本申请是申请人为弗劳恩霍夫应用研究促进协会、申请日为2015年7月24日、申请号为201580050417.1、发明名称为“用于使用独立噪声填充生成增强信号的装置和方法”的分案申请,其母案的内容通过引用并入本文。
本发明涉及信号处理,尤其涉及音频信号处理。
背景技术:
以用于音频信号的高效存储或传输的数据缩减为目的的音频信号的感知编码被广泛地实践使用。特别是在要实现最低比特率时,所应用的编码导致音频质量的下降,其经常主要是由待传输的音频信号带宽的编码器侧的限制引起。在现代的编解码器中,存在已知方法用于通过诸如谱带复制(sbr)的音频信号带宽扩展(bwe)的解码器侧信号恢复。
在低比特率编码中,也经常应用所谓的噪声填充。在解码器中,由于严格的比特率限制而已被量化为零的突出的谱区域以合成噪声而被填充。
通常,在低比特率编码应用中结合两种技术。此外,存在结合音频编码、噪声填充和谱间隙填充的集成解决方案,例如智能间隙填充(igf)。
然而,所有的这些方法具有如下共同之处:在第一步骤中,使用波形解码和噪声填充重构基带或核心音频信号,以及在第二步骤中,使用快速重构的信号执行bwe或igf处理。这导致如此事实:在重构期间通过噪声填充已被填充到基带中的相同噪声值被用于再生高频带中的缺失部分(在bwe中)或用于填充剩余的谱间隙(在igf中)。在bwe或igf中,使用高度相关的噪声用以重构多个谱区域可能导致感知损伤。
现有技术中相关主题包括:
·sbr作为至波形解码的后置处理器[1-3]
·accpns[4]
·mpeg-dusac噪声填充[5]
·g.719以及g.722.1c[6]
·mpeg-h3digf[8]
下面的论文和专利申请描述被视为与本申请相关的方法:
[1]m.dietz,l.liljeryd,k.
[2]s.meltzer,r.
[3]t.ziegler,a.ehret,p.ekstrandandm.lutzky,“enhancingmp3withsbr:featuresandcapabilitiesofthenewmp3proalgorithm,”in112thaesconvention,munich,germany,2002.
[4]j.herre,d.schulz,extendingthempeg-4aaccodecbyperceptualnoisesubstitution,audioengineeringsociety104thconvention,preprint4720,amsterdam,netherlands,1998
[5]europeanpatentapplicationep2304720usacnoise-filling
[6]itu-trecommendationsg.719andg.221c
[7]ep2704142
[8]ep13177350
以这些方法处理的音频信号遭受人为现象(artifact)如粗糙、调制失真以及被视为使人不愉快的音色,特别是在低比特率处及由此的低带宽处,和/或在lf范围内的谱孔(spectralhole)的发生。如下面所解释,对此的原因主要是这样的事实:扩展的或间隙填充的谱的重构分量基于来自基带的包含噪声的一个或多个直接副本。由重构噪声中的所述不需要的相关性引起的时间调制以感知粗糙或令人反感的失真的干扰方式是可听的。所有现有方法如mp3 sbr、aac sbr、usac、g.719和g.722.1c,以及mpeg-h3digf在以来自核心的复制或镜象的谱数据填充谱间隙或高频带之前首先进行包括噪声填充的完整核心解码。
技术实现要素:
本发明的目的是提供生成增强信号的改进的概念。
通过权利要求1所述的用于生成增强信号的装置、权利要求11所述的用于生成增强信号的方法、权利要求13所述的编码和解码系统、权利要求14所述的编码和解码方法或权利要求15所述的计算机程序实现此目的。
本发明基于如下发现:通过生成用于输入信号的源谱区域中的噪声填充区域的第一噪音值并随后生成用于目的或目标区域(即,在此刻具有噪声值即与第一噪声值相独立的第二噪声值的增强区域中)中的噪声区域的第二独立噪声值,获得通过带宽扩展或智能间隙填充或生成具有用于未包含在输入信号中的增强谱区域的谱值的增强信号的任意其他方法生成的增强信号的音频质量的显著提升。
因此,消除归因于谱值映射的在基带和增强带中具有相依噪声的在先技术问题,并消除关于如粗糙、调制失真以及被视为使人不愉快的音色(特别是在低比特率处)的人为现象的相关问题。
换言之,与第一噪声值解相关的第二噪声值(即与第一噪声值至少部分地相独立的噪声值)的噪声填充确保不再出现人为现象或相对于在先技术至少减少人为现象。因此,通过简单带宽扩展或智能间隙填充操作的将谱值噪声填充到基带中的在先技术处理并不能将噪声与基带解相关,而(例如)仅改变水平(level)。然而,一方面在源带中以及另一方面在目标带中引入解相关的噪声值(优选地,得自分离噪声处理),提供最好结果。然而,即使是未完全解相关或未完全相独立的而是在零的解相关值表示完全解相关时如以0.5或更小的解相关值至少部分地解相关的噪声值的引入也改善了在先技术的完全相关性问题。
因此,实施例涉及在感知解码器中的波形解码、带宽扩展或间隙填充以及噪声填充的结合。
进一步的优点是,对比已存在的概念,避免了信号失真和感知粗糙的人为现象(对于在波形解码和噪声填充之后计算带宽扩展或间隙填充,其通常是典型的)的出现。
在一些实施例中,此归因于所提及的处理步骤的顺序的改变。优选地,在波形解码后直接执行带宽扩展或间隙填充,更优选地,随后使用不相关噪声对已经重构的信号计算噪声填充。
在另外的实施例中,波形解码和噪声填充可以以传统顺序并在处理中的更下游执行,可以以适当缩放的不相关噪声替换噪声值。
因此,通过将噪声填充步骤移位至处理链的最末端以及使用用于修补(patching)或间隙填充的不相关噪声,本发明解决了由于对经噪声填充的谱的复制操作或镜象操作而发生的问题。
附图说明
随后,关于附图讨论本发明的优选实施例,其中:
图1a示出用于编码音频信号的装置;
图1b示出与图1a的编码器匹配的用于解码经编码的音频信号的解码器;
图2a示出解码器的优选实施;
图2b示出编码器的优选实施;
图3a示出由图1b的谱域解码器生成的谱的示意性表示;
图3b示出指示用于缩放因子带的缩放因子与用于重构带的能量以及用于噪声填充带的噪声填充信息之间的关系的表;
