技术邻域本发明属于语音信号处理
技术领域:
,具体涉及到一种基于深度自编码器子域自适应跨库语音情感识别方法。
背景技术:
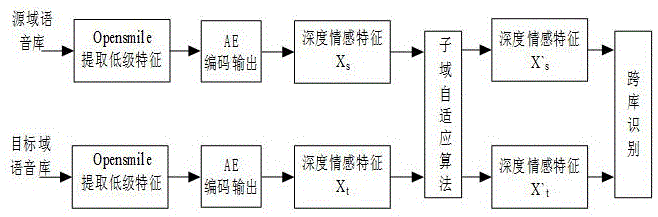
:语音作为人类交流最自然便利的方式之一。语音信号除了承载语义信息外,还承载着诸如性别、情感状态等其他信息,当人类语音交流时,两个人很容易感受到彼此的情感状态。情感是人类具有标志性的自然属性,在人们日常生产生活过程中扮演着重要的角色,并且对人类的行为判断产生一定的影响。人工智能的本质是使计算机模拟人类的思考判断,并作出相应的类人行为。人工智能想要从低级智能向高级智能发展,那么赋予计算机情感的感知将是必不可少的。传统语音情感识别的研究都是在同一个语音数据库上进行训练和测试,训练集和测试集具有同样的特征空间分布,往往可以达到较高的识别率。在实际语音情感识别系统中,一方面训练集和测试集往往来自不同的语料库,由于不同语料库的情感获取方法、情感种类以及录音环境有所不同,此时训练集和测试集存在分布差异,从而导致基于同分布假设的传统语音情感识别方法不能够很好地解决跨库识别问题;另一方面随着大数据时代的到来,数据的暴增而人工标注的昂贵,迁移学习对跨语料库的运用受到了越来越多研究者们的重视,利用已标注过的数据来帮助目标数据的训练己成为语音情感识别一个重要的研宄方向。迁移学习是机器学习领域近年来一个比较热门的研究领域,主要通过迁移当前领域已有知识来解决目标领域中数据仅有少量标签甚至没有标签的学习问题,在很多应用领域得到了广泛的研究如文本分类与聚类、图像分类、传感器定位、协同过滤等。受到迁移学习在这些领域成功应用的启发,在语音情感识别的跨库研究中使用迁移学习。而域自适应的引入己被证明可以显著减少不同领域之间特征分布的差异性,但相比于使用单一数据库进行语音情感识别率来说,跨库语音情感识别的识别率显得非常不理想,所以寻找更加有效的迁移方法来提高跨库语音情感识别的识别率显得尤为重要。因此本发明主要关注于不同语料库之间的跨库语音情感识别,使用两个深度自编码器,并且交叉使用激活函数以获取更匹配的特征,以及引入基于mmd的子域自适应算法,使其可以对齐以类别划分的子域之间的特征分布,减少不同域之间的分布差异,实现更为有效的跨库语音情感识别。技术实现要素:为了解决不同语料数据库之间特征分布差异的问题,更好地将带标记源域数据的知识迁移到无标记目标域,实现无标记数据的准确分类,提出了一种用于跨库语音情感识别深度自编码器子域自适应方法。具体步骤如下:(1)语音预处理:将源域语料库中的语音数据按对应的情感分类标记数字标签,而目标域数据库不做标签处理,之后对其进行分帧及加窗,为下一步提取特征做准备。(2)语音特征提取:对步骤(1)预处理完毕后的语音数据,提取语音情感特征,该特征包括但不限于mfcc、短时平均过零率、基频、均值、标准差、最大最小值等。(3)特征压缩:将步骤(2)得到的语音特征输入两个深度自编码器,其中一个自编码器提取源域数据特征,进行有监督学习,另一个为辅助性自编码器,用来无监督学习目标域数据特征。假设自编码的输入为x,编码阶段的输入用y表示,relu()和elu()为非线性激活函数,则编码过程表示如下:y=f(wx b)(6)从而获取源域和目标域在低维空间中的情感表示。(4)特征分布对齐:将步骤(3)得到的低维特征输入子域自适应模块,该模块度量了在考虑不同样本权重的情况下,源域相关子域经验分布核均值嵌入与目标域核均值嵌入之间的hilbertschmidt范数,实现了源域和目标域在不同情感空间中的特征分布对齐。