本发明涉及语音识别技术领域,尤其涉及一种广播音频的语种识别方法、装置、设备及存储介质。
背景技术:
随着我国对外多语种广播的日益丰富和发展,广播监测也得到蓬勃发展。广播监测的一项重要业务就是中短波广播的语种识别,即通过对广播音频的语种进行判断后,与计划播出的语言进行比对,进而判断是否存在错播,从而保证安全播出。然而,中短波广播信道极易受到自然和人为的干扰,严重降低广播内容的信噪比,给语种识别任务带来巨大挑战。
在语种识别方面,现有语种识别技术研究过程中采用的语料为信噪比较高的公开数据集,采用的主要为音频增强的方式,降低噪音对识别结果的影响。
由于面向噪声环境的语种识别研究采用的噪声也多为加性噪声。广播音频噪声类型复杂,噪声变化不平稳的特点,主要噪声为由信道干扰产生的卷性噪声。因此目前存在的语种识别方法难以胜任现阶段广播音频的语种识别。音频增强的方式在应对以卷性噪声为主的广播音频时难以起到显著的作用,同时也会带来语音的失真问题,影响语种识别结果的准确性。
技术实现要素:
本发明提供一种广播音频的语种识别方法、装置、设备及存储介质,用以解决现有技术中广播音频语种识别准确性低的缺陷,实现降低噪音对识别结果的影响,提高语种识别的准确性。
本发明提供一种广播音频的语种识别方法,包括:
根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据;
按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据;
将所述第一音频数据输入至语种识别模型中,得到语种识别结果;
其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
根据本发明提供一种广播音频的语种识别方法,所述根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据,包括:
提取所述待检测广播音频数据的数据部分;
根据第一采样率对待检测广播音频数据的数据部分进行重采样,得到第一采样音频数据;
根据第二采样率对待检测广播音频数据的数据部分进行重采样,得到第二采样音频数据。
根据本发明提供一种广播音频的语种识别方法,所述按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据,包括:
顺序拼接所述第一采样音频数据、所述待检测广播音频数据的数据部分和所述第二采样音频数据,得到拼接后的音频;
将所述拼接后的音频前加入头文件,得到所述第一音频数据;
其中,所述头文件中记录的采样率与所述待检测广播音频数据的采样率一致。
根据本发明提供一种广播音频的语种识别方法,将所述第一音频数据输入至语种识别模型中,得到语种识别结果,包括:
将所述第一音频数据输入至所述声学模型中,得到第一语种识别结果;
将所述第一音频数据输入至所述韵律模型中,得到第二语种识别结果;
将所述第一语种识别结果和第二语种识别结果输入至高斯混合分类器,得到所述待检测广播音频数据的语种识别结果。
根据本发明提供一种广播音频的语种识别方法,还包括:训练得到所述语种识别模型;
其中,所述训练得到所述语种识别模型包括:
获取已经完成分类的不同语种的原始广播音频数据,并将所述已经完成分类的不同语种的原始广播音频数据划分为训练集和开发集;
对所述训练集进行预处理,得到第一音频数据样本,其中,所述预处理包括:重采样和拼接;
根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对gmm-ubm模型进行训练,保存训练完成时的所述gmm-ubm模型的参数,得到所述声学模型;
根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对svm模型进行训练,保存训练完成时的所述svm模型的参数,得到所述韵律模型;
对所述开发集进行所述预处理,得到第二音频数据样本;
