本发明涉及一种用于识别用户语音的方法及装置。更具体地,涉及用于识别从用户获取的语音的方法中的基于上下文的语音识别精度的方法及装置。
背景技术:
自动语音识别(以下称为语音识别)是一种使用计算机将语音转换为文本的技术。近年来,这种语音识别已经实现了识别率的快速提高。
然而,尽管识别率总体上有所提高,但是根据学习语言模型或声学模型时所使用的数据结构或模型结构,会出现性能差异。
技术实现要素:
要解决的技术问题
本发明是鉴于所述诸多问题而提出的,其目的在于,提供一种在使用多个语音识别模型进行语音识别的情况下从多个语音识别结果中选择高精度语音识别结果的方法。
另外,本发明的另一目的在于,提供一种选择用于使用上下文信息进行语音识别的语音识别模型的方法。
本发明中要实现的技术问题不限于上述技术问题,根据以下描述,本发明所属技术领域的普通技术人员将清楚地理解未提及的其他技术问题。
技术方案
为了实现所述目的,根据本发明的识别语音的方法,其中,包括:从用户获取语音信息的步骤;将获取的语音信息转换为语音数据的步骤;通过利用第一语音识别模型识别转换后的所述语音数据来产生第一语音识别结果的步骤;通过使用第二语音识别模型识别转换后的所述语音数据来产生第二语音识别结果的步骤;以及通过特定确定过程从所述第一语音识别结果及所述第二语音识别结果中选择特定的语音识别结果的步骤。
在本发明中,所述特定确定过程包括:从所述第一语音识别结果及所述第二语音识别结果中提取上下文信息的步骤;将所述上下文信息分别与预设的所述第一语音识别模型的第一特征及所述第二语音识别模型的第二特征进行比较的步骤;以及基于所述比较结果选择所述第一语音识别结果及所述第二语音识别结果中的一个的步骤。
在本发明中,上下文信息包括所述语音信息的一部分或从所述第一语音识别结果及所述第二语音识别结果获得的信息,或者与发出语音的用户有关的信息中的至少一个。
并且,在本发明中,所述第一语音识别模型及所述第二语音识别模型是用于识别从所述用户获得的所述语音信息的多个语音识别模型中的一个。
并且,在本发明中,进一步包括通过使用多个所述语音识别模型识别转换后的所述语音数据来生成多个语音识别结果的步骤,所述特定语音识别结果是所述第一语音识别结果,所述第二语音识别结果以及多个所述语音识别结果中选择的一种。
并且,在本发明中,所述特定确定过程是用于基于上下文信息中包括的上下文来确定语音识别结果的过程。
并且,本发明作为识别语音的方法,包括:从用户获取语音信息的步骤;将获取的语音信息转换为语音数据的步骤;通过利用所述第一语音识别模型识别所述语音数据来产生第一语音识别结果的步骤;基于所述第一语音识别结果,从多个语音识别模型中选择用于识别所述语音数据的第二语音识别模型的步骤;以及通过使用所述第二语音识别模型识别所述语音数据来生成第二语音识别结果的步骤。
并且,在本发明中,进一步包括:从所述第一语音识别结果中提取上下文信息的步骤;以及将所述上下文信息与多个所述语音识别模型的预设细节进行比较的步骤,根据所述比较结果选择所述第二语音识别模型。
并且,在本发明中,所述第一语音识别模型是用于提取所述上下文信息的语音识别模型。
并且,本发明作为识别语音的方法,包括:从用户获取语音信息的步骤;将获取的语音信息转换为语音数据的步骤;以及通过使用从多个语音识别模型中选择的特定语音识别模型识别所述语音数据来生成语音识别结果的步骤。
并且,本发明进一步包括:设置用于语音识别的上下文信息的步骤;以及从多个所述语音识别模型中选择语音识别模型的特征最适合于所述上下文信息的所述特定语音识别模型的步骤。
