本发明涉及录音录像产品领域,特别涉及一种音频图像采集设备及说话人定位及语音分离方法。
背景技术:
在银行网点进行产品交易过程中需要进行录音录像,但是银行的大厅环境比较嘈杂,而当前的语音交互仅支持相对安静环境下单人对话,当环境噪声增强或其他人同时讲话时,语音识别的正确率将大幅降低甚至失效。传统的语音处理大多在单麦克风基础上利用时域及频域的信息来拟制噪声,而对同时刻及相同频带内的噪声及不相干的干扰声源的拟制是极其困难的。
麦克风阵列则可以通过空间域信息来构建空域滤波器,具有更好的降噪效果,可用于实现目标语音源的定位、跟踪和分离等功能。而当前麦克风阵列基础上的主流语音分离方法主要基于单一的声音模态,无法区分各声源是否属于有用信息,依然存在感知不足的问题。人们通常是通过图像、声音、触觉等多种模态协同感知、识别周围的环境,具有高度准确的识别能力。对这类多模态环境感知的研究在人机识别交互、服务机器人的说话人跟踪、移动通信等诸多领域有重要的理论意义与实用价值。
麦克风阵列的语音增强及分离方法极其依赖对声源的精确定位。传统基于麦克风阵列基础上的声源定位方法利用音频传播的空间特性,来估计出声源的传播来向,而当环境中具有多个不同属性声源的时候,这种方法无法判别各声源是否为有用声源,不能实现对目标声源进行准确估计和定位。在复杂声源环境下,这种音频处理方式下的智能语音交互系统性能受到了限制。
技术实现要素:
针对现有音频处理方式方法和系统的不足之处,本发明创造的目的是提供一种音频图像采集设备及说话人定位及语音分离方法。
本发明的目的是这样实现的:一种音频图像采集设备及说话人定位及语音分离方法,包括双摄像头、还包括4麦克风阵列的音频及图像采集设备;该方法包括以下步骤:
a.采集音频设备采集音频数据;
b.使用子带功率谱熵特征来实现语音端点检测;
c.通过广义互相关法对多声源进行初步定向;
d.采集图像设备采集人脸图像;
e.使用viola-jones人脸检测算法对说话人进行检测判别;并使用adaboost算法生成级联分类器,来对图像的小块区域进行特征匹配,检测该区域内是否有人;
f.使用人脸检测算法对双目相机得到的两幅图像进行人脸检测,得到各自人脸的位置及大小信息,再通过双目视觉定位的原理得到人脸的方向及距离信息;
g.将音频及图像两种方法的分别定位结果进行结合,判别声源是否来源于人;
h.结合广义旁瓣相消法与维纳滤波器相结合的期望语音分离方法,通过广义旁瓣相消器对主瓣方向语音进行增强,再使用维纳滤波器对残留噪声进行滤除,达到语音优化分离的目的。
优选的,所述步骤b检测方法如下:设音频信号为x(t),
(1)对观测信号x(t)进行分帧加窗得到n帧信号,每一帧信号长度为l,对所有分帧信号求自相关函数r(t),第n帧信号得到:
(2)对自相关函数作长度为l的快速傅里叶变换,得到功率频谱:
其中en(w)表示第w个频率点的功率谱幅度。由于en(w)的实信号部分关于l/2 1对称,其功率谱能量只看1≤w≤l/2部分;
(3)由于每个功率频谱点容易被噪声干扰,为了提高该参数在地信噪比环境下抗干扰的能力,将每帧功率谱均匀划分为4个子带:
(4)求得第n帧信号的第1个频点功率谱能量占整个功率谱概率为:
则每一帧信号对应的spse特征为:
最后通过设定阈值,对每一帧音频信号的子带功率谱熵特征来判定该帧信号是否为语音。
优选的,所述步骤c中初步定为方法如下:
(1)将两个麦克风所采集到的音频信号进行分帧加窗处理,第i个信号源到达两麦克风的第n帧信号分别为:
式中,sin(t)为第i个独立声源,αi为该声源传播到达对应麦克风的衰减系数,τi为该声源到达对应麦克风的时间参数,n(t)为对应麦克风中的不相干加性噪声;
(2)为锐化互相关函数的峰值,来降低环境噪声的影响,在频域中使用权函数
通过加权后的互相关函数中,认为噪声互相关函数rn1n2(τi)为0,则有:
当τi=τ1i-τ2i时,r12n(τi)取得最大值,可以通过此求得声源snj(t)到达相邻麦克风间的时延τl;
(3)得到一段语音信号每一帧的时延值后,可计算得到所有语音帧时延的概率密度,并对该函数进行寻峰即得声源方向矩阵:
其中,矩阵长度ns即为声源个数,
优选的,所述步骤e中viola-jones人脸检测步骤如下:首先对图像进行不同尺度大小的缩放,形成多个图像区域;对每个区域提取对应的haar-like特征,并使用级联分类器对其进行检测;若该级分类器认为该区域有人脸,使用下一级分类器对其进行检测,若无人脸,直接丢弃该区域。最终只有所有级分类器对该区域都判定为有人脸,才能认定该区域包含人脸。
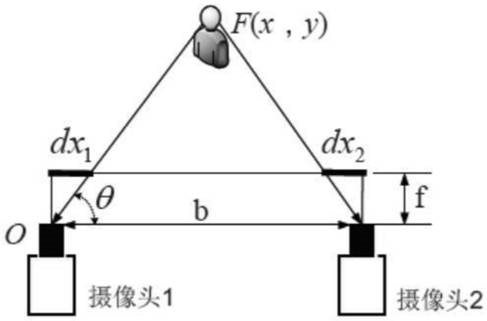
优选的,所述步骤f中双目视觉定位方法如下:设b为两摄像头之间基线距离,f为两摄像头焦距,f为说话人的位置信息,dx1及dx2分别为说话人到两摄像头投影空间中的水平偏移量;以摄像头1为参考,根据相似三角形几何原理,可得到说话人的位置信息以及方向信息分别为:
其中max1为参考摄像头在投影区域中最大水平偏移值;最终使用双目摄像头得到多说话人的人脸位置信息矩阵为:
其中θv及dv分别为说话人的方向及距离信息,nv为所检测到说话人数量。
优选的,所述步骤g中判别声源是否来源于人的方法如下:将声源估计方向结果与检测的人脸定位结果的方向值进行逐个计算差异值:
若该值小于设定阈值,则得到最终的个数为n的说话人定位矩阵:
优选的,所述步骤g中广义旁瓣相消法的具体步骤为:
(1)、麦克风数为m=4,所采集信号为x[x1(t),x2(t),x3(t),x4(t)]t,固定波束形成的加权矩阵矩阵为a[a1,a2,a3,a4]t,则固定波束形成的输出信号为:
yc(t)=atx(5-1)
(2)为保证阻塞矩阵能够阻塞主瓣方向的语音信号,阻塞矩阵的每一行元素都要为零,使用次数最多的阻塞矩阵形式为:
(3)通过该阻塞矩阵后,输出为m-1个维度的噪声参考信号为
u=bx(5-3)
(4)再使用自适应噪声系数从噪声参考信号中估计出只包含噪声和干扰的估计噪声有:
yn(t)=wt(t)u(t)(5-4)
(5)将两信号相减得到期望方向的分离语音为:
y(t)=yc(t)-yn(t)(5-5)
(6)通常使用最小均方准则从固定波束形成输出的信号估计出自适应噪声抵消系数:
其中u为步长因子,它影响的是滤波器滤除噪声的能力。
优选的,所述步骤g中后置维纳滤波器原理如下:
(1)广义旁瓣相消法输出信号y(t)中带有残留噪声nw(t)及干净语音yw(t):
y(t)=yw(t) nw(t)(6-1)
维纳滤波器的求解过程即是求出冲击响应函数h(t),来得到估计干净语音
为使得输出结果与干净语音之差满足lms准则:
维纳滤波器使用维纳-霍夫方程来得到最小误差,即:
其中ryw为估计信号yw(t)的自相关函数,n为示波器阶数,通过此方法得到最佳的响应函数h(t),从而估计出滤波后信号yw(t)。
优选的,所述音频图像采集设备可采集到扇形为170°范围内的双目图像信息以及5m范围内的4通道音频信号,并具有立体声语音播放功能。
