本申请涉及语言识别
技术领域:
,具体涉及一种低资源客家方言点识别方法。
背景技术:
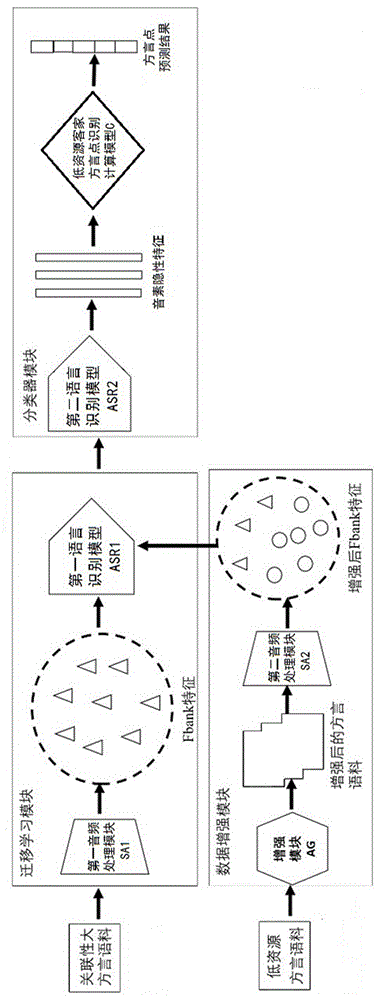
:客家方言又称客家话、客家语,流通于广东、广西等地区,以梅县话为代表。客家方言主要通行于广东东部和北部、广西南部、福建西部、江西南部、台湾、四川和湖南部分地区,是一种特殊的语言变体,具有珍贵的史学及语言学研究价值。基于“方言保护计划”,2018年科大讯飞面向全球首次开放珍贵的10种方言语料库,包括宁夏话、合肥话、四川话等,覆盖了我国的大部分地区的方言语音和音素语料库,聚焦方言种类识别问题,共同推进关于方言的算法研究和保护传承。但是目前客家方言语料资源匮乏,因此有效利用有限资源提高方言点识别准确率具有重要意义。技术实现要素:本发明的目的在于:提供一种低资源客家方言点识别方法,利用迁移学习策略,在源端训练一个相对较大的方言语音识别模型,然后对目标端低资源客家方言语音识别模型进行微调,利用中间语义向量进行客家方言识别,有效提取出客家方言音素隐性特征,从而提高客家方言点识别准确率。本发明采取的技术方案是:一种低资源客家方言点识别方法,包括如下步骤:步骤100:采集大方言语音资料,建立关联性大方言语料库;采集低资源客家方言语音资料,建立低资源客家方言语料库;步骤200:对所述关联性大方言语料库中的方言语音通过迁移学习模块进行处理,所述迁移学习模块包括第一音频处理模块和第一语音识别模型;先通过第一音频处理模块将大方言音频转化为大方言的fbank特征,再将所述大方言的fbank特征作为输入,训练第一语音识别模型并对所述大方言的fbank特征进行处理,获取所述大方言的fbank特征的大方言音素和大方言音素隐性特征;步骤300:对低资源客家方言语料库中的方言语音通过数据增强模块进行处理,所述数据增强模块包括增强模块和第二音频处理模块;通过增强模块对低资源客家方言语料库中的方言语音进行增强,将增强后的方言语音通过第二音频处理模块将增强后的方言语音转化为增强后的fbank特征,再将所述增强后的fbank特征作为输入,在步骤200训练好的第一语音识别模型的基础上,训练第二语音识别模型并对所述增强后的fbank特征进行处理,获取所述增强后的fbank特征的客家方言音素和客家方言音素隐性特征;步骤400:将步骤300中客家方言音素隐性特征作为输入建立低资源客家方言点识别计算模型,得到低资源客家方言点预测结果。进一步地,步骤200中的第一语音识别模型包括编码器、解码器和ctc损失函数,所述第一语音识别模型的训练方法包括:步骤201:编码器将大方言音频的fbank特征编码成大方言的音素隐性特征;所述编码器的编码过程包括将大方言音频的fbank特征经过残差cnn网络模型处理得到有效帧和经过多头注意力网络模型得到有效帧之间相关的注意力信息;步骤202:解码器将大方言的音素隐性特征解码成大方言音素;解码器的解码过程包括通过linear全连接层和softmax激活函数将编码器的输出解码成大方言音素;步骤203:将大方言音频对应的文本内容制作成大方言文本标签,和所述大方言音素作为输入代入ctc损失函数中进行迭代训练,并采用交叉熵作为目标函数,通过随机梯度下降法对所述目标函数进行优化,得到性能稳定的第一语音识别模型。进一步地,步骤300中对低资源客家方言语料库中的方言语音进行增强处理的方法包括时间延长、高音转换和添加噪声;时间延长的具体方法为放慢或加快音频采样,同时保持音频音高不变;音高转换的具体方法为提高或降低音频样本的音高,同时保持音频时长不变;添加噪声的具体方法为在音频中随机添加高斯噪声。进一步地,步骤300中第二语音识别模型包括编码器、解码器和ctc损失函数,所述第二语音识别模型的训练方法包括:步骤301:编码器将增强后的fbank特征编码成客家方言的音素隐性特征;所述编码器的编码过程包括将增强后的fbank特征经过残差cnn网络模型处理得到有效帧和经过多头注意力网络模型得到有效帧之间相关的注意力信息;步骤302:解码器将客家方言的音素隐性特征解码成客家方言音素;解码器的解码过程包括通过linear全连接层和softmax激活函数将编码器的输出解码成客家方言音素;步骤303:将客家方言音频对应的文本内容制作成客家方言文本标签,和所述客家方言音素作为输入代入ctc损失函数中进行迭代训练,并采用交叉熵作为目标函数,通过随机梯度下降法对所述目标函数进行优化,得到性能稳定的第二语音识别模型。