1.本发明涉及语音识别技术领域,具体涉及一种提升语音识别准确性的方法和设备。
背景技术:
2.asr(automatic speech recognition,语音识别)系统的性能,受环境因素的影响很大,当遇到复杂场景,如环境噪声很大或者与训练数据偏差较大时,对识别引擎性能会提出很大的挑战性。特别是声学打分会非常不准确,对识别结果起着至关重要的影响,引擎声学打分会不准,进而也会影响最终识别结果的准确性。
3.asr系统在复杂场景下的识别错误,最常见的一种错误类型是由于背景噪声(环境噪声或背景人声等)导致的插入错误:由于模型结构和训练数据的局限性,很多复杂场景下的人声和非人声无法做出很好的区分,会将背景的非人声误识别成人声,从而导致出现多余的识别结果,即产生插入错误。
4.而为了应对复杂场景下的高插入错误,目前的一般做法是,在asr系统引擎前端设置一个vad(voice activity detection,静音抑制,又称语音活动侦测)模块,先把人声和非人声区分开,然后只将纯人声部分送入asr系统引擎做识别。但是这种方式的缺点也很明显,具体有以下几点:
5.1.vad并非asr系统的标配,很多asr系统并没有vad模块;
6.2.即便有使用了vad,将人声部分提取出来了,最终对于识别而言效果并不一定很好(一方面,vad对人声的判断不一定准确,另外asr系统识别需要借助上下文信息,即便是非人声音频,对于识别往往也很有用。所以,将生硬截出的语音部分送入asr系统,效果往往不理想)
7.3.vad并不能区分目标人声和背景人声干扰(如电视背景噪音)。
8.由此,目前需要有一种更优的方案来解决现有技术中的问题。
技术实现要素:
9.本发明提供一种提升语音识别准确性的方法和设备,能够解决现有技术中识别率不高的技术问题。
10.本发明解决上述技术问题的技术方案如下:
11.本发明实施例提出了一种提升语音识别准确性的方法,应用于设置有sdm的用于语音识别的asr系统,所述asr系统设置有用于进行解码的解码网络;该方法包括:
12.通过所述sdm获取输入所述asr系统的原始音频和所述解码网络输出的历史解码信息;
13.通过所述sdm对所述原始音频进行处理,得到所述原始音频的多个信号特征;
14.通过所述sdm基于多个所述信号特征以及所述历史解码信息进行处理,得到所述原始音频的最终特征。
15.在一个具体的实施例中,还包括:
16.通过所述sdm将所述最终特征输出给所述解码网络,以使所述解码网络进行解码,得到识别文本。
17.在一个具体的实施例中,所述信号特征包括:信噪比、能量、过零率。
18.在一个具体的实施例中,所述历史解码信息中包括上下文信息。
19.在一个具体的实施例中,所述asr系统中还包括声学模型;
20.所述解码网络的声学打分包括:所述声学模型的打分与所述sdm的打分;其中,所述声学模型的打分与所述sdm的打分各自对应各自的权重。
21.在一个具体的实施例中,所述sdm的打分包括:从所述原始音频的信号特征得到的第一分数、基于所述历史解码信息得到的所述原始音频的第二分数;所述第一分数与所述第二分数各自对应各自的权重。
22.本发明实施例还提出了一种提升语音识别准确性的设备,应用于设置有sdm的用于语音识别的asr系统,所述asr系统设置有用于进行解码的解码网络;该设备包括:
23.获取模块,用于通过所述sdm获取输入所述asr系统的原始音频和所述解码网络输出的历史解码信息;
24.第一处理模块,用于通过所述sdm对所述原始音频进行处理,得到所述原始音频的多个信号特征;
25.第二处理模块,用于通过所述sdm基于多个所述信号特征以及所述历史解码信息进行处理,得到所述原始音频的最终特征。
26.在一个具体的实施例中,还包括:
27.识别模块,用于通过所述sdm将所述最终特征输出给所述解码网络,以使所述解码网络进行解码,得到识别文本。
28.在一个具体的实施例中,所述信号特征包括:信噪比、能量、过零率。
29.在一个具体的实施例中,所述历史解码信息中包括上下文信息。
30.本发明的有益效果是:
31.在asr系统解码阶段新增sdm,充分利用了各个维度的信息,包括直接从音频获取的信号特征、从历史解码信息中得到的上下文信息等,结合asr系统中原有的通过海量数据训练出的声学模型,能够提升asr系统在任何复杂场景下,对输入语音的打分和辨识能力,提升识别率。能够提升声学打分的准确性,进而提高asr系统整体性能。