图4a示出用于应用谱部分至第一集合的谱部分和第二集合的谱部分的选择的谱域编码器的功能;
图4b示出图4a的功能的实施;
图5a示出mdct编码器的功能;
图5b示出利用mdct技术的解码器的功能;
图5c示出频率再生器的实施;
图6示出依照本发明的用于生成增强信号的装置的框图;
图7示出依照本发明的实施例的由解码器中的选择信息控制的独立噪声填充的信号流;
图8示出通过解码器中的间隙填充或带宽扩展(bwe)与噪声填充交换后的顺序而实施的独立噪声填充的信号流;
图9示出依照本发明的又一实施例的过程的流程图;
图10示出依照本发明的又一实施例的过程的流程图;
图11示出用于对随机值的缩放进行解释的流程图;
图12示出显示本发明嵌入至一般带宽扩展或间隙填充过程的流程图;
图13a示出具有带宽扩展参数计算的编码器;以及
图13b示出具有作为后置处理器实施的带宽扩展而非图1a或图1b中的集成过程的解码器。
具体实施方式
图6示出用于从也可作为音频信号的输入信号生成增强信号如音频信号的装置。增强信号具有用于增强谱区域的谱值,其中用于增强谱区域的谱值未包含于位于输入信号输入600处的原始输入信号中。该装置包括映射器602,其用于将输入信号的源谱区域映射至增强谱区域中的目标区域,其中源谱区域包括噪声填充区域。
此外,该装置包括噪声填充器604,用于生成用于输入信号的源谱区域中的噪声填充区域的第一噪声值,并用于生成用于目标区域中的噪声区域的第二噪声值,其中第二噪声值,即目标区域中的噪声值,与噪声填充区域中的第一噪声值相独立或不相关或解相关。
一个实施例涉及如此情况,其中,噪声填充实际上在基带中执行,即其中已经通过噪声填充生成了源区域中的噪声值。在进一步的可选项中,假设尚未执行在源区域中的噪声填充。然而,源区域具有实际上以被源或核心编码器示例性地编码为谱值的类噪声谱值填充的噪声区域。将此类噪声源区域映射至增强区域也将在源区域和目标区域中生成相依噪声。为了解决此问题,噪声填充器仅将噪声填充至映射器的目标区域,即生成用于目标区域中的噪声区域的第二噪声值,其中第二噪声值与源区域中的第一噪声值解相关。此替换或噪声填充也可在源块元缓冲区(sourcetilebuffer)中发生或在目标本身中发生。通过分析源区域或通过分析目标区域,分类器可识别噪声区域。
为此,参照图3a。图3a示出填充区域,如输入信号中的缩放因子或噪声填充带301,并且噪声填充器在输入信号的解码操作中生成此噪声填充带301中的第一噪声谱值。
此外,映射此噪声填充带301至目标区域,即,依照在先技术,映射所生成的噪声值至目标区域,以及因此目标区域将具有与源区域相依或相关的噪声。
然而,依照本发明,图6的噪声填充器604生成用于目的或目标区域中的噪声区域的第二噪声值,其中第二噪声值与图3a的噪声填充带301中的第一噪声值解相关或不相关或相独立。
通常,噪声填充和用于映射源谱区域至目的区域的映射器可被包含于在集成间隙填充中的如在图1a至图5c的上下文中示例性地示出的高频再生器中,或可以被实施为如图13b中示出的后置处理器以及图13a中的对应编码器。
通常,输入信号经受反量化700或任意其他或额外的预定义解码器处理,这意味着在块700的输出处获取图6的输入信号,以使得至核心编码器噪声填充块或噪声填充器块704的输入是图6的输入600。图6中的映射器602对应(例如具体实施为)图7或图8中的间隙填充或带宽扩展块,以及独立噪声填充块702也包含在图6的噪声填充器604中。因此,块704和块702都包含在图6的噪声填充器块604中,并且块704生成用于噪声填充区域中的噪声区域的所谓第一噪声值,以及块702生成第二噪声值用于目的或目标区域中的噪声区域,其通过由图6中的映射器602或图7或图8中的间隙填充或带宽扩展块执行的带宽扩展而得自于基带中的噪声填充区域。此外,如后面所讨论,通过以控制线706示出的控制向量phi控制通过块702执行的独立噪声填充操作。
1.步骤:噪声识别
在第一步骤中,识别代表所传输的音频帧中的噪声的所有谱线。识别过程可由被噪声填充[4][5]使用的已存在的所传输的噪声位置的知识来控制,或可以以额外分类器识别。噪声线识别的结果是包含零和一的向量,其中具有一的位置指示代表噪声的谱线。
以数学术语可描述此过程为:
使
分类器c0确定谱线,其中使用在核心区域中的噪声填充[4][5]:
且结果
额外分类器c1可以识别代表噪声的
在噪声识别过程后,噪声指示向量
2.步骤:独立噪声
在第二步骤中,选择并复制所传输的谱的特定区域至源块元中。在该源块元内,所识别的噪声被替换为随机噪声。插入的随机噪声的能量被调节为与源块元中的原始噪声的相同能量。
以数学术语可描述此过程为:
使n,n<m作为用于在步骤3中描述的复制过程的起始线。使
此时,以随机生成的合成噪声替换所识别的噪声。为了以相同水平保持谱能量,首先计算由
如果e=0,跳过用于源块元
其中
然后计算插入的随机数的能量e′:
如果e′>0,计算因子g,否则设置g=0:
利用g,再缩放所替换的噪声:
在噪声替换后,源块元
3.步骤:复制
将源块元
或者,如果使用igf方案[8]:
图8示出实施例,其中,在诸如图1b中的块112中示出的谱域解码的任意后置处理之后,或在由图13b中的块1326示出的后置处理器实施例中,输入信号首先经受间隙填充或带宽扩展,即首先经受映射操作以及,然后,即在全频谱中执行独立噪声填充。
在以上的图7的上下文中描述的过程可作为就地操作(inplaceoperation)来完成,以使得不需要中间缓冲区
执行如图7的上下文中描述的第一步骤,再次,
2.步骤:复制
或者,如果使用igf方案[8]:
0≤i<v,c≥n,0<k i<n,c i<m<n
3.步骤:独立噪声填充
执行传统噪声填充直至n,并计算在源区域中的噪声谱线k,k 1,...,k v-1的能量:
在间隙填充或bwe谱区域中执行独立噪声填充:
其中r[i],0≤i<v再次为随机数的集合。
计算插入的随机数的能量e′:
再次,如果e′>0,计算因子g,否则设置g:=0:
利用g,再缩放所替换的噪声:
本发明的独立噪声填充也可以在立体声声道对环境(stereochannelpairenvironment)中使用。因此,编码器计算适当的声道对表示、l/r或m/s、每频带以及可选预测系数。解码器在所有频带至l/r表示的最终转换的随后计算之前将如上所述的独立噪声填充应用于声道的适当选中的表示。