有益效果
根据本发明的一实施例,当在识别语音输入时使用多个语音识别模型生成多个结果时,通过选择食物识别模型的识别结果中的高精度来选择语音识别的准确性。
另外,通过选择根据上下文信息的语音识别模型,可以根据目的使用多个语音识别模型中的每一个。
此外,即使在针对大规模用户的服务中或在用户所处的物理及上下文环境不时变化的环境中,也可以选择适当的语音识别模型。
另外,因为可以选择适当的语音识别模型,因此可以减少由于使用大语言模型时可能出现的相似词汇而引起的误识别,并且减少了由于应用小语言时可能出现的未注册词汇而引起的误识别。
附图说明
作为详细描述的一部分而包括的附图以帮助理解本发明,附图提供了本发明的实施例,并且与详细描述一起将是本发明的技术特征。
图1是根据本发明实施例的语音识别装置的框图。
图2及图3是示出根据本发明的实施例的语音识别装置的示例的图。
图4及图5是示出根据本发明的实施例的语音识别装置的另一示例的图。
图6是示出根据本发明的实施例的语音识别装置的另一示例的图。
图7是示出根据本发明的实施例的语音识别方法的示例的流程图。
图8是示出根据本发明的实施例的语音识别方法的另一示例的流程图。
图9是示出根据本发明的实施例的语音识别方法的另一示例的流程图。
具体实施方式
在下文中,将参考附图详细描述本发明的优选实施例。下面将与附图一起公开的详细描述旨在描述本发明的示例性实施例,而并非旨在表示可以实践本发明的唯一实施例。以下详细描述包括特定细节以提供对本发明的透彻理解。然而,本领域技术人员知道,可以在没有这些具体细节的情况下实施本发明。
在某些情况下,为了避免使本发明的概念模糊,可以省略公知的结构及装置,或者可以以每个结构及装置的核心功能为中心的框图形式示出。
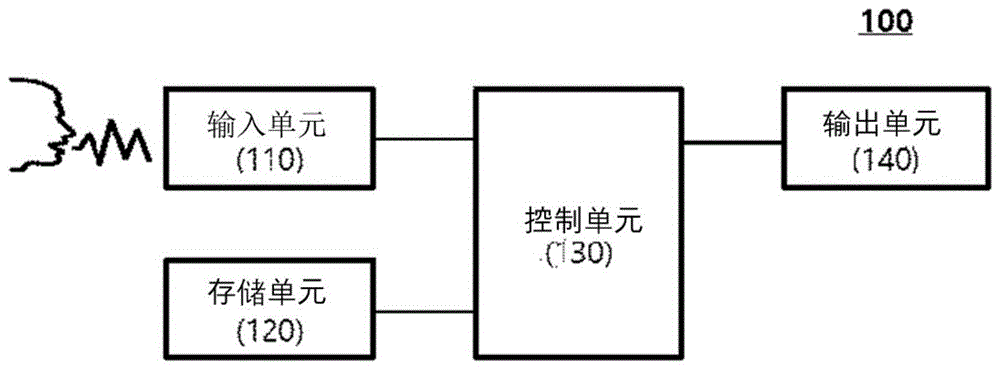
图1是根据本发明实施例的语音识别装置的框图。
参照图1,用于识别用户语音的语音识别装置100包括输入单元110,存储单元120,控制单元130及/或输出单元140等。
由于图1所示的组件不是必需的,因此可以实现具有更多组件或更少组件的电子装置。
在下文中,将按顺序描述上述组件。
输入单元110可以接收音频信号,视频信号或从用户接收语音信息(或音频信号)及数据。
输入单元110可以包括照相机及麦克风,以接收音频信号或视频信号。照相机在视频通话模式或拍摄模式下处理图像传感器获取的图像帧,例如静止图像或运动图像。
由照相机处理的图像帧可以被存储在存储单元120中。
麦克风在通话模式,录音模式或语音识别模式下从麦克风接收外部声音信号,并将其作为电子语音数据进行处理。可以在麦克风中实现各种噪声去除算法以去除在接收外部声音信号的过程中产生的噪声。
当通过麦克风或麦克风输入用户说出的语音时,输入单元110将语音转换为电信号并将其发送到控制单元130。
控制单元130可以通过对从输入单元110接收的信号应用语音识别算法或语音识别引擎来获得用户的语音数据。
此时,可以将输入到控制单元130的信号转换为用于语音识别的更有用的形式,并且控制单元130将输入信号从模拟形式转换为数字形式,并且检测信号的起点及终点,可以检测语音数据中包括的实际语音部分/数据。这称为epd(端点检测)。
并且,在检测到的间隔倒谱(cepstrum),线性预测编码(linearpredictivecoefficient:lpc),梅尔频率倒谱系数(mfcc)或滤波器组能量内的控制单元130可以通过应用特征矢量提取技术来提取信号的特征矢量。
