1.本发明属于飞机设计领域,提出一种基于深度强化学习和迁移学习的增升装置优化方法。
背景技术:
2.大型飞机起降阶段增升装置的优化设计,可以提升飞机的经济性和安全性,是关键技术。增升装置的流动机理复杂,难以通过理论推导求解。而计算流体力学手段,一套三维三段翼的翼身组合体网格至少在百万甚至千万以上,需要消耗大量的计算资源和时间,因此对优化算法的效率有较高要求。目前常用的优化算法以启发式算法为主,其中又以遗传算法为代表被广泛应用,但其只针对纯二维优化或三维优化,前者虽然计算速度较快,但性能与真实流动存在差异,只能在一些假设下通过物理方程推导二维和三维的流动关系,具有局限性。而纯三维优化对计算资源和时间的占用相当大;且二维优化结果无法为三维优化提供指导。目前增升装置朝着简单形式的方向发展,其设计目标包括但不限于气动、机构、结构、噪声、重量、可靠性等多方面因素,是个典型的多学科交叉耦合设计问题,这对优化方法又是个极大的挑战。目前人工智能技术得到了大量发展,其中深度强化学习,结合了深度学习的表征能力和强化学习的决策能力,正越来越在多领域内发挥重要作用。
技术实现要素:
3.针对上述问题,本发明提出一种基于深度强化学习和迁移学习的增升装置优化方法,旨在结合二维计算快、三维计算准的特点,从算法层面上搭建起二者衔接的桥梁,是一种高效率又精准的优化方法。
4.本发明基于深度强化学习和迁移学习的增升装置优化方法,具体过程如下:
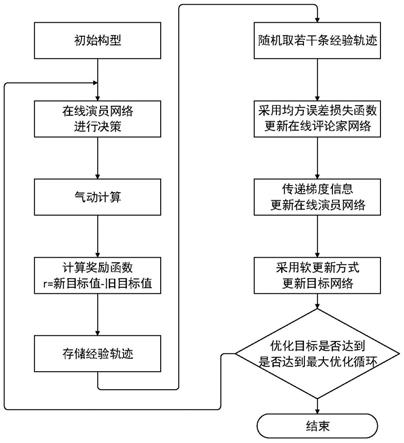
5.a、二维优化阶段
6.步骤1:给定目标值函数;对于单目标优化,优化目标直接视为目标值,对于多目标优化,采用线性加权的方式将其转化为单目标;
7.步骤2:建立智能体,包含在线演员网络和在线评论家网络,以及目标演员网络和目标评论家网络;在线演员神经网络和在线评论家网络内部参数采用正交随机初始化。
8.步骤3:建立空的经验池,将当前增升装置参数输入给在线演员神经网络,其输出决策,即新构型增升装置参数。
9.步骤4:计算新构型增升装置气动性能;
10.步骤5:根据气动性能计算奖励函数得到奖励值;
11.步骤6:将状态、动作、奖励值序列存入经验池中;其中状态值为旧构型增生装置参数,动作值为新构型增升装置参数。
12.步骤7:从当前的经验池中随机取出经验轨迹,分别训练在线评论家网络和在线演员网络,并更新目标演员网络和目标评论家网络。
13.步骤8:用新构型增升装置参数更新旧构型增升装置参数;
14.步骤9:重复步骤3至8,直到目标值函数满足优化要求,或达到最大优化循环。
15.b、三维优化阶段
16.三维优化阶段整体过程与二维类似,同样包括前述步骤1至步骤9,区别在于:步骤2中采用迁移学习中预训练的方法优化在线网络参数采用二维优化的结果参数;
17.在步骤3中,初始位置参数设置为二维优化的最优解。
18.本发明的优点在于:
19.1、本发明基于深度强化学习和迁移学习的增升装置优化方法,将深度强化学习方法引入至增升装置的起降构型优化设计中,提出一种不同于常见启发式算法的优化方式。
20.2、本发明基于深度强化学习和迁移学习的增升装置优化方法,利用迁移学习预训练的方式,搭建起二维优化结果和三维优化的关系,从而有效地利用二维优化的结果来加速三维优化效率,减少计算资源和时间的消耗。
附图说明
21.图1为本发明增升装置优化方法中整体流程图。
22.图2为二维翼型气动计算时对三维机翼构型的截取方式。
具体实施方式
23.下面结合附图对本发明做进一步详细说明。
24.本发明基于深度强化学习和迁移学习的增升装置优化方法中,增升装置位置采用下述方式进行描述:
25.不管是前缘缝翼还是后缘襟翼,其从巡航位置展开至起降位置,均可视为刚体的空间运动,满足夏莱定理,即任何刚体的运动可以转变为绕空间某根轴的旋转运动和沿着该轴的位移运动的矢量叠加。旋转轴由一参考点p1(p
x
,p
y
,p
z
)
t
和轴的方向矢量u(u
x
,u
y
,u
z
)
t
表示,绕该旋转轴的旋转运动角度表示为φ,沿该旋转轴的位移运动用l来表示。由上述参数可以组成有限螺旋矩阵[r
h
]。
[0026][0027][0028]
v
φ
=1
‑
cosφ
ꢀꢀ
(1.3)
[0029]
带增升装置的高升力构型设计一般位于高速巡航构型之后,因此增升装置上任意一点的巡航位置(x1,y1,z1)是已知的。在单次优化循环中,优化算法给定一组待计算的优化变量(p
x
,p
y
,u
x
,u
y
,φ,l),则增升装置上任意一点的起降位置(x2,y2,z2)可由其巡航位置和有限螺旋矩阵[r
h
]求出。
[0030]
[x
2 y
2 z
2 1]
t
=[r
h
][x
1 y
1 z
1 1]
t