本发明可应用于或适用于其中全带宽不可用或使用用于填充谱孔的间隙填充的所有音频应用。本发明可找到在音频内容的分布或播放中的使用,例如利用数字无线电、因特网流以及音频通信应用。
随后,关于图9至图12讨论本发明的实施例。在步骤900中,在源范围中识别噪声区域。之前已经关于“噪声识别”讨论的此过程可完全依靠从编码器侧接收的噪声填充辅助信息,或也可被配置为可选地或额外地依靠已经生成的但不具有用于增强谱区域的谱值(即不具有用于此增强的谱区域的谱值)的输入信号的信号分析。
然后,在步骤902中,将已经经受本领域公知的简单噪声填充的源范围即完整的源范围复制至源块元缓冲区。
然后,在步骤904中,在源块元缓冲区中以随机值替换第一噪声值,即在输入信号的噪声填充区域内生成的简单噪声值。然后,在步骤906中,在源块元缓冲区中缩放这些随机值,以获取用于目标区域的第二噪声值。随后,在步骤908中,执行映射操作,即在步骤904和步骤906之后可用的源块元缓冲区的其内容被映射至目的范围。因此,通过替换操作904,以及在映射操作908之后,已经实现在源范围中以及在目标范围中的独立噪声填充操作。
图10示出本发明的另外的实施例。再次,在步骤900中,识别源范围中的噪声。然而,此步骤900的功能与图9中的步骤900的功能不同,因为图9中的步骤900可对已接收到噪声值(即其中已执行噪声填充操作)的输入信号谱进行操作。
然而,在图10中,未执行对输入信号的任意噪声填充操作,并且输入信号在步骤902的输入处的噪声填充区域中还没有任何噪声值。在步骤902中,映射源范围至目的或目标范围,其中噪声填充值并未包括在源范围中。
因此,通过识别信号中的零谱值和/或通过使用来自输入信号的此噪声填充辅助信息,即编码器侧生成的噪声填充信息,可关于噪声填充区域执行步骤900中的在源范围中的噪声的识别。然后,在步骤1004中,读取噪声填充信息,并且特别地,读取识别待被引入至解码器侧输入信号的能量的能量信息。
然后,如步骤1006中所示出,执行在源范围中的噪声填充,并且随后或同时执行步骤1008,即将随机值插入至目的范围中的位置,其已在全部频带上通过步骤900而被识别或已通过使用基带或输入信号信息以及映射信息即映射源范围中哪个(哪些)至目标范围中哪个(哪些)而被识别。
最后,缩放所插入的随机值以获取第二独立的或不相关的或解相关的噪声值。
随后,为了说明关于增强谱区域中的噪声填充值的缩放(即如何从随机值获取第二噪声值)的进一步信息,论述图11。
在步骤1100中,获取关于源范围中的噪声的能量信息。然后,从随机值即从通过如步骤1102中示出的随机或伪随机过程生成的值确定能量信息。此外,步骤1104示出如何计算缩放因子的方法,即通过使用关于源范围中的噪声的能量信息并通过使用关于随机值的能量信息。然后,在步骤1106中,将通过步骤1104生成的缩放因子与随机值(即在步骤1102中已从其计算能量)相乘。因此,图11中示出的过程对应之前在实施例中示出的缩放因子g的计算。然而,所有这些计算也可在对数域或在任意其他域中执行,并且可以以对数范围中的加法或减法运算替换相乘步骤1106。
进一步参考图12,以示出在一般智能间隙填充或带宽扩展方案中嵌入本发明。在步骤1200中,从输入信号恢复谱包络信息。例如,谱包络信息可由图13a的参数提取器1306生成以及可由图13b的参数解码器1324提供。然后,使用如在1202中示出的此谱包络信息缩放目的范围中的第二噪声值和其他值。随后,在带宽扩展或在智能间隙填充的上下文中具有减少数量的谱孔或没有谱孔的情况下,可执行任意其他的后置处理1204以获取具有增加的带宽的最终时域增强信号。
在此上下文中,概述出,特别地对于图9的实施例,可应用多个可选项。对于实施例,利用输入信号的全部谱或至少利用输入信号的在噪声填充边界频率上的谱部分,执行步骤902。此频率确保在低于某频率即低于此频率时根本不执行任何噪声填充。
然后,不管任意特定源范围/目标范围映射信息,全部输入信号谱即完整的潜在源范围被复制至源块元缓冲区902,并随后利用步骤904、步骤906以及步骤908进行处理,然后从该源块元缓冲区中选择某些特别需要的源区域。
然而,在其他实施例中,基于包括在输入信号中的即作为辅助信息与此音频输入信号关联的源范围/目标范围信息,仅将可以是输入信号的仅部分的特别需要的源范围复制至单个源块元缓冲区或至多个个别源块元缓冲区。根据此情况,第二可选项,其中仅通过步骤902、904以及906处理特别需要的源范围,与独立于特定映射情况的总是通过步骤902、904以及906处理至少在噪声填充边界频率上的全部源范围的情况相比,可降低复杂性或至少降低内存需求。
随后,参照图1a至图5c,以示出在谱-时间转换器118之前放置的频率再生器116中的本发明的特定实施。
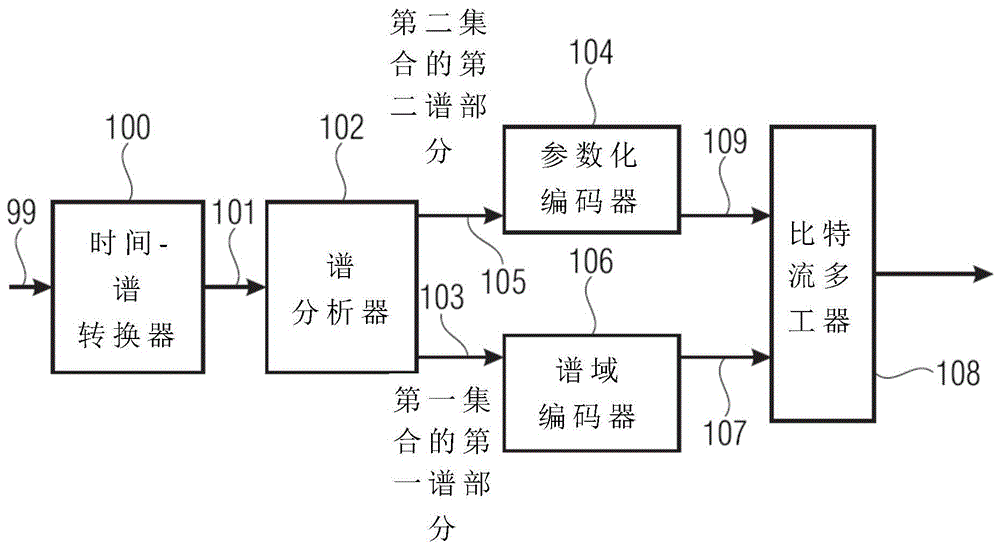
图1a示出用于编码音频信号99的装置。音频信号99被输入至用于将具有采样率的音频信号转换为通过时间谱转换器输出的谱表示101的时间谱转换器100。谱101被输入至用于分析谱表示101的谱分析器102。谱分析器102用于确定待被以第一谱分辨率编码的第一集合的第一谱部分103,以及待被以第二谱分辨率编码的不同的第二集合的第二谱部分105。第二谱分辨率比第一谱分辨率小。将第二集合的第二谱部分105输入至用于计算具有第二谱分辨率的谱包络信息的参数计算器或参数化编码器104。此外,提供谱域音频编码器106,用于生成具有第一谱分辨率的第一集合的第一谱部分的第一编码表示107。此外,参数计算器/参数化编码器104用于生成第二集合的第二谱部分的第二编码表示109。将第一编码表示107和第二编码表示109输入至比特流多工器或比特流形成器108,并且块108最终输出用于传输或在存储设备上存储的经编码的音频信号。
通常,将以两个第二谱部分如307a、307b包围如图3a的306的第一谱部分。此并非是heaac中的情况,其中核心编码器频率范围是频带受限的。
图1b示出匹配图1a的编码器的解码器。将第一编码表示107输入至用于生成第一集合的第一谱部分的第一解码表示的谱域音频解码器112,解码表示具有第一谱分辨率。此外,将第二编码表示109输入至用于生成具有比第一谱分辨率低的第二谱分辨率的第二集合的第二谱部分的第二解码表示的参数化解码器114。
