使用深度生成性模型的视频压缩
1.根据35 u.s.c.
§
119的优先权要求
2.本专利申请要求于2019年3月21日提交的题为“video compression using deep generative models(使用深度生成性模型的视频压缩)”的非临时申请no.16/360,458的优先权,该非临时申请已转让给其受让人并且由此通过援引被明确纳入于此。
3.公开领域
4.本公开一般涉及人工神经网络,尤其涉及使用人工神经网络来压缩视频内容。
5.相关技术描述
6.可包括一群互连的人工神经元(例如,神经元模型)的人工神经网络是一种计算设备或者表示由计算设备执行的方法。这些神经网络可被用于各种应用和/或设备,诸如网际协议(ip)相机、物联网(iot)设备、自主交通工具、和/或服务机器人。
7.人工神经网络中的个体节点可以通过采取输入数据并且对该数据执行简单操作来模拟生物神经元。有选择地将对输入数据执行简单操作的结果传递给其他神经元。权重值与网络中的每个向量和节点相关联,并且这些值约束了输入数据如何与输出数据有关。例如,可以将每个节点的输入数据乘以对应的权重值,并且可将乘积求和。这些乘积的总和可由可任选的偏置进行调节,并且可将激活函数应用于结果,从而产生该节点的输出信号或“输出激活”。这些权重值最初可由通过网络的训练数据的迭代流来确定(例如,权重值是在训练阶段期间建立的,在该阶段中,该网络学习如何按特定类的典型输入数据特征来标识特定类)。
8.存在不同类型的人工神经网络,诸如递归神经网络(rnn)、多层感知器(mlp)神经网络、卷积神经网络(cnn)等。rnn按节省层的输出并且将该输出反馈到输入以帮助预测该层的结果的原理来工作。在mlp神经网络中,数据可被馈送到输入层,并且一个或多个隐藏层为该数据提供抽象程度。然后可以基于经抽象的数据在输出层上作出预测。mlp可特别适用于输入被指派类或标签的情况下的分类预测问题。卷积神经网络(cnn)是一种类型的前馈人工神经网络。卷积神经网络可包括人工神经元集合,其中每一个神经元具有感受野(例如,输入空间的空间局部化区域)并且共同地拼砌出一输入空间。卷积神经网络具有众多应用。具体而言,cnn已被广泛使用于模式识别和分类领域。
9.在分层神经网络架构中,第一层人工神经元的输出成为第二层人工神经元的输入,第二层人工神经元的输出成为第三层人工神经元的输入,依此类推。可以训练卷积神经网络来识别特征的阶层。卷积神经网络架构中的计算可分布在处理节点群体上,该处理节点群体可被配置在一个或多个计算链中。这些多层架构可每次训练一层并可使用后向传播来微调。
10.概述
11.本公开的某些方面涉及一种用于压缩视频的方法。该方法一般包括:接收供压缩的视频内容,通过由第一人工神经网络实现的自编码器将所接收的视频内容编码到隐代码空间中,通过由第二人工神经网络实现的概率模型生成经编码视频内容的经压缩版本,以及输出经编码视频内容的经压缩版本以供传输。
12.本公开的某些方面涉及一种用于压缩视频的系统。该系统包括至少一个处理器、以及耦合至该至少一个处理器的存储器。该至少一个处理器一般被配置成:接收供压缩的视频内容,通过由配置成在该至少一个处理器上执行的第一人工神经网络实现的自编码器将所接收的视频内容编码到隐代码空间中,通过由配置成在该至少一个处理器上执行的第二人工神经网络实现的概率模型生成经编码视频内容的经压缩版本,以及输出经编码视频内容的经压缩版本以供传输。
13.本公开的某些方面涉及一种包括指令的非瞬态计算机可读介质,这些指令在由至少一个处理器执行时使该处理器执行用于压缩视频的操作。该操作一般包括:接收供压缩的视频内容,通过由第一人工神经网络实现的自编码器将所接收的视频内容编码到隐代码空间中,通过由第二人工神经网络实现的概率模型生成经编码视频内容的经压缩版本,以及输出经编码视频内容的经压缩版本以供传输。
14.本公开的某些方面涉及一种用于解压缩经编码视频的方法。该方法一般包括:接收经编码视频内容的经压缩版本,基于由第一人工神经网络实现的概率模型将经编码视频内容的经压缩版本解压缩到隐代码空间中,通过由第二人工神经网络实现的自编码器从隐代码空间解码出经编码视频内容,以及输出经解码视频内容以供显示。