存储单元120可以存储用于控制单元130的操作的程序,并且可以临时存储输入/输出数据。可以从用户保存基于符号的恶意代码检测模型的样本文件,并且可以保存恶意代码的分析结果。
存储单元120可以存储与所识别的语音有关的各种数据,尤其,可以存储与由控制单元130处理的语音数据的端点有关的信息及特征向量。
存储单元120包括闪存,硬盘,存储卡,rom(只读存储单元),ram(随机存取存储单元),存储卡,电可擦除可编程只读存储单元(eeprom),可编程只读存储单元(prom),磁存储单元,磁盘及光盘中的至少一个。
另外,控制单元130可以通过将提取的特征向量与训练的参考图案进行比较来获得识别结果。为此,可以使用用于对语音的信号特性进行建模及比较的语音识别模型,以及用于对如与所识别的词汇相对应的单词或音节的语言顺序关系进行建模的语言模型。
语音识别模型可以分为将识别对象设置为特征向量模型并将其与语音数据的特征向量进行比较的直接比较方法,以及将识别对象的特征向量进行统计的统计方法。
直接比较方法是一种将如单词及音素之类的单位设置为特征向量模型并比较输入语音与此相似程度的方法,并且代表性地,有一种矢量量化方法。根据矢量量化方法,将输入语音数据的特征矢量与作为参考模型的码本进行映射,并作为代表值进行编码,从而将码值彼此进行比较。
统计模型方法是一种将识别对象的单元配置为状态序列并利用状态序列之间的关系的方法。状态序列可以由多个节点组成。使用状态序列之间的关系的方法包括动态时间规整(dtw),隐马尔可夫模型(hmm)及使用神经网络的方法。
动态时间规整是一种通过与参考模型相比来补偿时间轴差异的方法,该方法通过考虑即使同一人发出相同发音时信号长度随时间变化的语音的动态特性,隐马尔可夫模型假设语音是具有状态转移概率及每个状态中的节点(输出符号)的观察概率的马尔可夫过程,然后通过训练数据估计状态转移概率及节点的观察概率,可以根据估计的模型计算生成输入语音的可能性的一种识别技术。
另一方面,对如单词或音节之类的语言顺序关系建模的语言模型可以通过将构成语言的单元之间的顺序关系应用于从语音识别获得的单元来减少声学歧义并减少识别错误。语言模型包括统计语言模型及基于有限状态自动机(fsa)的模型,统计语言模型使用单词的链概率,例如unigram,bigram及trigram。
控制单元130可以在识别语音中使用任何上述方法。例如,可以使用应用了隐马尔可夫模型的语音识别模型,或者可以使用其中集成了语音识别模型及语言模型的n最佳搜索方法。n最佳搜索方法可以通过使用语音识别模型及语言模型选择最多n个识别结果候选者,然后重新评估这些候选者的排名来提高识别性能。
控制单元130可以计算置信度分数(或者可以缩写为“置信度”)以确保识别结果的可靠性。
可靠性分数是该结果对语音识别结果的可靠性的度量,可以定义为语音是从作为识别结果的音素或单词,还是从另一个音素或单词发出语音的概率的相对值有。因此,可靠性得分可以表示为介于0及1之间或介于0及100之间的值。若可靠性得分大于预设阈值,则识别识别结果,而若可靠性得分小,则可以拒绝识别结果。
除此之外,可以根据各种现有的可靠性得分获取算法来获得可靠性得分。
控制单元130可以使用软件,硬件或其组合在计算机可读记录介质中实现。根据硬件实现,专用集成电路(asic),数字信号处理器(dsp),数字信号处理装置(dspd),可编程逻辑装置(pld),现场可编程门阵列(fpga),处理器及微控制单元及微处理器之类的电气单元中的至少一个来实现。
