本发明属于智能产品设计领域,具体地说是一种可识别情绪的语音对话装置设计。
背景技术:
随着社会经济的快速发展,人们的生活节奏也不断加速,并越来越多的承受着来自家庭、工作、学习等各方面的压力与负面情绪,从而导致社会负面事件频发。因此,个体的情绪调节与释放成为社会健康发展不可忽视的问题。产生情绪问题时,与心理专家的交流是最有效的疏解办法,但由于成本较高、社会观念落后等问题,大多的情绪问题都得不到及时的疏解,经过长期的积累则产生严重的后果。
智能语音技术与人工智能情绪识别技术的进步与发展为解决人们的情绪问题提供了新的思路,即社会中人际关系单薄的孤独青年通过与智能装置的交流可以有效的排解负面情绪。但目前,由于语音交互技术发展不够成熟,市面上现有的智能语音交互产品大多涉及智能电器控制、语音操作等领域,较少涉及与人文关怀相关的对话交流领域。
技术实现要素:
针对社会个体缺乏情绪疏解渠道的情绪失调问题,本发明提出一种可识别情绪的语音交互装置设计。
为了解决上述问题,本发明的技术方案是这样实现的:
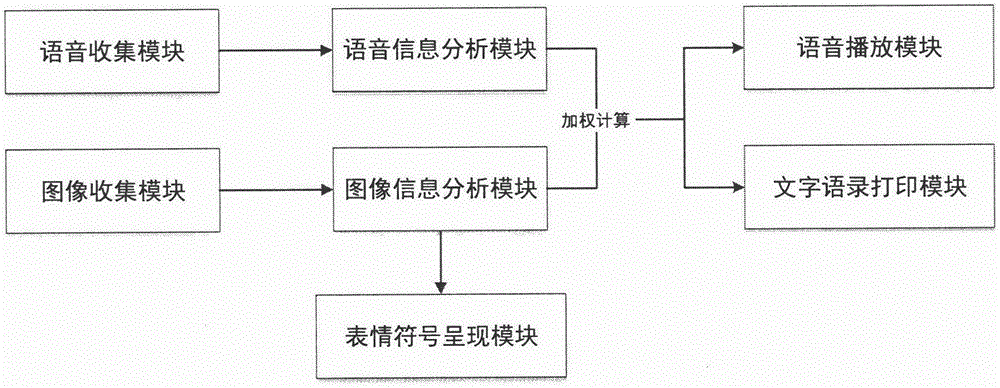
一种可识别情绪的语音对话装置设计,包括产品外设组件、语音功能组件、视觉功能组件、信息分析组件。具体地,所述产品外设组件包括座机电话壳体和底座;所述语音功能组件包括语音收集模块、语音播放模块;所述视觉功能组件包括图像收集模块和图像呈现模块;所述信息分析组件包括语音信息分析模块和图像信息分析模块;
优选地,所述语音收集模块与语音信息分析模块相连接,用于收集用户的语音信息,具体是通过传声器技术将采集的声音信号转换为电信号并传输给语音信息分析模块;
优选地,所述语音播放模块与语音信息分析模块相连接,用于播放装置反馈的语音信息,具体是通过扬声器技术将来自语音信息分析模块的电信号转换为声音信号播放给用户;
优选地,所述图像收集模块与图像信息分析模块相连接,用于收集用户的面部图像信息,具体是通过数字摄像头技术将采集的光学图像转换为数字图像信号并传输给图像分析模块;
优选地,所述图像呈现模块与图像信息分析模块相连接,用于呈现装置反馈的视觉信息,包括表情符号呈现模块与文字语录打印模块;
具体地,所述表情符号呈现模块通过led点阵呈现表情符号信息;所述文字语录打印模块通过嵌入式热敏打印机打印文字信息;
优选地,所述语音信息分析模块包括中央处理器与面向中文微博的情感分析语料库;
具体地,中央处理器采用x86平台工控机,中央处理器集中将所接收的语音信息与面向中文微博的情感分析语料库做情绪关键词的匹配分析,获得用户情绪倾向的第一部分结果;
优选地,所述图像信息分析模块包括51单片机处理器与face 人工智能开放平台;
具体地,51单片机处理器将所接收的用户面部图像信息上传至face 人工智能开放平台,利用该平台数据分析用户情绪成分,获得用户情绪倾向的第二部分结果;
优选地,用户情绪倾向的第一部分结果与第二部分结果经过中央处理器加权计算后获得用户情绪倾向最终结果;
优选地,所述用户情绪倾向最终结果有正向结果和负向结果两种可能;
优选地,装置对话范围包括家庭、工作、创业和感情四个话题内容;