附图说明
32.图1为本发明实施例提供的现有技术中asr系统的框架示意图;
33.图2为本发明实施例提供的一种提升语音识别准确性的方法所应用的asr系统的框架示意图;
34.图3为本发明实施例提供的一种提升语音识别准确性的方法的流程示意图;
35.图4为本发明实施例提供的一种提升语音识别准确性的设备的结构示意图;
36.图5为本发明实施例提供的一种提升语音识别准确性的设备的结构示意图。
具体实施方式
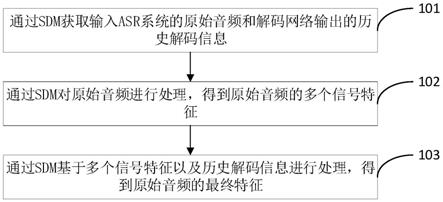
37.以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
38.本发明实施例提供的一种提升语音识别准确性的方法,应用于设置有sdm(speech detection module,语音检测模块)的用于语音识别的asr系统,所述asr系统设置有用于进行解码的解码网络;如图1所示,为现有技术中asr系统的框架示意图,传统asr系统包括:训练阶段和解码阶段;其中,训练阶段:利用语音数据库,基于深度神经网络等技术,训练出声学模型(acoustic model,am);利用文本数据库,基于ngram和深度神经网络等技术,训练出语言模型(language model,lm)。解码阶段:训练阶段得到的声学模型、语言模型,和发音词典一起可以组成一个解码网络。输入音频在经过特征提取以后,通过解码算法,可以从解码网络中找出一条最优路径,即得到最终的识别结果。但是其在复杂场景下的高插入错误,主要是声学模型(am)在计算声学打分时,无法准确区分人声和非人声,将噪声部分误判为了人声。且解码所用到的声学打分,直接来自于声学模型(am)的打分,是人声还是非人声也直接依赖于声学模型的性能。
39.而如图2所示,为本方案中asr系统的框架示意图,本方案在语音识别引擎内部加入一个sdm(speech detection module,语音检测模块),动态检测语音的产生,协助引擎判断人声和非人声,弥补声学模型在打分方面的不足,从而提高asr系统的识别准确性。
40.如图3所示,该方法包括以下步骤:
41.步骤101、通过所述sdm获取输入所述asr系统的原始音频和所述解码网络输出的历史解码信息;具体的,所述历史解码信息中包括上下文信息。
42.步骤102、通过所述sdm对所述原始音频进行处理,得到所述原始音频的多个信号特征;具体的,所述信号特征包括:信噪比、能量、过零率等。
43.步骤103、通过所述sdm基于多个所述信号特征以及所述历史解码信息进行处理,得到所述原始音频的最终特征。
44.具体的,本方案中,在asr系统解码环节加入的sdm输入有两个:输入音频和历史解码信息。输出有一个:模块对于当前输入语音的特征。
45.sdm直接针对输入的音频片段a,可以得到一组特征feat_a,该特征从信噪比、能量、过零率等多种维度表征了输入音频的特征;
46.针对解码网络已经得到的历史信息,可以将其作为输入,和上面的特征feat_a一起,作为语音检测模块对于当前输入音频的判断,输出特征feat_b,作为语音检测模块当前的输出特征。其中,解码网络得到的信息,是已经确定的上下文信息,具有更高的参考价值:从历史信息已知的人声和非人声中,可以提取出当前场景的人声和非人声特征。
47.以此,本方案与声学模型(am)的打分相比,sdm的输出特征feat_b,是从多个维度对当前输入音频做了描述;通过联合使用原始音频的特征和声学解码得到的上下文特征,可以弥补各自的不足,取得对复杂场景下人声/非人声的更准确的判断,提升引擎对复杂场景的打分识别能力,减少识别插入错误,提高识别率。
48.进一步的,在步骤103之后,如图2所示,该方法还包括:
49.通过所述sdm将所述最终特征输出给所述解码网络,以使所述解码网络进行解码,得到识别文本。
50.进一步的,所述asr系统中还包括声学模型;
51.所述解码网络的声学打分包括:所述声学模型的打分与所述sdm的打分;其中,所述声学模型的打分与所述sdm的打分各自对应各自的权重。
52.具体的,所述sdm的打分包括:从所述原始音频的信号特征得到的第一分数、基于所述历史解码信息得到的所述原始音频的第二分数;所述第一分数与所述第二分数各自对应各自的权重。
