本发明涉及声事件检测领域,具体是一种采用双token标签的声事件标注及识别方法。
背景技术:
在人们的生活环境中,各类声音携带了大量有关日常环境和其中发生的物理事件信息。声音事件检测(soundeventsdetection,简称sed)研究,能帮助人们更好地感知其所处声音场景,识别出各种声源类别,获得感兴趣事件的时间戳,具有重要的现实意义。可应用于城市环境噪声监控、公共场所的安全监控、室内环境中老人儿童行为监测等智慧城市与智慧家居场景,比如声监控应用场景下可以自动的检测识别枪声、尖叫声、物件燃烧声,在人机交互、听觉感知、满足社会中各类检测需求中都有重要价值。
声事件检测任务依赖于信号处理方法和机器学习模型,声事件检测模型通常由大量的带标签标注的音频数据训练得到,得到的模型可以对一段标签未知的音频做预测,通常是预测其发生的声事件所属类别和对应的时间戳。具体地,对带标注音频使用信号处理方法得到其时频域某种特征表示,将带标注的特征表示作为输入,送入机器学习模型,机器学习模型定义好损失函数和随机初始化权重参数;根据前向传播计算输出和标签的损失值,接着使用反向传播,更新权重;通过来回不断的迭代,直到损失函数很小,此时的权重参数就是声事件识别模型,得到的模型就可以对一段不知标签的音频做预测,达到声事件检测的目的。而这种迭代、更新权值的过程就是机器学习训练过程。由于机器学习遵从“garbagein,garbageout”的原则,标注数据的准确度、好坏程度、数据量的大小极大的影响了检测模型的效果。数据的标注有强标签标注(准确标注其声事件类别和时间戳、体现了一段音频中声事件数量及位置)和弱标签标注(仅标注某类声事件出现与否、无法体现其音频中发声了几次和在什么时间点发生)。
数据量和标注通常不能兼顾:若对音频数据进行强标注,训练模型就能获得更准确详细的标签描述,并预测出可能重叠的声事件的开始和结束时间(时间戳)。然而,强标注音频数据,往往是通过人耳聆听与手工标注完成,需要人在聆听过程中时刻保持高度注意力,并利用专业软件记录,是一项非常耗时、耗力的任务,尤其是当一段音频中混合着多种类别且时间重叠的声事件时,强标注任务的时间、人力成本则会成倍增长。而弱标注,这种方式只标注一段音频中有无感兴趣事件发生,以舍弃部分时间信息为代价,降低音频数据集标注的人力成本,相应地,使用弱标注数据集训练获得的模型,无法预测声音事件的时间信息,且识别率也不高。常用的弱标注数据集有:1.detectionandclassificationofacousticscenesandevents(dcase2017)声事件检测数据集-优点在于标注精确,但该数据集样本类型与数量较少,使用该数据集训练得到的模型识别范围较窄,模型普适性差;2.googleaudio-set弱标注数据集-优点在于样本类型与数量较多,但受成本限制,其标注精度较低,因此,基于该数据集训练得到的模型,虽然识别范围较广,但是识别准确率不如前者。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种采用双token标签的声事件标注及识别方法。这种方法能在保证准确率的同时,以较小的代价拓宽声事件识别范围,可实现人们生活环境中准确的声音事件检测与监控,从而更好地服务智慧城市建设。
实现本发明目的的技术方案是:
一种采用双token标签的声事件标注及识别方法,包括声事件标注过程和识别过程,所述声事件标注过程:
1-1)音频标签形式:在音频标注软件audacity播放包含各类声事件的原始音频数据,标注步骤为:在音频的每个声事件发生时间范围内随机地选取两个token,分别为ci_start与ci_end,c表示声事件类别;
1-2)重复标注步骤,完成数据集中所有音频标注;
所述识别过程为:
2-1)构建音频数据集:根据检测任务要求添加声事件音频构成音频数据集,音频数据集构建需要大量的带标注音频,依据检测要求,首先确定待检测声事件类别,采用音频标注软件audacity播放待检测声事件音频,播放音频的同时,在软件labeltrack栏中点击鼠标标记声事件类别和时间戳,完成音频数据标注,在听到的声事件发声时间范围内随机的选取两个点,得到两个token,token分别为ci_start与ci_end,c表示声事件类别,因为强标签中重叠声事件的边界需要人反复回放才能准确标注,本发明随机给定两个token省去了反复回放确定边界这一耗时繁琐的过程,节省了人力,这种简化标注方法以此节省人力带来了标注信息减少会对识别带来负面影响,这种影响可以通过设计配套的卷积循环神经网络解决;最后,采用audacity导出标签文件,标签文件记录了音频文件名、每个音频文件名下发生的声事件类别、每个声事件时间戳;
2-2)音频数据预处理和特征提取:
对于音频:由于音频的来源可能为不同的录制设备,处理平台对所有音频重采样频率为16khz,重采样完成后对音频波形数据标准化,使音频波形数据值规整到(-1,1)范围类,采用max标准化:x(t)=s(t)/max(|s(t)|),然后采用短时傅里叶变换对所有音频提取128维的对数梅尔能量谱,短时傅里叶变换具体参数为:nfft=2048、采样频率为16khz、采用1/2帧重叠,最后对对数梅尔能量谱采样z-score标准化:假设输入对数梅尔能量谱为x1,x2,...xn,
对音频标签:将以秒为单位的标签转换成以帧为单位的标签,对每个标签文件采取如下步骤变换得到以帧为单位的音频标签编码矩阵,标签编码矩阵由0元素和1元素组成,矩阵的列数n为帧数,矩阵的行数m为声事件类别数,一个包含m类声事件的音频标签编码矩阵从以秒为单位到以帧为时间单位的转换如下:
step1:产生一个m行n列的零矩阵,假设采样频率为sr,音频持续时间为t,则矩阵列数n=sr*t,矩阵行数m为声事件类别数;
step2:确定每个声事件以帧为单位的时间戳:假设以秒为单位的时间戳timestampsecond、hop_length为帧重叠,则时间戳转换公式为:
timestampframe=timestampsecond÷nfft÷(1-hop_length);
step3:timestampframe包含范围即每个声事件起始帧到结束帧之间的矩阵值用1替换0;
2-3)音频数据扩增:为提高神经网络泛化性能,防止过拟合采用如下数据扩增方式将音频数据扩增至原来的三倍:音频随机缩放、timemasking、frequencymasking、加随机噪声、音频样本混合(mixup);
2-4)搭建卷积循环神经网络:采用pytorch框架搭建如下卷积循环神经网络:第一层为输入层、输入128维对数梅尔能量谱,第二层为输入通道数为16的2维卷积层接2×2的2d池化,第三层为输入通道数为32的2维卷积层接2×2的2d池化,第四层为输入通道数为64的2维卷积层接2×2的2d池化,第五层为输入通道数为128的2维卷积层接2×1的2d池化,第六层为输入通道数为256使用2×1的2d池化,再将输出特征图张量展平,第七层为输入通道数为256的一维卷积层,第八层为使用两层gru的双向循环神经网络、神经元个数为256,第九层为输出层,依次使用256、80个神经元的全连接层且使用relu激活,最后拼接一个神经元个数为声事件类别数的使用sigmoid激活的全连接层,每个卷积层都使用大小为3×3的卷积核、步长为1,并且每个卷积层接一个批标准化层、且都使用relu函数激活;
2-5)训练卷积循环神经网络学习检测模型:将训练数据即音频的对数梅尔能量谱送入步骤2-4)搭建的卷积循环神经网络,卷积循环神经网络初始权值参数由pytorch随机给定,得到输出
梯度反向传播,使用adam梯度下降法,学习率设置为0.001,更新权值参数,迭代训练直至损失不再下降,保存模型参数;
2-6)使用训练好的检测模型识别待检测音频:将标签未知的待检测音频标准化后提取对数梅尔能量谱在规整后送入卷积循环神经网络,得到神经网络概率输出,保存,依据f1-score为标尺搜索最佳判决门限α,依据判决门限α二值化得到双token标签下预测结果,双token标注此时的结果相较强标签标注检测模型而言,是没有覆盖到声事件真实的时间戳的,为了降低这种假阴性的预测,采用标签延展的策略,具体做法是:依据双token标签预测输出矩阵确定的声事件开始结束时间帧节点,计算神经网络概率输出矩阵对应帧节点的相邻帧cosine相似度,相似度大于0.5则延展该帧,即延展了双token标签矩阵中时间戳,最后得到标签延展后的预测矩阵,得到识别结果,完成识别,注意的是这种左右两侧延展不得超过预先设定的超参数collar值,根据所有声事件的最大最小时长一般取(250ms-50ms)。
