本发明涉及语音基频检测提取领域,尤其涉及一种婴儿语音基频高精度提取方法、装置及计算机设备。
背景技术:
目前人声的语音处理大部分是针对已经会说话的人群。一般侧重于说话人识别和语音识别,对婴儿这类倾向于情感表现而无对应文字的啼哭音研究太少。通用的基频识别方法包括自相关系数法、平均幅值差函数法、倒谱系数法等,但是倒谱系数法对资源要求过大。由于婴儿的基音频率较高,谐音个数少,有时第一共振峰过高,基音频率衰减过大,因而使用自相关系数法、平均幅值差函数法对于婴儿基频进行识别时容易出错。
技术实现要素:
针对上述问题,本发明提供一种婴儿语音基频高精度提取方法,方法包括:获取婴儿语音数据,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理,获得若干帧时域上的分帧婴儿语音数据;将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值,获得频域上的分帧婴儿语音数据;将频域上的分帧婴儿语音数据从中间位置处划分为对称的第一部分及第二部分,将第一部分或所述第二部分定义为数组z,根据预设计算策略对所述数组z取对数,记为zlog;根据预设的自相关系数计算策略计算zlog的自相关系数,根据zlog的自相关系数以及预设的语音基频提取策略提取婴儿语音数据的语音基频。
进一步的,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理包括:对婴儿语音数据进行预加重处理,提高婴儿语音数据的高频分辨率;将进行预加重处理后的婴儿语音数据,利用汉明窗进行分帧处理。
进一步的,在将分帧婴儿语音数据进行快速傅里叶变换后取绝对值,获得频域上的分帧婴儿语音数据前,方法还包括:预先计算分帧婴儿语音数据中的各个数据分度的正弦值以及余弦值,并将各个数据分度的正弦值以及余弦值存为数组,在将分帧婴儿语音数据进行快速傅里叶变换时,利用数组进行快速傅里叶变换。
进一步的,每一帧分帧婴儿语音数据的采样频率为8820hz,采样点为256个。
进一步的,根据预设计算策略对数组z取对数,记为zlog包括:预先存储m=1024:128:33664的自然对数结果n,其中m=1024:128:33664为m从1024开始,以128为步进,至33664结束的256个数据,依次表示为m0、m1、m2……m255,m0、m1、m2……m255的自然对数结果依次表示为n0、n1、n2……n255;利用公式ln(z)=ln(z*et)-t,对ln(z)进行变形,令z’=z*et,z’在[m0,m255]区间内;确定z’所在的精确区间[mq,mq 1],q为[0,255]中的整数;获取mq的自然对数结果nq,根据公式ln(z’)=nq (z’-mq)/mq以及公式ln(z)=ln(z’)-t,计算得到ln(z)作为将数组z取对数的结果zlog。
进一步的,将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值为利用牛顿迭代法计算绝对值。
本发明还提供一种婴儿语音基频高精度提取装置,包括预处理模块、快速傅里叶变换模块、对数计算模块、自相关系数计算模块以及语音基频计算模块,其中:预处理模块,与快速傅里叶变换模块连接,用于获取婴儿语音数据,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理,获得若干帧时域上的分帧婴儿语音数据;快速傅里叶变换模块,与对数计算模块连接,用于将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值,获得频域上的分帧婴儿语音数据;对数计算模块,与自相关系数计算模块连接,用于将频域上的分帧婴儿语音数据从中间位置处划分为对称的第一部分及第二部分,将第一部分或所述第二部分定义为数组z,根据预设计算策略对数组z取对数,记为zlog;自相关系数计算模块,与语音基频计算模块连接,用于根据预设的自相关系数计算策略计算zlog的自相关系数;语音基频计算模块,用于根据zlog的自相关系数以及预设的语音基频提取策略提取婴儿语音数据的语音基频。