53.具体的,所述解码网络的声学打分可以通过下列公式来进行表示:
54.s
am
′
=w
am
s
am
w
sdm
(w
sdm_audios
s
dm_audio
w
sdm_history_decs
s
dm_history_dec
);
55.具体的,在加上sdm以后,解码用到的声学打分s
am
′
由两部分组成,一部分是直接来自声学模型的打分s
am
,它在最终打分中权重为w
am
;另一部分是sdm的打分,其在最终打分中权重为w
sdm
,sdm的打分又源自如下两部分:
56.一部分是直接从原始音频信息得到的分数s
sdm_audio
,通过音频信噪比、能量大小和过零率等信号特征得到,其权重为:w
sdm_audio
。
57.还一部分是依赖历史解码信息,进而得到当前音频的分数s
sdm_history_dec
。历史上得到的解码信息往往更加可靠,对当前语音特征有很强的指向性(音频具有时序性和短时稳定性)。可以通过历史解码信息得到当前识别场景的两个特征:语音特征feat_speech和非语音特征feat_nonspeech。当前音频的更倾向于哪个特征就可以认为是当前是speech或nonspeech。其权重为w
sdm_history_dec
。
58.本方案在asr系统解码阶段新增的“语音检测模块”,充分利用了各个维度的信息,包括直接从音频获取的信号特征、从历史解码信息中得到的上下文信息等,结合通过海量数据训练出的声学模型,能够提升asr系统在任何复杂场景下,对输入语音的打分和辨识能力,提升识别率。能够提升声学打分的准确性,进而提高asr系统引擎整体性能。本方案通过多维度特征的运用,能够在任何复杂场景下,对输入音频做出更综合更合理的打分,降低复杂环境带来的插入错误,提升系统的识别准确率。
59.实施例2
60.本发明实施例2还公开了一种提升语音识别准确性的设备,如图4所示,应用于设置有sdm的用于语音识别的asr系统,所述asr系统设置有用于进行解码的解码网络;该设备包括:
61.获取模块201,用于通过所述sdm获取输入所述asr系统的原始音频和所述解码网络输出的历史解码信息;
62.第一处理模块202,用于通过所述sdm对所述原始音频进行处理,得到所述原始音频的多个信号特征;
63.第二处理模块203,用于通过所述sdm基于多个所述信号特征以及所述历史解码信息进行处理,得到所述原始音频的最终特征。
64.在一个具体的实施例中,图5所示,还包括:
65.识别模块204,用于通过所述sdm将所述最终特征输出给所述解码网络,以使所述解码网络进行解码,得到识别文本。
66.在一个具体的实施例中,所述信号特征包括:信噪比、能量、过零率等。
67.在一个具体的实施例中,所述历史解码信息中包括上下文信息。
68.在一个具体的实施例中,所述asr系统中还包括声学模型;
69.所述解码网络的声学打分包括:所述声学模型的打分与所述sdm的打分;其中,所述声学模型的打分与所述sdm的打分各自对应各自的权重。
70.在一个具体的实施例中,所述sdm的打分包括:从所述原始音频的信号特征得到的第一分数、基于所述历史解码信息得到的所述原始音频的第二分数;所述第一分数与所述第二分数各自对应各自的权重。
71.本发明涉及一种提升语音识别准确性的方法和设备,应用于设置有sdm的用于语音识别的asr系统,所述asr系统设置有用于进行解码的解码网络;该方法包括:通过所述sdm获取输入所述asr系统的原始音频和所述解码网络输出的历史解码信息;通过所述sdm对所述原始音频进行处理,得到所述原始音频的多个信号特征;通过所述sdm基于多个所述信号特征以及所述历史解码信息进行处理,得到所述原始音频的最终特征。在asr系统解码阶段新增sdm,充分利用了各个维度的信息,包括直接从音频获取的信号特征、从历史解码信息中得到的上下文信息等,结合asr系统中原有的通过海量数据训练出的声学模型,能够提升asr系统在任何复杂场景下,对输入语音的打分和辨识能力,提升识别率。能够提升声学打分的准确性,进而提高asr系统整体性能。
72.以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