将所述第二音频数据样本输入至所述声学模型和韵律模型,得到第三语种识别结果和第四语种识别结果;
根据所述第三语种识别结果和第四语种识别结果以及所述第二音频数据样本对应的语种标签对gbe模型进行训练,保存训练完成时的所述gbe模型的参数,得到所述高斯混合分类器。
根据本发明提供一种广播音频的语种识别方法,所述根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对gmm-ubm模型进行训练,保存训练完成时的所述gmm-ubm模型的参数,得到所述声学模型,包括:
对所述第一音频数据样本进行移动差分倒谱特征提取,得到所述第一音频数据样本对应的sdc特征向量;
将所述sdc特征向量输入至ubm模型,通过k均值聚类与em迭代算法训练所述ubm模型,训练结束后,得到训练完成的ubm模型;
根据贝叶斯自适应算法,从所述训练完成的ubm模型中自适应得到每个语种的gmm模型。
根据本发明提供一种广播音频的语种识别方法,所述根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对svm模型进行训练,保存训练完成时的所述svm模型的参数,得到所述韵律模型,包括:
对所述第一音频数据样本进行韵律特征提取,得到所述第一音频数据对应的四维韵律特征向量;
通过多项式映射函数将所述四维韵律特征向量映射成多项式基向量;
针对所述原始广播音频数据中的每一语种,将所述多项式基向量输入至广义线性判别序列glds模块得到具有分性的训练样本,将当前语种的所述训练样本作为正样本,把非所述当前语种的训练样本作为负样本,进行svm训练得到所述当前语种的支持向量;
对每个语种的支持向量进行线性变换得到每个语种的被压缩的韵律模型,其中,所有语种的被压缩的韵律模型构成所述韵律模型。
本发明还提供一种广播音频的语种识别装置,包括:
第一预处理模块,用于根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据;
第二预处理模块,用于按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据;
语种识别模块,用于将所述第一音频数据输入至语种识别模型中,得到语种识别结果;
其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
本发明还提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现所述广播音频的语种识别方法的步骤。
本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述广播音频的语种识别方法的步骤。
本发明提供的广播音频的语种识别方法、装置、设备及存储介质,通过重采样和音频拼接技术对待检测广播音频数据进行预处理得到第一音频数据,再将所述第一音频数据输入到语种识别模型中,得到语种识别结果。预处理过程中,改变了音频的语速和语调,对重采样后的音频进行拼接后得到的音频相较于待识别音频增加了音频的声学与韵律特征,对待识别音频进行了特征增强,降低了噪音对音频的特征掩蔽。语种识别模型包括声学模型、韵律模型和高斯混合分类器,通过混合高斯分类器将基于声学模型提取检测广播音频数据的声学特征得到的第一语种识别结果和基于韵律模型提取所述待检测广播音频数据的韵律特征得到的第二语种识别结果在得分层次上进行融合,得到语种识别结果,提高了语种识别的准确度。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明提供的广播音频的语种识别方法的流程示意图之一;
图2是本发明提供的广播音频的语种识别方法的流程示意图之二;
图3是本发明提供的广播音频的语种识别方法的流程示意图之三;
图4是本发明提供的广播音频的语种识别方法的流程示意图之四;
图5是本发明提供的广播音频的语种识别方法的流程示意图之五;
