本发明属于心音处理技术领域,更为具体地讲,涉及一种基于vmd和多小波的心音分割定位方法。
背景技术:
目前采用可穿戴心音检测设备进行心音监测已经成为了诊断和控制心脏疾病的重要手段,但是现有的可穿戴心音检测设备所采集的心音信号具有低幅值、低频率、易受干扰等特性,考虑到可穿戴心音检测设备使用的复杂环境,使用过程中可能会引入其他生理音干扰、背景噪声、工频干扰以及运动伪影等,进而会严重影响对所采集到心音信号做进一步的处理。
传统的心音分割定位算法是与心电图相结合,在使用心电图作为参考的情况下,心音分割的效果很好。然而,心电图作为另一种信号源,在医学检查中可能不方便使用。如果嵌入ecg电路会极大地提高电子听诊器的硬件复杂度。因此,使用心音信号作为唯一信号源也是当下的主要研究方向。目前不使用参考信号的主流心音信号处理流程为先对原始心音信号进行去噪之后,对其进行特征提取、分类,从而对心动周期的各组分进行分割定位。
在信号去噪方面,最传统的方法是基于心音信号的频域特征进行滤波去噪,但这种方法仅可抑制心音分量频带外的干扰,心音作为典型的非平稳信号,非常容易受带内噪声或其他生理音干扰,由于时频率(tf)域可以产生更健壮的定位和分类方法,特别是对非平稳信号,因此时频域的分析方法也被应用于了心音处理领域。
目前,研究非平稳信号常用的时频分析工具有:短时傅里叶变换、维格纳-维尔分布、科恩类、小波变换和s变换等。时傅里叶变换的时频分辨率不能自适应,而维格纳-维尔分布和科恩类虽然具有良好的时频特性,但是由于存在交叉干扰项,影响了它们的实际应用范围。作为短时傅里叶变换的继承和发展,s变换采用高斯窗函数且窗宽与频率的倒数成正比,免去了窗函数的选择和改善了窗宽固定的缺陷,并且时频表示中各频率分量的相位谱与原始信号保持直接的联系,使其在信号分析中可以采用更多的特征量。s变换的缺点是在较高频带范围内相对于小波变换来说,对频域的分析上不够精确。
另外,因为可穿戴心音监测平台采集的单通道测量信号是由不同的物理过程产生的,而且它们在统计上是相互独立的,所以可以看作心音信号和背噪两个独立信号的叠加,因此采用基于盲源分离的方法进行处理也是现在的一种新的处理思路。目前使用频率比较高的盲源信号分离的方法主要是经验模态分解(empiricalmodedecomposition,emd)、小波分解以及他们的衍生算法如(ensembleempiricalmodedecomposition,eemd)等。然而emd算法存在模态混叠、模态残差噪声及虚假模态问题,而且emd算法现实中所产生的本征模函数(intrinsicoscillatorymode,imf)不会保持完全稳定的频率和振幅。因此在2014年提出了vmd(variationalmodedecomposition,变分模态分解)的方法,此方法是一种自适应、完全非递归的模态变分和信号处理的方法。该技术具有可以确定模态分解个数的优点它克服了emd方法存在端点效应和模态分量混叠的问题,并且具有更坚实的数学理论基础。
在心音特征提取方面,传统的方法所提取的特征大多以频域特征和时域特征为主,或者对信号提取包络特征,即利用各种技术构造心音包络来进行心音分割,其中香农包络和希尔伯特包络是最常使用的两种包络。基于包络抽取方法参数的推导直接受到阈值的影响,阈值选择主要是依靠经验值,所以容易因为过学习而导致在不同样本集之间泛化性不强。
总体来说,虽然目前方法可以实现在正常心音信号中识别s1/s2的难度不高,但如果想在可穿戴平台上使用传统的心音处理方法进行处理还是有很多问题:可穿戴平台面对的复杂噪声的使用场景,如杂音、咔嚓声、噼啪声和低信噪比等场景,会极大地提高心音分割定位的难度。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于vmd和多小波的心音分割定位方法,结合vmd分解、多小波、香农包络和奇异值分解,以提高在高噪声的现实场景中识别和分割心音信号的性能。
为了实现上述发明目的,本发明基于vmd和多小波的心音分割定位方法包括以下步骤:
