本发明涉及氢氧混合气体发生器技术领域,具体涉及应用于氢氧混合气体发生器语音控制的声音处理方法。
背景技术:
氢氧混合气体发生器作为医院辅助治疗新冠病患的设备,可以对该氢氧混合气体发生器进行改进应用于家庭,作为家庭健康养生设备,更方便的服务于用户,为了便于用户对其进行控制,可以采用语音控制的方式控制氢氧混合气体发生器的各种功能,为用户提供更方便的操作方式。
但是,在实现语音控制氢氧混合气体发生器时,存在一个显著的问题,即氢氧混合气体发生器使用者常处于身体虚弱状态,发出语音指令声音比较小,在环境嘈杂的情况下容易造成无法进行语音识别的问题,因此亟需一种方案可以解决上述技术问题。
技术实现要素:
本发明提供一种应用于氢氧混合气体发生器语音控制的声音处理方法,用以解决在环境嘈杂的情况下容易造成无法进行语音识别的问题。
本发明提供一种应用于氢氧混合气体发生器语音控制的声音处理方法,该方法包括:
获取针对氢氧混合气体发生器的语音信号;
对所述语音信号采用维纳滤波算法进行降噪处理;
将降噪处理后的语音频谱输入至语音增强模型,基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理,获得增强后的语音信号;
对增强后的语音信号进行信号放大处理,获得放大的语音信号;
将放大的语音信号输入至氢氧混合气体发生器的语音控制的识别系统中进行语音信号的识别。
可选的,所述对所述语音信号采用维纳滤波算法进行降噪处理之前,包括:
对所述语音信号进行分帧、加窗及频域变换预处理;
将经过预处理后的语音信号输入至维纳滤波器中进行降噪处理。
可选的,所述基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理,包括:
确定语音频谱的先验信噪比参数的估计;
基于所述先验信噪比参数的估计去除音乐噪声。
可选的,所述确定语音频谱的先验信噪比参数的估计,包括:
基于直接判决算法或两步噪声消除算法确定语音频谱的先验信噪比参数的估计。
可选的,所述两步噪声消除算法包括:
基于直接判决算法确定语音频谱的第一先验信噪比;
结合高斯统计模型及第一先验信噪比确定纯净语音短时谱能量;
根据所述确定的纯净语音短时谱能量确定语音频谱的第二先验信噪比;
将所述第二先验信噪比设定为先验信噪比参数的估计。
可选的,所述结合高斯统计模型及第一先验信噪比确定纯净语音短时谱能量,包括:
基于高斯统计模型确定纯净语音分量的幅度及相位;
确定纯净语音分量的幅度估计误差;
基于最小均方差确定贝叶斯风险函数;
基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计;
将所述幅度平方的估计设定为纯净语音短时谱能量。
可选的,所述基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计中,幅度平方的估计采用如下公式表示:
其中,
可选的,根据所述确定的纯净语音短时谱能量确定语音频谱的第二先验信噪比,所述第二先验信噪比公式如下:
其中,snr1(m,k)为第一先验信噪比,snr2为第二先验信噪比,ym,k为第m帧时刻第k个谱分量,λv(m,k)为噪声分量方差。
可选的,所述将所述第二先验信噪比设定为先验信噪比参数的估计之后,包括:
根据所述第二先验信噪估计确定与所述频域语音信号对应的声学场景;
根据所述声学场景对语音增强模型进行参数调整;
根据调整后的语音增强模型对所述频域语音信号进行语音增强。
可选的,所述对增强后的语音信号进行信号放大处理,获得放大的语音信号,包括:
将增强后的语音信号输入至由三极管构成的放大电路的输入端;