进一步的,预处理模块包括预加重单元以及与预加重单元连接的分帧单元,其中:预加重单元用于对婴儿语音数据进行预加重处理,提高婴儿语音数据的高频分辨率;分帧单元用于将进行预加重处理后的所述婴儿语音数据,利用汉明窗进行分帧处理,获得若干帧时域上的分帧婴儿语音数据。
进一步的,装置还包括数据分度值存储模块,数据分度值存储模块与快速傅里叶变换模块连接,用于预先将分帧婴儿语音数据中的各个数据分度的正弦值以及余弦值存为数组,快速傅里叶变换模块还用于在将分帧婴儿语音数据进行快速傅里叶变换时,利用数组进行快速傅里叶变换。
本发明还提供一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,处理器执行计算机程序时实现上述的婴儿语音基频高精度提取方法步骤。
本发明提供的婴儿语音基频高精度提取方法、装置及计算机设备,至少包括以下有益效果:在进行语音基频提取时,先对婴儿语音数据进行分帧处理,获得平稳的分帧婴儿语音数据,将时域上的分帧婴儿语音数据转换为频域上的分帧婴儿语音数据,对频域上的分帧婴儿语音数据取对数zlog,相当于对频率能量的集中程度进行了一次提纯,再进行自相关性计算后计算精度大大提高,从而降低婴儿语音基频提取的出错率。利用牛顿迭代法计算绝对值、采样查表以及微分法取对数,使本方法可以广泛适用于单片机,大大提高计算速度。
附图说明
为了更清楚的说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图;
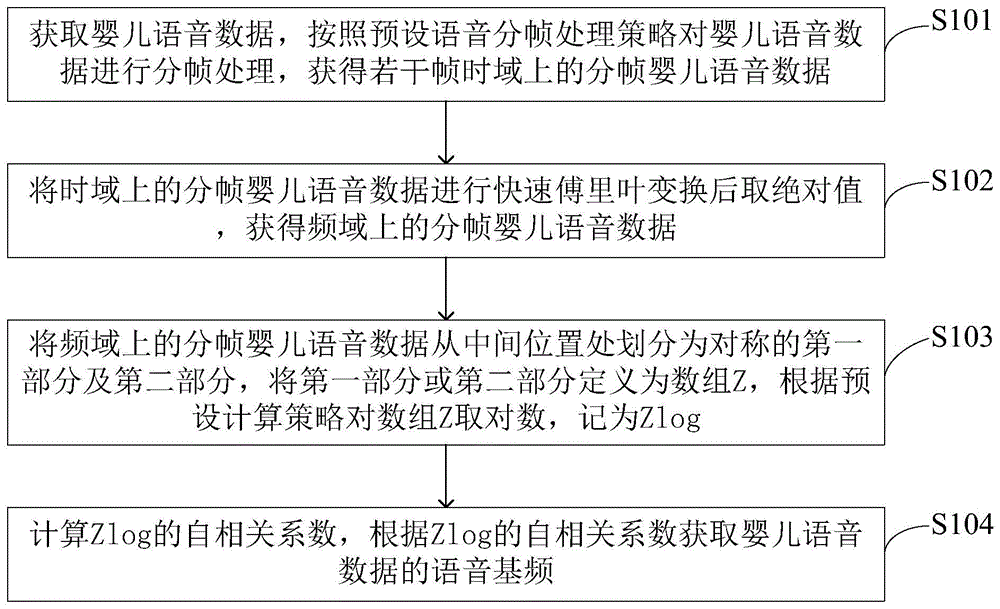
图1为本发明一种实施例中的婴儿语音基频高精度提取方法流程图;
图2为本发明一种实施例中的对数计算方法流程图;
图3为本发明一种实施例中的时域下的一帧分帧婴儿语音数据图谱;
图4为现有技术中对图3中计算自相关系数后获得的图谱;
图5为本发明一种实施例中对图3进行快速傅里叶变换后获得的频域下的一帧分帧婴儿语音数据图谱的第一部分;
图6为本发明一种实施例中的对图5取对数后计算自相关系数后获得的图谱;
图7为本发明一种实施例中的婴儿语音基频高精度提取装置示意图;
图8为本发明一种实施例中的预处理模块的结构示意图;
图9为本发明又一种实施例中的婴儿语音基频高精度提取装置示意图;
301-预处理模块、302-快速傅里叶变换模块、303-对数计算模块、304-自相关系数计算模块、305-语音基频计算模块、306-数据分度值存储模块、3011-预加重单元、3012-分帧单元。
具体实施方式
下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通的技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本发明的保护范围。
在本发明的一种实施例中,如图1所示,公开了一种婴儿语音基频高精度提取方法,具体的,方法包括以下步骤:
步骤s101:获取婴儿语音数据,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理,获得若干帧时域上的分帧婴儿语音数据。
具体的,在本实施例中,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理包括:对婴儿语音数据进行预加重处理,提高婴儿语音数据的高频分辨率;将进行预加重处理后的婴儿语音数据,利用汉明窗进行分帧处理,如图3所示,为分帧后的时域下的一帧分帧婴儿语音数据图谱,其中横坐标表示语音信号震动的幅值,纵坐标表示采样点的个数。