本发明的有益效果:本发明通过设计话题选项、语音流程引导用户交流的方法,巧妙地在现有人工智能语音技术和人脸识别技术的基础之上,较为准确的识别用户交流过程中的情绪倾向并适时给用户视觉与听觉上的反馈,使体验者感受到机器装置能够与之共情、互动,极大提升了用户体验,具有很强的推广性和实用性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的系统结构示意图;
图2为本发明实施例的装置结构组装透视图;
图3为本发明实施例的装置本体分解图;
图4为本发明实施例的听筒局部拆解示意图;
图5为本发明的用户体验流程示意图;
附图标记:中央处理器1,座机壳体2,底座3,打印机4,摄像头5,听筒6,单片机处理器7,led点阵8,出纸口9,扬声器10,传声器11;
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种可识别情绪的语音对话装置设计,由语音收集模块收集用户的语音内容信息并发送给语音信息分析模块进行分析处理;由图像收集模块收集用户的面部图像信息并发送给图像信息分析模块进行分析处理,图像分析模块控制表情符号呈现模块,使所呈现的表情符号与用户表情情绪一致;
进一步地,语音信息分析模块与图像信息分析模块的处理结果经过加权计算后得到用户情绪倾向最终结果,依据该结果,语音播放模块为用户播放对应主题的故事语音信息,文字语录打印模块为用户打印对应主题的文字短句信息。
如图2与图3所示,本发明实施例整体由装置本体与中央处理器1组成,装置本体包括位于底部的底座3、安装于底座3表面的led点阵8、放置于底座3内部的打印机4与单片机处理器7、下半部分内置于底座3内的座机壳体2、放置于座机壳体2左侧的听筒6以及安装于座机壳体2顶部的摄像头5。
进一步地,装置本体底座3的前表面有出纸口9。
如图4所示,听筒6上端部内置扬声器10,下端部内置传声器11。
如图5所示,本发明的用户体验流程如下:当用户拿起听筒6,装置通过扬声器10发声开始主动问候用户并引导用户选择话题类别,交流由此开始。根据用户所选话题类型,对用户情绪做探测性的负向猜测询问,传声器11收录用户回答的语音内容并传输至中央处理器1,由中央处理器1负责将语音信息转为文本并与面向中文微博的情感分析语料库进行情绪关键词的匹配分析,获得用户情绪倾向第一部分结果;在用户倾诉交流过程中,摄像头5间隔五秒截取用户面部表情图像传输至单片机处理器7,由单片机处理器7借助face 人工智能开放平台对面部图像做情绪分析,获得用户情绪倾向的第二部分结果并传输至中央处理器1。根据中央处理器1对第一部分结果和第二部分结果加权计算后获得的用户情绪倾向最终结果,再由中央处理器1将反馈对应话题和情绪的故事文本并转化为语音信息传输至扬声器10播放给用户;
进一步地,依据所述用户情绪倾向的第二部分结果,单片机处理器7控制led点阵8显示特定位置的led灯以呈现贴合用户情绪的表情符号;
进一步地,在语音交流结束后,中央处理器1将根据此次交流的话题与用户情绪倾向最终结果,通过程序控制打印机4打印输出一段简短的语录文字给用户以作此次交流的纪念。
后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