根据该软件实现可以与执行至少一个功能或操作的单独的软件模块一起实现,并且该软件代码可以由以适当的编程语言编写的软件应用来实现。
控制单元130实现后述的图2至图6中提出的功能,处理及/或方法,并且在下文中,为了便于说明,控制单元130与语音识别装置100相同并且进行了描述。
输出单元140用于生成与视觉,听觉等有关的输出,并且输出由装置100处理的信息。
例如,输出单元140可以输出由控制单元130处理的语音信号的识别结果,从而用户可以通过视觉或听觉功能来识别。
以下描述的语音识别模型可以通过与图1中描述的语音识别模型相同的方法来识别从用户输入的语音信息。
图2及图3是示出根据本发明的实施例的语音识别装置的示例的图。
参照图2及图3,语音识别装置将从用户获取的语音数据识别为多个语音识别模型,并且基于上下文信息从多个语音识别模型中选择识别结果之一以提供语音识别服务。
具体地,语音识别装置可以通过将从用户输入的语音信息转换为电信号,并且将作为转换后的电信号的模拟信号转换为数字信号来生成语音数据。
然后,语音识别模型可以分别使用第一语音识别模型(2010)及第二语音识别模型(2020)来识别语音数据。
语音识别装置使用基本语音识别模型和用户的语音识别模型中的每一个,从用户输入的语音信号转换而来的语音数据中获取两个语音识别结果(语音识别结果1(2030),语音识别结果2(2040))
语音识别装置将所述第一语音识别结果及所述第二语音识别结果应用于第一特定确定过程(例如,基于第一上下文的适当语音识别模型确定技术)从第一语音识别结果和第二语音识别结果中选择并输出更合适的语音识别结果(2050)。
即,语音识别装置可以通过第一特定确定过程从第一语音识别结果及第二语音识别结果中选择更适合于语音识别目的的语音识别结果,并且可以输出选择的语音识别结果。
例如,当从第一语音识别结果及第二语音识别结果中提取的上下文信息与地址搜索有关时,在第一语音识别结果及第二语音识别模型中选择更适合于地址搜索的语音识别模型,并提供所选语音识别模型的语音识别结果作为语音识别服务。
在下文中,将参照图3描述具体的确定过程。
图3是示出用于基于基于第一语音识别结果及第二语音识别结果的上下文来确定适当的语音识别模型的第一特定确定过程的示例的流程图。
如图3所示,当分别根据第一语音识别模型及第二语音识别模型生成第一语音识别结果3010及第二语音识别结果3020时,第一特定确定过程基于从第一语音识别结果3010及第二语音识别结果3020中提取的上下文3032,在第一语音识别结果3010及第二语音识别结果3020中选择更合适语音识别的目的的语音识别模型(3034)。
然后,语音识别装置选择(3036)并输出(3040)从所选择的语音识别模型生成的语音识别结果。
例如,在图3中,第一语音识别的结果“告诉我李基同的地址”及第二语音识别结果“告诉我李吉东的地址”中,语音识别装置确定“告诉我地址”为上下文信息。
具体地,语音识别装置可以从“告诉我李基同的地址”及“告诉我李吉东的地址”中提取上下文信息“告诉我地址”(3032)。
然后,语音识别装置将提取的上下文信息与第一语音识别模型的特征(第一特征)及第二语音识别模型的特征(第二特征)进行比较,可以选择第一语音识别模型作为更适合于语音识别目的的语音识别模型(3034)。
然后,语音识别装置可以选择所选择的第一语音识别模型的第一语音识别结果(3036),并且可以输出所选择的第一语音识别结果“告诉我李基同的地址”。