语音信号(即婴儿语音数据)是一种随时间而变化的信号,主要分为浊音和清音两大类。浊音的基音周期、清浊音信号幅度和声道参数等都随时间而缓慢变化。由于发声器官的惯性运动,可以认为在一小段时间里(一般为15~30ms)语音信号近似不变,即语音信号具有短时平稳性。由于在发明中,进行语音基频提取时需要进行快速傅里叶变换,而快速傅里叶变换要求输入信号是平稳的,才能达到预期的效果,因此,本发明在进行快速傅里叶变换之前需要先对婴儿语音数据进行分帧处理(帧长为15~30ms),将婴儿语音数据分为一些短段(称为分析帧)来分别进行分析,从中提取到每一帧分析帧(即本发明中的每一帧分帧婴儿语音数据)的语音基频。更具体的,分帧可以采用可移动的有限长度窗口进行加权的方法来实现,优选的,在本实施例中,采用汉明(hamming)窗来进行分帧,汉明窗的瓣衰减较大,具有更平滑的低通特性,能够在较高的程度上反映短时信号的频率特性。
进一步的,在本实施例中,可以设置每一帧分帧婴儿语音数据的采样频率为8820hz,采样点为256个,此时一帧分帧婴儿语音数据约为29ms,图3即为在采样频率为8820hz、采样点为256个时的时域下的一帧分帧婴儿语音数据的语音图谱。
步骤s102:将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值,获得频域上的分帧婴儿语音数据。
快速傅里叶变换(fft,fastfouriertransformation),指的是离散傅氏变换的快速算法,它是根据离散傅氏变换的奇、偶、虚、实等特性,对离散傅立叶变换的算法进行改进获得的。利用快速傅里叶变换进行分帧婴儿语音数据的时域、频域变换,可以提高运算速度。
步骤s103:将频域上的分帧婴儿语音数据从中间位置处划分为对称的第一部分及第二部分,将第一部分或第二部分定义为数组z,根据预设计算策略对数组z取对数,记为zlog。
具体的,将频域上的分帧婴儿语音数据从中间位置处划分为对称的第一部分及第二部分,其中第一部分为频域上的分帧婴儿语音数据的前半部分序列,第二部分为频域上的分帧婴儿语音数据的后半部分序列,由于第一部分与第二部分是对称的,因此在取对数时,仅需就其中一个序列取对数即可。
如图5所示,即为将图3转换为频域上的分帧婴儿语音数据之后得到的前半部分序列,即第一部分,其中横坐标为频率,纵坐标为能量幅值。由于采样频率为8820hz,因此前半部分序列为0-4410hz。
进一步的,在本实施例中,可以将第一部分用数组z表示,进而取第一部分的对数,也可以将第二部分用数组z表示,进而取第二部分的对数,本发明对此不作限制。
进一步的,在本实施例中,根据预设计算策略对数组z取对数,记为zlog,为利用采样查表以及微分法实现上述计算。当每一帧分帧婴儿语音数据的采样频率为8820hz,采样点为256个时,如图2所示,根据预设计算策略对数组z取对数,记为zlog,包括以下步骤:
步骤s201:预先存储m=1024:128:33664的自然对数结果n,其中m=1024:128:33664为m从1024开始,以128为步进,至33664结束的256个数据,这256个数据依次表示为m0、m1、m2……m255,m0、m1、m2……m255的自然对数结果依次表示为n0、n1、n2……n255;
具体的,步进值的选取与每一帧的采样点数有关,为了让基音不至于突跳,一般取一帧采样点数的1/4~1/2,在本实施例中,由于采样点数为256,因此步进值为采样点数256的1/2,因此步进值设定为128。
在本步骤中,预先存储的是m的自然对数结果,后续计算zlog时,计算的也为z的自然对数,可以提高计算速度。在本实施例中z为数组,数组z为是每一帧婴儿语音数据经过fft变换后的频域结果,即幅值,由于采样点数为256,只取前半部分或后半部分的数据作为数组z,也即数组z中有128个数值,计算z的自然对数,即计算数组z中的各个元素数据的自然对数。