经由所述放大电路输出放大后的语音信号。
本发明提供应用于氢氧混合气体发生器语音控制的声音处理方法,采用本发明提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
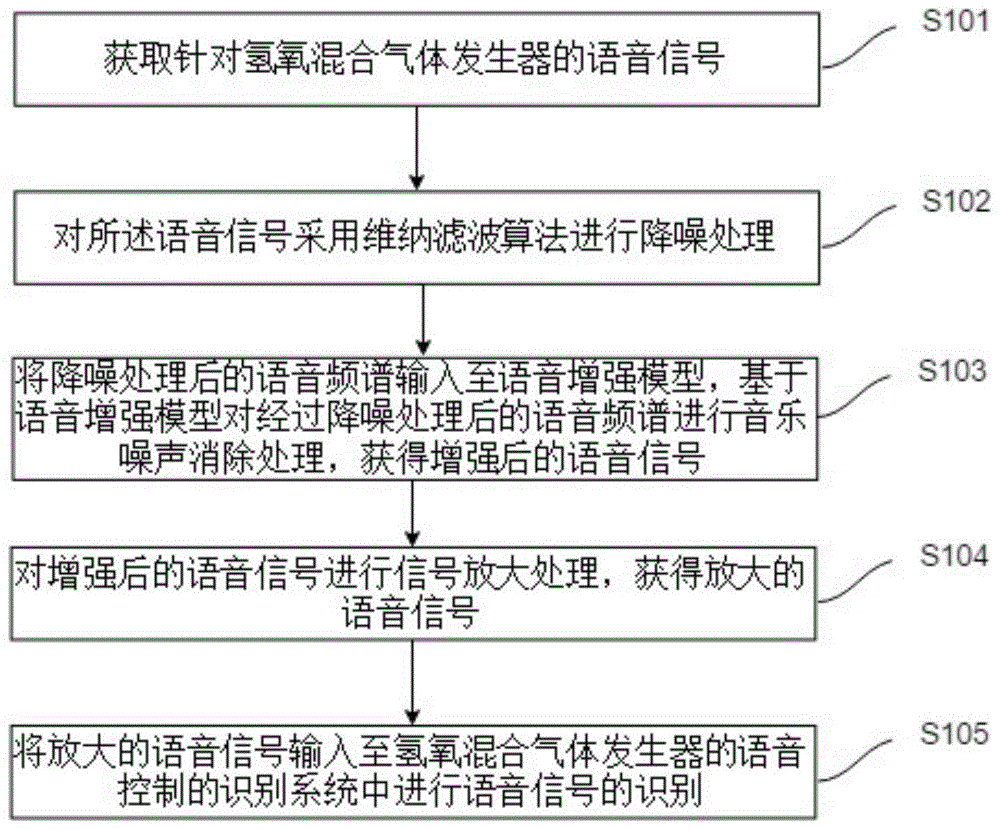
图1为本发明实施例中应用于氢氧混合气体发生器语音控制的声音处理方法的流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:
本发明实施例提供了应用于氢氧混合气体发生器语音控制的声音处理方法,图1为本发明实施例中应用于氢氧混合气体发生器语音控制的声音处理方法的流程图,请参照图1,该方法包括以下步骤:
步骤s101,获取针对氢氧混合气体发生器的语音信号;
步骤s102,对所述语音信号采用维纳滤波算法进行降噪处理;
步骤s103,将降噪处理后的语音频谱输入至语音增强模型,基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理,获得增强后的语音信号;
步骤s104,对增强后的语音信号进行信号放大处理,获得放大的语音信号;
步骤s105,将放大的语音信号输入至氢氧混合气体发生器的语音控制的识别系统中进行语音信号的识别。
上述技术方案的工作原理为:采用本实施例提供的方案首先对所述语音信号采用维纳滤波算法进行降噪处理,然后再将降噪处理后的语音频谱输入至语音增强模型,基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理,获得增强后的语音信号,最后再对增强后的语音信号进行信号放大处理,获得放大的语音信号,以完成对语音控制系统中语音识别的声音处理,通过对有效的语音信号进行语音增强,保证微弱的语音信号不受环境噪声等的影响,可以很容易被语音识别系统进行识别,进而实现采用语音控制方式对氢氧混合气体发生器的控制。
需要说明的是,氢氧混合气体发生器作为医院辅助治疗新冠病患的设备,可以对该氢氧混合气体发生器进行改进应用于家庭,作为家庭健康养生设备,更方便的服务于用户,为了便于用户对其进行控制,可以采用语音控制的方式控制氢氧混合气体发生器的各种功能,以为用户提供更方便的操作方式。
所述氢氧混合气体发生器的体积不大,为长方体形状,可以拜访在床头柜上,有输出氢氧混合气体的小软管印出来,夹在耳朵上将出气口伸到口鼻附近使用。
另外,由于对语音频谱进行降噪处理,在降噪的过程中由于对噪声谱进行统计学算法进行降噪处理,会产生一些类似于乐音特性的信号,称之为音乐噪声,而音乐噪声也会影响语音信号的识别,因此,为了进一步消除音乐噪声,采用语音增强模型对音乐噪声进行进一步的消除,以更好的抑制噪声,保证语音识别时接收的语音信号的质量。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例2:
在实施例1的基础上,所述对所述语音信号采用维纳滤波算法进行降噪处理之前,包括:
对所述语音信号进行分帧、加窗及频域变换预处理;
将经过预处理后的语音信号输入至维纳滤波器中进行降噪处理。
上述技术方案的工作原理为:本实施例采用的方案是在对所述语音信号采用维纳滤波算法进行降噪处理之前,对所述语音信号进行分帧、加窗及频域变换预处理,将经过预处理后的语音信号输入至维纳滤波器中进行降噪处理。通过对语音信号进行分帧加窗处理,并且进行傅里叶变换将语音信号由时域转换为频域,为语音信号的降噪处理提供前提条件,保证语音信号输入至维纳滤波器中进行降噪处理。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例3:
在实施例1的基础上,所述基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理,包括:
确定语音频谱的先验信噪比参数的估计;
基于所述先验信噪比参数的估计去除音乐噪声。
上述技术方案的工作原理为:本实施例采用的方案是基于语音增强模型对经过降噪处理后的语音频谱进行音乐噪声消除处理的过程,具体是通过确定语音频谱的先验信噪比参数的估计,然后基于所述先验信噪比参数的估计去除音乐噪声。由于先验信噪比在去除噪声的过程中起着重大作用,因此,需要对先验信噪比进行确定,其优选的计算过程可通过后续的实施例进行详细的介绍,在此不再赘述。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例4:
在实施例3的基础上,所述确定语音频谱的先验信噪比参数的估计,包括:
基于直接判决算法或两步噪声消除算法确定语音频谱的先验信噪比参数的估计。
上述技术方案的工作原理为:本实施例采用的方案是基于直接判决算法或两步噪声消除算法确定语音频谱的先验信噪比参数的估计,通过直接判决算法可以高效的抑制音乐噪声,另外通过两步噪声消除算法可以更好的抑制音乐噪声。
所述两步噪声消除算法是在直接判决算法上的改进,通过m 1帧的先验信噪比确定当前帧的先验信噪比。不管通过何种算法,最终需要确定的先验信噪比参数的估计,通过确定先验信噪比参数的估计,可以比较精确的抑制音乐噪声。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例5:
在实施例4的基础上,所述两步噪声消除算法包括:
基于直接判决算法确定语音频谱的第一先验信噪比;
结合高斯统计模型及第一先验信噪比确定纯净语音短时谱能量;
根据所述确定的纯净语音短时谱能量确定语音频谱的第二先验信噪比;
将所述第二先验信噪比设定为先验信噪比参数的估计。
上述技术方案的工作原理为:本实施例采用的方案是两步噪声消除算法的具体步骤,首先基于直接判决算法确定语音频谱的第一先验信噪比,然后,结合高斯统计模型及第一先验信噪比确定纯净语音短时谱能量,其次,根据所述确定的纯净语音短时谱能量确定语音频谱的第二先验信噪比,最后将所述第二先验信噪比设定为先验信噪比参数的估计。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例6:
在实施例5的基础上,所述结合高斯统计模型及第一先验信噪比确定纯净语音短时谱能量,包括:
基于高斯统计模型确定纯净语音分量的幅度及相位;
确定纯净语音分量的幅度估计误差;
基于最小均方差确定贝叶斯风险函数;
基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计;
将所述幅度平方的估计设定为纯净语音短时谱能量。
上述技术方案的工作原理为:本实施例采用的方案是在实施例5的基础上的优化,基于高斯统计模型确定纯净语音分量的幅度及相位,确定纯净语音分量的幅度估计误差,基于最小均方差确定贝叶斯风险函数,基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计,将所述幅度平方的估计设定为纯净语音短时谱能量。通过确定纯净语音短时谱能量即可进一步的确定先验信噪比。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例7:
在实施例6的基础上,所述基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计中,幅度平方的估计采用如下公式表示:
其中,
上述技术方案的工作原理为:本实施例采用的方案是基于高斯统计模型确定纯净语音分量的幅度及相位,确定纯净语音分量的幅度估计误差,基于最小均方差确定贝叶斯风险函数,基于所述贝叶斯风险函数确定纯净语音分量的幅度平方的估计,将所述幅度平方的估计设定为纯净语音短时谱能量,在确定纯净语音分量的幅度平方的估计的过程,采用上述公式通过确定纯净语音分量的幅度及相位,进一步根据密度分布函数确定纯净语音分量的幅度平方的估计,而纯净语音分量的幅度平方的估计也就是纯净语音短时谱能量。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例8:
在实施例5的基础上,根据所述确定的纯净语音短时谱能量确定语音频谱的第二先验信噪比,所述第二先验信噪比公式如下:
其中,snr1(m,k)为第一先验信噪比,snr2为第二先验信噪比,ym,k为第m帧时刻第k个谱分量,λv(m,k)为噪声分量方差。
上述技术方案的工作原理为:本实施例采用的方案是确定第二先验信噪的过程,通过上述公式可以看出,第二先验信噪比仅与第一先验信噪比以及第m帧时刻第k个谱分量的平方以及噪声分量方差有关,而与增益因子无关,因此,避免了算法对增益因子的依赖。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例9:
在实施例5的基础上,所述将所述第二先验信噪比设定为先验信噪比参数的估计之后,包括:
根据所述第二先验信噪估计确定与所述频域语音信号对应的声学场景;
根据所述声学场景对语音增强模型进行参数调整;
根据调整后的语音增强模型对所述频域语音信号进行语音增强。
上述技术方案的工作原理为:本实施例采用的方案是将所述第二先验信噪比设定为先验信噪比参数的估计之后,根据所述第二先验信噪估计确定与所述频域语音信号对应的声学场景,根据所述声学场景对语音增强模型进行参数调整,根据调整后的语音增强模型对所述频域语音信号进行语音增强。通过对声学场景进行分类确定,以更精确的方式实现语音增强。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
实施例10:
在实施例1的基础上,所述对增强后的语音信号进行信号放大处理,获得放大的语音信号,包括:
将增强后的语音信号输入至由三极管构成的放大电路的输入端;
经由所述放大电路输出放大后的语音信号。
上述技术方案的工作原理为:本实施例采用的方案是对增强后的语音信号进行信号放大处理,获得放大的语音信号的过程,具体的将增强后的语音信号输入至由三极管构成的放大电路的输入端,经由所述放大电路输出放大后的语音信号。通过放大电路实现语音信号的放大,由于通过之前步骤已经对语音信号中的噪声进行了最大程度的抑制,因此,通过对降噪和语音增强后的信号进行放大处理,放大的是用户的语音信号,由于噪声信号得到有效的抑制,放大信号主要针对的用户有效的语音信号,通过对语音信号的放大,进一步增加语音识别的效率及准确性。
上述技术方案的有益效果为:采用本实施例提供的方案通过对语音信号在频域上进行降噪处理以及语音增强处理,保证语音信号的质量,在此基础上再对降噪和语音增强处理后的信号进行放大,使输入至语音识别系统的语音信号的质量达到最佳,以提高语音识别的效率和准确性,并且可以解决氢氧混合气体发生器在环境嘈杂的情况下容易造成无法进行语音识别的问题。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