解码器还包括用于使用第一谱部分再生具有第一谱分辨率的重构的第二谱部分的频率再生器116。频率再生器116执行块元填充操作,即使用第一集合的第一谱部分的块元或部分并将此第一集合的第一谱部分复制至具有第二谱部分的重构范围或重构带,并且通常执行如通过由参数化解码器114输出(即通过使用关于第二集合的第二谱部分的信息)的经解码的第二表示指示的谱包络成形或另一操作。将经解码的第一集合的第一谱部分以及如在线117上的频率再生器116的输出处指示的重构的第二集合的谱部分输入至用于将第一经解码的表示以及重构的第二谱部分转换为时间表示119的谱-时间转换器118,时间表示具有某个高采样率。
图2b示出图1a编码器的实施。音频输入信号99被输入至对应于图1a的时间谱转换器100的分析滤波器组220。然后,在tns块222中执行时间噪声成形操作。因此,当不施加时间噪声成形/时间块元成形操作时,至对应于图2b的块音调掩蔽(tonalmask)226的图1a的谱分析器102的输入可以是全部谱值,或当施加如图2b的块222所示出的tns操作时,至对应于图2b的块音调掩蔽226的图1a的谱分析器102的输入可以是谱残余值。对于两声道信号或多声道信号,可额外地执行联合声道编码228,从而图1a的谱域编码器106可包括联合声道编码块228。此外,提供用于执行无损数据压缩的熵编码器232,其也是图1a的谱域编码器106的部分。
谱分析器/音调掩蔽226将tns块222的输出分离为对应于图1a的第一集合的第一谱部分103的核心带和音调分量以及对应于图1a的第二集合的第二谱部分105的残余分量。示出为igf参数提取编码的块224对应图1a的参数化编码器104以及比特流多工器230对应图1a的比特流多工器108。
优选地,分析滤波器组220被实施为mdct(改进的离散余弦变换滤波器组),且mdct被用于利用充当频率分析工具的改进的离散余弦变换将信号99变换至时间-频率域。
谱分析器226优选地应用音调掩蔽。使用此音调掩蔽估计阶段以从信号中的类噪声分量中分离音调分量。此允许核心编码器或联合声道编码器228利用心理声学模块对所有音调分量进行编码。可以以多种不同方式实施音调掩蔽估计阶段,并优选地以其功能类似于在正弦中使用的正弦曲线轨迹估计阶段以及用于语音/音频编码的噪声建模[8,9]或在[10]中描述的基于hiln模型的音频编码器来实施音调掩蔽估计阶段。优选地,使用无需维持生-死轨迹的易于实施的实施方式,但也可使用任意其他音调或噪声检测器。
igf模块计算在源区域和目标区域之间存在的相似性。目标区域将由来自源区域的谱代表。使用互相关方法完成源区域和目标区域之间的相似性的测量。目标区域分裂为ntar个非重叠频率块元。对目标区域中的每个块元,从固定起始频率创建nsrc个源块元。这些源块元以介于0和1之间的因子重叠,其中0意味着0%重叠以及1意味着100%重叠。这些源块元中的每个以各种滞后与目标块元相关,以找到与目标块元最匹配的源块元。最匹配块元编号存储在tilenum[idx_tar]中,其与目标最相关所借以的滞后存储在xcorr_lag[idx_tar][idx_src]中,以及相关性的符号存储在xcorr_sign[idx_tar][idx_src]中。在相关性是高度负的情况中,在解码器的块元填充过程之前,源块元需要与-1相乘。由于使用音调掩蔽保存音调分量,igf模块也考虑不在谱中重写音调分量。逐带(band-wise)能量参数被用于存储目标区域的能量,使得我们能够精确地重构谱。
此方法优于传统的sbr[1],因为多音调信号的谐波网格(harmonicgrid)由核心编码器保存,而仅正弦曲线之间的间隙被以来自源区域的最匹配“成形噪声”填充。此系统相比于asr(精确谱替换)[2-4]的另一优点是缺少了在解码器处创建信号的重要部分的信号合成阶段。相反,核心编码器接手此任务,能够实现谱的重要分量的保存。所提出的系统的另一优点是特征提供的连续缩放能力。对每个块元仅使用tilenum[idx_tar]和xcorr_lag=0被称为总粒度匹配(grossgranularitymatching)并且可用于低比特率,而对每个块元使用变量xcorr_lag使得我们能够更好地匹配目标谱和源谱。
此外,提出块元选择稳定化技术,其移除频率域人为现象如颤音和音乐噪声。
在立体声声道对的情况中,施加额外的联合立体声处理。这是必要的,因为对于某目的范围,信号可以是高度相关的平移声源。假如为此特定区域所选的源区域并非密切相关的,即使能量与目的区域匹配,空间影像会由于不相关的源区域而受到影响。编码器分析每个目的区域能量带,通常执行谱值的互相关,并且如果超出某个阈值,为此能量带设置联合旗标。在解码器中,如果没有设置联合立体声旗标,单独地处理左声道和右声道能量带。在设置了联合立体声旗标的情况中,在联合立体声域中执行能量以及修补。用信号通知用于igf区域的联合立体声信息,类似用于核心编码的联合立体声信息,其在预测的方向是从降混到残余时包括指示预测情况的旗标或反之亦然。
可从在l/r域中的所传输的能量计算能量。
midnrg[k]=leftnrg[k] rightnrg[k];
sidenrg[k]=leftnrg[k]-rightnrg[k];
k是变换域中频率索引。
另一解决方案是对于联合立体声是活跃的频带在联合立体声域中直接计算并传输能量,所以在解码器侧不需要额外的能量变换。
总是根据中间/侧边-矩阵(mid/side-matrix)创建源块元:
midtile[k]=0.5·(lefttile[k] righttile[k])
sidetile[k]=0.5·(lefttile[k]-righttile[k])
能量调节:
midtile[k]=midtile[k]*midnrg[k];
sidetile[k]=sidetile[k]*sidenrg[k];
联合立体声->lr变换:
如果没有额外的预测参数被编码:
lefttile[k]=midtile[k] sidetile[k]
righttile[k]=midtile[k]-sidetile[k]
如果额外的预测参数被编码并且如果信号方向是从中间到侧边:
sidetile[k]=sidetile[k]-predictioncoeff·midtile[k]
lefttile[k]=midtile[k] sidetile[k]