步骤s202:利用公式ln(z)=ln(z*et)-t,对ln(z)进行变形,令z’=z*et,t为整数,z’在[m0,m255]区间内;
具体的,在本步骤中,将ln(z)变形为ln(z*et)-t,并且通过设定t的值,使z*et处于[m0,m255]区间内。从而后续再计算时,可以利用预先存储的m的自然对数n实现快速计算。
步骤s203:确定z’所在的精确区间[mq,mq 1],q为[0,255]中的整数;
步骤s204:获取mq的自然对数结果nq,根据公式ln(z’)=nq (z’-mq)/mq以及公式ln(z)=ln(z’)-t,计算得到ln(z)作为将所述第一部分取对数的结果zlog。
在本实施例中,利用采样查表以及微分法,预先存储了256个数据的自然对数结果,之后可以根据预先存储的256个数据的自然对数结果快速的计算得到ln(z),此方法可以广泛适用于单片机,提高计算速度。
步骤s104:根据预设的自相关系数计算策略计算zlog的自相关系数,根据zlog的自相关系数以及预设的语音基频提取策略提取婴儿语音数据的语音基频。
具体的,自相关系数即一段语音位移n后,与原语音数组的相关系数(即自己与自己位移后的相关性),在本实施例中预设的自相关系数计算策略可以为根据序列的自协方差公式:
其中,变量xt表示一个时间序列,xt表示时间序列中的第t个点,t=1,2,3···n,n表示序列xt的长度,序列的均值μ=e(xt),序列的方差σ2=d(xt)=e((xt-μ)2),k为序列的滞后次数,
进一步的,根据zlog的自相关系数以及预设的语音基频提取策略提取婴儿语音数据的语音基频,为根据对频域下的一帧分帧婴儿语音数据取对数后计算自相关系数后获得的图谱(如图6所示),将对应的图谱中的各谐波的间距作为语音基频。如图3所示,为采样频率为8820hz,采样点为256个的情况下的在时域下的一帧分帧婴儿语音数据图谱。
如图4所示,图4为采用现有技术中常用的基频提取方式,对图3中的时域下的一帧分帧婴儿语音数据直接计算自相关系数后获得的图谱,自相关系数r(k)=r(t,t k),语音基频计算选取最大值为f0=1/t=1/(3.968ms)=252hz。(对比图4及图5、6,根据图4计算出的结果明显出错)。
如图5所示,为对图3中的时域下的一帧分帧婴儿语音数据进行快速傅里叶变换取绝对值后,获得的频域下的一帧分帧婴儿语音数据图谱的第一部分(即前半段序列),从谐波可以看出,图5中的语音基频应该在500hz左右。
如图6所示,为对图5取对数后计算自相关系数后获得的图谱,得到更为明显的基频区别,由图6可明显得到500hz才是真正基频。
综上,本实施例中提供的语音基频的提取方法,在进行语音基频提取时,先将时域上的分帧婴儿语音数据转换为频域上的分帧婴儿语音数据,对频域上的分帧婴儿语音数据取对数zlog,相当于对频率能量的集中程度进行了一次提纯,再进行自相关性计算后计算精度大大提高,从而降低婴儿语音基频提取的出错率。
进一步的,zlog采用采样查表以及微分法进行计算,能够有效提高zlog的计算速度。
在本发明的又一种实施例中,在将分帧婴儿语音数据进行快速傅里叶变换,获得频域上的分帧婴儿语音数据前,方法还包括:
预先计算分帧婴儿语音数据中的各个数据分度的正弦值以及余弦值,并将各个数据分度的正弦值以及余弦值存为数组,在将分帧婴儿语音数据进行快速傅里叶变换时,利用数组进行快速傅里叶变换。
具体的,以分帧婴儿语音数据为n点序列为例,分帧婴儿语音数据中的各个数据可以表示为如下公式:
其中,k=0,···n-1,根据欧拉公式将上述公式变形为:
因而对于分帧婴儿语音数据中的每一个数据而言,有一个正弦值和余弦值分量的计算。
