本发明属于网络通信和语音识别技术领域,具体涉及一种端到端的多语言连续语音流语音内容识别方法及系统。
背景技术:
目前,端到端识别框架已广泛应用于自动语音识别任务。由于端到端框架在构建语音识别系统的过程中不依赖于发音词典,因此在构建新语言的语音识别系统以及多语言语音识别系统的过程中更加灵活。不仅如此,端到端语音识别模型可以对声学特征序列和文本建模单元序列之间的映射关系进行直接建模。相比于基于声学建模和语言建模的传统语音识别系统,端到端框架将声学建模和语言学建模过程进行统一,有效地降低了语音识别系统构建的复杂性。
在多语言语音识别系统的构建过程,虽然端到端框架可以降低语音识别系统构建的复杂性,但也给多语言语音识别带来了新问题。多语言端到端框架将多种语言的建模单元在一个统一的框架下进行建模,由于不同语言间发音机制以及语法规则存在较大差异,相比于单语言语音识别系统来说,将多种语言进行联合建模会不可避免地在使得多语言建模单元相互混淆。现有的语音内容识别方法存在无法有效提升多语言语音识别系统的语种区分性的问题。
技术实现要素:
本发明的目的在于,为解决现有的语音识别方法存在上述缺陷,本发明提出了一种端到端的多语言连续语音流语音内容识别方法及系统,具体涉及一种基于多注意力机制的端到端多语言的语音识别方法,该方法将语种分类信息引入到端到端建模过程中,并结合多注意训练机制有效提升多语言语音识别系统的性能。
为了实现上述目的,本发明还提供了一种端到端的多语言连续语音流语音内容识别方法,该方法包括:
将待识别的语音频谱特征输入至预先构建的基于深度神经网络的段级别语种分类模型,输出语句级别语种状态后验概率分布向量;
将每一种语言种类的待识别的语音频谱特征序列和语句级别语种状态后验概率分布向量,输入至预先构建的多语言语音识别模型,输出对应语言种类的语音识别结果。
作为上述技术方案的改进之一,所述方法还包括:根据语句级别语种状态后验概率分布向量,获得对应语言种类的语种分类结果,将其结合预先构建的多语言语音识别模型中的解码网络的输出的对应语言种类的语音识别结果的历史信息,获得相应的解码网络预测序列,最终得到多语言语音识别结果。
作为上述技术方案的改进之一,所述方法还包括:基于深度神经网络的段级别语种分类模型的训练步骤,具体包括:
提取训练集的多语言连续语音流的帧级别的语音频谱特征,将所述帧级别语音频谱特征输入至该段级别语种分类模型,对当前隐含层的输出向量进行长时统计,计算当前隐含层输出向量的均值向量、方差向量和段级统计向量;
所述均值向量为:
所述方差向量为:
所述段级统计向量:
hsegment=append(μ,σ)(6)
其中,hj为当前隐含层在j时刻的输出向量;t为长时统计周期;μ为长时统计的均值向量;σ为长时统计的方差向量;hsegment为段级统计向量;其中,所述段级统计向量是将均值向量和方差向量拼接在一起,其维度为hj维度的2倍;append(μ,σ)表示将μ和σ进行拼接构成高维向量;
将段级统计向量hsegment作为下一隐含层的输入,根据段级别语种标签,通过误差计算和反向梯度回传过程训练,获得训练好的段级别语种分类模型,完成该段级别语种分类模型的建立。
作为上述技术方案的改进之一,所述多语言语音识别模型包括:编码网络、多个注意力机制模块和解码网络;其中,根据待识别的语言种类数目,设置对应数目的注意力机制模块;
根据待识别的语音频谱特征中包含的语言种类数目,设置对应数目的注意力机制模块。
作为上述技术方案的改进之一,所述注意力机制模块的训练步骤具体包括:
将语音特征的状态序列henc输入至对应的注意力机制模块,输出对应的输出状态序列;
根据公式(2),获得对应的输出序列:
elt,i=wttanh(wlhenc vlhdeci ul(fl*alt,i-1) bl)(2)
其中,l表示多语言的语言种类标号;elt,i表示第t帧待识别的语音频谱特征的注意力机制模块的输出状态;wt,wl,vl,ul分别表示第一变换矩阵、第二变换矩阵、第三变换矩阵和第四变换矩阵;bl表示偏置向量;tanh()表示非线性激活函数;fl表示卷积函数;