righttile[k]=midtile[k]-sidetile[k]
如果信号方向是从侧边到中间:
midtile1[k]=midtile[k]-predictioncoeff·sidetile[k]
lefttile[k]=midtile1[k]-sidetile[k]
righttile[k]=midtile1[k] sidetile[k]
此处理确保,从用于再生高度相关的目的区域和平移目的区域的块元,即使源区域是不相关的,产生的左声道和右声道仍然代表相关且平移的声源,为此区域保存立体声影像。
换言之,在比特流中,传输指示是否应该使用作为用于一般联合立体声编码的示例的l/r或m/s的联合立体声旗标。在解码器中,首先,如由用于核心带的联合立体声旗标所指示的,解码核心信号。其次,以l/r和m/s表示存储核心信号。对于igf块元填充,选择源块元表示以适应目标块元表示,如由用于igf带的联合立体声信息所指示。
时间噪声成形(tns)是标准技术,并且是acc的部分[11-13]。tns可以被视为是感知编码器的基本方案的扩展,在滤波器组和量化阶段之间插入可选处理步骤。tns模块的主要任务是在类瞬态信号的时间掩蔽区域中隐藏所产生的量化噪声,并因此导致更有效的编码方案。首先,tns在变换域例如mdct中使用“正向预测”计算预测系数的集合。这些系数然后被用于使信号的时间包络变平。由于量化影响经tns滤波的谱,量化噪声也是暂时平直的。通过在解码器侧应用逆tns滤波,根据tns滤波器的时间包络将量化噪声成形,并且因此量化噪声通过瞬态而得到掩蔽。
igf基于mdct表示。为了有效的编码,优选地需要使用大约20ms的长块。如果在此长块中的信号包含瞬态,由于块元填充,在igf谱带中出现可听到的前回声和后回声。通过在igf的上下文中使用tns降低此前回声效应。在此,由于对tns残余信号执行解码器中的谱再生,tns被用作时间块元成形(tts)工具。如往常一样在编码器侧使用全部谱计算并应用所需要的tts预测系数。tns/tts起始及停止频率不受igf工具的igf起始频率figfstart的影响。相比传统的tns,tts停止频率增长至比figfstart高的igf工具的停止频率。在解码器侧,将tns/tts系数再次应用于全部谱,即核心谱加上再生谱加上来自音调映射的音调分量。对于形成再生谱的时间包络以再次匹配原始信号的包络,tts的应用是必要的。因此降低所显示的前回声。此外,仍然如往常一样利用tns在figfstart之下的信号中成形量化噪声。
在传统解码器中,通过引入离差,音频信号上的谱修补破坏在修补边界处的谱相关性,并因此损害音频信号的时间包络。因此,对残余信号执行igf块元填充的另一好处是,在成形滤波器的应用之后,块元边界是无缝相关的,导致信号的更可靠的时间再现。
在所发明的编码器中,除了音调分量之外,已经经过tns/tts滤波、音调掩蔽处理以及igf参数估计的谱毫无在igf起始频率之上的任意信号。此时,通过使用算术编码和预测编码的原理的核心编码器编码此稀疏的谱。这些经编码的分量与信号比特一起形成音频的比特流。
图2a示出对应的解码器实施。将对应于经编码的音频信号的图2a中的比特流输入至(关于图1b)与块112和114连接的解多工器/解码器。比特流解多工器将输入的音频信号分离为图1b的第一编码表示107和图1b的第二编码表示109。将具有第一集合的第一谱部分的第一编码表示输入至与图1b的谱域解码器112对应的联合声道解码块204。将第二编码表示输入至未在图2a中示出的参数化解码器114,并随后输入至与图1b的频率再生器116对应的igf块202。通过线203将频率再生所需的第一集合的第一谱部分输入至igf块202。此外,在联合声道解码204之后,在音调掩蔽块206中应用特定核心解码,以使得音调掩蔽206的输出对应谱域解码器112的输出。然后,执行由组合器208进行的组合即帧建立,其中组合器208的输出此时具有全部范围谱,但仍然处于经tns/tts滤波的域中。然后,在块210中,使用通过线109提供的tns/tts滤波器信息执行逆tns/tts操作,即tts辅助信息优选地包含在由谱域编码器106(例如可以是简单aac或usac核心编码器)生成的第一编码表示中,或者也可以包含在第二编码表示中。在块210的输出处,提供直至最大频率的完整谱,其是通过原始输入信号的采样率定义的全部范围频率。然后,在合成滤波器组212中执行谱/时间转换,以最终获取音频输出信号。
图3a示出谱的示意性表示。在图3a的所示示例中,在有七个缩放因子带scb1至scb7的缩放因子带scb中细分谱。缩放因子带可以是以aac标准定义的aac缩放因子带并且对较上频率具有增大的带宽,如图3a示意地示出。优选地,不从谱的最开始即在低频处执行智能间隙填充,而是在309示出的igf起始频率处开始igf操作。因此,核心频带从最低频率扩展至igf起始频率。在igf起始频率之上,应用谱分析以从由第二集合的第二谱部分代表的低分辨率分量中分离高分辨率谱分量304、305、306以及307(第一集合的第一谱部分)。图3a示出被示例性输入至谱域编码器106或联合声道编码器228的谱,即核心编码器在全部范围内操作,但是编码大量的零谱值,即这些零谱值被量化至零或在量化前或量化后被设置为零。无论如何,核心编码器在全部范围内操作,即好像谱将如所示出的那样,即核心解码器不必意识到具有较低的谱分辨率的第二集合的第二谱部分的任意智能间隙填充或编码。
优选地,通过谱线如mdct线的逐行编码(line-wisecoding)定义高分辨率,而通过例如每缩放因子带仅计算单个谱值来定义第二分辨率或低分辨率,其中缩放因子带覆盖多条频率线。因此,第二低分辨率关于其谱分辨率比由通常通过核心编码器如aac或usac核心编码器应用的逐行编码定义的第一或高分辨率低的多。
关于缩放因子或能量计算,图3b中示出该情况。由于编码器是核心编码器的事实,以及由于在每个频带中可以但不必存在第一集合的谱部分中的分量的事实,核心编码器不仅在igf起始频率309以下的核心范围内也在igf起始频率以上直至最大频率figfstop(其小于或等于采样频率的一半即fs/2)计算用于每个频带的缩放因子。因此,图3a的经编码的音调部分302、304、305、306以及307,以及在此实施例中与缩放因子scb1至scb7一起对应高分辨率谱数据。低分辨率谱数据从igf起始频率开始计算,并对应与缩放因子sf4至sf7一起传输的能量信息值e1、e2、e3以及e4。