s1:采集若干心音信号样本xd(t),其中d=1,2,…,d,d表示心音信号样本的数量,t表示时间;对每个心音信号样本xd(t)进行去噪处理,然后按照采样频率fs进行重采样得到每个心音信号样本的采样信号xd(n),其中n=1,2,…,sd,sd表示采样信号xd(n)的采样点数;在每个心音信号样本的采样信号xd(n)中标记第一心音s1和第二心音s2的区间,记标记得到的第k个心音区间为
s2:采用滑动窗对各个采样信号xd(n)进行片段划分得到nd个采样信号片段xd,i(n′),i=1,2,…,nd,n′=1,2,…,w,w表示采样信号xd(n)每个信号片段的长度;
s3:对于每个采样信号xd(n),在步骤s2划分得到nd个信号片段xd,i(n′)后,对每个信号片段分别进行v层vmd分解,记信号片段xd,i(n′)经vmd分解得到的第v个分量为
s4:对于每个信号片段xd,i(n′)经过vmd分解得到的v个分量
s5:将各个imf分量信号
s6:对于各个信号xd,i(n″)经ghm多小波分解得到k个大小为2×w′信号分量yd,i,j,构建得到大小为2k×w′的信号矩阵zd,i:
对于同一心音信号样本的nd个信号片段xd,i(n′),采用其所对应的nd个信号矩阵zd,i构建得到大小为2k×ld的时频域矩阵md:
其中,
其中,
s7:对于得到的每个时频域矩阵md对行进行降维,得到降维后大小为p×ld的时频域矩阵
s8:对步骤s1中每个心音信号样本所标记的心音区间
对各个子矩阵
其中,qd,k表示p×p阶的酉矩阵,vd,k表示ud×ud阶的酉矩阵,∑d,k表示大小为p×ud的奇异值矩阵;
在奇异值矩阵∑d,k选择最大的前m个奇异值,其中m根据实际需要设置,从矩阵qd,k中提取出m个坐标为(m,m)的元素值
s9:将步骤s8得到的各个时间频率列向量fd,k作为输入,对应的标签flagd,k作为输出,对预设的分类模型进行训练;
s10:采集待分割定位的心音信号
s11:采用步骤s2中的相同方法对待分割定位心音信号的采样信号
s12:对于待分割定位心音信号的时频域矩阵m′,分别计算每一列的香农能量sse(b),从而得到香农能量包络;
s13:对于待分割定位心音信号所对应的香农能量包络,筛选出香农能量最大值ssemax,然后基于最大类间方差法获取区分噪音和心音的分类阈值th,然后使用类间方差法确定的分类阈值th作为较高的门限t1,即t1=th,在香农能量包络中提取出连续高于阈值th的区间,将区间长度小于预设阈值的区间删除,剩余区间即为第一心音s1或第二心音s2所在的粗定心音区间
s14:根据步骤s12得到的心音区间zk′,从时频域矩阵m′提取对应列构成子矩阵mk″,采用步骤s8中的相同方法,基于奇异值分解得到该心音区间的时间频率列向量fk″;
s15:将每个心音区间的时间频率列向量fk″分别输入步骤s9训练好的分类模型,其分类结果即为该心音区间内心音信号的类型;
s16:将待分割定位心音信号的每个心音区间
本发明基于vmd和多小波的心音分割定位方法,首先对心音信号样本中第一心音和第二心音的心音区间和类型进行标记,采用滑动窗对心音信号样本进行片段划分,使用峭度对vmd分解得到的各个imf分量进行挑选,对最有效的imf分量进行ghm多小波包分解,基于分解结果构建心音信号样本的时频域矩阵,根据标记的心音区间从中提取子矩阵并得到时间频率列向量,将其作为输入,对应类型标签作为输出,对预设的分类模型进行训练;对待分割定位的心音信号采用相同方法得到时频域矩阵,提取香农能量包络,基于最大类间方差法确定心音区间,提取子矩阵并采用相同方法获取时刻频率列向量,输入训练好的分类模型得到分类结果,从而得到心音信号分割定位结果。
本发明具有以下有益效果:
1)本发明可以实现心音信号的自适应分解、自适应降维、全自动提取、自动选择分解层数,无需人工选择,避免人工参数设置干扰;
2)经实验验证,本发明能够在高噪声环境下对心音信号的各组份进行鲁棒的准确定位和分类。
附图说明
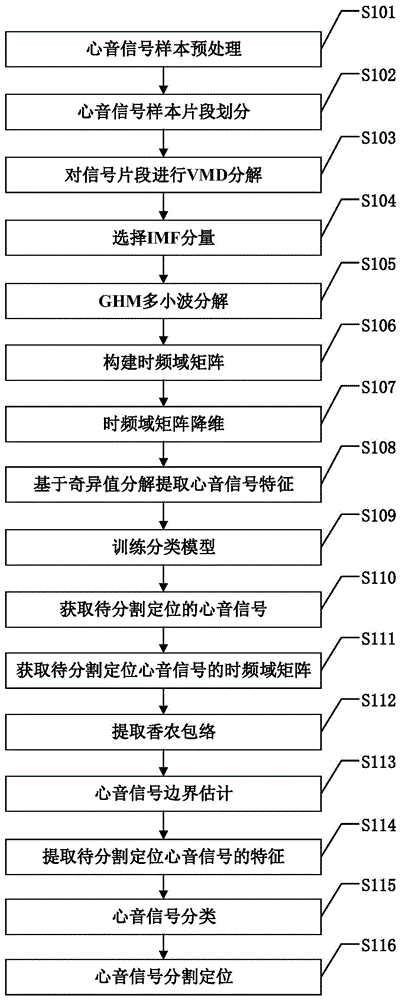
图1是本发明基于vmd和多小波的心音分割定位方法的具体实施方式流程图;
图2是心音信号的vmd分解结果示例图;
图3是小波包分解示意图;
图4是本实施例中时频域矩阵的示例图;
图5是本实施例中自行采集心音信号示例图;
