绝对值最大的定义为目标语音特征信息。
上述实施例中,在基于目标语音特征信息识别出用户意图,并执行与用户意图一致的操控指令之前还包括:
训练语音语料知识库,语音语料知识库包括多个语音特征信息和与语音特征信息对应的意图类别;分别对每个语音特征信息进行向量化计算,得到每个语音特征信息的向量;对每个语音特征信息的向量及对应的意图类别进行分类模型训练,获取意图分类模型;从语音语料知识库中获取关键词,对关键词进行训练构建词向量模型。
具体实施时,通过人工整理语音语料,得到针对智能设备操控的各种语音语料,然后对应的在每个语音语料上标注意图类别,建立包括语音特征信息和用户意图的语音语料知识库;接着将语音语料知识库中的各语音语料向量化计算并利用svm训练模型对其进行分类模型训练,得到意图分类模型,通过意图分类模型匹配用户当前语音语料向量与语音语料知识库中的语音语料向量,得到用户当前意图,但是,在实际操作中由于人工整理的语音语料以及标注的意图类别数据量有限,而用户的语音语料形式又多种多样,这样就会导致用户换句不换意时,意图分类模型就会因匹配不成功而输出两种截然不同的用户意图,从而降低了对用户意图识别的准确性,因此,为了避免上述情况的发生,本实施例通过构建词向量模型,将匹配不成功的当前语音语料向量中的0项词替换成与词向量模型中最相似的词,进而利用上述意图分类模型根据替换后的问句向量得到当前问句的用户意图。
具体地,对目标语音特征信息进行预处理和文本处理以提取问句中的多个关键词;计算各关键词的tf-idf值,生成问句向量。
其中,计算关键词tf-idf值的方法包括:计算关键词在目标语音特征知识库中出现的频率,得到词频tf;将语音特征知识库中包含关键词目标语音特征信息的数量除以语音特征知识库中语音特征信息的总数量,得到的商取对数得到逆向文件频率idf;词频tf乘以逆向文件频率idf得到关键词的tf-idf值。
文本处理是指在预处理后,对目标语音特征信息进行敏感词过滤,去停用词、文本纠错、分词处理中的一种或多种,得到目标语音特征信息中的多个关键词,对于文本处理可采用viterbi方法、hmm方法和crf方法中的一种或多种。
本实施中从语音特征知识库中获取关键词,并对关键词进行训练得到词向量模型的方法为:提取语音特征知识库各语音特征信息中的关键词,得到关键词集合;使用word2vec对关键词集合进行训练得到词向量模型。
本实施例中对目标语音特征信息进行向量化计算得到目标语音特征信息向量,利用词向量模型将语音特征信息向量中的0项词替换成与词向量模型中最相似的词的方法包括:
1、获取用户目标语音特征信息,对目标语音特征信息进行预处理和文本处理提取多个关键词;
2、计算各关键词的tf-idf值,得到目标语音特征信息向量;
3、使用词向量模型搜寻目标语音特征信息向量中的0项词,以及匹配词向量模型中与0项词词义最接近的相似词;
4、将相似词乘以cosine相似度替换0项词,所述0项词为在目标语音特征信息中出现而未在词向量模型中出现的关键词。
上述实施例中,执行对应的操控指令之前还包括:根据识别出的用户意图,结合获取的用户动作指令,生成对应的操控指令。例如,智能设备可通过用户意图获取一部分操作指令,通过用户动作指令获取另一部分操作指令,让后将这两部分操作指令整合成最终的针对智能设备的操控指令。例如,用户通过目标语音特征信息发出“播放音乐”,然后通过肢体动作“手指指向智能音箱”,最终得到的操控指令为“播放智能音箱中的音乐”。再例如,在相机开启之后,先接收到用户触发的动作“手摆出‘v’的姿势”,对其进行识别,得到识别结果;之后再接收到用户发送的语音指令“拍照”,经用户意图的识别检测,确认需要进行拍照处理,从而实现了快速“拍照”操作。
实施例二
请参阅图2,本实施例提供一种智能语音识别处理系统,包括:
语音采集单元,用于采集多人发出的混合语音指令,从中提取出多个语音特征信息;
语音筛选单元,用于将多个所述语音特征信息做差异化比对,筛选出其中一个目标语音特征信息;
意图识别单元,用于基于所述目标语音特征信息识别出用户意图,执行对应的操控指令。
优选地,所述语音采集单元包括:
特征提取模块,用于对所述混合语音指令进行特征提取;
语音分离模块,用于根据提取的所述特征进行语音分离,得到所述多个语音特征信息。
优选地,所述语音筛选单元包括:
第一计算模块,用于计算全部所述语音特征信息的差异化均值;
第二计算模块,用于分别每个所述语音特征信息以及所述差异化均值,计算出各所述语音特征信息对应的差异值;
筛选模块,用于筛选出最大差异值对应的所述语音特征信息,定义为目标语音特征信息。
与现有技术相比,本发明实施例提供的智能语音识别处理系统的有益效果与上述实施例一提供的智能语音识别处理方法的有益效果相同,在此不做赘述。
实施例三
本实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行上述智能语音识别处理优化方法的步骤。
与现有技术相比,本实施例提供的计算机可读存储介质的有益效果与上述技术方案提供的智能语音识别处理方法的有益效果相同,在此不做赘述。
本领域普通技术人员可以理解,实现上述发明方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,上述程序可以存储于计算机可读取存储介质中,该程序在执行时,包括上述实施例方法的各步骤,而的存储介质可以是:rom/ram、磁碟、光盘、存储卡等。
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