该算法实现如下,(5)训练模型:整个网络训练是通过梯度下降法不断优化训练的,由带标签数据计算的交叉熵作为分类loss,两个自编码器的重构loss,以及域自适应层中基于mmd度量准则的子域自适应loss组成总的损失函数一起优化训练网络参数。整个网络的损失函数表示为:loss=loss重构1 loss重构2 loss分类 lossmmd(10)(6)重复步骤(3)、(4),迭代训练网络模型。(7)利用步骤(6)训练好的网络模型,使用sofmatx分类器识别步骤(2)中的目标域数据集,最终实现语音情感在跨语料库条件下的情感识别。附图说明如附图所示,图1为一种基于深度自编码器子域自适应跨库语音情感识别方法模型框架图,图2为子域情感特征对齐示意图。具体实施方式下面结合具体实施方式对本发明做更进一步的说明。(1)语音特征是进行跨库情感识别的关键,我们使用的语音特征是2010年国际语音情感识别挑战赛的标准特征集,这个特征集包含了声学特征中使用最为广泛的特征和函数。我们使用开源工具包opensmile从语音中提取这些特征,每条语音提取出的特征都为1582维,所以使用emo-db数据库的5类情感语音共有368条语音,数据总量为368*1582;enterface数据库的5类情感语音共有1072条语音,数据总量为1072*1582。(2)标签问题。本发明网络模型是基于有监督学习的跨库语音情感识别,网络训练过程中,训练集使用真实的标签,并将其类别标签one-hot向量形式,与最后经softmax输出的概率做互熵损失,计算出分类损失loss。计算自适应loss时,并没有使用目标域的类别标签,而是使用目标域类别的概率分布作为目标域的标签,即为伪标签。(3)将步骤(1)得到的源域和目标域数据集特征分别输入两个深度自动编码器模型提取高级情感特征。两个自编码器采用相同的结构,编码部分包含5层隐层神经网络,除了第3层使用elu之外,其余隐层均使用relu激活函数,而解码部分则都是采用relu激活函数。激活函数的交叉使用一方面在一定程度上缓解了relu导致过多的神经元失活,丢失情感信息的弊端,另一方面使用elu函数可以使得数据输出均值均接近于零,加快网络收敛速度。(4)网络训练过程设置学习率为0.01,batchsize设置为350,解码隐层神经节点依次设置为1300、1000、700、500、50,每次训练10000epochs。(5)为了进一步验证该算法的有效性,分别采用2种方案进行测试。在方案1中,将enterface数据库(类别标签已知)作为训练库,并将emo-db数据库(类别标签未知)作为测试库;在方案2中,将emo-db数据库(类别标签已知)作为训练库,并将enterface数据库(类别标签未知)作为测试库。选择2个数据库共有的生气、厌恶、害怕、高兴、伤心等5类基本情感进行实验评价。将所提算法与mmd ae及ae模型在相同的价标准下作对比,其中mmd ae是在该发明网络模型的基础上使用了传统的基于mmd的域自适应,而ae则是仅使用深度自编码器。不同方法在enterface语料库、emo-db语料库的识别准确度如表1所示。表一不同方法得到的准确率aeae mmdourse-b48.10%49.18%55.16%b-e36.85%38.34%40.67%平均42.48%43.76%47.92%表中e为enterface语料库,b为emo-db语料库。从实验结果上看,我们提出的方法比ae和ae mmd分别提升了5.44%和4.16%,证明了我们的模型可以学习到更多领域间的共同特征,能够有效地完成迁移学习,实现从带标记数据中跨邻域识别无标记数据的情感类别。本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