在这种情况下,除了从语音数据中识别出的被识别句子的一部分作为上下文信息之外,可以通过识别结果推断出的所有信息都可以用作上下文信息。
例如,与用户相关的信息,例如用户的位置,用户的天气,用户的习惯,用户的前言背景,用户的职业,用户的位置,用户的财务状况,当前时间及用户的语言等中至少其中之一可用作上下文信息。
图4及图5是示出根据本发明的实施例的语音识别装置的另一示例的图。
参照图4及图5,语音识别装置将从用户获得的语音数据识别为多个语音识别模型,并基于上下文信息从多个语音识别模型中选择识别结果之一提供语音识别服务。
具体地,语音识别装置可以通过将从用户输入的语音信息识别为第一语音识别模型4010来生成第一语音识别结果(4020)。
在这种情况下,第一语音识别模型是用于从用户获得的语音信息中提取上下文的语音信息模型,并且可以被配置为根据语音信息的目的根据语音信息模型的目的仅使用小的资源。
语音识别装置使用第二特定确定过程(例如,第二上下文的适当语音识别模型确定技术),可以从多个预设的语音识别模型中选择最适合于识别从用户输入的语音信息的特定语音识别模型(4030)。
即,语音识别装置可以根据语音识别的目的及用途,基于第一语音识别结果从多个语音识别模型中选择特定的语音识别模型。
例如,当从第一语音识别结果提取的上下文信息与地址搜索有关时,可以在多个候选语音识别模型中选择最适合地址搜索的语音识别模型作为特定语音识别模型。
在这种情况下,第二特定确定过程包括从第一语音识别结果中提取上下文信息以便选择特定语音识别模型,并使用所提取的上下文信息来选择特定语音识别模型的过程。
然后,语音识别过程可以使用所选的特定语音识别模型重新识别从用户输入的语音信息所转换而来的语音数据,并最终生成语音识别结果(4040)。
在下文中,将参照图5描述第二特定确定过程。
图5是示出用于基于第一语音识别结果及第二语音识别结果的上下文来确定适当的语音识别模型的第二特定确定过程的示例的流程图。
具体地,语音识别装置生成(或接收输入)通过图4中描述的第一语音识别模型识别用户的语音信息的第一语音识别结果5010,基于生成的第一语音识别结果,通过第二特定确定过程从多个(例如,n个)语音识别模型中选择最适合语音识别目的的特定语音识别模型(5020)。
在这种情况下,第二特定确定过程包括从第一语音识别结果中提取上下文信息以便选择特定语音识别模型,并使用所提取的上下文信息来选择特定语音识别模型的过程。
例如,可以从通过第一语音识别模型识别出的第一语音识别结果中,提取“告诉我李吉东的地址”,“告诉我地址”作为上下文信息。
在这种情况下,第一语音识别模型是如上所述的用于从用户获得的语音信息中提取上下文的语音信息模型,并且根据语音识别的目的配置为仅根据语音信息模型的目的使用少量资源。
关于上下文信息,除了通过语音识别模型识别出的句子的一部分之外,可以将通过识别结果推断出的所有信息用作上下文信息。
例如,与用户有关的信息,例如用户的位置,用户所处的天气,用户的习惯,用户的先前话语上下文,用户的职业,用户的职责,用户的财务状况,当前时间及用户的语言等中至少其中之一可用作上下文信息。
然后,语音识别装置可以通过使用提取的上下文信息“告诉我地址”,从多个语音识别模型中选择最适合语音识别目的的特定语音识别模型。
通过该方法,语音识别装置可以通过用于获取上下文信息的语音识别模型提取上下文信息,从而选择最适合语音识别目的的特定语音识别模型。