特别地,当核心编码器在低比特率条件下时,可额外施加在核心带(即频率比igf起始频率低,即在缩放因子带scb1至scb3中)中的额外噪声填充操作。在噪声填充中,存在已被量化为零的多条相邻谱线。在解码器侧,再合成这些被量化为零的谱值,并且使用噪声填充能量如在图3b中的308处所示出的nf2,这些再合成的谱值的幅度被调节。可以以绝对项或相对项(特别是关于如在usac中的缩放因子)给定的噪声填充能量对应于被量化为零的谱值的集合的能量。这些噪声填充谱线也可被视为第三集合的第三频谱部分,使用来自源范围和能量信息e1、e2、e3以及e4的谱值,无需依赖于使用用于重构频率块元的来自其他频率的频率块元的频率再生的任意igf操作,通过简单噪声填充合成再生该第三集合的第三频谱部分。
优选地,频带(为其计算了能量信息)与缩放因子带相一致。在其他实施例中,应用能量信息值成组,以使得例如对于缩放因子带4和5仅传输单个能量信息值,但即使在此实施例中,成组的重构带的边界与缩放因子带的边界相一致。如果应用不同的带分离,则可应用某些再计算或同步计算,并且根据某实施这是合理的。
优选地,图1a的谱域编码器106是如图4a中所示出的心理声学驱动编码器。通常地,如在mpeg2/4aac标准或mpeg1/2,layer3标准中所示出,在已被传输至谱范围(图4a中的401)之后,待被编码的音频信号被转发至缩放因子计算器400。缩放因子计算器被额外接收待被量化的音频信号或如以mpeg1/2layer3或mpegaac标准接收音频信号的复杂谱表示的心理声学模型控制。心理声学模型为每个缩放因子带计算代表心理声学阈值的缩放因子。此外,随后通过已知的内部和外部迭代循环的协作或通过任意其他适合的编码过程调整缩放因子,从而满足某些比特流条件。然后,一方面待被量化的谱值,另一方面计算的缩放因子,被输入至量化器处理器404。在简单音频编码器操作中,通过缩放因子对待被量化的谱值进行加权,并随后将加权的谱值输入至通常具有对较上幅度范围的压缩功能的固定量化器。然后,在量化器处理器的输出处,的确存在随后将被转发至熵编码器的量化索引,熵编码器通常对于用于相邻频率值的零量化索引集合具有特定且非常有效的编码或如在本技术领域也被称为零值的“运行(run)”。
然而,在图1a的音频编码器中,量化器处理器通常从谱分析器接收关于第二谱部分的信息。因此,量化器处理器404确保在量化器处理器404的输出中,由谱分析器102识别的第二谱部分为零或具有被编码器或解码器认可为零表示的表示,该零表示可被非常有效地编码,特别是在谱中存在零值的“运行”时。
图4b示出量化器处理器的实施。可将mdct谱值输入至设置为零块410。然后,在执行通过加权块412中的缩放因子的加权之前,第二谱部分已被设为零。在额外实施中,不提供块410,但是在加权块412之后在块418中执行设置为零的协作。在又一实施中,也可在量化器块420中的量化之后在设置为零块422中执行设置为零的操作。在此实施中,不呈现块410和块418。一般地,根据特定的实施提供块410、418和422中的至少一个。
然后,在块422的输出处,对应于图3a中所示出的事物,获取量化的谱。随后,将此量化的谱输入至熵编码器,如图2b中的232,其可以是huffman编码器或例如以usac标准定义的算数编码器。
相互替代或并行地提供的设置为零块410、418以及422受谱分析器424的控制。优选地,谱分析器包括已知音调检测器的任意实施或包括可操作地用于将谱分离为具有高分辨率的待被编码的分量和具有低分辨率的待被编码的分量的任意不同种类的检测器。根据关于对不同谱部分的分辨率需求的谱信息或关联元数据,在谱分析器中实施的其他此种算法可以是声音激活检测器、噪音检测器、语音检测器或任意其他检测器决策。
图5a示出图1a的时间谱转换器100的优选实施,例如实施在aac或usac中。时间谱转换器100包括由瞬态检测器504控制的加窗器502。当瞬态检测器504检测到瞬态时,则从长窗口至短窗口的切换被信号通知给加窗器。然后,加窗器502计算用于重叠块的窗口帧,其中每个窗口帧通常具有2n个值如2048个值。然后在块变换器506中执行变换,并且此块变换器通常额外提供小数式采样(decimation),以执行组合的小数式采样/变换从而获取具有n个值如mdct谱值的谱帧。因此,对于长窗口操作,在块506的输入处的帧包括2n个值如2048个值,并且谱帧然后具有1024个值。然而,然后执行至短块的切换,当执行八个短块时,其中每个短块相比于长窗口具有1/8窗口的时域值,以及每个谱块相比于长块具有1/8的谱值。因此,当此小数式采样与加窗器的50%的重叠操作相组合时,谱是时域音频信号99的临界采样版本。
随后,参照图5b,图5b示出图1b的频率再生器116和谱-时间转换器118或图2a的块208和212的组合操作的特定实施。在图5b中,考虑特定的重构带如图3a的缩放因子带6。此重构带中的第一谱部分即图3a的第一谱部分306被输入至帧建立器/调节器块510。此外,也将用于缩放因子带6的重构的第二谱部分输入至帧建立器/调节器块510。此外,用于缩放因子带6的能量信息如图3b的e3也被输入至块510。已经使用源范围通过频率块元填充生成重构带中的重构的第二谱部分,并且重构带然后对应目标范围。此时,执行帧的能量调节以最终获取具有(如,例如在图2a的组合器208的输出处获取到的)n个值的完全重构的帧。然后,在块512中,执行逆块变换/插补以获取用于例如在块512的输入处的124个谱值的248个时域值。然后,在再次被作为辅助信息传输在经编码的音频信号中的长窗口/短窗口指示所控制的块514中执行合成加窗操作。然后,在块516中,执行对在先时间帧的重叠/相加操作。优选地,mdct应用50%的重叠,以使得对于2n个值中的每个新的时间帧,最终输出n个时域值。特别优选50%的重叠,因为如此事实:由于块516中的重叠/相加操作,提供了从一个帧到下一个帧的临界采样以及连续交叉。
如图3a中301所示,不仅在igf起始频率之下也可在igf起始频率之上,如对于与图3a的缩放因子带6一致的所考虑的重构带,可额外施加噪声填充操作。然后,也可将噪声填充谱值输入至帧建立器/调节器510,并可在此块中施加噪声填充谱值的调节或噪声填充谱值可在被输入至帧建立器/调节器510之前已使用噪声填充能量而被调节。
