本发明涉及一种对音响信号进行解析的技术。
背景技术:
以往提出有根据表示乐曲的歌唱音或者演奏音等音响的音响信号对代码(code)进行推定的技术。例如,在专利文献1中公开了基于从输入乐音的波形数据解析出的频谱而对代码进行判定的技术。在专利文献2中公开了对输入音的包含在基本频率的概率密度函数观测到峰值的基本频率的构成音在内的代码进行辨识的技术。在专利文献3中公开了利用进行了机器学习的神经网络而对代码进行推定的技术。
专利文献1:日本特开2000-298475号公报
专利文献2:日本特开2008-209550号公报
专利文献3:日本特开2017-215520号公报
技术实现要素:
假想要求对在乐曲内相同的代码持续的区间(以下,称为“连续区间”)进行推定的情形。还可以根据通过专利文献1至专利文献3的技术而推定出的代码的时间序列对各连续区间进行推定。但是,在基于专利文献1至专利文献3的技术而误推定出代码的情况下,存在还会误推定出连续区间的问题。本发明的一个方式的目的在于,通过音响信号的解析而高精度地对连续区间进行推定。
为了解决以上的课题,本发明的一个方式涉及的音响解析方法取得音响信号的特征量的时间序列,向对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习(训练)的边界推定模型,输入所述取得的所述特征量的时间序列,由此生成边界数据。
本发明的一个方式涉及的音响解析装置具有:特征取得部,其取得音响信号的特征量的时间序列;以及边界推定模型,其是对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习(训练)的训练好的模型,且针对由所述特征取得部所取得的所述特征量的时间序列的输入而生成边界数据。
本发明的一个方式涉及的模型构建方法取得包含特征量的时间序列和表示代码持续的连续区间的边界的边界数据在内的多个教师数据,通过利用所述多个教师数据的机器学习,构建对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习的边界推定模型。
附图说明
图1是例示出第1实施方式涉及的音响解析装置的结构的框图。
图2是例示出音响解析装置的功能性结构的框图。
图3是特征量以及边界数据的说明图。
图4是特征量的说明图。
图5是例示出边界推定处理的具体流程的流程图。
图6是学习处理部的动作的说明图。
图7是例示出通过机器学习而构建边界推定模型的处理的具体流程的流程图。
具体实施方式
a:第1实施方式
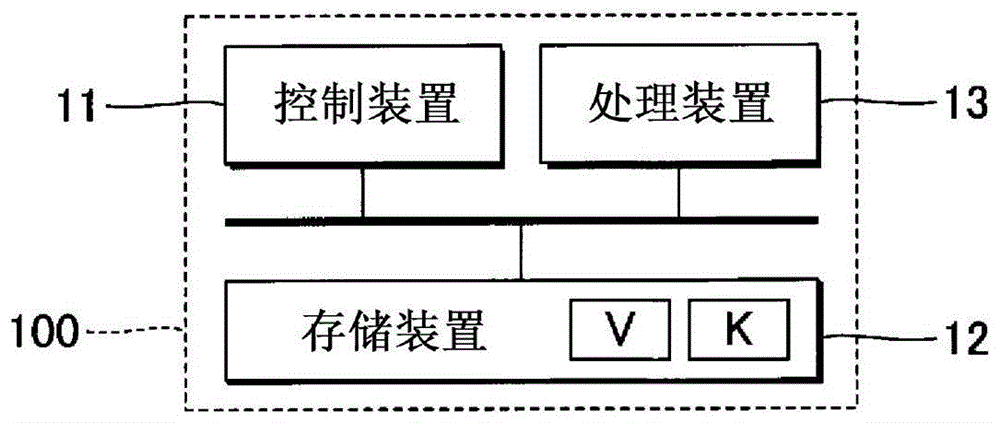
图1是例示出第1实施方式涉及的音响解析装置100的结构的框图。音响解析装置100是通过对表示乐曲的歌唱音或者演奏音等音响的音响信号v进行解析,从而对该乐曲中的各连续区间进行推定的信息处理装置。连续区间意味着1个代码持续的一系列区间。在乐曲内能推定出多个连续区间。
音响解析装置100通过具有控制装置11、存储装置12和处理装置13的计算机系统而实现。例如,移动电话、智能机或者个人计算机等信息终端作为音响解析装置100而利用。处理装置13是执行与对音响信号v进行解析得到的结果相对应的处理的电子设备。处理装置13例如是对根据音响信号v推定出的各连续区间进行显示的显示装置。
控制装置11由对音响解析装置100的各要素进行控制的单个或者多个处理器构成。例如,控制装置11由cpu(centralprocessingunit)、spu(soundprocessingunit)、dsp(digitalsignalprocessor)、fpga(fieldprogrammablegatearray)、或者asic(applicationspecificintegratedcircuit)等1种以上的处理器构成。存储装置12例如是由磁记录介质或者半导体记录介质等公知的记录介质构成的单个或者多个存储器,对控制装置11执行的程序和控制装置11使用的各种数据进行存储。例如,存储装置12对音响信号v进行存储。此外,也可以由多种记录介质的组合构成存储装置12。另外,也可以将相对于音响解析装置100能够拆装的可移动型记录介质、或者能够经由通信网与音响解析装置100进行通信的外部记录介质(例如,网络硬盘)作为存储装置12而利用。