进一步地,所述残差cnn网络模型包括一个卷积层conv1子模块、一个最大池化层maxpool子模块、四个子残差cnn模块和一个mean函数模块。进一步地,所述多头注意力网络模型的具体表达式为:其中,k为键向量,q为查询向量,v为值向量,dk为一个q和k向量的维度,kt为键向量的转置向量。进一步地,所述目标函数的具体公式为:h0=-yclog[p(yc=1)]-(1-yc)log[1-p(yc=1)]其中,θ是参数集,m代表训练实例的个数,j(θ)为目标函数,h0为交叉熵值,q为调和参数,yc为分类标签,p(yc=1)为分类标签为1时的概率,trainset为训练集。进一步地,所述低资源客家方言点识别计算模型为一个分类器模型,包括bilstm模块、两个linear模块和softmax模块;所述客家方言音素隐性特征依次经过bilstm模块、两个linear模块和softmax模块处理,再通过交叉熵目标函数和adam算法进行优化,得到低资源客家方言点预测结果。本发明的有益技术效果在于:既可将输入的客家方言音频识别并转录成音素级别的文本句子,也可针对输入的方言语音所属的方言点进行识别。针对低资源客家方言数据量较少的情况,通过迁移学习模块和数据增强模块,有效提取出客家方言音素隐性特征,训练出准确率较好的低资源客家方言识别计算模型,便于后期为进行方言自动回复,聊天等任务提供更准确的指导信息。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。图1为本发明实施例的客家方言识别框架示意图。图2为本发明实施例第一语音识别模型和第二语音识别模型的结构示意图。图3为本发明实施例客家方言点识别计算模型结构示意图。具体实施方式为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明并不限于下面公开的具体实施例的限制。除非另作定义,此处使用的技术术语或者科学术语应当为本申请所述领域内具有一般技能的人士所理解的通常意义。本专利申请说明书以及权利要求书中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”或者“一”等类似词语也不表示数量限制,而是表示存在至少一个。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也相应地改变。如图1~图3所示,一种低资源客家方言点识别方法,包括如下步骤:步骤100:采集大方言语音资料,建立关联性大方言语料库;采集低资源客家方言语音资料,建立低资源客家方言语料库;步骤200:对所述关联性大方言语料库中的方言语音通过迁移学习模块进行处理,所述迁移学习模块包括第一音频处理模块sa1和第一语音识别模型asr1;先通过第一音频处理模块sa1将大方言音频转化为大方言的fbank特征,再将所述大方言的fbank特征作为输入,训练第一语音识别模型asr1并对所述大方言的fbank特征进行处理,获取所述大方言的fbank特征的大方言音素和大方言音素隐性特征;步骤300:对低资源客家方言语料库中的方言语音通过数据增强模块进行处理,所述数据增强模块包括增强模块ag和第二音频处理模块sa2;通过增强模块ag对低资源客家方言语料库中的方言语音进行增强,将增强后的方言语音通过第二音频处理模块sa2将增强后的方言语音转化为增强后的fbank特征,再将所述增强后的fbank特征作为输入,在步骤200训练好的第一语音识别模型asr1的基础上,训练第二语音识别模型asr2并对所述增强后的fbank特征进行处理,获取所述增强后的fbank特征的客家方言音素和客家方言音素隐性特征;步骤400:将步骤300中客家方言音素隐性特征作为输入建立低资源客家方言点识别计算模型c,得到低资源客家方言点预测结果。在本发明实施例中,所述大方言语音资料来自于2018年科大讯飞面向全球首次开放珍贵的10种方言语料库,包括宁夏话、合肥话、四川话、宁夏话、长沙话、河北话、南昌话、上海话、客家话和闽南话,覆盖了我国的大部分地区的方言语音和音素,是目前为止公开发布的最大方言语音和音素语料库,以此作为迁移学习的相关大方言语料,用来训练第一语音识别模型asr1。