图6是示出根据本发明的实施例的语音识别装置的另一示例的图。
参考图6,语音识别装置可以通过设置用于语音识别的上下文信息来预先从多个语音识别模型中选择特定的语音识别模型,并且使用通过所选语音识别模型识别的语音识别结果提供语音识别服务。
具体地,语音识别装置可以根据预设的上下文信息从多个语音识别模型中选择被确定为最适合语音识别的特定语音识别模型(6010)。
例如,当语音识别服务的目的及用途是地址搜索时,语音识别装置可以在多个语音识别模型中选择预设用于地址搜索的语音识别模型作为特定语音识别模型。
然后,语音识别模型通过识别通过选择的特定食物模型从用户获取的语音数据来生成语音识别结果(6020)。
在这种情况下,语音数据是指将从用户获得的语音信息改变为电信号,并且将作为改变后的电信号的模拟信号改变为数字信号的数据。
图7是示出根据本发明的实施例的语音识别方法的示例的流程图。
参考图7,如图2及图3所示,语音识别装置通过多个语音识别装置生成语音识别结果,并从所生成的语音识别结果中选择最合适的语音识别结果提供语音识别服务。
具体地,语音识别装置可以从用户获取语音信息,并将获得的语音信息转换为语音数据(s7010)。
例如,语音识别装置可以将从用户获取的语音信息转换为电信号,并且将作为改变后的电信号的模拟信号转换为作为数字信号的语音数据。
然后,语音识别装置可以将语音数据分别识别为第一语音识别模型及第二语音识别模型,以生成第一语音识别结果及第二语音识别结果(s7020及s7030)。
然后,语音识别装置通过图2及图3所述的第一特定确定过程从第一语音识别结果及第二语音识别结果中选择更适合语音识别目的的语音识别结果,从而提供语音识别服务(s7040)。
例如,语音识别装置从第一语音识别结果及第二语音识别结果中提取上下文信息,将提取的上下文信息分别与预设的第一语音识别模型的第一特征及第二语音识别模型的第二特征进行比较。
然后,语音识别装置可以基于所述比较结果从所述第一语音识别模型及第二语音识别模型中选择适合于语音识别的目的及/或目的的语音识别模型。
然后,语音识别装置可以选择由选择的第二语音识别模型生成的第二语音识别结果作为语音识别结果,并且基于所选的第二语音识别结果提供语音识别服务。
图8是示出根据本发明的实施例的语音识别方法的另一示例的流程图。
参照图8,语音识别模型可以通过语音数据提取上下文信息,并且基于所提取的上下文信息来提供语音识别服务。
首先,步骤s8010与图7的步骤s7010相同,因此将省略其描述。
然后,语音识别装置通过使用第一语音识别模型识别语音数据来生成第一语音识别结果(s8020)。
此时,第一语音识别模型是如图4所示的用于从用户获得的语音信息中提取上下文的语音信息模型,根据语音识别的目的配置为仅根据语音信息模型的目的使用少量资源。
语音识别装置可以从第一语音识别结果中提取上下文信息(s8030)。
上下文信息指的是除了通过语音识别模型识别的句子的一部分以外,还可以是通过识别结果等推断出的所有信息。
例如,与用户有关的信息,例如用户的位置,用户所处的天气,用户习惯,用户的先前讲话的上下文,用户的职业,用户的职责,用户的财务状况,当前时间及用户的语言等中至少其中之一可用作上下文信息。
然后,语音识别装置可以使用图4及图5中描述的第二特定确定过程从多个预设语音识别模型中选择最适合识别从用户输入的语音信息的特定语音识别模型(s8040)。
即,语音识别装置可以根据语音识别的目的及用途,基于第一语音识别结果从多个语音识别模型中选择特定的语音识别模型。