图2是例示出通过由控制装置11执行在存储装置12存储的程序而实现的功能的框图。控制装置11实现特征取得部21、边界推定模型22、学习处理部23和动作控制部24。此外,也可以通过相互分体地构成的多个装置而实现控制装置11的功能。也可以通过专用的电子电路而实现控制装置11的功能的一部分或者全部。
特征取得部21从存储于存储装置12的音响信号v对特征量y进行提取。如图3所例示的那样,特征量y针对每个单位期间t(t1,t2,t3,…)进行提取。即,根据音响信号v生成特征量y的时间序列。单位期间t例如是与乐曲的1拍相当的期间。但是,也可以与乐曲的拍点无关地对固定长度或者可变长度的单位期间t进行划分。
各单位期间t的特征量y是表示音响信号v中的与该单位期间t内的部分相关的音响的特征的指标。如图4所例示的那样,第1实施方式的特征量y包含半音阶矢量q和强度p。半音阶矢量q是包含与不同的音阶音(具体而言,平均律的12半音)相对应的12个成分强度q1~q12的12维矢量。音阶音是忽略了八度音的差异的音名(音高等级:pitchclass)。构成半音阶矢量q的任意1个成分强度qn(n=1~12)是将在音响信号v中与第n个音阶音相对应的音响成分的强度遍及多个八度音范围相加得到的数值。特征量y所包含的强度p是遍及音响信号v的整个频带的音量或者功率。
如图2所例示的那样,特征取得部21所生成的特征量y的时间序列被输入至边界推定模型22。边界推定模型22是对特征量y的时间序列和边界数据b的关系进行学习(训练)得到的训练好的模型。即,边界推定模型22通过特征量y的时间序列的输入而输出边界数据b。边界数据b是表示时间轴上的各连续区间的边界的时间序列数据。
如图3所例示的那样,边界数据b由与时间轴上的各单位期间t(t1,t2,t3,…)相对应的单位数据b的时间序列构成。针对各单位期间t的每个特征量y,从边界推定模型22输出1个单位数据b。与各单位期间t相对应的单位数据b是以2值方式表示与该单位期间t相对应的时间点是否属于连续区间的边界的数据。例如,与任意1个单位期间t相对应的单位数据b在该单位期间t的起点为连续区间的边界的情况下,设定为数值1,在该单位期间t的起点不属于连续区间的边界的情况下,设定为数值0。即,单位数据b的数值1意味着与该单位数据b相对应的单位期间t为连续区间的开头。如根据以上说明所理解的那样,边界推定模型22是根据特征量y的时间序列对各连续区间的边界进行推定的统计推定模型。另外,第1实施方式的边界数据b是以2值方式表示时间轴上的多个时间点各自是否属于连续区间的边界的时间序列数据。
边界推定模型22通过使控制装置11执行根据特征量y的时间序列生成边界数据b的运算的程序(例如,构成人工智能软件的程序模块)和应用于该运算的多个系数k的组合而实现。多个系数k通过利用了多个教师数据的机器学习(特别是,深度学习)而设定并存储于存储装置12。例如,适于时间序列数据的处理的长短期记忆(lstm:longshorttermmemory)等循环型神经网络(rnn:recurrentneuralnetwork)作为边界推定模型22而利用。此外,也可以将卷积神经网络(cnn:convolutionalneuralnetwork)等其他种类的神经网络作为边界推定模型22而利用。
图2的动作控制部24与从边界推定模型22输出的边界数据b对应地对处理装置13的动作进行控制。例如,动作控制部24使处理装置13对边界数据b所表示的各连续区间进行显示。
