本发明属于语音识别技术领域,具体涉及一种结合gmmtoken配比与聚类的核心训练语音选择方法。
背景技术:
声纹认证系统作为一种生物认证的方式,具有采集成本低、易于获取、方便远程认证等等优势,已经广泛应用于门禁系统、金融交易和司法鉴定等等领域。随着语音合成技术飞速发展,一方面给人们带来了更方便的服务和更良好的用户体验,如真声智能客服、真声智能导航、有声读物、智能语音呼叫等等;另一方面也给声纹认证系统的安全性带来了巨大的挑战,如利用合成语音攻击声纹认证系统使其性能显著下降,因此关于合成语音检测的研究具有重要的意义。
合成语音检测的目的就是从真实语音中将合成语音检测出来。现有的关于合成语音检测的实验研究都是按照比赛设定的训练集进行训练的,通常会使用大量的训练数据;然而在实际情况中,当使用更多的训练数据时,性能反而有所下降,因为训练数据中是存在冗余的,进行数据选择成为一个值得关注的课题。
技术实现要素:
为了解决选择高质量训练数据获取的问题,本发明提出了一种结合gmmtoken配比与聚类的核心训练语音选择方法,使用该方法可以选取高质量的核心训练语音集,使得模型在使用更少训练语音的情况下取得更好的性能,不仅节约了训练时间和能耗,而且提升了检测性能。
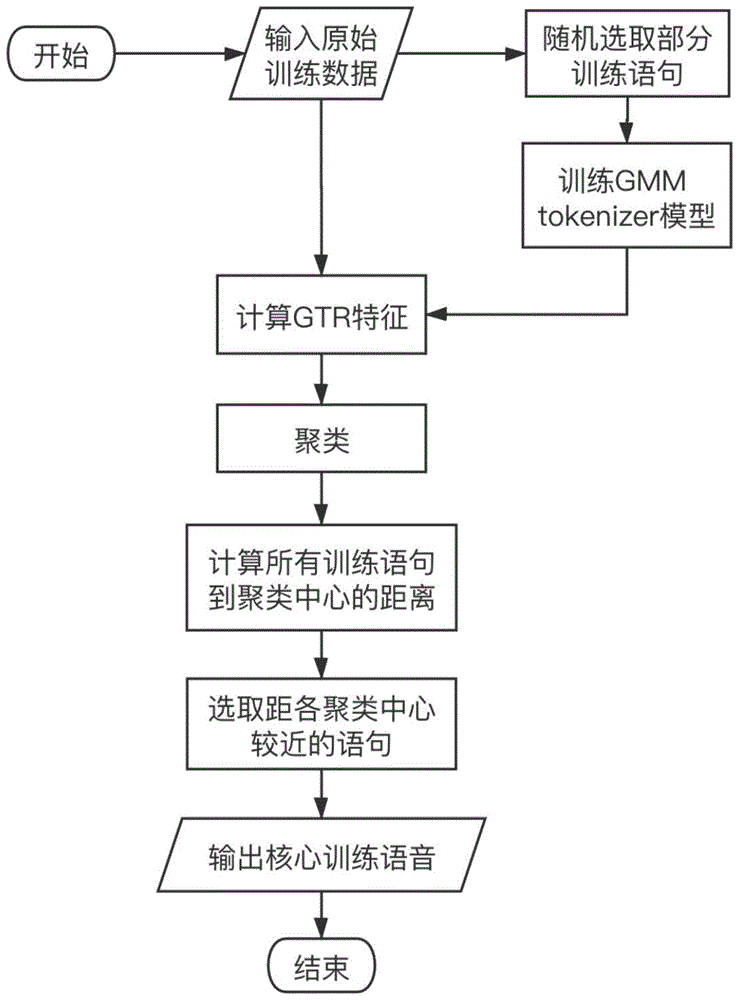
一种结合gmmtoken配比与聚类的核心训练语音选择方法,包括如下步骤:
s1.随机选取部分训练语音进行训练获得初始模型;
s2.利用所述初始模型计算所有训练语音的gmmtoken配比特征;
s3.利用所述gmmtoken配比特征对所有训练语音进行聚类;
s4.逐一计算每条训练语音到聚类中心的距离;
s5.根据一定比例逐类选取距离聚类中心较近的训练语音作为核心训练语音。
进一步地,所述步骤s1的具体实现方式为:随机选择一定比例的训练语音,提取其特征数据,使用这些特征数据训练得到具有k阶高斯分量的gmm(高斯混合模型)即初始模型。gmm的训练是一个有监督的优化过程,其采用最大似然准则,整个过程分为参数初始化和参数优化两部分,前者使用lbg算法实现,后者使用em算法实现,将训练得到的gmm作为之后用于获取训练语音token配比特征的gmmtokenizer。
进一步地,所述步骤s2的具体实现方式为:首先提取各训练语音的特征数据(语音特征提取方式应与步骤s1中训练gmm时采用的特征提取方式保持一致),然后针对特征数据的每一帧,在gmmtokenizer上计算似然得分,将得分最高的高斯分量索引序号标记作为这一帧的gmmtoken,相应地,特征数据中的每一帧经过gmmtokenizer之后都将对应得到一个gmmtoken,整个特征数据经过gmmtokenizer之后便可获得一组gmmtoken序列;最后计算每一高斯分量索引的gmmtoken数量与gmmtoken总数之比即训练语音的gmmtoken配比特征,计算方法为
进一步地,所述步骤s3的具体实现方式为:根据步骤s2获得所有训练语音的gmmtoken配比特征,对训练语音进行聚类,将所有训练语音聚成m类,m为自定义大于1的自然数。
进一步地,所述步骤s4的具体实现方式为:对于任一条训练语音,根据gmmtoken配比特征计算该语音到其所属类别聚类中心的距离。
进一步地,所述步骤s5的具体实现方式为:对于任一类别,将该类别中的训练语音按其与聚类中心的距离从小到大进行排序,按照一定的比例选择排名靠前的训练语音作为核心训练语音。
通过本发明提供的核心语音选择方法,可以保证挑选的训练语音之间差异较大,且分别能够较好地覆盖待识别类别语音的声学特征空间,因此能使部分的训练数据获取的语音模型性能优于原始训练数据上建立的语音模型。
附图说明
图1为本发明核心训练语音选择方法的步骤流程示意图。
具体实施方式
本发明适用于语音识别、说话人识别、伪造语音识别等语音分类场景,下面提供了在合成语音检测中选择核心训练语音的应用实施例。
为了进一步理解本发明,下面结合具体实施例对本发明的技术方案进行详细描述,但是应当理解,这些描述只是为进一步说明本发明的特征和优点,而不是对本发明权利要求的限制。
本实施方式中的实验数据采用的是2019年自动说话人识别欺骗攻击与防御对策挑战赛逻辑访问数据库(asvspoof2019-la)以及2015年自动说话人识别欺骗攻击与防御对策挑战赛(asvspoof2015)。