图6是本实施例中纯净心音信号叠加白噪声所得到的归一化心音信号波形图;
图7是vmd ewt算法采用对图6所示心音信号进行处理后的归一化信号波形图;
图8是采用emd pca算法对图5所示心音信号进行处理后的归一化信号波形图;
图9是采用本发明中多小波 pca算法对图6所示心音信号进行处理后的归一化信号波形图;
图10是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的信噪比比较图;
图11是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的相关系数比较图;
图12是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的均方误差比较图;
图13是本发明和两种对比方法在不同信噪比粉噪声下心音信号去噪后的信噪比比较图;
图14是本发明和两种对比方法在不同信噪粉噪声下心音信号去噪后的相关系数比较图;
图15是本发明和两种对比方法在不同信噪比粉噪声下心音信号去噪后的均方误差比较图;
图16是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的信噪比比较图;
图17是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的相关系数比较图;
图18是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的均方误差比较图;
图19是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的信噪比比较图;
图20是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的相关系数比较图;
图21是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的均方误差比较图;
图22是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的信噪比比较图;
图23是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的相关系数比较图;
图24是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的均方误差比较图;
图25是采用本发明对图6所示心音信号进行处理后提取的香农包络结果图。
图26是采用本发明对图6所示心音信号进行处理后的处理结果图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图1是本发明基于vmd和多小波的心音分割定位方法的具体实施方式流程图。如图1所示,本发明心音分割定位方法的具体步骤包括:
s101:心音信号样本预处理:
采集若干心音信号样本xd(t),其中d=1,2,…,d,d表示心音信号样本的数量,t表示时间。对每个心音信号样本xd(t)进行去噪处理,然后按照采样频率fs进行重采样得到每个心音信号样本的采样信号xd(n),其中n=1,2,…,sd,sd表示采样信号xd(n)的采样点数。在每个心音信号样本的采样信号xd(n)中标记第一心音s1和第二心音s2的区间,记标记得到的第k个心音区间为
对可穿戴平台而言,根据心音信号的频谱分布范围主要集中分布在10-200hz,高频心杂音可达1000hz的特性,先进行一个10-500hz的带通预滤波,同时设置一个50hz的带阻滤波器来滤除工频干扰。本实施例中在进行去噪处理后,根据香农采样定理,将各个样本统一重采样到2000hz方便后续进行统一处理。
s102:心音信号样本片段划分:
由于本发明中需要对心音信号进行vmd分解,vmd算法最大的局限性是边界效应和突发的信号,直接的解决方案是将信号分解成较短的块,在这些块上信号足够稳定。因此本发明采用滑动窗对各个采样信号xd(n)进行片段划分得到nd个采样信号片段xd,i(n′),i=1,2,…,nd,n′=1,2,…,w,w表示采样信号xd(n)每个信号片段的长度,也就是窗宽。