优选的,所述音频图像采集设备使用gui功能设计交互界面,对采集到的数据进行实时处理,将说话人定位结果进行显示,并将目标说话人的语音进行分离,将分离语音进行显示及播放。
与现有技术相比,本发明的有益之处在于:采用音频收集设备收集声源,在说话人部分,使用单一音频模态的麦克风阵列下的广义互相关法,同时采用了子带功率频谱熵特征来对语音进行端点检测,提升声源定向方法的鲁棒性;然后使用viola-jones人脸检测方法与双目视觉相结合的多人脸检测定位方法;最后将两种模态定位的结果进行联合判定,得到说话人详细的位置信息,极大降低干扰声源造成声源定向的错误率;在语音分离部分,采用了广义旁瓣相消法与维纳滤波器相结合的期望语音分离方法,通过广义旁瓣相消器对主瓣方向语音进行增强,再使用维纳滤波器对残留噪声进行滤除,从而达到语音优化分离的目的。
附图说明
图1为本发明的整体流程图。
图2为本发明双目视觉定位模型。
具体实施方式
一种音频图像采集设备及说话人定位及语音分离方法,包括双摄像头、还包括4麦克风阵列的音频及图像采集设备;该方法包括以下步骤:
a.采集音频设备采集音频数据;
b.使用子带功率谱熵特征来实现语音端点检测;
c.通过广义互相关法对多声源进行初步定向;
d.采集图像设备采集人脸图像;
e.使用viola-jones人脸检测算法对说话人进行检测判别;并使用adaboost算法生成级联分类器,来对图像的小块区域进行特征匹配,检测该区域内是否有人;
f.使用人脸检测算法对双目相机得到的两幅图像进行人脸检测,得到各自人脸的位置及大小信息,再通过双目视觉定位的原理得到人脸的方向及距离信息;
g.将音频及图像两种方法的分别定位结果进行结合,判别声源是否来源于人;
h.结合广义旁瓣相消法与维纳滤波器相结合的期望语音分离方法,通过广义旁瓣相消器对主瓣方向语音进行增强,再使用维纳滤波器对残留噪声进行滤除,达到语音优化分离的目的。
上述步骤b检测方法如下:设音频信号为x(t),
(1)对观测信号x(t)进行分帧加窗得到n帧信号,每一帧信号长度为l,对所有分帧信号求自相关函数r(t),第n帧信号得到:
(2)对自相关函数作长度为l的快速傅里叶变换,得到功率频谱:
其中en(w)表示第w个频率点的功率谱幅度。由于en(w)的实信号部分关于l/2 1对称,其功率谱能量只看1≤w≤l/2部分;
(3)由于每个功率频谱点容易被噪声干扰,为了提高该参数在地信噪比环境下抗干扰的能力,将每帧功率谱均匀划分为4个子带:
(4)求得第n帧信号的第1个频点功率谱能量占整个功率谱概率为:
则每一帧信号对应的spse特征为:
最后通过设定阈值,对每一帧音频信号的子带功率谱熵特征来判定该帧信号是否为语音。
上述步骤c中初步定为方法如下:
(1)将两个麦克风所采集到的音频信号进行分帧加窗处理,第i个信号源到达两麦克风的第n帧信号分别为:
式中,sin(t)为第i个独立声源,αi为该声源传播到达对应麦克风的衰减系数,τi为该声源到达对应麦克风的时间参数,n(t)为对应麦克风中的不相干加性噪声;
(2)为锐化互相关函数的峰值,来降低环境噪声的影响,在频域中使用权函数
通过加权后的互相关函数中,认为噪声互相关函数rn1n2(τi)为0,则有:
当τi=τ1i-τ2i时,r12n(τi)取得最大值,可以通过此求得声源snj(t)到达相邻麦克风间的时延τl;
(3)得到一段语音信号每一帧的时延值后,可计算得到所有语音帧时延的概率密度,并对该函数进行寻峰即得声源方向矩阵:
其中,矩阵长度ns即为声源个数,
上述步骤e中viola-jones人脸检测步骤如下:首先对图像进行不同尺度大小的缩放,形成多个图像区域;对每个区域提取对应的haar-like特征,并使用级联分类器对其进行检测;若该级分类器认为该区域有人脸,使用下一级分类器对其进行检测,若无人脸,直接丢弃该区域。最终只有所有级分类器对该区域都判定为有人脸,才能认定该区域包含人脸。
上述步骤f中双目视觉定位方法如下:设b为两摄像头之间基线距离,f为两摄像头焦距,f为说话人的位置信息,dx1及dx2分别为说话人到两摄像头投影空间中的水平偏移量;以摄像头1为参考,根据相似三角形几何原理,可得到说话人的位置信息以及方向信息分别为:
其中max1为参考摄像头在投影区域中最大水平偏移值;最终使用双目摄像头得到多说话人的人脸位置信息矩阵为:
其中θv及dv分别为说话人的方向及距离信息,nv为所检测到说话人数量。
上述步骤g中判别声源是否来源于人的方法如下:将声源估计方向结果与检测的人脸定位结果的方向值进行逐个计算差异值:
若该值小于设定阈值,则得到最终的个数为n的说话人定位矩阵:
上述步骤g中广义旁瓣相消法的具体步骤为:
(1)、麦克风数为m=4,所采集信号为x[x1(t),x2(t),x3(t),x4(t)]t,固定波束形成的加权矩阵矩阵为a[a1,a2,a3,a4]t,则固定波束形成的输出信号为:
yc(t)=atx(5-1)
(2)为保证阻塞矩阵能够阻塞主瓣方向的语音信号,阻塞矩阵的每一行元素都要为零,使用次数最多的阻塞矩阵形式为:
(3)通过该阻塞矩阵后,输出为m-1个维度的噪声参考信号为
u=bx(5-3)
(4)再使用自适应噪声系数从噪声参考信号中估计出只包含噪声和干扰的估计噪声有:
yn(t)=wt(t)u(t)(5-4)
(5)将两信号相减得到期望方向的分离语音为:
y(t)=yc(t)-yn(t)(5-5)
(6)通常使用最小均方准则从固定波束形成输出的信号估计出自适应噪声抵消系数:
其中u为步长因子,它影响的是滤波器滤除噪声的能力。
上述步骤g中后置维纳滤波器原理如下:
(1)广义旁瓣相消法输出信号y(t)中带有残留噪声nw(t)及干净语音yw(t):
y(t)=yw(t) nw(t)(6-1)
维纳滤波器的求解过程即是求出冲击响应函数h(t),来得到估计干净语音
为使得输出结果与干净语音之差满足lms准则:
维纳滤波器使用维纳-霍夫方程来得到最小误差,即:
其中ryw为估计信号yw(t)的自相关函数,n为示波器阶数,通过此方法得到最佳的响应函数h(t),从而估计出滤波后信号yw(t)。
上述音频图像采集设备可采集到扇形为170°范围内的双目图像信息以及5m范围内的4通道音频信号,并具有立体声语音播放功能。
上述音频图像采集设备使用gui功能设计交互界面,对采集到的数据进行实时处理,将说话人定位结果进行显示,并将目标说话人的语音进行分离,将分离语音进行显示及播放。
本发明的工作原理阐述如下:采集设备将数据采集到后,麦克风阵列基础上的gcc声源定向方法对多声源进行定向,使用图像处理中的viola-jones人脸检测方法进一步对说话人进行判定,并通过双目视觉原理得到多说话人的位置信息,在选择目标说话人后,使用gsc方法及后置维纳滤波器搭建空域滤波器对目标方向语音进行分离。
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