所述低资源客家方言语音资料采集于乡音苑网站,覆盖了昌靖片、赣州片、海陆片、粤台片和粤西片这五个片区,涵盖了新闻、诗歌、故事三大主题。表1为本发明实施例建立低资源客家方言语料库时的要求,表2为本发明实施例采集到的低资源客家方言数据集信息表,表2中采集到的低资源客家方言数据与科大讯飞公开的客家话数据均不相同。表1低资源客家方言语料库建立要求表2客家方言数据集信息表如图2所示,步骤200中的第一语音识别模型asr1包括编码器、解码器和ctc损失函数,所述第一语音识别模型asr1的训练方法包括:步骤201:编码器将大方言音频的fbank特征编码成大方言的音素隐性特征;所述编码器的编码过程包括将大方言音频的fbank特征经过残差cnn网络模型处理得到有效帧和经过多头注意力网络模型得到有效帧之间相关的注意力信息;所述残差cnn网络模型包括一个卷积层conv1子模块、一个最大池化层maxpool子模块、四个子残差cnn模块和一个mean函数模块;所述多头注意力网络模型的具体表达式为:其中,k为键向量,q为查询向量,v为值向量,dk为一个q和k向量的维度,kt为键向量的转置向量。步骤202:解码器将大方言的音素隐性特征解码成大方言音素;解码器的解码过程包括通过linear全连接层和softmax激活函数将编码器的输出解码成大方言音素。步骤203:将大方言音频对应的文本内容制作成大方言文本标签,和所述大方言音素作为输入代入ctc损失函数中进行迭代训练,并采用交叉熵作为目标函数,通过随机梯度下降法对所述目标函数进行优化,得到性能稳定的第一语音识别模型asr1。采用ctc损失函数对所述大方言音素和所述大方言文本标签进行处理,无需进行数据对齐,省略了对齐语音的数据迭代过程。所述目标函数的具体公式为:h0=-yclog[p(yc=1)]-(1-yc)log[1-p(yc=1)](3)其中,θ是参数集,m代表训练实例的个数,j(θ)为目标函数,h0为交叉熵值,q为调和参数,yc为分类标签,p(yc=1)为分类标签为1时的概率,trainset为训练集。采用交叉熵作为目标函数,通过随机梯度下降法对所述目标函数进行优化,得到性能稳定的第一语音识别模型asr1。表3为科大讯飞公开的10种方言数据集信息表,分别建立10种方言的训练集和开发集。训练集用于训练模型,开发集用于测试模型性能,保障训练模型和测试模型性能过程中不会用到相同的语料,使训练结果更加公平可靠。表3科大讯飞数据集信息表本发明实施例通过词错率wer来评判模型训练准确度,所述词错率wer的具体计算公式为:其中,s表示被替换的音素,d表示被删除的音素,i表示被插入的音素,n表示所有的音素。经计算,本发明实施例第一语音识别模型asr1的词错率wer为0.3912%。表3为本发明实施例收集到的低资源客家方言数据集信息表,针对数据量小的客家方言语料,本发明实施例通过增强模块ag对低资源客家方言语料库中的方言语音进行增强处理,可获得数量为原始数量12倍的增强语音数据。增强处理的方法包括时间延长、高音转换和添加噪声。时间延长的具体方法为放慢或加快音频采样,同时保持音频音高不变,本发明实施例使用python音频处理库librosa中librosa.effects.time_stretch()函数,将音频的播放速度变为0.9~1.1倍进行采样。音高转换的具体方法为提高或降低音频样本的音高,同时保持音频时长不变,本发明实施例使用python音频处理库librosa中librosa.effects.pitch_shift()函数将每个样本的音高偏移了八个值,每个值以半音为单位。添加噪声的具体方法为在音频中随机添加高斯噪声,本发明实施例使用工具python数值计算扩展库numpy中np.random.normal()函数添加四次随机高斯噪声,所述高斯噪声的正态分布的均值=0,正态分布的标准差=1。步骤300中第二语音识别模型asr2与第一语音识别模型asr1的结构相同,包括编码器、解码器和ctc损失函数,所述第二语音识别模型asr2是在第一语音识别模型asr1参数的基础上,使用低资源客家方言语料库的语料训练得到的,所述第二语音识别模型asr2的训练方法包括:步骤301:编码器将增强后的fbank特征编码成客家方言的音素隐性特征;所述编码器的编码过程包括将增强后的fbank特征经过残差cnn网络模型处理得到有效帧和经过多头注意力网络模型得到有效帧之间相关的注意力信息;步骤302:解码器将客家方言的音素隐性特征解码成客家方言音素;解码器的解码过程包括通过linear全连接层和softmax激活函数将编码器的输出解码成客家方言音素;步骤303:将客家方言音频对应的文本内容制作成客家方言文本标签,和所述客家方言音素作为输入代入ctc损失函数中进行迭代训练,并采用交叉熵作为目标函数,通过随机梯度下降法对所述目标函数进行优化,得到性能稳定的第二语音识别模型asr2。