图6是本发明提供的广播音频的语种识别装置的结构示意图;
图7是本发明提供的电子设备的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
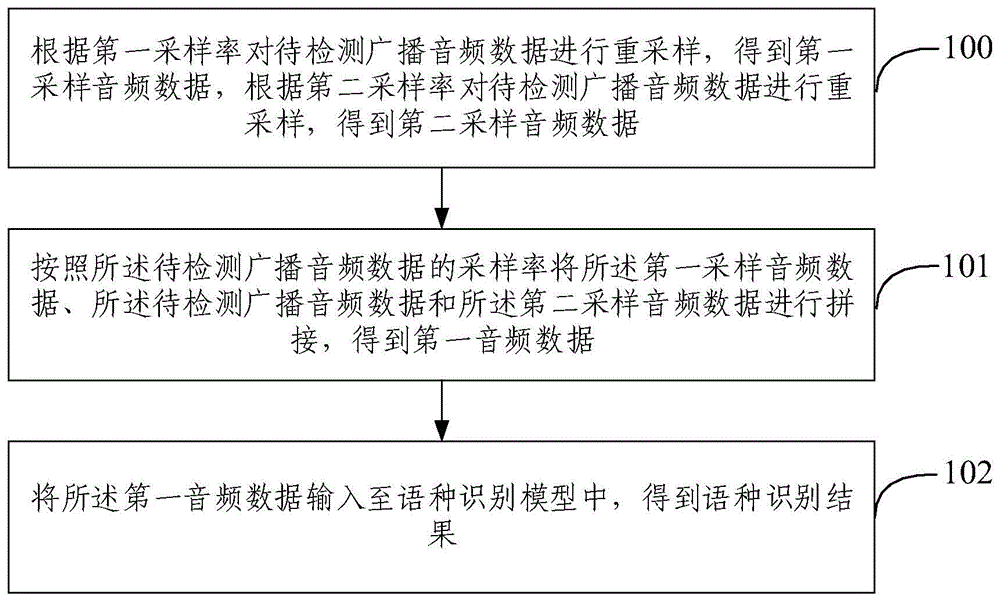
图1为本发明实施例的广播音频识别方法的流程图之一,如图1所示,包括以下步骤:
步骤100、根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据。
其中,音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。在当今的主流采集卡上,采样频率一般共分为11025hz、22050hz、24000hz、44100hz、48000hz五个等级,11025hz能达到am调幅广播的声音品质。作为优选,本实施例中待检测广播音频数据的采样率为11025hz,对于其他采样率的广播音频数据,本方案同样适用。
第一采样率可以是预设的采样频率,也可以是基于预设的第一采样率与待识别广播音频数据的采样率的比值计算得到的采样频率。
例如,预设的第一采样率与待识别广播音频数据的采样率的比值为0.8。读取待检测广播音频数据,将待检测广播音频数据的数据部分保存至第一采样文件,并记录待检测广播音频数据的采样率,基于第一采样率与待识别广播音频数据的采样率的比值,可以得到第一采样率为8820hz。根据第一采样率对待检测广播音频数据的数据部分进行重采样,每秒钟的采样次数是待检测广播音频数据的0.8倍,重采样的结果为第一采样音频数据,并将第一采样音频数据保存至所述第一采样文件。
同理,第二采样率可以是预设的采样频率,也可以是基于预设的第二采样率与待识别广播音频数据的采样率的比值计算得到的采样频率,例如,预设的第二采样率与待识别广播音频数据的采样率的比值为1.2,基于该比值,可以得到第二采样率为13230hz。读取待检测广播音频数据,将待检测广播音频数据的数据部分保存至第二采样文件,根据第二采样率对待检测广播音频数据的数据部分进行重采样,每秒钟的采样次数是待检测广播音频数据的1.2倍,重采样的结果为第二采样音频数据,并将第二采样音频数据保存至第二采样文件。
步骤101、按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据。
具体地,从第一采样文件中提取第一采样音频数据,从第二采样文件中提取第二采样音频数据,将第一采样音频数据、待检测广播音频的数据部分和第一采样音频数据拼接为第一音频,按照待检测广播音频数据的采样率将第一音频保存至第一音频文件中,保证拼接得到的音频文件的采样间隔与待检测广播音频数据一致,得到第一音频数据。
拼接后得到的第一音频数据相较于待检测广播音频数据,具有丰富的语种区分性。
步骤102、将所述第一音频数据输入至语种识别模型中,得到语种识别结果。
其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
具体地,根据预设的帧长和帧移,可以确定第一音频数据的多个分析帧,例如,预设的帧长为20ms,预设的帧移为10ms。对于每个分析帧,可以计算出该分析帧的移动差分倒谱特征向量。计算公式如下:
sdc(t)=[δc(t)δc(t p)…δc(t (k-1)p)]
其中δc(t)为t时刻的一阶差分倒谱特征向量,p为帧移,k为组成sdc特征的连接块数,连接块是指每帧的一阶差分倒谱特征。将第一音频数据的全部分析帧的移动差分倒谱特征向量组合,可得到第一音频数据的声学特征。根据所得到的声学特征,声学模型输出第一语种识别结果。
对于每一个分析帧,可以确定一个短时自相关函数。短时自相关函数如下:
其中窗长的范围为[0,n-1],k为自相关延迟时间,n为该帧的起始时刻,m为相对起始时刻偏移的时刻,w(m)为m时刻窗函数的值。根据自相关函数第一个峰值的位置估计出基音频率,从而得到当前分析帧的基音频率。按照时间顺序组合全部分析帧的基音频率,得到第一音频数据的韵律特征。根据所得到的韵律特征,韵律模型输出第二语种识别结果。