asvspoof挑战赛由英国爱丁堡大学、法国eurecom、日本nec、东芬兰大学等多个世界领先的研究机构共同组织发起。asvspoof2019的真实语音来自107个说话人,其中61人为女性、46人为男性,数据集被划分为三部分:训练集(train)、开发集(dev)、评估集(eval),录音环境较安静,没有明显的信道或环境噪声。训练集和开发集的虚假语音是用各种算法从真实语音中生成的,其中训练集包含20个说话人,12人为女性、8人为男性,包含真实语音2580句、虚假语音22800句;开发集包含20个说话人,12人为女性、8人为男性,包含真实语音2548句、虚假语音22296句;评估集包含67个说话人,37人为女性、30人为男性,包含真是语音7355句、虚假语音63882句,评估集大小约为4gb。
asvspoof2015的真实语音来自106个说话人,其中61人为女性、45人为男性,数据集被划分为三部分:训练集(train)、开发集(dev)、评估集(eval),录音环境较安静,没有明显的信道或环境噪声。训练集和开发集的虚假语音是用各种算法从真实语音中生成的,其中训练集包含25个说话人,15人为女性、10人为男性,包含真实语音3750句、虚假语音12625句;开发集包含35个说话人,20人为女性、15人为男性,包含真实语音2497句、虚假语音49875句;评估集包含46个说话人,26人为女性、20人为男性,约20万条测试语音,评估集大小约为20gb。
如图1所示,本发明结合gmmtoken配比与聚类的核心训练语音选择方法包括如下步骤:
s1.随机选取语句进行训练获取模型参数;
s2.计算所有训练语句的gmm托肯配比特征;
s3.对所有语句进行kmenas聚类;
s4.计算各个语句到各个聚类中心的距离;
s5.选取距离各个聚类中心最近的语句。
前述步骤s1的具体实施方法是:首先定义合成语音检测训练语料为
随机选择比例为α的语音,获取其特征数据,可以使用语音的32阶lfcc,并加上一阶δ特征和二阶δ特征。使用这些特征数据,训练得到拥有k阶高斯分量的gmm,将这个gmm作为之后用于获取训练语音token配比特征的gmmtokenizer。
gmm的训练是一个有监督的优化过程,一般采用最大似然准则,整个过程分为参数初始化和参数优化两部分,前者通常使用lbg算法,后者使用em算法,由于gmm的训练以及语音特征的获取方法在现有的合成语音检测系统中已得到普遍的应用,在此不多作说明。对于gmm模型阶数k的选择,一般是2的幂次方如64、128、512、1024等等,在实验中发现对于使用的96维lfcc特征,512阶的gmm合成语音检测系统性能更优。
前述步骤s2的具体实施方法是:首先获取各个语音的特征数据,语音特征的获取方式应该与步骤s1中训练gmmtokenizer的数据的获取方式保持一致(如32阶lfcc加上一阶δ特征和二阶δ特征);然后针对特征数据的每一帧,在gmmtokenizer上计算似然得分
前述步骤s3的具体实施方法是:对于步骤s2所获得的所有语音的gmmtoken配比特征,进行kmeans聚类,将数据聚成m类。kmeans算法是基于距离的非层次聚类算法,步骤首先是随机初始化聚类中心center={c1,c2,…,cm},然后计算每个样本到聚类中心的距离disti={d1,d2,…,dm},按照最小距离原则划分到最邻近聚类,接着计算每个聚类中的样本均值作为聚类中心
前述步骤s4的具体实施方法是:对于步骤s3得到的聚类中心,计算距离各个语音特征到各聚类中心的欧式距离
前述步骤s5的具体实施方法是:对于步骤s4得到的各个语音特征到各聚类中心的欧式距离进行排序,选择距离各个中心最近的语音j*=argminjdij加入选取的核心语音集合c。
以下我们对开发集和评估集的所有语音进行测试,实验均基于gmm系统,除了本发明提出的gtr聚类选择算法以外,对比了使用全部数据、随机选择和最大平均距离(topk)选择的方法,实验等错误率eer结果比较如表1所示:
表1
从表1中可以看出,本发明能够在一定程度上提高系统识别性能且性能优于随机选择和topk选择方法,对比原始使用全部数据训练的方法eer平均提升了0.65个百分点。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明,熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