滑动窗的具体类型的参数可以根据需要进行设置,本实施例中采用窗宽为180,步长为90的高斯窗w(n)对心音信号xd(n)进行了分段操作,其中高斯窗w(n)的表达式为:
其中,δ表示窗宽调节参数,本实施例中设置为2.5,t表示信号周期。
s103:对信号片段进行vmd分解:
对于每个采样信号xd(n),在步骤s102划分得到nd个信号片段xd,i(n′)后,对每个信号片段分别进行v层vmd分解,记信号片段xd,i(n′)经vmd分解得到的第v个分量为
vmd分解是一种非递归分解方法,自适应同步提取复杂信号中的调幅-调频分量。该方法将信号为一组本征模态分量(imf),通过这些本征模态分量,可以重构信号,在频域内迭代更新各个本征模态分量,将本征模态分量频谱的重心作为中心频率。假设本征模态分量在频域内紧致聚集在中心频率周围,即具有稀疏性质。每个本征模态分量的稀疏性质通过它的带宽来描述:(1)应用hilbert变换构造其解析信号,以便获得非负频率的单边频谱;(2)通过和频率调整至各自中心频率处的指数谐波相乘,将频谱平移至基带;(3)通过梯度的平方l2范数估计带宽。为了将约束变分优化问题转化为无约束形式,增加惩罚项和lagrange乘子,以便快速收敛并增强约束,所以,最小化的目标函数转换为增广lagrange函数:
式中,λ(t)为lagrange乘子,α为惩罚系数,是数据真实性约束的平衡参数,
vmd分解的过程简述如下:
(1)初始化:将
(2)对于v=1,2,…,v及所有w(w≥0),更新每个本征模态分量cv(t)和中心频率wv,更新本征模态分量cv(t)的计算公式为:
更新中心频率wv的计算公式为:
(3)对于所有w≥0,更新lagrange乘子;
(4)检查收敛条件:
其中,ε为预设的阈值。
如果条件满足,令
vmd分解中最主要的参数有两个,一个是分解层数v,另一个是惩罚系数α。
在分解层数v的选择上,如果分解尺度太小,会导致vmd自适应的维纳滤波将重要信息滤除。反之若分解的imf分量过多,会导致中心频段发生重叠现象。惩罚因子α的选取主要影响各imf分量的带宽和收敛的速度。本实施例设定惩罚因子α的搜索区间为[203000],搜索步长为20,分解导数v的搜索区间设[210],搜索步长为1,对原始信号实施vmd分解,求出分解后的各imf分量中最大峭度值并保存,从保存的峭度值中筛选出最大的,这个最大峭度值所采用的参数v值与α值即为最优。根据实验结果可知,对于心音信号中第一心音s1和第二心音s2而言,最优的分解层数v为6,惩罚系数α为2520。
s104:选择imf分量:
信号的一个重要特性是它的振荡振幅,可以利用每个模态的振幅函数来计算每个imf分量的概率密度分布函数值(pdf)。基于贝叶斯解释,pdf值表示有关系统或感兴趣信号的知识状态,而不仅仅是频率。因为pdf值包含有关其对应的imf分量的完整信息,所以可以使用pdf分量的相似性度量来识别、捕捉包含更多有用信息的imf。对于信号进行vmd分解的结果,可以计算得到各imf分量之间的pdf值,pdf值包括kl散度、js散度、互相关系数以及峭度的pdf值,然后计算各imf分量的pdf值与原信号的pdf值之间的l2范数,l2范数最大的imf分量即为信号的主模式,比主模式频带要低的imf内是低频干扰,主要包括运动伪迹中的低频运动信号部分、肺音部分以及有色噪声的红色噪声中的低频部分;比主模式频带要高的imf内是高频干扰,主要是运动伪迹中听诊头与人体的相对位移所引入高频噪声,以及各色有色噪声。图2是心音信号的vmd分解结果示例图。如图2所示,不难看出,有效心音信号主要集中在第二层内,第一层主要是以运动伪迹为主的低频基线漂移,第二层以下的主要是以高斯白噪声为主的高频噪声干扰。
根据对心音信号的pdf值进行分析,峭度对于心音信号的区分度最高。峭度kurtosis反映随机变量分布特性的数值统计量,是归一化4阶中心矩。峭度对冲击信号特别敏感,因此,在本发明中,对于每个信号片段xd,i(n′)经过vmd分解得到的v个分量
s105:ghm多小波分解:
在步骤s104得到nd个信号片段的imf分量信号