为了便于直观展示数据在模型内的计算过程,这里以两条低资源客家方言语音数据为例进行计算:首先,在python中将低资源客家方言语料库中的语料对应的文本内容定义成一个set集合,记为all_txt。接着对all_txt进行去重操作,去掉重复的音素,并记为norepeat_txt。对norepeat_txt中的音素进行编号,形成低资源客家方言音素字典。将两条低资源客家方言语音数据分别记为wav1和wav2,查找所述低资源客家方言音素字典,用所述低资源客家方言音素字典中的编号表示wav1和wav2的文本内容,得到wav1的文本标签为[2,5,3,6,9,10]、wav2的文本标签为[12,7,30,66,98,110]。使用音频处理工具sox将wav1和wav2的量化位数设置为16,采样率设置为16000,通道数设置为1,再使用kaldi工具包提取出80维的fbank特征。此时wav1、wav2变成第二语音识别模型asr2所需要的输入,形状分别为(300,80),(500,80)。其中第一维度代表帧数,第二维度代表每帧的向量大小。考虑到训练效率,输入到模型的语音特征个数往往不是单个,而是多个合并在一起组成一个批次batch输入到模型进行训练。因为batch里面每个元素的各个维度需要保持一致才能有效训练,因此在合并的过程中需以batch里帧数最大的语音作为基准,没有达到基准的语音通过补零来达到,因为补零不会影响模型的训练。本发明实施例中最大帧数为500,即基准帧数为500,而帧数为300的语音还需要200帧数据才能达到基准帧数,所以需要进行补零,再将wav1和wav2形状合并为(2,500,80)。由于残差cnn网络模型需要4个维度的输入,故使用unsqueeze()函数将(2,500,80)转换至(2,1,500,80)。至此,输入信号处理完毕,记为asr_input。如图2所示,输入信号asr_input先经过残差cnn网络模型处理,表4为第二语音识别模型asr2的残差cnn网络模型结构表,表5为第二语音识别模型asr2的残差cnn网络模型参数表。表4第二语音识别模型asr2的残差cnn网络模型结构表表5第二语音识别模型asr2的残差cnn网络模型参数表层数(layer)卷积核(kernel_size)步长(stride)填充(padding)conv17(2,2)3maxpool3(2,2)1res13(1,2)1res23(1,2)1res33(1,2)1res43(1,2)1输入信号asr_input(2,1,500,80)首先经过卷积层conv1子模块,形状转换至(2,64,250,40);接着经过最大池化层maxpool子模块,形状转换至(2,64,125,20);接着经过第一个子残差cnn模块res1,此时形状转换至(2,64,125,10),这里的残差是调用pytorch中的basicblock接口,本发明实施例的第一个子残差cnn模块res1是由2个basicblock模块组成,第二个子残差cnn模块res2由2个basicblock模块组成,经过第二个子残差cnn模块res2,此时形状转换至(2,128,125,5);第三个子残差cnn模块res3由1个basicblock模块组成经过第三个子残差cnn模块res3,此时形状转换至(2,256,125,3);第四个子残差cnn模块res4由1个basicblock模块组成,经过第四个子残差cnn模块res4,此时形状转换至(2,512,125,2)。使用mean函数对第四个子残差cnn模块res4的输出进行处理,在最后一个维度上求平均,此时形状转换至(2,512,125)。至此,输入信号asr_input已经经过了残差cnn网络模型处理,提取出了有效帧,此时形状为(2,512,125)。使用transpose()函数将输入信号asr_input形状调整为(2,125,512),输入多头注意力网络模型,输出形状仍为(2,125,512),得到有效帧之间相关的注意力信息,完成了对输入信号asr_input的编码过程。