15.本公开的某些方面涉及一种用于解压缩经编码的视频的系统。该系统包括至少一个处理器、以及耦合至该至少一个处理器的存储器。该至少一个处理器一般被配置成:接收经编码视频内容的经压缩版本,基于由配置成在所述至少一个处理器上执行的第一人工神经网络实现的概率模型将经编码视频内容的经压缩版本解压缩到隐代码空间中,通过由配置成在所述至少一个处理器上执行的第二人工神经网络实现的自编码器从隐代码空间解码出经编码视频内容,以及输出经解码视频内容以供显示。
16.本公开的某些方面涉及一种包括指令的非瞬态计算机可读介质,这些指令在由至少一个处理器执行时使该处理器执行用于解压缩经编码视频的操作。这些操作一般包括:接收经编码视频内容的经压缩版本;基于由第一人工神经网络实现的概率模型将经编码视频内容的经压缩版本解压缩到隐代码空间中;通过由第二人工神经网络实现的自编码器从隐代码空间解码出经编码视频内容;以及输出经解码视频内容以供显示。
17.本公开的其他方面、优点、和特征将在阅读整个申请后变得明了,整个申请包括以下章节:附图简述、详细描述、以及权利要求。
18.附图简述
19.图1解说了片上系统(soc)的示例实现。
20.图2a解说了全连通神经网络的示例。
21.图2b解说了局部连通神经网络的示例。
22.图2c解说了卷积神经网络的示例。
23.图2d解说了设计成用于从图像中识别视觉特征的深度卷积网络(dcn)的详细示例。
24.图3是解说深度卷积网络(dcn)的框图。
25.图4解说了根据本公开的各方面的使用人工神经网络的用于压缩视频内容的示例流水线和用于将所接收的比特流解压缩为视频内容的另一示例流水线。
26.图5解说了根据本公开的各方面的用于通过包括自编码器和概率模型的压缩流水
线来压缩所接收的视频内容的示例操作。
27.图6解说了根据本公开的各方面的用于解压缩经编码视频的示例操作。
28.图7示出了解说根据本公开的各方面的用于将人工智能(ai)功能模块化的示例性软件架构的框图。
29.详细描述
30.本公开的某些方面提供用于使用深度生成性模型来压缩视频内容以及用于将所接收的比特流解压缩为视频内容的方法和装置。
31.现在参照附图,描述本公开的若干示例性方面。措辞“示例性”在本文中用于意指“用作示例、实例、或解说”。本文中所描述为“示例性”的任何方面不必被解读为优于或胜过其他方面。
32.示例人工神经网络
33.图1解说了根据本公开的某些方面的片上系统(soc)100的示例实现,其可包括配置成执行并行monte carlo丢弃功能的中央处理单元(cpu)102或多核cpu。变量(例如,神经信号和突触权重)、与计算设备相关联的系统参数(例如,带有权重的神经网络)、延迟、频率槽信息、以及任务信息可被存储在与神经处理单元(npu)108相关联的存储器块中、与cpu 102相关联的存储器块中、与图形处理单元(gpu)104相关联的存储器块中、与数字信号处理器(dsp)106相关联的存储器块中、存储器块118中,或可跨多个块分布。在cpu 102处执行的指令可从与cpu 102相关联的程序存储器加载或可从存储器块118加载。
34.soc 100还可包括为具体功能定制的附加处理块,诸如gpu 104、dsp106、连通性块110(其可包括第五代(5g)连通性、第四代长期演进(4g lte)连通性、wi
‑
fi连通性、usb连通性、蓝牙连通性等)以及例如可检测和识别姿势的多媒体处理器112。在一种实现中,npu实现在cpu 102、dsp 106、和/或gpu 104中。soc 100还可包括传感器处理器114、图像信号处理器(isp)116、和/或导航模块120(其可包括全球定位系统)。
35.soc 100可基于arm指令集。在本公开的一方面中,加载到cpu 102中的指令可包括用于在与输入值和滤波器权重的乘积相对应的查找表(lut)中搜索所存储的乘法结果的代码。加载到cpu 102中的指令还可包括用于在该乘法乘积的乘法运算期间当检测到该乘法乘积的查找表命中时禁用乘法器的代码。另外,加载到cpu 102中的指令可包括用于在乘积的查找表未命中被检测到时存储输入值和滤波器权重的所计算乘积的代码。
36.根据下面讨论的本公开的各方面,soc 100和/或其组件可被配置成执行视频压缩和/或解压缩。通过使用深度学习架构来执行视频压缩和/或解压缩,本公开的各方面可以加速对设备上视频内容的压缩和经压缩视频到另一设备的传输,和/或可以加速对在该设备处所接收的经压缩视频内容的解压缩。