第一语种识别结果和第二语种识别结果为待检测广播音频数据在各个语种上的得分组成的得分向量。至此,语种识别模型根据输入的第一音频数据,得到了第一语种识别结果和第二语种识别结果两个得分向量。
接着,将第一语种识别结果和第二语种识别结果输入至语种识别模型中的高斯混合分类器,在得分层次上将第一语种识别结果与第二语种识别结果进行融合,得到待检测广播音频数据的语种识别结果。
本发明实施例提供的广播音频的语种识别方法,基于重采样和音频拼接技术对待检测音频进行预处理得到第一音频数据,再将所述第一音频数据输入到语种识别模型中,得到语种识别结果。预处理过程中,改变了音频的语速和语调,对重采样后的音频进行拼接后得到的音频相较于待识别音频增加了音频的声学与韵律特征,对待识别音频进行了特征增强,降低了噪声对语种识别特征的掩蔽。语种识别模型包括声学模型、韵律模型和高斯混合分类器,通过混合高斯分类器将韵律模型和声学模型输出的得分向量在得分层次上进行融合,得到语种识别结果,提高了语种识别的准确度。
图2为本申请实施例提供的广播音频识别方法的流程图之二,如图2所示,在一个实施例中,步骤100包括以下子步骤:
步骤200、提取所述待检测广播音频数据的数据部分。
待检测广播音频数据包括头文件和数据部分,具体来说,头文件是一段承担一定任务的数据,其中包括音频的采样率信息,一般都在开头的部分,而数据部分记录了广播音频的具体内容。本方案中,提取音频文件的音频数据部分,保存为新的文件,进而根据预设的采样率对新的文件进行重采样,并记录待检测广播音频数据的采样率。
步骤201、根据第一采样率对待检测广播音频数据的数据部分进行重采样,得到第一采样音频数据。
根据步骤200中记录的待检测广播音频数据的采样率,得到第一采样率,根据第一采样率对待检测广播音频数据的数据部分进行重采样,本次重采样过程每秒钟的采样次数是待检测广播音频数据的0.8倍,重采样的结果为第一采样音频数据,并将第一采样音频数据保存至第一采样文件。
步骤202、根据第二采样率对待检测广播音频数据的数据部分进行重采样,得到第二采样音频数据。
根据步骤200中记录的待检测广播音频数据的采样率,得到第二采样率,根据第二采样率对待检测广播音频数据的数据部分进行重采样,每秒钟的采样次数是待检测广播音频数据的1.2倍,重采样的结果为第二采样音频数据,并将第二采样音频数据保存至所述第二采样文件。
本发明实施例通过提取待检测广播音频数据的数据部分,对待检测广播音频数据进行基于第一采样率和第二采样率的重采样,改变了音频的语速和语调,在此基础上对重采样的结果进行拼接和语种识别,提高了语种识别的准确性。
图3为本申请实施例提供的广播音频识别方法的流程图之三,如图3所示,在一个实施例中,步骤101包括以下子步骤:
步骤300、顺序拼接所述第一采样音频数据、所述待检测广播音频数据的数据部分和所述第二采样音频数据,得到拼接后的音频。
本发明的预处理过程是一个增强语种区分性特征的过程,将重采样所得的音频数据与待检测音频数据,按照第一采样音频数据、待检测广播音频数据的数据部分和第二采样音频数据的顺序进行拼接,得到拼接后的音频。拼接后的音频包括改变了语音的语调和语速的采样音频数据和待检测广播音频数据。
步骤301、将所述拼接后的音频前加入头文件,得到所述第一音频数据;其中,所述头文件中记录的采样率与所述待检测广播音频数据的采样率一致。
采样率是指录音设备在一秒钟内对声音信号的采样次数,一个固定的采样率对应着一个固定的采样间隔,以不同的采样率对待检测广播音频数据进行重采样后,每秒钟采样的次数发生变化,即第一采样音频数据和第二采样音频数据的采样间隔发生变化。在拼接后的音频前加入头文件,且头文件中记录的采样率与待检测广播音频数据的采样率一致,将导致第一采样音频数据和第二采样音频数据在被语种识别模型识别的过程中,以待检测广播音频数据的采样率进行识别,第一采样音频数据和第二采样音频数据的语音时长被拉长或者缩短。