ꢀꢀ
(1.4)
[0031]
本发明中基于深度强化学习中的ddpg算法框架,用二维优化的结果以提高三维增升装置的优化效率,整体过程分为两个阶段,即二维优化阶段和三维优化阶段,如图1所示,
具体方法如下:
[0032]
a、二维优化阶段
[0033]
步骤1:给定目标值函数t。对于单目标优化,优化目标直接视为目标值,对于多目标优化,采用线性加权的方式将其转化为单目标,如式(1.5)。
[0034][0035]
其中,α
i
为第i个目标的权重,t
i
为第i个目标值。
[0036]
步骤2:建立智能体,其包含两个在线神经网络(在线演员网络和在线评论家网络)和两个目标神经网络(目标演员网络和目标评论家网络)。在线演员神经网络π(s|θ)和在线评论家网络q(s|ω),其中θ和ω分别为两个神经网络各自的内部参数,采用正交随机初始化,s代表了当前的优化构型所对应的位置参数s=(p
x
,p
y
,u
x
,u
y
,φ,l),是神经网络的输入。初始化目标演员神经网络π
′
(s|θ
′
)和目标评论家网络q
′
(s|ω
′
),其内部参数θ
′
、ω
′
完全复制相应的在线网络,即θ
′
=θ,ω
′
=ω。
[0037]
步骤3:建立空的经验池ω,给定一组初始位置参数(p
x
,p
y
,u
x
,u
y
,φ,l),并将位置参数s=(p
x
,p
y
,u
x
,u
y
,φ,l)输入给在线演员神经网络π(s|θ),其输出决策表示为a=(p
x
′
,p
y
′
,u
x
′
,u
y
′
,φ
′
,l
′
)。
[0038]
步骤4:根据新参数(p
x
′
,p
y
′
,u
x
′
,u
y
′
,φ
′
,l
′
),由式(1.1)至(1.4)计算增升装置新的起降位置,得到增升装置新构型,并采用二维计算的结果近似代替其气动性能。如图2所示,取机翼展长方向的1/4和3/4位置截取平面,对两个二维翼型进行气动计算,取结果的平均值近似为三维气动性能。
[0039]
步骤5:根据气动性能计算目标值,根据式(1.6)计算奖励函数r,其中t
new
为新构型目标值,t
old
为旧构型目标值。
[0040]
r=t
new
‑
t
old
ꢀꢀ
(1.6)
[0041]
步骤6:将状态、动作、奖励值序列[s,a,r]存入经验池ω中。其中状态值s=(p
x
,p
y
,u
x
,u
y
,φ,l)为旧构型的六个变量,动作值a=(p
x
′
,p
y
′
,u
x
′
,u
y
′
,φ
′
,l
′
)为新构型的六个变量。
[0042]
步骤7:从当前的经验池ω中随机取5至10条经验轨迹,采用小批量梯度下降法分别训练在线评论家网络和在线演员网络。采用软更新的方式对目标演员网络和目标评论家网络进行更新。
[0043]
步骤8:用新构型参数更新旧构型参数。
[0044]
(p
x
,p
y
,u
x
,u
y
,φ,l)
←
(p
x
′
,p
y
′
,u
x
′
,u
y
′
,φ
′
,l
′
)
ꢀꢀ
(1.7)
[0045]
步骤9:重复步骤3至8,直到目标值函数满足优化要求,或达到最大优化循环。二维优化得到在线演员神经网络的参数θ
end
和在线评论家神经网络的参数ω
end
,同时得到二维优化的最优解
[0046]
b三维优化阶段。
[0047]
三维优化阶段整体过程与二维类似,同样包括前述步骤1至步骤9,但其中步骤2与步骤3中采用迁移学习中预训练的方法,以提升优化算法的收敛速度。
[0048]
在步骤2中,三维优化和二维优化的各神经网络组成形式一致,但初始化方式不
同。二维在线演员神经网络和在线评论家网络的参数θ和ω采用正交随机初始化,而三维优化在线网络参数θ
3d
和ω
3d
采用二维优化的结果参数θ
end
和ω
end
,即二维优化的最优解时所对应的在线评论家网络和在线演员网络参数,θ
3d
=θ
end
,ω
3d
=ω
end
。
[0049]
在步骤3中,建立空的经验池不变,初始位置参数设置为二维优化的最优解
[0050]
此外在步骤5中,三维优化采取的气动性能计算方法为整机三维计算,相较二维近似的计算手段,精度更高。
[0051]
三维优化的计算成本相当巨大,本发明通过深度强化学习和迁移学习耦合的方式,让智能体在二维优化中进行大量而快速的预训练,从而学习到增升装置气动性能与优化变量之间的经验,即使二维计算结果与真实流动存在一定差异性,但这份经验仍具有参考性。让二维优化训练出的智能体在三维优化中进行采样,修正所获得的经验,而不是纯三维优化中需要从零开始学习,这能有效减少三维计算成本,同时保证了优化结果的准确性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。