优选地,可在完整谱中施加使用来自其他部分的谱值的igf操作即频率块元填充操作。因此,不仅可在igf起始频率之上的高频带中,还可以在低频带中施加谱块元填充操作。此外,不仅可在igf起始频率之下,还可在igf起始频率之上施加不经频率块元填充的噪声填充。然而,已经发现,当噪声填充操作受限于在igf起始频率之下的频率范围时,以及当频率块元填充操作受限于在图3a中所示的igf起始频率之上的频率范围时,可实现高质量和高效率的音频编码。
优选地,目标块元(tt,targettiles)(具有大于igf起始频率的频率)受到全速率编码器的缩放因子带边界的约束。源块元(st,sourcetiles)(从其取得信息,即用于低于igf起始频率的频率)不受缩放因子带边界的约束。st的尺寸应对应关联tt的尺寸。此使用下面的示例示出。tt[0]具有十个mdct频格(bin)的长度。此正好对应两个后续scb的长度(如4 6)。然后,与tt[0]相关的所有可能st也具有十个频格的长度。与tt[0]相邻的第二目标块元tt[1]具有15个频格i的长度(scb具有7 8的长度)。然后,为此st具有15个频格的长度而不是如对于tt[0]的10个频格的长度。
如果发生以目标块元长度无法找到对于的st的tt的情况(当例如tt的长度大于可用源范围时),则不计算相关性,并且多次复制源范围至此tt(依次完成复制,以使得用于第二次复制的最低频的频率线-以频率-直接跟随用于第一次复制的最高频的频率线),直到目标块元tt被完全填充。
随后,参照图5c,图5c示出图1b的频率再生器116或者图2a的igf块202的另一优选实施例。块522是不仅接收目标带id且额外接收源带id的频率块元生成器。示例性地,在编码器侧已经确定,图3a的缩放因子带3非常适合用于对缩放因子带7进行重构。因此,源带id可以是2,以及目标带id可以是7。基于此信息,频率块元生成器522施加复制或谐波块元填充操作或任意其他块元填充操作以生成谱分量的未经处理的第二部分523。谱分量的未经处理的第二部分具有与包含在第一集合的第一谱部分中的频率分辨率相同的频率分辨率。
然后,将重构带的第一谱部分如图3a的307输入至帧建立器524,并将未经处理的第二部分523输入至帧建立器524。然后,使用由增益因子计算器528计算的用于重构带的增益因子,通过调节器526调节重构的帧。然而,重要的是,帧中的第一谱部分不受调节器526的影响,而仅用于重构帧的未经处理的第二部分受调节器526的影响。鉴于此,增益因子计算器528分析源带或未经处理的第二部分523,并额外分析重构带中的第一谱部分,以最终找到合适的增益因子527,以使得在考虑缩放因子带7时由调节器526输出的经调节的帧的能量具有能量e4。
在此上下文中,与he-aac相比,评价本发明的高频重构准确性是非常重要的。关于图3a中的缩放因子带7解释此。假设如图13a所示的在先技术编码器将检测作为“缺失的谐波(missingharmonics)”的具有高分辨率的待被编码的谱部分307。然后,此谱分量的能量将与用于重构带例如缩放因子带7的谱包络信息一起被传输至解码器。然后,解码器将重建缺失的谐波。然而,缺失的谐波307将被图13b的在先技术解码器重构时所处的谱值将处于在由重构频率390指示的频率处的频带7的中间。因此,本发明避免将会由图13b的在先技术解码器引入的频率误差391。
在实施中,谱分析器也被实施以计算第一谱部分和第二谱部分之间的相似性,并基于计算的相似性为重构范围中第二谱部分确定与第二谱部分尽可能匹配的第一谱部分。然后,在此可变源范围/目的范围的实施中,参数化编码器额外地把为每个目的范围指示匹配源范围的匹配信息引入至第二编码表示中。在解码器侧,基于源带id和目标带id,示出未经处理的第二部分523的生成的图5c中的频率块元生成器522然后将使用此信息。
此外,如图3a中所示,谱分析器用于分析谱表示上达至最大分析频率,其仅少量地低于采样频率的一半且优选地为采样频率的至少四分之一或通常更高。
如所示,编码器未降采样(downsample)地操作,且解码器未升采样(upsample)地操作。换言之,谱域音频编码器用于生成具有由原始输入音频信号的采样率定义的奈奎斯特频率(nyquistfrequency)的谱表示。
此外,如图3a所示,谱分析器用于分析以间隙填充起始频率为起始并以由包含在谱表示中的最大频率代表的最大频率为终止的谱表示,其中从最小频率扩展至间隙填充起始频率的谱部分属于第一集合的谱部分,并且其中具有在间隙填充频率之上的频率值的其他谱部分如304、305、306以及307额外地包括在第一集合的第一谱部分中。
如概述的,配置谱域音频解码器112,以使得由第一解码表示中的谱值代表的最大频率等于包含在具有采样率的时间表示中的最大频率,其中用于第一集合的第一谱部分中的最大频率的谱值为零或与零不同。无论如何,对于在第一集合的谱分量中的此最大频率,存在用于缩放因子带的缩放因子,不管此缩放因子带中的所有谱值是否被设置为零,生成并传输该缩放因子,如图3a和图3b的上下文中所讨论。
因此,本发明关于其他参数化技术对于增加压缩效率有益的,例如噪声替换以及噪声填充(这些技术唯一地用于类噪声本地信号内容的有效表示),本发明允许音调分量的准确频率再现。至今,没有现有技术通过谱间隙填充且不对低频带(lf)和高频带(hf)中的固定优先划分进行限制来提出任意信号内容的有效参数化表示。
本发明的系统的实施例改进现有技术方法,并因此提供高压缩效率,没有或仅有小的感知干扰以及甚至用于低比特率的全音频带宽。
一般系统包括
·全频带核心编码
·智能间隙填充(块元填充或噪声填充)
·通过音调掩蔽选择的核心中的稀疏音调部分
·用于全频带的联合立体声对编码,包括块元填充
·块元上的tns
·在igf范围中的谱增白
朝向更有效的系统的第一步骤是移除对于将谱数据变换至与核心编码器中的变换域不同的第二变换域的需求。由于音频编解码器的大多数(例如aac)使用mdct作为基础变换,在mdct域中执行bwe是有用的。对于bwe系统的第二需求是对保存音调网格的需要,借此甚至保存hf音调分量且经编码的音频的质量因此优于现有系统。为了考虑上面提及的两种需求,提出称为智能间隙填充(igf)的系统。图2b显示在编码器侧的所提出的系统的框图,以及图2a显示在解码器侧的系统。