表6为第二语音识别模型asr2的多头注意力网络模型参数表。表6第二语音识别模型asr2的多头注意力网络模型参数表随后将编码器处理过的asr_input输入解码器进行解码过程,首先经过linear全连接层处理,再经过softmax激活函数处理,将最后一个维度大小映射到音素字典大小,得到每个有效帧对应的音素的分布概率,概率最大的即为我们预测的客家方言音素,此时形状为(2,125,100)。将(125,2,100)和对应的客家方言文本标签输入至ctc损失函数中计算模型损失值,并通过公式(1)、(2)以及随机梯度下降法进行优化,得到性能稳定的第二语音识别模型asr2。通过对输入信号asr_input进行编码和解码,可获得输入信号asr_input的音素和音素隐性特征,将输入信号asr_input的音素隐性特征输入到低资源客家方言点识别计算模型c中,即可得到输入信号asr_input的方言所属点。所述低资源客家方言点识别计算模型c为一个分类器模型,包括bilstm模块、两个linear模块和softmax模块;方言音素隐性特征依次经过bilstm模块、两个linear模块和softmax模块处理,再通过交叉熵目标函数和adam算法进行优化,得到低资源客家方言点预测结果。在本发明实施例中,将所述低资源客家方言点识别计算模型c的三个超参数做如下设置:学习率learningrate设置为0.001,迭代次数epoch设置为100,单批数据量mini-batch大小设置为10000帧语音数据。通过对所述三项超参数进行设置,在不改变模型内部网络结构的情况下,改变模型的训练速度,将数据分为若干批进行分批处理,降低随机性,提高模型的训练效率。本发明实施例采用正确度accuracy来衡量所述低资源客家方言点识别计算模型c的输出结果的准确性,所述正确度accuracy的具体表达式如公式(5)所示:其中,truepositive代表本来是正样例,同时分类成正样例的个数;truenegative代表本来是负样例,同时分类成负样例的个数;all代表样例总个数。为了直观比较模型性能,将本发明实施例与四个基线模型进行性能比较,分别是:lstm模型,resnet&bi-lstm模型,x-vector模型,cnn_att模型。表7为本发明实施例与所述四个基线模型的实验结果。表7中第一行为lstm模型相关实验结果、第二行为resnet&bi-lstm模型相关实验结果、第三行为x-vector模型相关实验结果、第四行为cnn_att模型相关实验结果、第五~七行为本发明实施例相关实验结果,f1分数代表prec和rec的加权调和平均分数。表7客家方言点识别实验结果从表中数据得知,本发明实施例取得了最好的识别性能,验证了本发明实施例的可行性。分别去除迁移学习模块或数据增强模块进行对比实验,实验结果显示本发明实施例始终是最好性能,充分说明迁移学习和数据增强技术在低资源客家方言识别技术中的重要性。表8为本发明实施例客家方言点识别实验混淆矩阵结果,其中l1代表昌靖片,l2代表赣州片,l3代表海陆片,l4代表粤台片,l5代表粤西片,truelabel代表真实标签,predictedlabel代表预测标签。从表中可以看出大部分音频都可以被正确地识别出来。表8客家方言点识别混淆矩阵混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。以第一行数据[37,1,0,0,0]为例,五个数字相加为38,代表属于l1标签的语音有38条,其中预测为l1的占37条,预测为l2的占1条,预测为l3的占0条,预测为l4的占0条,预测为l5的占0条。对角线上的数字代表着正确预测的数量,其他的都为预测错误的数量。对角线上数值越大越好,即预测准确率越好。本发明实施例既可将输入的客家方言音频识别并转录成音素级别的文本句子,也可针对输入的方言语音所属的方言点进行识别。针对低资源客家方言数据量较少的情况,通过迁移学习模块和数据增强模块,有效提取出客家方言音素隐性特征,训练出准确率较好的低资源客家方言识别计算模型,便于后期为进行方言自动回复,聊天等任务提供更准确的指导信息。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