图5是例示出根据音响信号v对各连续区间的边界进行推定的处理(以下,称为“边界推定处理”)的具体流程的流程图。例如,以来自利用者的指示为契机而开始进行边界推定处理。如果开始进行边界推定处理,则特征取得部21从存储于存储装置12的音响信号v针对每个单位期间t而对特征量y进行提取(sa1)。边界推定模型22根据由特征取得部21所提取的特征量y的时间序列,生成边界数据b(sa2)。动作控制部24使处理装置13对从边界推定模型22输出的边界数据b所表示的各连续区间进行显示(sa3)。此外,表示由边界推定模型22推定的结果的显示画面的内容是任意的。例如,音响信号v所表示的乐曲的乐谱以针对该乐曲内的每个连续区间而不同的方式(例如,色彩)进行显示。
图2的学习处理部23通过机器学习(特别是,深度学习)而对边界推定模型22的多个系数k进行设定。学习处理部23通过利用在存储装置12存储的多个教师数据l的机器学习而对多个系数k进行设定。如图6所例示的那样,多个教师数据l各自由特征量y的时间序列和边界数据bx的组合构成。各教师数据l的边界数据bx相当于该教师数据l的针对特征量y的时间序列的正解值,由与特征量y的时间序列相对应的已知的单位数据b的时间序列构成。即,边界数据bx的多个单位数据b中与各连续区间的开头的单位期间t相对应的单位数据b被设定为数值1,与各连续区间的开头以外的单位期间t相对应的单位数据b被设定为数值0。
图7是例示出学习处理部23构建边界推定模型22的处理的具体流程的流程图。学习处理部23从存储装置12取得多个教师数据l(sb1)。
学习处理部23通过利用多个教师数据l的机器学习而构建边界推定模型22(sb2)。具体而言,学习处理部23以减小通过输入教师数据l的特征量y的时间序列而从临时的边界推定模型22输出的边界数据b、和该教师数据l的边界数据bx之间的差异的方式,对边界推定模型22的多个系数k进行更新。例如,学习处理部23以使得表示边界数据b和边界数据bx之间的差异的评价函数最小化的方式,例如通过误差逆传播法反复对多个系数k进行更新。在以上流程中由学习处理部23设定的多个系数k被存储于存储装置12。因此,边界推定模型22基于在多个教师数据l的特征量y的时间序列和边界数据bx之间潜在的倾向,输出相对于未知的特征量y的时间序列而在统计上合理的边界数据b。
如以上所说明的那样,根据第1实施方式,通过向对特征量y的时间序列和边界数据b的关系进行学习得到的边界推定模型22输入音响信号v的特征量y而生成边界数据b。即,边界数据b的生成是不需要进行代码的推定的独立的处理。因此,与根据通过音响信号v的解析而推定出的代码的时间序列对各连续区间进行确定的结构相比较,能够不受代码的推定结果的影响而通过音响信号v的解析高精度地对各连续区间进行推定。
另外,在第1实施方式中,将针对每个音阶音而包含成分强度qn的特征量y用于边界数据b的生成,该成分强度qn对应于音响信号v中的与音阶音相对应的音响成分的强度。根据以上结构,具有如下优点,即,能够利用适当反映出音响信号v所表示的乐曲的代码的特征量y而高精度地对各连续区间的边界进行推定。
b:第2实施方式
对第2实施方式进行说明。此外,对于以下的各例示中功能与第1实施方式相同的要素,沿用在第1实施方式的说明中使用的标号,适当地省略各自的详细说明。
在第1实施方式中,例示出边界数据b,该边界数据b以2值的方式表示各单位期间t是否属于连续区间的边界。第2实施方式的边界数据b表示各单位期间t为连续区间的边界的似然度。具体而言,构成边界数据b的多个单位数据b各自设定为大于或等于0且小于或等于1的范围内的数值,多个单位数据b所表示的数值的合计成为规定值(例如1)。与构成边界数据b的多个单位数据b中的数值大的单位数据b相对应的单位期间t被判定为位于连续区间的边界。在第2实施方式中,也实现与第1实施方式相同的效果。
c:变形例
以下例示出对以上所例示的各方式附加的具体变形的方式。也可以将从以下例示中任意选择出的2个以上的方式在相互不矛盾的范围适当进行合并。