随后,关于图13a和图13b描述后置处理架构,以示出本发明也可在此后置处理实施例中的高频重构器1330中实施。
图13a示出例如在高效先进音频编码(he-aac)中使用的用于带宽扩展技术的音频编码器的框图。在线1300处的音频信号被输入至包括低通1302以及高通1304的滤波器系统。通过高通滤波器1304输出的信号被输入至参数提取器/编码器1306。参数提取器/编码器1306用于计算和编码诸如谱包络参数、噪声附加参数、缺失的谐波参数或逆滤波参数的参数。这些提取的参数被输入至比特流多工器1308。低通输出信号被输入至通常包括降采样器1310和核心编码器1312的功能的处理器。低通1302将待被编码的带宽限制为比在线1300上的原始输入音频信号中出现的显著地小的带宽。由于出现在核心编码器中的全部功能仅需要对具有减小的带宽的信号进行操作的事实,此提供显著编码增益。例如,当线1300上的音频信号的带宽是20khz时,并且当低通滤波器1302示例性地具有4khz的带宽时,为了满足采样定理,在理论上,降采样器之后的信号具有8khz的采样频率已足以,这实质减小了音频信号1300所需的必须为至少40khz的采样率。
图13b示出对应的带宽扩展解码器的框图。解码器包括比特流多工器1320。比特流解多工器1320提取用于核心解码器1322的输入信号以及用于参数解码器1324的输入信号。在上面的示例中,核心解码器输出信号具有8khz的采样率,并且因此具有4khz的带宽,而为了完整的带宽重构,高频重构器1330的输出信号必须位于需要至少40khz的采样率的20khz。为了使其成为可能,需要具有升采样器1325和滤波器组1326的功能的解码器处理器。然后,高频重构器1330接收由滤波器组1326输出的经频率分析的低频信号,并使用高频带的参数化表示对由图13a的高通滤波器1304定义的频率范围进行重构。高频重构器1330具有多个功能例如在低频范围中使用源范围的较上频率范围的再生、谱包络调节、噪声附加功能以及用于在较上频率范围中引入缺失的谐波的功能,以及当应用并计算于图13a的编码器中时的为了解释较高频范围通常并非是像较低频范围那样的音调的事实的逆滤波操作。在he-aac中,缺失的谐波在解码器侧被再合成,并正好被放置在重构带的中间。因此,在某个重构带中已确定的所有缺失的谐波线并未被放置于它们在原始信号中所位于的频率值处。相反,那些缺失的谐波线被放置在某个频带的中心的频率处。因此,当原始信号中的缺失的谐波线被放置为非常接近原始信号中的重构带边界时,通过将重构的信号中的此缺失的谐波线放置在频带的中心处而引入的频率中的误差接近单个重构带(为此生成并传输参数)的50%。
此外,即使在谱域中操作典型的音频核心编码器,核心解码器仍然生成随后被滤波器组1326功能再次转换为谱域的时域信号。由于首先从谱域变换至频域并再次变换至通常不同的频域的串联处理,此引入额外处理延迟,可引入人工现象,并且,当然,此也需要大量的计算复杂度并因此需要电力,当在移动装置如手机、平板电脑或笔记本电脑等中应用带宽扩展技术时这尤其是问题。
虽然在用于编码或解码的装置的上下文中描述了一些方面,显然,这些方面也代表对应方法的描述,其中块或装置对应方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中描述的方面也代表对应装置的对应块或项或特征的描述。通过(或使用)硬件装置例如微处理器、可编程计算机或电子电路可执行方法步骤的一些或全部。在一些实施例中,通过如此装置可执行一些一个或多个最重要的方法步骤。
根据某些实施需求,可在硬件或在软件中实施本发明的实施例。可使用在其上存储有电子可读控制信号的非易失存储介质如数字存储介质(如软盘、硬盘驱动器(hdd)、dvd、蓝光光碟、cd、rom、prom及eprom、eeprom或闪存)执行实施,其(或能够)与可编程计算机系统协作从而执行各个方法。因此,数字储存介质可以是计算机可读的。
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,其能够与可编程计算机系统协作,以执行本文中描述的方法中的一个。
通常,本发明的实施例可实施为具有程序代码的计算机程序产品,当计算机程序产品在计算机上运行时,可操作的程序代码用于执行方法中的一个。程序代码可(例如)存储于计算机可读载体上。
其他实施例包括储存于机器可读载体上的计算机程序,其用于执行本文所述方法中的一个。
换言之,本发明的方法的实施例(因此)是具有程序代码的计算机程序,当该计算机程序在计算机上运行时程序代码用于执行本文描述的方法中的一个。
因此,本发明的方法的另一实施例是一种数据载体(或数字存储介质,或计算机可读介质),其包括记录在其上的用于执行本文描述的方法的一个的计算机程序。数据载体、数字存储介质或记录介质通常是有形的和/或非易失的。
因此,本发明的方法的另一实施例是一种表示用于执行本文所述方法的一个的计算机程序的数据流或信号序列。数据流或信号序列可(例如)用于通过数据通信连接(例如,通过因特网)被传输。
另一实施例包括一种处理构件,例如,计算机或可编程逻辑设备,其用于或适用于执行本文所述方法的一个。
另一实施例包括计算机,其上安装有用于执行本文所述方法中的一个的计算机程序。
根据本发明的另一实施例包括一种装置或系统,其用于将用于执行本文所述方法的一个的计算机程序传输(例如,电子地或光学地)至接收器。接收器可例如是计算机、移动设备、存储设备或类似。此装置或系统可(例如)包括用于将计算机程序传输至接收器的文件服务器。
在一些实施例中,使用一种可编程逻辑设备(例如,现场可编程门阵列)用于执行本文所述方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可与微处理器协作,以便执行本文所述方法中的一个。通常,可通过任何硬件装置优选地执行此方法。
上面描述的实施例仅示出本发明的原理。应理解的是,本文所描述的布置及细节的修改及变形对本领域技术人员是显而易见的。因此,意图在于,仅通过权利要求的范围而不通过本文实施例的描述及说明书的方式呈现的特定细节限制本发明。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