根据该对应的输出状态序列,获得对应的语言种类的注意力权重向量;
具体地,根据公式(3),获得对应的语言种类的注意力权重向量:
其中,alt,i表示第l个语言种类的注意力权重向量在第i个输出建模单元的第t帧对应的权重值;elt′,i为第t′帧待识别的语音频谱特征在第i个输出建模单元对应的注意力机制模块的输出状态;1≤t′≤t为语音特征序列的对应帧。
作为上述技术方案的改进之一,所述将每一种语言种类的待识别的语音频谱特征序列和语句级别语种状态后验概率分布向量,输入至预先构建的多语言语音识别模型,输出对应语言种类的语音识别结果;具体为:
将每一种语言种类的待识别的语音频谱特征输入至编码网络,输出对应的语音特征的状态序列;
根据公式(1),获得对应的语音特征的状态序列henc:
henc=encoder(x)(1)
其中,
将该对应的语音特征状态序列与对应的语言种类的注意力权重向量进行加权求和,获得对应的注意力上下文内容向量;
具体地,根据公式(4),获得对应的注意力上下文内容向量;
其中,cli表示对应的注意力上下文内容向量,即第l个语言种类对编码网络加权求和得到的注意力上下文内容向量;
在多注意力机制条件下,通过语种状态分布向量vl与对应的注意力上下文内容向量进行加权求和,得到最终的注意力上下文内容向量:
其中,vl为语种状态分布向量,即vl=(wl1,wl2,...,wln,...,wln);n为待识别的多语言的语言种类数目;
将所述最终的注意力上下文内容向量输入至解码网络,获得该语言种类的语音识别结果。
本发明还提供了一种端到端的多语言连续语音流语音内容识别系统,所述系统包括:提取模块和语音识别模块;
所述提取模块,用于将待识别的语音频谱特征输入至预先构建的基于深度神经网络的段级别语种分类模型,并根据该段级别语种分类模型,提取语句级别语种状态后验概率分布向量;
所述语音识别模块,将每一种语言种类的待识别的语音频谱特征序列和语句级别语种状态后验概率分布向量,输入至预先构建的多语言语音识别模型,输出对应语言种类的语音识别结果。
作为上述技术方案的改进之一,所述系统还包括:语音结果获取模块,用于根据语句级别语种状态后验概率分布向量,获得对应语言种类的语种分类结果,将其结合预先构建的多语言语音识别模型中的解码网络的输出的对应语言种类的语音识别结果的历史信息,获得相应的解码网络预测序列,最终得到多语言语音识别结果。
本发明还提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述方法。
本发明还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述方法。
本发明与现有技术相比的有益效果是:
本发明的方法是基于多注意力机制的端到端多语言语音识别方法,该方法在基于注意力机制的端到端框架下为每种语言构建特定的注意力机制模块,该注意力机制模块对特定语言的输入频谱特征序列与输出标注序列的映射关系进行语言特定建模。此外通过将语种分类信息引入到端到端建模过程中,对多注意力机制模块的输出信息进行加权,从而可以有效提升多语言语音识别系统的语种区分性。
附图说明
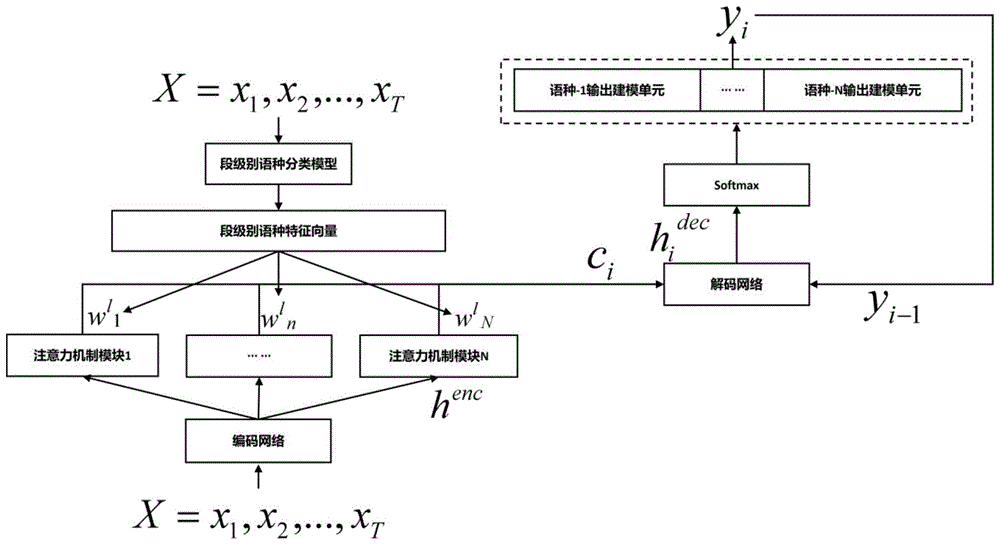
图1是本发明的一种端到端的多语言连续语音流语音内容识别方法的流程图。
具体实施方式
现结合附图对本发明作进一步的描述。
如图1所示,本发明提供了一种端到端的多语言连续语音流语音内容识别方法,该方法包括:
将待识别的语音频谱特征输入至预先构建的基于深度神经网络的段级别语种分类模型,并根据该段级别语种分类模型,提取语句级别语种状态后验概率分布向量vl,获得对应语言种类的语种分类结果;其中,对应语言种类的语种分类结果为语句级别语种状态后验概率分布向量vl;待识别的语音频谱特征是通过对多语言连续语音流进行傅里叶变换得到的频域表示,多语言连续语音流是指语音流中只包含一种语言信息的语音流,但是语音流的语言种类未知的情况。