本技术方案拟针对数据强标签和弱标签的特性,结合深度学习范式,找到一种折衷的方法,提供了弱标签往强标签转换的一种节省人力的思路,通过计算音频分析研究和机器学习模型,更新双token标签标注下的预测结果,使其能在声学事件检测结果上达到超过弱标签而趋于强标注的效果,本技术方案所提出的交互式音频标注配套发明提出的神经网络模型,有望降低数据驱动模型的数据标注的时间与人力成本、缩小声学事件检测模型实际检测能力和理论检测能力的差异,从而更好地服务智慧城市建设。
这种方法能在保证准确率的同时,以较小的代价拓宽声事件识别范围,可实现人们生活环境中准确的声音事件检测与监控,从而更好地服务智慧城市建设。
附图说明
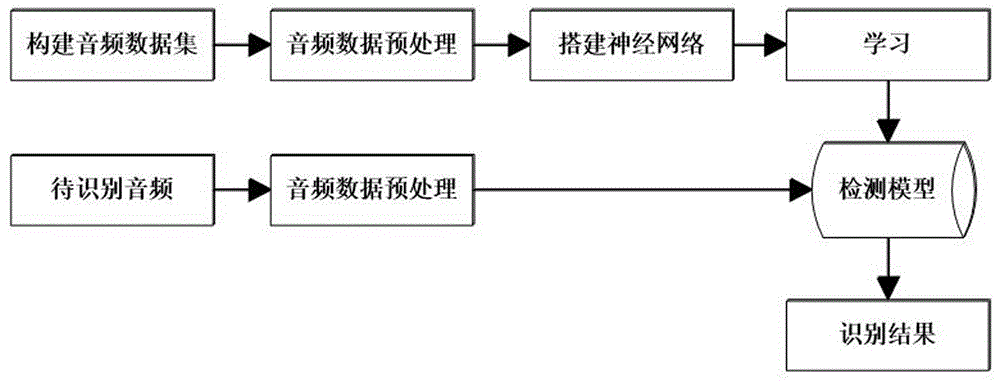
图1为实施例中识别过程流程示意图;
图2为实施例中构建数据集过程中使用音频标注软件标注一段音频示意图;
图3为实施例中包含3类声事件实施例的双token标签示意图。
具体实施方式
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
实施例:
参照图1,一种采用双token标签的声事件标注及识别方法,包括声事件标注过程和识别过程,所述事件标注过程为:
1-1)音频标签形式:采用音频标注软件audacity播放包含各类声事件的原始音频数据,标注步骤为:在音频的每个声事件发生时间范围内随机地选取两个token,分别为ci_start与ci_end,c表示声事件类别;
1-2)重复标注步骤,完成数据集中所有音频标注;
所述识别过程为:
2-1)构建音频数据集:根据检测任务要求添加声事件音频构成音频数据集,音频数据集构建需要大量的带标注音频,依据检测要求,首先确定待检测声事件类别,本例检测要求为3类声事件:枪击声、尖叫声、警笛声,通过人工录制枪击声、尖叫声、警笛声和在视频社交网站如youtube、bilibili下载包含枪击声、尖叫声、警笛声的音频文件,将获取到的音频分为持续时间为10s的音频段,10s各类音频声事件可能重叠多次,重复录制和下载使得包含三类声事件的音频数量达到3000条,采用音频标注软件audacity播放待检测声事件这3000条音频,播放音频的同时,在软件labeltrack栏中点击鼠标标记声事件类别和时间戳,完成音频数据标注,如图2所示,在audacity软件labeltrack栏每点击鼠标就是一次标注,标注方法:不用仔细聆听、确定声事件的开始、停止事件点,在听到的声事件发声时间范围内随机的选取两个点,得到两个token,token分别为ci_start与ci_end,c表示声事件类别,因为强标签中重叠声事件的边界需要人反复回放才能准确标注,本例随机给定两个token省去了反复回放确定边界这一耗时繁琐的过程,节省了人力,这种简化标注方法以此节省人力带来了标注信息减少会对识别带来负面影响,这种影响可以通过设计配套的卷积循环神经网络解决,如图3所示,图3上部为对模拟双token标签标注过程,只用随机在对应声事件发生范围内取两个token占位,图3中部为标签的真值,图3下部为双token标签的标签编码矩阵,与真值对比,由于随机选取token没有仔细地、消耗大量精力取确定重叠声发声时间边界的缘故,故标签覆盖不完整,以标签矩阵的形式对比了强签标注和双token标注,图3标签矩阵中纵轴代表声事件类别(这里假设为3类),横轴表示帧数,1表示在图中所示帧数发声了该类声事件,空白处为0即未发生声事件,可以看到,虽然双token虽然是随机给定的,但是,仍然保留了一定的时间戳信息,最后,使用audacity导出标签文件,标签文件记录了音频文件名、每个音频文件名下发生的声事件类别、每个声事件时间戳;
2-2)音频数据预处理和特征提取:
对于音频:由于音频的来源可能为不同的录制设备,处理平台对所有音频重采样频率为16khz,重采样完成后对音频波形数据标准化,使音频波形数据值规整到(-1,1)范围类,采用max标准化:x(t)=s(t)/max(|s(t)|),然后采用短时傅里叶变换对所有音频提取128维的对数梅尔能量谱,短时傅里叶变换具体参数为:帧长nfft=2048、采样频率为16khz、采用1/2帧重叠,最后对对数梅尔能量谱采样z-score标准化:假设输入对数梅尔能量谱为x1,x2,...xn,
,得到规整后的对数梅尔能量谱y1,y2....yn的均值为0,方差为1;
对音频标签:将以秒为单位的标签转换成以帧为单位的标签,对每个标签文件采取如下步骤变换得到以帧为单位的音频标签编码矩阵,标签编码矩阵由0元素和1元素组成,矩阵的列数n为帧数,本例中n=160000;矩阵的行数m为声事件类别数,本例中m=3;本例中取nfft=2048,hop_length=1/2提取梅尔能量谱,一个包含m类声事件的音频标签编码矩阵从以秒为单位到以帧为时间单位的转换如下:
step1:假设采样率为sr,本例中sr=16000;音频持续时间为t,本例中为10d,则矩阵列数n=sr*t=160000,矩阵行数m为声事件类别数3,即产生一个3行160000列的零矩阵;
step2:确定每个声事件以帧为单位的时间戳:假设以秒为单位的时间戳timestampsecond、hop_length为帧重叠,则时间戳转换公式为:
timestampframe=timestampsecond÷2048÷(1-1/2);
step3:timestampframe包含范围即每个声事件起始帧到结束帧之间的矩阵值用1替换0;
2-3)音频数据扩增:为提高神经网络泛化性能,防止过拟合采用如下数据扩增方式将音频数据扩增至原来(3000条)的三倍(9000条):音频随机缩放、timemasking、frequencymasking、加随机噪声、音频样本混合(mixup);
2-4)搭建卷积循环神经网络:采用pytorch框架搭建如下卷积循环神经网络:第一层为输入层、输入128维对数梅尔能量谱,第二层为输入通道数为16的2维卷积层接2×2的2d池化,第三层为输入通道数为32的2维卷积层接2×2的2d池化,第四层为输入通道数为64的2维卷积层接2×2的2d池化,第五层为输入通道数为128的2维卷积层接2×1的2d池化,第六层为输入通道数为256使用2×1的2d池化,再将输出特征图张量展平,第七层为输入通道数为256的一维卷积层,第八层为使用两层gru的双向循环神经网络、神经元个数为256,第九层为输出层,依次使用256、80个神经元的全连接层且使用relu激活,最后拼接一个神经元个数为声事件类别数的使用sigmoid激活的全连接层,每个卷积层都使用大小为3×3的卷积核、步长为1,并且每个卷积层接一个批标准化层、且都使用relu函数激活;
2-5)训练卷积循环神经网络学习检测模型:将训练数据即音频的对数梅尔能量谱送入步骤2-4)搭建的卷积循环神经网络,卷积循环神经网络初始权值参数由pytorch随机给定,得到输出
梯度反向传播,使用adam梯度下降法,学习率设置为0.001,更新权值参数,迭代训练直至损失不再下降,保存模型参数;
2-6)使用训练好的检测模型识别待检测音频:将标签未知的待检测音频标准化后提取对数梅尔能量谱在规整后送入卷积循环神经网络,得到神经网络概率输出,保存,依据f1-score为标尺搜索最佳判决门限α,依据判决门限α二值化得到双token标签下预测结果,双token标注此时的结果相较强标签标注检测模型而言,是没有覆盖到声事件真实的时间戳的,为了降低这种假阴性的预测,本项发明采用标签延展的策略,具体做法是:依据双token标签预测输出矩阵确定的声事件开始结束时间帧节点,计算神经网络概率输出矩阵对应帧节点的相邻帧cosine相似度,相似度大于0.5则延展该帧,即延展了双token标签矩阵中时间戳。最后得到标签延展后的预测矩阵,得到识别结果,完成识别,本例中左右两侧延展不得超过预先设定的超参数collar值,根据所有声事件的最大最小时长取(250ms-50ms)。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