37.深度学习架构可通过学习在每一层中以逐次更高的抽象程度来表示输入、藉此构建输入数据的有用特征表示来执行对象识别任务。以此方式,深度学习解决了传统机器学习的主要瓶颈。在深度学习出现之前,用于对象识别问题的机器学习办法可能严重依赖人类工程设计的特征,或许与浅分类器相结合。浅分类器可以是两类线性分类器,例如,其中可将输入值(例如,输入向量分量)的加权和与阈值作比较以预测输入属于哪一类别。人类工程设计的特征可以是由拥有领域专业知识的工程师针对具体问题领域定制的模版或内核。相反,深度学习架构可学习以表示与人类工程师可能会设计的相似的特征,但它是通过
训练来学习的。此外,深度网络可以学习以表示和识别人类可能还没有考虑过的新类型的特征。
38.深度学习架构可以学习特征阶层。例如,如果向第一层呈递视觉数据,则第一层可学习以识别输入流中的相对简单的特征(诸如边)。在另一示例中,如果向第一层呈递听觉数据,则第一层可学习以识别特定频率中的频谱功率。取第一层的输出作为输入的第二层可以学习以识别特征组合,诸如对于视觉数据识别简单形状或对于听觉数据识别声音组合。例如,更高层可学习以表示视觉数据中的复杂形状或听觉数据中的词语。再高层可学习以识别常见视觉对象或口语短语。
39.深度学习架构在被应用于具有自然阶层结构的问题时可能表现特别好。例如,机动交通工具的分类可受益于首先学习以识别轮子、挡风玻璃、以及其他特征。这些特征可在更高层以不同方式被组合以识别轿车、卡车和飞机。
40.神经网络可被设计成具有各种连通性模式。在前馈网络中,信息从较低层被传递到较高层,其中给定层中的每个神经元向更高层中的神经元进行传达。如上所述,可在前馈网络的相继层中构建阶层式表示。神经网络还可具有回流或反馈(也被称为自顶向下(top
‑
down))连接。在回流连接中,来自给定层中的神经元的输出可被传达给相同层中的另一神经元。回流架构可有助于识别跨越不止一个按顺序递送给该神经网络的输入数据组块的模式。从给定层中的神经元到较低层中的神经元的连接被称为反馈(或自顶向下)连接。当高层级概念的识别可辅助辨别输入的特定低层级特征时,具有许多反馈连接的网络可能是有助益的。
41.神经网络的各层之间的连接可以是全连通的或局部连通的。图2a解说了全连通神经网络202的示例。在全连通神经网络202中,第一层中的神经元可将它的输出传达给第二层中的每个神经元,从而第二层中的每个神经元将从第一层中的每个神经元接收输入。图2b解说了局部连通神经网络204的示例。在局部连通神经网络204中,第一层中的神经元可连接到第二层中有限数目的神经元。更一般化地,局部连通神经网络204的局部连通层可被配置成使得一层中的每个神经元将具有相同或相似的连通性模式,但其连接强度可具有不同的值(例如,210、212、214和216)。局部连通的连通性模式可能在更高层中产生空间上相异的感受野,这是由于给定区域中的更高层神经元可接收到通过训练被调谐为到网络的总输入的受限部分的性质的输入。
42.局部连通神经网络的一个示例是卷积神经网络。图2c解说了卷积神经网络206的示例。卷积神经网络206可被配置成使得与针对第二层中每个神经元的输入相关联的连接强度被共享(例如,208)。卷积神经网络可能非常适合于其中输入的空间位置有意义的问题。根据本公开的各方面,卷积神经网络206可被用于执行对视频压缩和/或解压缩的一个或多个方面。
43.一种类型的卷积神经网络是深度卷积网络(dcn)。图2d解说了被设计成识别来自图像捕捉设备230(诸如车载相机)的图像226输入的视觉特征的dcn 200的详细示例。可对当前示例的dcn 200进行训练以标识交通标志以及在交通标志上提供的数字。当然,dcn 200可被训练用于其他任务,诸如标识车道标记或标识交通信号灯。
44.可以用监督式学习来训练dcn 200。在训练期间,可向dcn 200呈递图像(诸如限速标志的图像226),并且随后可计算“前向传递(forward pass)”以产生输出222。dcn 200可