具体地,基于待识别的语音频谱特征序列输入到所述段级别语种分类模型,通过神经网络前向计算,并根据该段级别语种分类模型,提取语句级别语种状态后验概率分布向量vl,获得对应语言种类的语种分类结果。
其中,所述基于深度神经网络的段级别语种分类模型的建立具体包括:
提取训练集的多语言连续语音流的帧级别的语音频谱特征,将所述帧级别语音频谱特征输入至该段级别语种分类模型,对当前隐含层的输出向量进行长时统计,计算当前隐含层输出向量的均值向量、方差向量和段级统计向量;
所述均值向量为:
所述方差向量为:
所述段级统计向量:
hsegment=append(μ,σ)(6)
其中,hj为当前隐含层j时刻的输出向量;t为长时统计周期;μ为长时统计的均值向量;σ为长时统计的方差向量;hsegment为段级统计向量;其中,所述段级统计向量是将均值向量和方差向量拼接在一起,其维度为hj维度的2倍;append(μ,σ)表示将μ和σ进行拼接构成高维向量;
将段级统计向量hsegment作为下一隐含层的输入,根据段级别语种标签,通过误差计算和反向梯度回传过程训练,获得训练好的段级别语种分类模型,完成该段级别语种分类模型的建立。其中,所述语种标签为带有语言种类的标签。
将每一种语言种类的待识别的语音频谱特征序列和语句级别语种状态后验概率分布向量输入至预先构建的多语言语音识别模型,输出对应语言种类的语音识别结果。
其中,如图1所示,所述多语言语音识别模型包括:编码网络、多个注意力机制模块(注意力机制模块1,注意力机制模块2,…,注意力机制模块n)和解码网络。其中,根据待识别的语言种类数目,设置对应数目的注意力机制模块;
具体地,根据待识别的语音频谱特征中包含的语言种类数目,设置对应数目的注意力机制模块;
将每一种语言种类的待识别的语音频谱特征输入至编码网络,输出对应的语音特征的状态序列;
具体地,根据公式(1),获得对应的语音特征的状态序列henc:
henc=encoder(x)(1)
其中,henc=(henc1,henc2,...,henct,...,henct)为语音特征的状态序列,即编码网络的隐层状态输出序列;x=(x1,x2,...,xt,...,xt)为待识别的语音频谱特征序列,即输入特征;其中,t为输入特征序列的总帧数;encoder()为基于卷积神经网络/双向长短时记忆网络(cnn/blstm)的编码网络的计算函数。
将对应的语音特征的状态序列henc输入至对应的注意力机制模块,输出对应的输出状态序列;
具体地,根据公式(2),获得对应的输出序列:
elt,i=wttanh(wlhenc vlhdeci ul(fl*alt,i-1) bl)(2)
其中,l表示多语言的语言种类标号;elt,i表示第t帧待识别的语音频谱特征的注意力机制模块的输出状态;wt,wl,vl,ul分别表示第一变换矩阵、第二变换矩阵、第三变换矩阵和第四变换矩阵;bl表示偏置向量;tanh()表示非线性激活函数;fl表示卷积函数;henct表示第t帧编码网络的输出状态;hdeci表示解码网络的第i个输出建模单元的隐含层状态;alt,i-1为第l个语言种类的注意力权重向量在第i-1个输出建模单元的第t帧对应的权重值;
根据该对应的输出状态序列,获得对应的语言种类的注意力权重向量;
具体地,根据公式(3),获得对应的语言种类的注意力权重向量:
其中,alt,i表示表示第l个语言种类的注意力权重向量在第i个输出建模单元的第t帧对应的权重值;elt′,i为第t′帧待识别的语音频谱特征在第i个输出建模单元对应的注意力机制模块的输出状态;1≤t′≤t为语音特征序列的对应帧;
将该对应的语音特征状态序列与对应的语言种类的注意力权重向量进行加权求和,获得对应的注意力上下文内容向量;
具体地,根据公式(4),获得对应的注意力上下文内容向量;
其中,cli表示对应的注意力上下文内容向量,即第l个语言种类对编码网络加权求和得到的注意力上下文内容向量;
在多注意力机制条件下,通过语种状态分布向量vl与对应的注意力上下文内容向量进行加权求和,得到最终的注意力上下文内容向量:
其中,vl为语种状态分布向量,即vl=(wl1,wl2,...,wln,...,wln);n为待识别的多语言的语言种类数目;