多小波系统对应的是一个多滤波器,滤波器系数是矩阵,输入具有向量形式,在多小波变换的情况下,需要对每个信号xd,i(n″)进行预滤波处理,得到大小为2×w的预滤波信号
然后采用ghm多小波系统对每个预滤波信号
ghm多小波系统对应的是一个多滤波器,其中低通滤波器由四个2×2的矩阵ha给出,而高通滤波器由四个2×2矩阵ga给出,a=0,1,2,3。进行第一层分解后的公式可以表示为:
其中:
本实施例中四个2×2矩阵ha和四个2×2矩阵ga的具体取值分别如下:
第一层分解完成后,
在实际应用中,可以选择对高频分量或低频分量进行连续分解,也可以二者一起进行连续分解,即为小波包分解,本实施例中即采用小波包分解。图3是小波包分解示意图。如图3所示,对每一层分解得到的高频分量和低频分量均进行连续分解,经过λ层分解后,得到2λ个大小为2×w′的信号分量,即得到信号分量数量k=2λ。
s106:构建时频域矩阵:
对于各个信号xd,i(n″)经ghm多小波分解得到k个大小为2×w′信号分量yd,i,j,构建得到大小为2k×w′的信号矩阵zd,i:
对于同一心音信号样本的nd个信号片段xd,i(n′),采用其所对应的nd个信号矩阵zd,i构建得到大小为2k×ld的时频域矩阵md:
其中,
其中,
根据以上公式可知,在构建时频域矩阵md时,相邻两个信号矩阵zd,i各取一半元素进行叠加。
假设采样信号长度sd=3960,划分的信号片段数量nd=43,长度w=90,信号片段的imf分量信号插值后的长度w=1440,ghm多小波系统的分解层数λ=4,则w′=w/2λ=90。ghm多小波系统采用小波包分解,则时频域矩阵md的大小为32×1980。图4是本实施例中时频域矩阵的示例图。
s107:时频域矩阵降维:
为了便于后续分析,本发明对于得到的每个时频域矩阵md对行进行降维,得到降维后大小为p×ld的时频域矩阵
本实施例中采用主成分分析方法进行降维,主成分分析方法是一种常用的降维方法,其具体过程在此不再赘述。
s108:基于奇异值分解提取心音信号特征:
由于步骤s101中每个心音信号样本所标记的心音区间
对各个子矩阵
其中,qd,k表示p×p阶的酉矩阵,vd,k表示ud×ud阶的酉矩阵,∑d,k表示大小为p×ud的奇异值矩阵。
在奇异值矩阵∑d,k选择最大的前m个奇异值,其中m根据实际需要设置,从矩阵qd,k中提取出m个坐标为(m,m)的元素值
s109:训练分类模型:
将步骤s108得到的各个时间频率列向量fd,k作为输入,对应的标签flagd,k作为输出,对预设的分类模型进行训练。本实施例中分类模型采用svm(supportvectormachines,支撑向量机)模型。
s110:获取待分割定位的心音信号:
采集待分割定位的心音信号
s111:获取待分割定位心音信号的时频域矩阵:
采用步骤s102中的相同方法对待分割定位心音信号的采样信号
s112:提取香农包络:
对于待分割定位心音信号的时频域矩阵m′,分别计算每一列的香农能量sse(b),从而得到香农能量包络。香农能量sse(b)的计算公式如下:
其中,m′(p,b)表示时频域矩阵m′中第p行第b列的元素值,b=1,2,…,l。
接下来还可以对香农能量包络采用均值滤波器进行平滑处理,以实现去噪处理。
s113:心音信号边界估计:
对于待分割定位心音信号所对应的香农能量包络,筛选出香农能量最大值ssemax,然后基于最大类间方差法获取区分噪音和心音的分类阈值th。基于最大类间方差法获取区分噪音和心音的分类阈值th的具体方法为:
1)初始化r=1,初始化噪音集合
2)对于每一列的香农能量sse(b),判断是否
3)根据以下公式计算当前分类的类间方差gr:
gr=ωr0×ωr1×(μr0-μr1)2
其中,ωr0=|φ0|/l,ωr1=|φ1|/l,|φ0|和|φ1|分别表示噪音集合φ0和心音集合φ1中的香农能量数量,μr0和μr1分别表示噪音集合φ0和心音集合φ1中的香农能量平均值。
4)判断是否r<r,如果是,进入步骤5),否则进入步骤6)。
5)令r=r 1,返回步骤2)。
6)筛选出类间方差gr中的最大值gr*,则分类阈值