下面以第一采样率为待检测广播音频数据的0.8倍为例进行说明。第一采样率为待检测广播音频数据的0.8倍,即第一采样音频数据每秒钟的采样次数是待检测广播音频数据的0.8倍,第一采样音频数据的采样间隔是待检测广播音频数据的1.25倍。顺序拼接第一采样音频数据、待检测广播音频数据的数据部分和第二采样音频数据,得到拼接后的音频,将拼接后的音频前加入头文件,得到第一音频数据。第一音频数据的第一采样音频数据部分,在识别的过程中将被按照待检测广播音频数据的采样率进行识别,即识别过程中将第一采样音频数据的采样间隔缩短为待检测广播音频数据采样间隔的1倍,第一采样音频数据的音频总时长被缩短为待检测广播音频数据时长的0.8倍,改变了语音的语调和语速。
同理,第二采样音频数据的音频总时长被缩短为待检测广播音频数据时长的1.2倍,改变了语音的语调和语速。
本发明实施例中通过在拼接后的音频前加入头文件,改变了第一采样音频数据和第二采样音频数据语音的语调和语速,增加了音频的声学与韵律特征,增加了语种识别的准确性。
图4为本申请实施例提供的广播音频识别方法的流程图之四,如图4所示,在一个实施例中,步骤102包括以下子步骤:
步骤400、将所述第一音频数据输入至所述声学模型中,得到第一语种识别结果。
具体地,根据预设的帧长和帧移,可以确定第一音频数据的多个分析帧,例如,预设的帧长为20ms,预设的帧移为10ms。对于每个分析帧,可以计算出该分析帧的移动差分倒谱特征向量。计算公式如下:
sdc(t)=[δc(t)δc(t p)…δc(t (k-1)p)]
其中δc(t)为t时刻的一阶差分倒谱特征向量,p为帧移,k为组成sdc特征的连接块数,“连接块”是指每帧的一阶差分倒谱特征。将第一音频数据的全部分析帧的移动差分倒谱特征向量组合,可得到第一音频数据的声学特征。根据所得到的声学特征,声学模型输出第一语种识别结果。第一语种识别结果为待检测广播音频数据在预设的各个语种上的得分组成的得分向量。
步骤401、将所述第一音频数据输入至所述韵律模型中,得到第二语种识别结果。
具体地,对于每一个分析帧,可以确定一个短时自相关函数。本发明实施例中,预设的帧长为20ms,预设的帧移为10ms。短时自相关函数如下:
其中窗长的范围为[0,n-1],k为自相关延迟时间,n为该帧的起始时刻,m为相对起始时刻偏移的时刻w(m)为m时刻窗函数的值。根据自相关函数第一个峰值的位置估计出基音频率,从而得到当前分析帧的基音频率。按照时间顺序组合全部分析帧的基音频率,得到第一音频数据的韵律特征。根据所得到的韵律特征,韵律模型输出第二语种识别结果。第二语种识别结果为待检测广播音频数据在预设的各个语种上的得分组成的得分向量。
步骤402、将所述第一语种识别结果和第二语种识别结果输入至高斯混合分类器,得到所述待检测广播音频数据的语种识别结果。
具体地,将步骤400中得到的第一语种识别结果和步骤401得到的第二语种识别结果输入至高斯混合分类器,高斯混合分类器在得分层次上将第一语种识别结果和第二语种识别结果进行混合,得到待检测广播音频数据的语种识别结果。
本发明实施例中高斯混合分类器将韵律模型和声学模型输出的得分向量在得分层次上进行融合,得到语种识别结果,提高了语种识别的准确度。
在一个实施例中,还包括训练得到所述语种识别模型;
图5为本申请实施例提供的广播音频识别方法的流程图之五,如图5所示,本申请实施例提供的广播音频识别方法还包括训练得到所述语种识别模型,所述训练得到所述语种识别模型包括以下子步骤:
步骤500、获取已经完成分类的不同语种的原始广播音频数据,并将所述已经完成分类的不同语种的原始广播音频数据划分为训练集和开发集。
人类能够听到的所有声音都称之为音频,它可能包括噪音等。采集到的原始的广播音频由于存在噪声,会对原始音频的掩蔽,使识别过程中获取到的特征的语种区分性不强,可用于语种识别的特征较少,降低语种识别的准确度。本步骤中获取的不同语种的原始广播音频数据均存在噪声。