(1)在前述的各方式中,例示出具有边界推定模型22和学习处理部23的音响解析装置100,但也可以在与音响解析装置100分体的信息处理装置(以下,称为“机器学习装置”)搭载学习处理部23。应用了由机器学习装置的学习处理部23设定的多个系数k的边界推定模型22被转送至音响解析装置100而用于连续区间的边界的推定。如根据以上说明所理解的那样,从音响解析装置100省略学习处理部23。
(2)也可以通过在与移动电话或者智能机等信息终端之间进行通信的服务器装置而实现音响解析装置100。例如,音响解析装置100通过从信息终端接收到的音响信号v的解析而生成边界数据b,并发送至信息终端。此外,在由信息终端从音响信号v对特征量y进行提取的结构中,音响解析装置100的特征取得部21从信息终端接收特征量y的时间序列。边界推定模型22根据特征取得部21所取得的特征量y的时间序列,生成边界数据b。边界推定模型22所生成的边界数据b被发送至信息终端。如根据以上说明所理解的那样,特征取得部21除了从音响信号v对特征量y进行提取的要素之外,还包含从信息终端等其他装置接收特征量y的要素。
(3)在前述的各方式中,例示出包含半音阶矢量q和强度p的特征量y,但特征量y的内容不限定于以上的例示。例如,也可以将半音阶矢量q单独地作为特征量y而利用。另外,例如,也可以针对音响信号v的多个频带的各个,分别生成包含半音阶矢量q和强度p的特征量y。例如,也可以针对音响信号v中的相对于规定的频率处于低频侧的频带成分和处于高频侧的频带成分,分别生成包含半音阶矢量q和强度p的特征量y。
(4)在前述的各方式中显示出边界数据b,但边界推定模型22所生成的边界数据b的用途不限定于以上的例示。具体而言,在通过公知的解析技术而根据音响信号v对代码的时间序列(以下,称为“代码系列”)进行推定的结构中,动作控制部24利用由边界推定模型22生成的边界数据b而对代码系列进行修正。例如,以使得在边界数据b所表示的各连续区间内相同的代码持续的方式,对根据音响信号v推定出的代码系列进行修正。
另外,也可以在各种的处理装置13的控制中利用边界数据b。例如,将执行乐曲的自动演奏的自动演奏装置(例如,自动演奏钢琴)设想为处理装置13。自动演奏装置能够变更自动演奏时的演奏风格。动作控制部24对自动演奏装置进行控制,以使得在音响信号v所表示的乐曲的自动演奏时,针对边界数据b所表示的每个连续区间而变更演奏风格。根据以上结构,能够针对乐曲内的每个连续区间而使自动演奏的音乐表情多样地变化。此外,演奏风格例如包含自动演奏的模式或者带音乐表情。带音乐表情例如是音色、效果、音量、强弱或者奏法。
例如,将设置于卡拉ok等音响空间的照明装置设想为处理装置13。动作控制部24对照明装置进行控制,以使得针对边界数据b所表示的每个连续区间而变更照明的条件。照明的条件例如为发光量、发光色或者发光模式等各种特性。根据以上结构,能够针对乐曲内的每个连续区间而使由照明装置进行的照明多样地变化。
(5)前述的各方式涉及的音响解析装置100如在各方式中所例示的那样,通过计算机(具体而言,控制装置11)和程序的协作而实现。前述的各方式涉及的程序能够以储存于计算机可读取的记录介质的方式提供并安装于计算机。记录介质例如是非临时性(non-transitory)的记录介质,优选例为cd-rom等光学式记录介质(光盘),但也可以包含半导体记录介质或者磁记录介质等公知的任意形式的记录介质。此外,非临时性的记录介质包含除了临时性的传输信号(transitory,propagatingsignal)的任意的记录介质,并非将易失性的记录介质除外。另外,还可以以经由通信网的传送的方式将程序提供给计算机。
此外,实现边界推定模型22的程序的执行主体不限定于cpu等通用的处理电路。例如,张量处理单元(tensorprocessingunit)或者神经引擎(neuralengine)等专用于人工智能的处理电路、或者信号处理用的电子电路(dsp:digitalsignalprocessor)也可以执行程序。另外,也可以是从以上的例示选择出的多种主体协作而执行程序。