计算得到阈值之后使用单参数的双门限法来定位到心音的边界,具体方法为:使用类间方差法确定的分类阈值th作为较高的门限t1,即t1=th,先进行一次粗判,具体方法为:在香农能量包络中提取出连续高于阈值th的区间,将区间长度小于预设阈值的区间删除,剩余区间即为第一心音s1或第二心音s2所在的粗定心音区间
s114:提取待分割定位心音信号的特征:
根据步骤s112得到的心音区间zk′,从时频域矩阵m′提取对应列构成子矩阵m′k′,采用步骤s108中的相同方法,基于奇异值分解得到该心音区间的时间频率列向量f′k′。
s115:心音信号分类:
将每个心音区间的时间频率列向量f′k′分别输入步骤s109训练好的分类模型,其分类结果即为该心音区间内心音信号的类型。
s116:心音信号分割定位:
由于待分割定位心音信号的时频域矩阵m′的列数是其采样信号x′(n)采样点数的2k倍,为了将心音区间还原到原始信号中,需要先进行心音区间的尺度变换,即将待分割定位心音信号的每个心音区间
为了更好地说明本发明的技术效果,采用一个具体实例对本发明进行实验验证。本次实验验证中的心音数据集来自三部分:
数据集1来自于“classifyingheartsoundspascalchallengecompetition”,该数据集包括数据集a和数据集b两部分。其中数据集a为通过istethoscopeproiphone应用程序从公众中提取的数据。数据集b为在巴西累西腓的realportugues医院(rhp)使用数字示波器收集系统采集的孕产妇和胎儿心脏病病房收集的200多个听诊病例组成(pereira等,2011),不具备一般性,因此只使用了该数据集得数据集a部分。该数据集得数据采样数据长度1s-30s不等,采样频率为44100hz,采样位数为16位,本次实验验证中选取其中31例正常心音信号和34例含杂音的心音信号。
数据集2来自于2016年physionet/cinc的心音挑战赛。该数据集的心音数据来自于9个独立的数据库,除去sufhsdb数据库的数据(来自于胎儿和母亲的心音),建立了8个独立的心音数据库。其中四个数据库以7比3的比例,被分为训练集与测试集,其余的四个数据库被专门分配为训练集或测试集。该数据集共包括从764例心脏录音/病人身上录取的3153段心音信号,持续时间从5s到120s不等,采样频率为2000hz。本次实验验证中主要选取了其中超过7s的116个正常心音和290个异常心音进行了处理。
数据集3来自于采用一款可穿戴心音监测平台自行采集的心音信号,图5是本实施例中自行采集心音信号示例图。根据图5可以看到,可穿戴心音监测平台所采集到的信号底噪更大,且容易发生s1和s2的混叠。本数据集共包括20段心音信号,持续时间都被裁剪为4s,采样频率为2000hz。
本实施例主要从抗噪鲁棒性和抗噪上限两个方面来进行实验验证。
·实验一:抗噪鲁棒性实验
首先对本发明的抗噪鲁棒性进行实验验证。噪声可分为白噪声、粉噪声、蓝噪声、肺音和运动伪迹五种。白噪声在全频段均匀分布;粉噪音为白噪声将高频声音的响度降低,将低频声音的响度提高;蓝色噪声则为低频声音变得更弱,高频声音变得更强;肺音属于人体的生理音,这类噪声的引入是由心音听诊这种采集方式所决定的,现实中听诊获得的心音,或者肺音信号是互为干扰,同时存在的,互相影响,所以听诊得到的心肺音信号在时域上是混叠的,这对听诊的准确性造成很大干扰;运动伪迹是由可穿戴心音监测装置与人体和皮肤之间的相对位移而引起的,噪音信号幅度大,且频谱与心音信号频谱部分重叠,难以滤波消除。为了体现本发明在抗噪鲁棒性方面的优势,采用2种算法作为对比方法,分别为vmd ewt(经验小波)算法和emd pca(主成分分析)算法,采用信噪比(snr)、相关系数和均方误差(mse)作为对于噪声的鲁棒性评估指标。
图6是本实施例中纯净心音信号叠加白噪声所得到的归一化心音信号波形图。图7是vmd ewt算法采用对图6所示心音信号进行处理后的归一化信号波形图。图8是采用emd pca算法对图5所示心音信号进行处理后的归一化信号波形图。图9是采用本发明中多小波 pca算法对图6所示心音信号进行处理后的归一化信号波形图。对比图6至图9可知,由于所叠加白噪音强度较大,较为纯净的心音信号已经几乎湮没在了高斯白噪声中,vmd ewt算法的去噪效果比较差,与原信号相比区别不大,emd pca算法甚至抑制了部分的有效信号并不能肉眼分辨s1和s2的位置,而本发明多小波 pca算法处理之后,第一心音s1和第二心音s2的位置已经相对明显了。