由于在进行快速傅里叶变换时,会使用到各个数据分度的正弦值以及余弦值,因而在本实施例中,预先将各个数据分度的正弦值以及余弦值计算出来并进行存储,当进行快速傅里叶变换时,直接调用已有的数据即可,从而进一步的提高计算速度。
在本发明的又一种实施例中,将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值为利用牛顿迭代法计算绝对值,牛顿迭代法(newton'smethod)又称为牛顿-拉夫逊方法(newton-raphsonmethod)。具体的,在进行绝对值计算时需要开根号,采用牛顿迭代法,可以有效提高计算精度。
本发明还提供一种婴儿语音基频高精度提取装置,如图7所示,装置包括:预处理模块301、快速傅里叶变换模块302、对数计算模块303、自相关系数计算模块304以及语音基频计算模块305,其中:
预处理模块301,与快速傅里叶变换模块302连接,用于获取婴儿语音数据,按照预设语音分帧处理策略对婴儿语音数据进行分帧处理,获得若干帧时域上的分帧婴儿语音数据;
快速傅里叶变换模块302,与对数计算模块303连接,用于将时域上的分帧婴儿语音数据进行快速傅里叶变换后取绝对值,获得频域上的分帧婴儿语音数据;
对数计算模块303,与自相关系数计算模块304连接,用于将频域上的分帧婴儿语音数据从中间位置处划分为对称的第一部分及第二部分,将第一部分或第二部分定义为数组z,根据预设计算策略对数组z取对数,记为zlog;
自相关系数计算模块304,与语音基频计算模块305连接,用于根据预设的自相关系数计算策略计算zlog的自相关系数;
语音基频计算模块305,用于根据zlog的自相关系数以及预设的语音基频提取策略提取婴儿语音数据的语音基频。
进一步的,如图8所示,预处理模块301包括预加重单元3011以及与预加重单元3011连接的分帧单元3012,其中:
预加重单元3011用于对婴儿语音数据进行预加重处理,提高婴儿语音数据的高频分辨率;
分帧单元3012用于将进行预加重处理后的婴儿语音数据,利用汉明窗进行分帧处理,获得若干帧时域上的分帧婴儿语音数据。
在本发明的又一种实施例中,如图9所示,装置还包括数据分度值存储模块306,数据分度值存储模块306与快速傅里叶变换模块302连接,用于预先将分帧婴儿语音数据中的各个数据分度的正弦值以及余弦值存为数组,快速傅里叶变换模块306还用于在将分帧婴儿语音数据进行快速傅里叶变换时,利用数组进行快速傅里叶变换。
本发明还提供一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,处理器执行计算机程序时实现上述的婴儿语音基频高精度提取方法步骤。
综上,本实施例中提供的语音基频的提取方法,在进行语音基频提取时,先将时域上的分帧婴儿语音数据转换为频域上的分帧婴儿语音数据,对频域上的分帧婴儿语音数据取对数zlog,相当于对频率能量的集中程度进行了一次提纯,再进行自相关性计算后计算精度大大提高,从而降低婴儿语音基频提取的出错率。进一步的,zlog采用采样查表以及微分法进行计算,能够有效提高zlog的计算速度,预先存储分帧婴儿语音数据中的各个数据分度的正弦值以及余弦值存为数组,在进行快速傅里叶变换时利用预先存储的数组可以大大减少计算量,提高计算速度。从而保证了在低运算量的情况下,实现语音基频的高精度计算。
本发明说明书中使用的术语和措辞仅仅为了举例说明,并不意味构成限定。本文中在本发明的权利要求书、说明书中所使用的“第一”、“第二”只是为了便于区分的目的,没有特殊含义,不是旨在于限制本发明。本领域技术人员应当理解,在不脱离所公开的实施方式的基本原理的前提下,对上述实施方式中的各细节可进行各种变化。因此,本发明的范围只由权利要求确定,在权利要求中,除非另有说明,所有的术语应按最宽泛合理的意思进行理解。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

