本发明涉及情感计算、深度学习技术领域,具体为一种对话文本的深度学习情感识别方法。
背景技术:
情感是人们在日常生活中表现出来的一种心理现象,对于智能机器,如果能够实现快速准确地判断人的情感状态,就可以进一步理解用户的情感。
情感识别是自然语言处理的一个重要任务,也是人工智能领域的重要领域,在工业界也有着广泛的应用,如商品评论情感识别、基于文本的智能客服情感识别、以及讨论主题的用户情感识别等。因此,如何提高情感别的准确性有着重要意义。目前,常见的情感识别方法在情感识别过程常常存在无法正确识别用户的真正的情感和识别精准度不高的缺陷。因此我们对此做出改进,提出一种对话文本的深度学习情感识别方法。
技术实现要素:
为了解决上述技术问题,本发明提供了如下的技术方案:
本发明一种对话文本的深度学习情感识别方法,包括以下步骤:
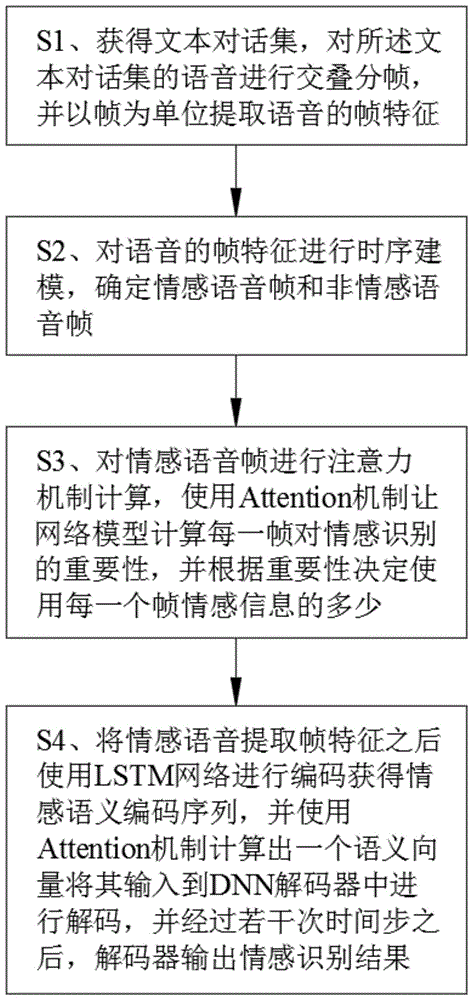
s1、获得文本对话集,对所述文本对话集的语音进行交叠分帧,并以帧为单位提取语音的帧特征;
s2、对语音的帧特征进行时序建模,确定情感语音帧和非情感语音帧;
s3、对情感语音帧进行注意力机制计算,使用attention机制网络模型计算每一帧对情感识别的重要性,并根据重要性决定使用每一个帧情感信息的多少;
s4、将情感语音提取帧特征之后使用lstm网络进行编码获得情感语义编码序列,并使用attention机制计算出一个语义向量将其输入到解码器中进行解码,并经过若干次时间步之后,解码器输出情感识别结果。
作为本发明的一种优选技术方案,所述s2中时序建模包括构建情感语音所对应的情感状态链,由情绪状态和非情绪状态;将整个情感语音样本的标签y在假设的指导下扩展为一个标签序列yseg=(null,y,null,...,y,null);根据yseg中y的个数确定一个文情感语音样本对应的标签序列敛。
作为本发明的一种优选技术方案,所述s2中时序建模采用lstm-ctc时序深度学习模型,进行建模,并通过时间上误差反向传播算法训练lstm-ctc网络,使其收敛。
作为本发明的一种优选技术方案,所述attention机制的语音情感识别模型由两个lstm网络模型组成,并分别作为编码器和解码器。
作为本发明的一种优选技术方案,所述attention机制的语音情感识别模型识别流程为:对一个语音样本的情感特征,进行编码器,得到该语音的情感语义编码序列,在得到语音的情感语义编码序列后,将最后一个编码向量输入到解码器之中开始进行情感解码。
作为本发明的一种优选技术方案,所述解码器接收两个输入,一个输入是根据上一时刻注意力计算得到的情感语义向量,另外一个输入是解码器根据上一时刻的情感识别结果对应的情感表示向量。
作为本发明的一种优选技术方案,所述在s4解码过程中,每一个时间步计算一次对语音情感语义编码序列的注意力,并根据注意力计算情感语义向量作为下一时刻的输入,并且解码器在每一次时间步中都会做一次情感识别判断,判断当前语句属于哪一种情感,并将代表该类情感的表示向量作为下一次时间步的输入,经过若干次时间步之后,解码器输出情感识别结果。
本发明的有益效果是:该种对话文本的深度学习情感识别方法,通过采用lstm-ctc时序深度学习模型,将标签从单一形式扩展为一个序列,并使用lstm模型根据ctc损失训练语音情感识别模型,将标签自动对齐到语音中的情感帧上,进而可有效对语音的帧特征进行精准提取;通过使用lstm神经网络作为解码器,模拟人类的注意力变化过程,使模型对情感信息含量不一致语音帧进行不同程度学习,降低了特征中情感无关信息对模型的干扰,提高模型的识别性能;通过attention模型计算注意力分配权重方式,使模型对语音中的情感帧的关注有一个从整体到局部的侧重过程,进而可有效提高情感识别的精准性。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明一种对话文本的深度学习情感识别方法的流程示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例:如图1所示,本发明一种对话文本的深度学习情感识别方法,包括以下步骤:
s1、获得文本对话集,对所述文本对话集的语音进行交叠分帧,并以帧为单位提取语音的帧特征;
s2、对语音的帧特征进行时序建模,确定情感语音帧和非情感语音帧;
s3、对情感语音帧进行注意力机制计算,使用attention机制网络模型计算每一帧对情感识别的重要性,并根据重要性决定使用每一个帧情感信息的多少;
s4、将情感语音提取帧特征之后使用lstm网络进行编码获得情感语义编码序列,并使用attention机制计算出一个语义向量将其输入到解码器中进行解码,并经过若干次时间步之后,解码器输出情感识别结果。
其中,s2中时序建模包括构建情感语音所对应的情感状态链,由情绪状态和非情绪状态;将整个情感语音样本的标签y在假设的指导下扩展为一个标签序列yseg=(null,y,null,...,y,null);根据yseg中y的个数确定一个文情感语音样本对应的标签序列敛。
其中,s2中时序建模采用lstm-ctc时序深度学习模型,进行建模,并通过时间上误差反向传播算法训练lstm-ctc网络,使其收敛,通过采用lstm-ctc时序深度学习模型,将标签从单一形式扩展为一个序列,并使用lstm模型根据ctc损失训练语音情感识别模型,将标签自动对齐到语音中的情感帧上,进而可有效对语音的帧特征进行精准提取。
其中,attention机制的语音情感识别模型由两个lstm网络模型组成,并分别作为编码器和解码器。
其中,attention机制的语音情感识别模型识别流程为:对一个语音样本的情感特征,进行编码器,得到该语音的情感语义编码序列,在得到语音的情感语义编码序列后,将最后一个编码向量输入到解码器之中开始进行情感解码,通过attention模型计算注意力分配权重方式,使模型对语音中的情感帧的关注有一个从整体到局部的侧重过程,进而可有效提高情感识别的精准性。
其中,解码器接收两个输入,一个输入是根据上一时刻注意力计算得到的情感语义向量,另外一个输入是解码器根据上一时刻的情感识别结果对应的情感表示向量。
其中,在s4解码过程中,每一个时间步计算一次对语音情感语义编码序列的注意力,并根据注意力计算情感语义向量作为下一时刻的输入,并且解码器在每一次时间步中都会做一次情感识别判断,判断当前语句属于哪一种情感,并将代表该类情感的表示向量作为下一次时间步的输入,经过若干次时间步之后,解码器输出情感识别结果。
该种对话文本的深度学习情感识别方法在实际使用时,通过采用lstm-ctc时序深度学习模型,将标签从单一形式扩展为一个序列,并使用lstm模型根据ctc损失训练语音情感识别模型,将标签自动对齐到语音中的情感帧上,进而可有效对语音的帧特征进行精准提取;通过使用lstm神经网络作为解码器,模拟人类的注意力变化过程,使模型对情感信息含量不一致语音帧进行不同程度学习,降低了特征中情感无关信息对模型的干扰,提高模型的识别性能;通过attention模型计算注意力分配权重方式,使模型对语音中的情感帧的关注有一个从整体到局部的侧重过程,进而可有效提高情感识别的精准性。
最后应说明的是:在本发明的描述中,需要说明的是,术语“竖直”、“上”、“下”、“水平”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