例如,当从第一语音识别结果提取的上下文信息与地址搜索有关时,可以在多个候选语音识别模型中选择最适合地址搜索的语音识别模型作为特定食物识别模型。
在这种情况下,第二特定确定过程包括从第一语音识别结果中提取上下文信息以便选择特定语音识别模型,并使用所提取的上下文信息来选择特定语音识别模型的过程。
然后,在语音识别过程中,使用选择的特定语音识别模型,重新识别从用户输入的语音信息转换的语音数据,以最终生成语音识别结果(s8040)。
然后,语音识别装置可以基于通过特定语音识别模型识别语音数据的语音识别结果来提供语音识别服务。
图9是示出根据本发明的实施例的语音识别方法的另一示例的流程图。
参照图9,语音识别装置可以在从用户接收语音信息之前基于上下文信息从多个语音识别模型中选择特定的语音识别模型,并且识别通过所选择的语音识别模型从用户输入的语音信息。
具体地,语音识别装置可以预设用于语音识别的上下文信息。
上下文信息指的是除了通过语音识别模型识别的句子的一部分以外,还可以通过识别结果等推断出的所有信息。
例如,与用户相关的信息,例如用户的位置,用户所处的天气,用户的习惯,用户的先前话语上下文,用户的职业,用户的职责,用户的财务状况,当前时间及用户的语言等中至少其中之一可用作上下文信息。
然后,语音识别装置基于上下文信息从多个语音识别模型中根据语音识别的目的/用途选择特定语音识别模型(s9020)。
例如,在地址搜索的情况下,语音识别装置可以在多个语音识别模型中选择预设用于地址搜索的语音识别模型作为特定语音识别模型。
然后,当从用户获得语音信息时,语音识别装置可以将获得的语音信息转换为语音数据(s9010)。
例如,语音识别装置可以将从用户获取的语音信息转换为电信号,并且将作为改变后的电信号的模拟信号转换为作为数字信号的语音数据。
然后,语音识别装置可以通过使用所选择的特定语音识别模型来识别语音数据来生成语音识别结果(s9050)。
然后,语音识别装置可以基于通过特定语音识别模型识别语音数据的语音识别结果来提供语音识别服务。
根据本发明的实施例是多种手段,例如,可以通过硬件,固件,软件或其组合来实现。在通过硬件实现的情况下,本发明的实施例是一个或多个asic(专用集成电路),dsp(数字信号处理器),dspd(数字信号处理装置),pld(可编程逻辑装置),fpga(现场可编程门阵列),处理器,控制单元,微控制单元,微处理器等。
在通过固件或软件来实现的情况下,本发明的实施例以执行上述功能或操作的模块,过程,功能等的形式实现。可以将软件代码存储在存储器中并由处理器驱动。所述存储器位于所述处理器内部或外部,并且可以通过各种已知方式与所述处理器交换数据。
对于本领域技术人员显而易见的是,在不脱离本发明的基本特征的情况下,可以以其他特定形式来实施本发明。因此,以上详细描述不应在所有方面解释为限制性的,而应被认为是说明性的。本发明的范围应该由所附权利要求的合理解释来确定,并且在本发明的等同范围内的所有改变都包括在本发明的范围内。
产业上的利用可能性
本发明可以应用于语音识别技术的各个领域,并且本发明可以提供一种用于基于上下文选择最佳语音识别模型的方法。
由于这些特性,当使用针对每个字段具有不同强度的多个语音识别模型从服务接收到未指定的语音输入时,有可能获得最佳的语音识别结果。
这些功能不仅可以应用于语音识别,还可以应用于其他ai服务。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