d:附录
根据以上所例示的方式,例如掌握以下的结构。
本发明的一个方式(第1方式)涉及的音响解析方法取得音响信号的特征量的时间序列,向对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习(训练)的边界推定模型,输入所述取得的所述特征量的时间序列,由此生成边界数据。根据以上方式,向对特征量的时间序列和表示连续区间的边界的边界数据的关系进行了学习的边界推定模型,输入音响信号的特征量,由此生成与音响信号相关的边界数据。即,对于边界数据的生成,不需要代码的推定。因此,与根据通过音响信号的解析而解析出代码的结果而对各连续区间进行确定的结构相比较,具有如下优点,即,能够不受代码的推定结果的影响而通过音响信号的解析高精度地对各连续区间进行推定。
在第1方式的具体例(第2方式)中,所述音响信号的特征量针对每个音阶音而包含成分强度,该成分强度对应于该音响信号中的与音阶音相对应的音响成分的强度。根据以上方式,具有如下优点,即,能够利用适当地反映出音响信号所表示的乐曲的代码的特征量而高精度地对各连续区间的边界进行推定。
在第1方式或第2方式的具体例(第3方式)中,所述边界数据以2值的方式表示时间轴上的多个时间点各自是否为所述连续区间的边界。另外,在第1方式或第2方式的具体例(第4方式)中,所述边界数据表示时间轴上的多个时间点各自为所述连续区间的边界的似然度。
第1方式至第4方式中任一项所述的具体例(第5方式)涉及的所述音响解析方法还与所述生成的边界数据对应地控制处理装置。根据以上结构,能够与代码持续的连续区间同步地对处理装置进行控制。
在第5方式的具体例(第6方式)中,所述处理装置为对图像进行显示的显示装置,在所述处理装置的控制中,使所述显示装置对所述生成的边界数据所表示的连续区间进行显示。根据以上方式,利用者能够在视觉上掌握连续区间。
在第5方式的具体例(第7方式)中,所述处理装置为执行乐曲的自动演奏的自动演奏装置,在所述处理装置的控制中,与所述生成的边界数据对应地对由所述自动演奏装置进行的自动演奏进行控制。根据以上方式,例如能够针对每个连续区间而控制由自动演奏装置进行的自动演奏。
在第5方式的具体例(第8方式)中,所述处理装置为照明装置,在所述处理装置的控制中,与所述生成的边界数据对应地控制由所述照明装置进行的照明的条件。根据以上方式,能够针对每个连续区间而控制由照明装置进行的照明的条件。
第1方式至第8方式的具体例(第9方式)涉及的所述音响解析方法还与所述生成的边界数据对应地修正根据所述音响信号推定的代码系列。在以上的方式中,能够适当地对根据音响信号推定的代码系列进行修正。
本发明也可以作为执行以上例示出的各方式的音响解析方法的音响解析装置、或者、使计算机执行以上例示出的各方式的音响解析方法的程序而实现。例如,本发明的一个方式涉及的音响解析装置具有边界推定模型,该边界推定模型是对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习(训练)的训练好的模型,且针对音响信号的特征量的时间序列的输入而生成边界数据。
本发明的一个方式涉及的模型构建方法取得包含特征量的时间序列和表示代码持续的连续区间的边界的边界数据在内的多个教师数据,通过利用所述多个教师数据的机器学习,构建对特征量的时间序列和表示代码持续的连续区间的边界的边界数据的关系进行了学习的边界推定模型。
标号的说明
100…音响解析装置、11…控制装置、12…存储装置、13…处理装置、21…特征提取部、22…边界推定模型、23…学习处理部、24…动作控制部。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