图10是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的信噪比比较图。图11是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的相关系数比较图。图12是本发明和两种对比方法在不同信噪比高斯白噪声下心音信号去噪后的均方误差比较图。如图10到图12可知,随着噪声信噪比snr的增大,三种方法一般符合以下规律:对源心音信号与去噪后心音信号的相关系数和均方误差的提升逐步增大。其中本发明和vmd ewt算法的效果总体要优于emd pca算法的效果,在噪声较高的时候,本发明和vmd ewt算法的效果差距不算很大,但是随着噪声的增多,本发明处理的结果就开始展现出他的优势,而且在全过程都能获得比较稳定的增益,说明本发明对高斯白噪声的变化更敏感,能获得更好的去噪效果。
图13是本发明和两种对比方法在不同信噪比粉噪声下心音信号去噪后的信噪比比较图。图14是本发明和两种对比方法在不同信噪粉噪声下心音信号去噪后的相关系数比较图。图15是本发明和两种对比方法在不同信噪比粉噪声下心音信号去噪后的均方误差比较图。如图13到图15可知,emd pca算法对粉噪声并不敏感,处理效果比较差,而本发明方法处理的效果要优于vmd ewt算法。
图16是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的信噪比比较图。图17是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的相关系数比较图。图18是本发明和两种对比方法在不同信噪比蓝噪声下心音信号去噪后的均方误差比较图。如图16到图18可知,添加了较多蓝噪声的情况下,在低噪的情况下,vmd ewt算法的性能略优一点,但是本发明整体处理效果最好。
图19是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的信噪比比较图。图20是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的相关系数比较图。图21是本发明和两种对比方法在不同信噪比肺音下心音信号去噪后的均方误差比较图。如图19到图21可知,添加了肺音的情况下,本发明整体处理效果优于两种对比方法。
图22是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的信噪比比较图。图23是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的相关系数比较图。图24是本发明和两种对比方法在不同信噪比运动伪迹下心音信号去噪后的均方误差比较图。如图22到图24可知,添加了运动伪迹的情况下,本发明处理效果与vmd ewt算法的处理效果相差不大,均优于emd pca算法的处理效果。
综上所述,本发明在不同噪声条件下对心音信号的去噪效果都较好。
·实验二:抗噪上限实验
在抗噪上限实验中,除了vmd ewt算法和emd pca算法外,还采用了s变换 香农能量包络算法和ewt 香农熵算法作为对比方法。表1是本发明和四种对比方法对于对单种噪声的抗噪上限数据表。
表1
从表1可以看出,本发明所提出的方法要明显优于其他几种对比方法,经测试,本发明方法能在各种噪声环境下实现带噪为-8db的信号中稳定地分割心音信号。
图25是采用本发明对图6所示心音信号进行处理后提取的香农包络结果图。图26是采用本发明对图6所示心音信号进行处理后的处理结果图。可以看到,在添加了较大噪声,信号已经严重失真的情况下本发明依旧能对心音信号进行稳定而准确的分割。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