中短波是指波长为200m~50m,频率为1500khz~6000khz的无线电波通过地波和天波传播,用于调幅am无线电广播、电报和通信。由于中短波广播信道极易受到自然和人为的干扰,严重降低广播内容的信噪比,给语种识别任务带来巨大挑战。本申请可对广播音频进行语种识别,尤其可对中短波广播音频进行语种识别。
具体地,为了基于机器学习的方法实现对广播音频的语种分类的目的,本发明实施例中准备大量已经完成分类的不同语种的广播音频。包括以下33个语种:阿拉伯语、孟加拉语、缅甸语、柬埔寨语、粤语、潮州话、捷克语、英语、世界语、波斯语、法语、德语、豪萨语、印第语、匈牙利语、印度尼西亚语、意大利语、日语、朝鲜语、老挝语、马来西亚语、普通话、蒙古语、尼泊尔语、俄语、西班牙语、斯瓦西里语、泰米尔语、泰语、乌尔都语、维吾尔语和厦门语。音频的采样率为11025hz、单声道、采样位数为16位,音频保存的文件格式为wav文件。将这些已知语种的音频数据按1:5的比例分为开发集与训练集。训练集和开发集中的音频数据均包含33个语种的音频数据。本实施例仅仅是示意性的,本方案同样适用于其他语种的训练和识别。
步骤501、对所述训练集进行预处理,得到第一音频数据样本,其中,所述预处理包括:重采样和拼接。
本步骤中的重采样和拼接过程与上述实施例中的重采样和拼接过程一致,在此不再赘述。
步骤502、根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对gmm-ubm模型进行训练,保存训练完成时的所述gmm-ubm模型的参数,得到所述声学模型。
具体地,对所述第一音频数据样本进行移动差分倒谱特征提取,得到所述第一音频数据样本对应的sdc特征向量;将所述sdc特征向量通过k均值聚类与em迭代算法训练所述ubm模型,训练结束后,得到训练完成的ubm模型;根据贝叶斯自适应算法,从所述训练完成的ubm模型中自适应得到每个语种的gmm模型。
步骤503、根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对svm模型进行训练,保存训练完成时的所述svm模型的参数,得到所述韵律模型。
具体地,对所述第一音频数据样本进行韵律特征提取,得到所述第一音频数据对应的四维韵律特征向量。通过多项式映射函数将所述四维韵律特征向量映射成多项式基向量。针对所述原始广播音频数据中的每一语种,将所述多项式基向量输入至广义线性判别序列glds模块得到具有分性的训练样本,将当前语种的所述训练样本作为正样本,把非所述当前语种的训练样本作为负样本,进行svm训练得到所述当前语种的支持向量。对每个语种的支持向量进行线性变换得到每个语种的被压缩的韵律模型,其中,所有语种的被压缩的韵律模型构成所述韵律模型。
步骤504、对所述开发集进行所述预处理,得到第二音频数据样本,将所述第二音频数据样本输入至所述声学模型和韵律模型,得到第三语种识别结果和第四语种识别结果。
具体地,对所述开发集进行所述预处理,预处理的过程包括重采样和拼接,得到第二音频数据样本。将第二音频数据样本输入至训练完成的gmm-ubm模型中,得到第三语种识别结果,将第二音频数据样本输入至训练完成的svm模型中,得到第四语种识别结果。
步骤505、根据所述第三语种识别结果和第四语种识别结果以及所述第二音频数据样本对应的语种标签对gbe模型进行训练,保存训练完成时的所述gbe模型的参数,得到所述高斯混合分类器。
具体地,将声学模型和韵律模型的语种识别结果分别进行线性归一化处理,以得到相同分布范围的输出分数。分数线性归一化方法分为两步,首先采用线性变换将得分归一化到单位分布范围。
具体地,线性变换公式为:
其中,sij表示第i条语音对第j个语种模型的原始得分,sij′表示归一化之后的分数。(si)min和(si)min分别表示第i条语音对所有语种模型的得分集合的最小值和最大值。归一化后的得分值都分布在[0,1],因此对不同语种都得到了相同的分数动态范围。