包括特征提取区段和分类区段。在接收到图像226之际,卷积层232可向图像226应用卷积核(未示出),以生成第一组特征图218。作为示例,卷积层232的卷积核可以是生成28x28特征图的5x5核。在本示例中,由于在第一特征图集合218中生成四个不同的特征图,因此在卷积层232处四个不同的卷积核被应用于图像226。卷积核还可被称为过滤器或卷积过滤器。
45.第一组特征图218可由最大池化层(未示出)进行子采样以生成第二组特征图220。最大池化层减小了第一组特征图218的大小。即,第二组特征图220的大小(诸如14x14)小于第一组特征图218的大小(诸如28x28)。减小的大小向后续层提供类似的信息,同时降低存储器消耗。第二组特征图220可经由一个或多个后续卷积层(未示出)被进一步卷积,以生成后续的一组或多组特征图(未示出)。
46.在图2d的示例中,第二组特征图220被卷积以生成第一特征向量224。此外,第一特征向量224被进一步卷积以生成第二特征向量228。第二特征向量228的每个特征可包括与图像226的可能特征(诸如“标志”、“60”和“100”)相对应的数。softmax(软最大化)函数(未示出)可将第二特征向量228中的数转换为概率。如此,dcn 200的输出222是图像226包括一个或多个特征的概率。
47.在本示例中,输出222中关于“标志”和“60”的概率高于输出222的其他特征(诸如“30”、“40”、“50”、“70”、“80”、“90”和“100”)的概率。在训练之前,由dcn 200产生的输出222很可能是不正确的。由此,可计算输出222与目标输出之间的误差。目标输出是图像226的真值(例如,“标志”和“60”)。dcn 200的权重可随后被调整以使得dcn 200的输出222与目标输出更紧密地对齐。
48.为了调整权重,学习算法可为权重计算梯度向量。该梯度可指示在权重被调整情况下误差将增加或减少的量。在顶层,该梯度可直接对应于连接倒数第二层中的活化神经元与输出层中的神经元的权重的值。在较低层中,该梯度可取决于权重的值以及所计算出的较高层的误差梯度。权重可随后被调整以减小误差。这种调整权重的方式可被称为“反向传播”,因为其涉及在神经网络中的“反向传递(backward pass)”。
49.在实践中,权重的误差梯度可能是在少量示例上计算的,从而计算出的梯度近似于真实误差梯度。这种近似方法可被称为随机梯度下降法。随机梯度下降法可被重复,直到整个系统可达成的误差率已停止下降或直到误差率已达到目标水平。在学习之后,dcn可被呈递新图像并且在网络中的前向传递可产生输出222,其可被认为是该dcn的推断或预测。
50.深度置信网络(dbn)是包括多层隐藏节点的概率性模型。dbn可被用于提取训练数据集的阶层式表示。dbn可通过堆叠多层受限波尔兹曼机(rbm)来获得。rbm是一类可在输入集上学习概率分布的人工神经网络。由于rbm可在没有关于每个输入应该被分类到哪个类的信息的情况下学习概率分布,因此rbm经常被用于无监督式学习。使用混合无监督式和受监督式范式,dbn的底部rbm可按无监督方式被训练并且可以用作特征提取器,而顶部rbm可按受监督方式(在来自先前层的输入和目标类的联合分布上)被训练并且可用作分类器。
51.深度卷积网络(dcn)是卷积网络的网络,其配置有附加的池化和归一化层。dcn已在许多任务上达成现有最先进的性能。dcn可使用受监督式学习来训练,其中输入和输出目标两者对于许多典范是已知的并被用于通过使用梯度下降法来修改网络的权重。
52.dcn可以是前馈网络。另外,如上所述,从dcn的第一层中的神经元到下一更高层中的神经元群的连接跨第一层中的神经元被共享。dcn的前馈和共享连接可被利用于进行快
速处理。dcn的计算负担可比例如类似大小的包括回流或反馈连接的神经网络小得多。
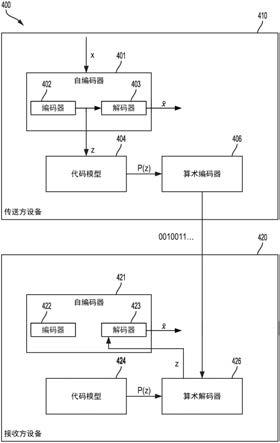
53.卷积网络的每一层的处理可被认为是空间不变模版或基础投影。如果输入首先被分解成多个通道,诸如彩色图像的红色、绿色和蓝色通道,那么在该输入上训练的卷积网络可被认为是三维的,其具有沿着该图像的轴的两个空间维度以及捕捉颜色信息的第三维度。卷积连接的输出可被认为在后续层中形成特征图,该特征图(例如,220)中的每个元素从先前层(例如,特征图218)中一定范围的神经元以及从该多个通道中的每个通道接收输入。特征图中的值可以用非线性(诸如矫正)max(0,x)进一步处理。来自毗邻神经元的值可被进一步池化(这对应于降采样)并可提供附加的局部不变性以及维度缩减。
