1.本发明属于人工智能技术领域,涉及语音提取技术,具体涉及一种基于双麦克风阵列的目标语音提取方法。
背景技术:
2.在人工智能技术领域,语音增强、语音识别一直都是专家学者及语音交互产品市场关注的热点话题。其中,双麦克风阵列以其显而易见的优势成为技术人员研究的主要对象。原因在于相比于单麦克风,双麦克风阵列在降噪处理及远距离拾音等方面具有较大优势;而与多麦克风阵列相比,双麦克风阵列又极大简化了语音交互产品的硬件设计方案及语音前端算法处理的复杂度。因此,双麦克风阵列以其小巧灵活的构型以及电路、算力、成本要求都比较低而广泛应用于智能家居、智能家电、智能玩具等领域。
3.在语音增强技术上,基于双麦克风阵列的语音信号处理算法主要有基于波束形成的算法,如延时累加波束形成(delay
‑
sum beamforming,dsb)方法、最小方差无失真响应(minimum variance distortionless response,mvdr)波束形成方法等,基于盲源分离的算法以及基于深度学习的方法等。其中,基于盲源分离的算法相比于传统波束形成方法降噪效果好、相比于深度学习方法算力小,易集成在嵌入式系统上。因此,盲源分离算法在双麦克风阵列降噪处理上具有很好的应用前景。
4.虽然盲源分离算法在双麦降噪处理上可以取得较好的效果,但由于盲源分离算法只是将语音与噪声或者语音与干扰分离开,对于如何在盲源分离处理后提取目标语音仍是需要解决的难题。目前,对于目标语音的提取,主要的方法有基于目标声源的波达方向(direction of arrival,doa)、基于深度学习的训练、基于音视频融合等方法。但是对于双麦克风而言,由于其麦克风数量较少,空间指向性较弱,利用doa的方法会使目标语音提取时信号频谱失真甚至无法提取到目标语音,而深度学习的方法又对嵌入式系统的性能和资源要求较高。
技术实现要素:
5.为克服现有方案技术存在的缺陷,本发明公开了一种基于双麦克风阵列的目标语音提取方法。
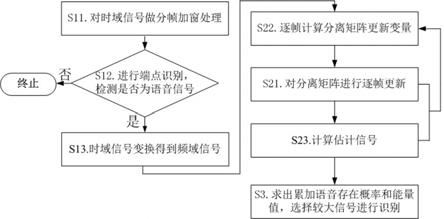
6.本发明所述基于双麦克风阵列的目标语音提取方法,其特征在于,包括如下步骤:s1. 将两个麦克风接收的时域信号转化为频域信号;s2. 然后对频域信号进行频域盲源分离算法处理;处理后得到两个源信号的估计信号;s3. 利用两个源信号的估计信号求出各自的累加语音存在概率和功率谱值,并以功率谱值比值和概率值差值进行综合比较,设置不同的阈值范围,将功率谱值大和概率值高的信号作为目标语音传输到后端语音识别系统进行识别。
7.优选的:如果步骤s3中识别不成功,则更换另一估计信号进行识别。
analysis,auxiva)等。
22.本发明以自然梯度下降iva算法为例,利用双麦克风阵列分离两个源信号,源信号为麦克风观测的信号,现实中不易直接得出,可利用频域盲源分离算法对麦克风阵列的接收信号进行处理得到源信号的估计信号。
23.具体实现过程为:设x(k,l),y(k,l)分别为双麦克风阵列的接收信号及经频域盲源分离算法处理后的估计信号,则:x(k,l)=[x1(k,l),x2(k,l)]
t
y(k,l)=[y1(k,l),y2(k,l)]
t
y(k,l)=w(k,l)*x(k,l)其中:x1(k,l) 、y1(k,l)分别表示第一个麦克风的接收信号、第一个源信号的估计信号;x2(k,l) 、y2(k,l) 分别表示第二个麦克风的接收信号、第二个源信号的估计信号,上标t表示向量转置;对双麦克风阵列,w(k,l)表示2 * 2的分离矩阵。可通过按帧实时更新该分离矩阵w(k,l)得到双麦克风阵列估计信号y(k,l)。
[0024]
一般的,分离矩阵w(k,l)用2 * 2的单位矩阵作为初始化矩阵,其更新过程为:以超高斯分布近似表示语音信号的概率密度分布,即源语音信号概率密度分布其中; y
i
(k,l)表示估计信号y(k,l)的第i个元素,对应不同麦克风的源信号,i = 1,2,k为采样点总数。
[0025]
则分离矩阵w(k,l)更新的梯度计算方法为:分离矩阵更新变量:其中h表示复数共轭转置,m为单位矩阵,e表示期望;w(k)即分离矩阵 w(k,l),δw(k)表示分离矩阵更新变量;语音信号概率密度。
[0026]
y1(k,l)、y2(k,l)分别表示双麦克风阵列观测的两个源信号的估计信号,则w(k,l)的更新规则为:w(k,l) η*δw(k);即每次更新增加一个η*δw(k);其中:0<η<1, η为w(k,l)更新的步长因子,可设置η=0.01。
[0027]
则估计信号y(k,l)= w(k,l)*x(k,l),然后分别求两个估计信号y1(k,l)、y2(k,l)的语音存在概率值和功率谱值。
[0028]
估计信号的语音存在概率的计算过程为:首先计算估计信号y
i
每个频点的功率谱:
则提取的目标语音信号y为:上述目标语音提取的原理在于,在信噪比较高情况下,当一个估计信号的功率谱比值或概率值明显高于另一个估计信号的功率谱值或概率值时,可认为此时功率谱值或概率值高的估计信号为目标语音信号。但当功率谱值和概率值相差不大时,需要综合考虑差值范围,如上述分段函数所示,选择功率谱值和概率值至少一个相差较大,且另一个也不低的,具体的端点区间可以根据实际情况调整。
[0032]
采用前述的具体实施方式和参数设置,进行语音提取,其中目标人声位于阵列90
°
方向,距离双麦克风阵列2米,说话声65
‑
70db。噪声位于阵列180
°
方向,距离双麦克风阵列1米,音响播放噪声。噪声类型为新闻噪声和音乐噪声55
‑
60db;按照本发明所述步骤s1至s3,仅进行第一次识别的实验结果如下表,其中对识别率的统计采用命令词识别方法,即统计100个命令词中能正确识别的词的个数、错误识别的个数及未能识别的个数,最终以正确识别率作为评估标准:表1 正确识别率比较从上表可见,在无需进行第二次识别的情况下,与以doa为先验信息的目标语音提取方法相比,正确识别率相差不大,说明本发明所述目标语音提取方法可正确选取目标语音。
[0033]
通过本发明所述目标语音提取方法,利用盲源分离算法降噪性好的特点,对盲源分离算法分离后的两个信号通过语音存在概率和功率谱值综合比较,提取出目标语音信号;该方法相对传统方法,不需要利用doa提供目标声源先验信息,且不需要采用深度学习提取,对系统资源要求降低,并在信噪比(snr)较高情况如snr 不小于5db下能准确单次即提取出目标语音。
[0034]
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