其次,对第j个语种模型,我们计算其所有得分的均值和标准差参数,用来调整上述步骤中得到的sij′,调整方式为:
其中μj'和σ′j分别表示第一步中得到的第j个语种模型的所有s.j′的均值和标准差,sij″为调整后的结果。
声学模型和韵律模型的分数经过线性归一化之后,用加权相加方法进行分数融合,根据第二音频数据样本对应的语种标签、经过线性归一化之后的声学模型和韵律模型的分数对gbe模型进行训练,保存训练完成时的所述gbe模型的参数,得到所述高斯混合分类器。
本发明实施例中,通过训练集数据对gmm-ubm模型和svm模型进行训练,得到声学模型和韵律模型,再通过开发集数据对gbe模型进行训练得到高斯混合分类器,使训练完成的模型能对含有噪音的音频数据进行语种识别,并对两种语种识别结果进行融合,提高了语种识别的准确度。
本发明另一实施例,提供一种广播音频的语种识别装置,包括:
第一预处理模块,用于根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据。
第二预处理模块,用于按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据。
语种识别模块,用于将所述第一音频数据输入至语种识别模型中,得到语种识别结果。其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
本发明提供的广播音频的语种识别装置,通过重采样和音频拼接技术对待检测广播音频数据进行预处理得到第一音频数据,再将所述第一音频数据输入到语种识别模型中,得到语种识别结果。预处理过程中,改变了音频的语速和语调,对重采样后的音频进行拼接后得到的音频相较于待识别音频增加了音频的声学与韵律特征,对待识别音频进行了特征增强,降低了噪音对音频的特征掩蔽。语种识别模型包括声学模型、韵律模型和高斯混合分类器,通过混合高斯分类器将基于声学模型提取检测广播音频数据的声学特征得到的第一语种识别结果和基于韵律模型提取所述待检测广播音频数据的韵律特征得到的第二语种识别结果在得分层次上进行融合,得到语种识别结果,提高了语种识别的准确度。
可选地,所述第一预处理模块具体用于提取所述待检测广播音频数据的数据部分;根据第一采样率对待检测广播音频数据的数据部分进行重采样,得到第一采样音频数据;根据第二采样率对待检测广播音频数据的数据部分进行重采样,得到第二采样音频数据。
可选地,所述第二预处理模块具体用于顺序拼接所述第一采样音频数据、所述待检测广播音频数据的数据部分和所述第二采样音频数据,得到拼接后的音频;将所述拼接后的音频前加入头文件,得到所述第一音频数据;其中,所述头文件中记录的采样率与所述待检测广播音频数据的采样率一致。
可选地,所述语种识别模块包括第一语种识别模块、第二语种识别模块和第三语种识别模块。
所述第一语种识别模块,用于将所述第一音频数据输入至所述声学模型中,得到第一语种识别结果。
所述第二语种识别模块,用于将所述第一音频数据输入至所述韵律模型中,得到第二语种识别结果。
所述第三语种识别模块,用于将所述第一语种识别结果和第二语种识别结果输入至高斯混合分类器,得到所述待检测广播音频数据的语种识别结果。
可选地,本发明提供的广播音频的语种识别装置还包括训练模块,所述训练模块包括第一训练子模块、第二训练子模块、第三训练子模块、第四训练子模块、第五训练子模块和第六训练子模块。
所述第一训练子模块,用于获取已经完成分类的不同语种的原始广播音频数据,并将所述已经完成分类的不同语种的原始广播音频数据划分为训练集和开发集。
所述第二训练子模块,用于对所述训练集进行预处理,得到第一音频数据样本,其中,所述预处理包括:重采样和拼接。
所述第三训练子模块,用于根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对gmm-ubm模型进行训练,保存训练完成时的所述gmm-ubm模型的参数,得到所述声学模型。