将所述最终的注意力上下文内容向量输入至解码网络,获得该语言种类的语音识别结果。
所述方法还包括:将该语言种类的语种分类结果,结合预先构建的多语言语音识别模型中的解码网络的输出的对应语言种类的语音识别结果的历史信息,获得相应的解码网络预测序列,最终得到多语言语音识别结果。
具体地,为了预测解码网络的第i个输出建模单元yi的概率,所述的输出建模单元为图1所示的语种-1输出建模单元,…,语种-n输出建模单元,需要首先预测解码网络的第i个输出建模单元的解码网络隐含层状态hdeci,其中,解码网络的输入为第i-1个输出建模单元和注意力上下文内容向量ci,如公式(6)所示,最终结合softmax函数可以由解码网络的第i个输出建模单元的解码网络隐含层状态hdeci预测解码网络的第i个输出建模单元yi的概率p(yi|y1:i-1,x),如公式(7)所示:
hidec=decoder(yi-1,ci)(6)
p(yi|y1:i-1,x)=softmax(hidec)(7)
其中,x表示输入的待识别的语音频谱特征序列;yi-1为解码网络的第i-1个输出建模单元;ci为最终的注意力上下文内容向量;y1:i-1为解码网络的第1个输出到第i-1个输出的历史信息;p(yi|y1:i-1,x)为解码网络的第i个输出建模单元yi的预测概率;softmax(hidec)为对解码网络隐含层状态hdeci取softmax函数;yi表示解码网络的第i个输出建模单元;decoder()表示基于长短时记忆网络(lstm)的解码网络;
通预测概率p(yi|y1:i-1,x),可以得到第i次建模单元预测过程中预测概率最大的建模单元yi,通过结合第1次预测的结果到第i次预测的结果,可以得到最终的语音识别结果y=(y1,y2,...,yi,...,yi)。
对于不同语言来说,输入特征序列和输出建模单元序列的时间步长映射是不一致的,因此通过这种方式可以使得多种语言之间在编码网络和解码网络进行模型信息共享的同时还可以根据特定语言的特性对注意力模块进行优化。
本发明还提供了一种端到端的多语言连续语音流语音内容识别系统,该系统基于上述方法来实现,该系统包括:
提取模块,用于将待识别的语音频谱特征输入至预先构建的基于深度神经网络的段级别语种分类模型,并根据该段级别语种分类模型,提取语句级别语种状态后验概率分布向量vl;
语音识别模块,将每一种语言种类的待识别的语音频谱特征序列和语句级别语种状态后验概率分布向量vl输入至预先构建的多语言语音识别模型,输出对应语言种类的语音识别结果。
所述系统还包括:语音结果获取模块,用于根据语句级别语种状态后验概率分布向量vl,获得对应语言种类的语种分类结果,将该语言种类的语种分类结果,结合预先构建的多语言语音识别模型中的解码网络的输出的对应语言种类的语音识别结果的历史信息,获得相应的解码网络预测序列,最终得到多语言语音识别结果。
本发明还提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述方法。
基于本发明的基于多注意力机制的多语言语音识别系统的合理性和有效性已经在实际系统上得到了验证,结果见表1:
表1多语言端到端识别模型的识别结果(词错误率%)
本发明的方法通过使用他加禄语、宿雾语、托克皮辛语和海地克里奥尔语构建多语言端到端语音识别系统。其中,他加禄语和宿雾语是在菲律宾不同地区使用的菲律宾语,而托克皮辛语和海地克里奥尔语是两种不同的克里奥尔语。这四种语言的共同特征是它们的标注文本都是拉丁字母以及拉丁字母的变体。
因此,基于这四种语言的多语言联合建模可以有效地共享信息并提高多语言语音识别系统的性能。从表1可知,相比于单语言端到端识别模型以及不包含多注意力机制模块的多语言端到端识别系统来说,本发明的方法通过将语种信息融合到多语言识别方法中,并结合多注意力机制模块,在四种语言上有效将多语言识别模型的词错误率从平均62.6%降低到60.3%。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