所述第四训练子模块,用于根据所述第一音频数据样本和所述第一音频数据样本对应的语种标签对svm模型进行训练,保存训练完成时的所述svm模型的参数,得到所述韵律模型。
所述第五训练子模块,用于对所述开发集进行所述预处理,得到第二音频数据样本,将所述第二音频数据样本输入至所述声学模型和韵律模型,得到第三语种识别结果和第四语种识别结果。
所述第六训练子模块,用于根据所述第三语种识别结果和第四语种识别结果以及所述第二音频数据样本对应的语种标签对gbe模型进行训练,保存训练完成时的所述gbe模型的参数,得到所述高斯混合分类器。
可选地,所述第三训练子模块,具体用于对所述第一音频数据样本进行移动差分倒谱特征提取,得到所述第一音频数据样本对应的sdc特征向量。
将所述sdc特征向量输入至ubm模型,通过k均值聚类与em迭代算法训练所述ubm模型,训练结束后,得到训练完成的ubm模型。
根据贝叶斯自适应算法,从所述训练完成的ubm模型中自适应得到每个语种的gmm模型。
可选地,所述第四训练子模块,具体用于对所述第一音频数据样本进行韵律特征提取,得到所述第一音频数据对应的四维韵律特征向量。
通过多项式映射函数将所述四维韵律特征向量映射成多项式基向量。
针对所述原始广播音频数据中的每一语种,将所述多项式基向量输入至广义线性判别序列glds模块得到具有分性的训练样本,将当前语种的所述训练样本作为正样本,把非所述当前语种的训练样本作为负样本,进行svm训练得到所述当前语种的支持向量。
对每个语种的支持向量进行线性变换得到每个语种的被压缩的韵律模型,其中,所有语种的被压缩的韵律模型构成所述韵律模型。
本发明提供的广播音频的语种识别装置装置能够实现图1至图5的方法实施例实现的各个过程,并达到相同的技术效果,为避免重复,这里不再赘述。
图7示例了一种电子设备的实体结构示意图,如图7所示,该电子设备可以包括:处理器(processor)710、通信接口(communicationsinterface)720、存储器(memory)730和通信总线740,其中,处理器710,通信接口720,存储器730通过通信总线740完成相互间的通信。处理器710可以调用存储器730中的逻辑指令,以执行广播的音频语种识别方法,例如包括:根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据;按照所述待检测广播音频数据的采样率将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据;将所述第一音频数据输入至语种识别模型中,得到语种识别结果;其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
此外,上述的存储器730中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各提供的广播的音频语种识别方法,例如包括:根据第一采样率对待检测广播音频数据进行重采样,得到第一采样音频数据,根据第二采样率对待检测广播音频数据进行重采样,得到第二采样音频数据;将所述第一采样音频数据、所述待检测广播音频数据和所述第二采样音频数据进行拼接,得到第一音频数据;按照所述待检测广播音频数据的采样率将所述第一音频数据输入至语种识别模型中,得到语种识别结果;其中,所述语种识别模型包括声学模型、韵律模型和高斯混合分类器;所述声学模型用于提取所述待检测广播音频数据的声学特征,得到第一语种识别结果,所述韵律模型用于提取所述待检测广播音频数据的韵律特征,得到第二语种识别结果,所述高斯混合分类器用于基于所述第一语种识别结果和第二语种识别结果得到所述待检测广播音频数据的语种识别结果。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