54.图3是解说示例性深度卷积网络350的框图。深度卷积网络350可包括多个基于连通性和权重共享的不同类型的层。如图3中示出的,深度卷积网络350包括卷积块354a、354b。卷积块354a、354b中的每一者可配置有卷积层(conv)356、归一化层(lnorm)358、和最大池化层(max pool)360。
55.卷积层356可包括一个或多个卷积过滤器,其可被应用于输入数据352以生成特征图。尽管仅示出了两个卷积块354a、354b,但本公开不限于此,而是代之以可根据设计偏好将任何数目的卷积块(例如,块354a、354b)包括在深度卷积网络350中。归一化层358可对卷积过滤器的输出进行归一化。例如,归一化层358可提供白化或侧向抑制。最大池化层360可提供在空间上的降采样聚集以实现局部不变性和降维。
56.例如,深度卷积网络的并行过滤器组可被加载到soc 100的cpu 102或gpu 104上以达成高性能和低功耗。在替换实施例中,平行过滤器组可被加载到soc 100的dsp 106或isp 116上。另外,深度卷积网络350可访问其他可存在于soc 100上的处理块,诸如分别专用于传感器和导航的传感器处理器114和导航模块120。
57.深度卷积网络350还可包括一个或多个全连通层,诸如层362a(标记为“fc1”)和层362b(标记为“fc2”)。深度卷积网络350可进一步包括逻辑回归(lr)层364。深度卷积网络350的每一层356、358、360、362、364之间是要被更新的权重(未示出)。每一层(例如,356、358、360、362、364)的输出可以用作深度卷积网络350中一后续层(例如,356、358、360、362、364)的输入以从第一卷积块354a处供应的输入数据352(例如,图像、音频、视频、传感器数据和/或其他输入数据)学习阶层式特征表示。深度卷积网络350的输出是针对输入数据352的分类得分366。分类得分366可以是概率集,其中每个概率是输入数据包括来自特征集的特征的概率。
58.使用深度生成性模型的示例视频压缩
59.视频内容可被上传到视频托管服务和共享平台,并且可被传送到各种设备。录制未压缩的视频内容一般导致大的文件大小,该文件大小随所录制视频内容分辨率的增加而大大增加。例如,以1080p/24录制的未压缩16比特每通道的视频(例如,宽1920像素且高1080像素的分辨率,每秒捕获24帧)可占用12.4兆字节每帧,或即297.6兆字节每秒。以24帧每秒按4k分辨率录制的未压缩16比特每通道的视频可占用49.8兆字节每帧、或1195.2兆字节每秒。
60.因为未压缩视频内容可导致大文件,这些大文件可涉及用于物理存储的相当大的存储器和用于传输的相当大的带宽,所以可以利用技术来压缩此类视频内容。例如,考虑在无线网络上递送视频内容。预计视频内容将包括大部分消费者因特网话务,其中超过一半
的视频内容正在无线网络上(例如,经由lte、高级lte、新无线电(nr)或其他无线网络)被递送到移动设备。尽管无线网络中的可用带宽量有所进步,但仍然期望减少这些网络中用于递送视频内容的带宽量。
61.为了减少视频内容的大小——并且因此减少存储视频内容所涉及的存储量——以及在递送视频内容方面所涉及的带宽量,可以对视频内容应用各种压缩算法。常规地,可以使用先验定义的压缩算法来压缩视频内容,诸如运动图像专家组(mpeg)算法、h.264或高效率视频编码算法。这些先验定义的压缩算法可能能够保留原始视频内容中的大部分信息,并且可以基于信号处理和信息理论理念来先验定义。然而,虽然这些预定义的压缩算法可普遍适用(例如,适用于任何类型的视频内容),但这些预定义的压缩算法可能并不计及内容的相似性、视频捕获和递送的新分辨率或帧速率、非自然影像(例如,雷达影像或经由各种传感器所捕获的其他影像)等。
62.本公开的各方面提供使用深度神经网络对视频内容的压缩和解压缩。深度神经网络可以包括:(1)自编码器,其将所接收的视频内容的帧映射到隐代码空间(例如,自编码器的编码器和解码器之间的空间,在该自编码器中视频内容已被编码为代码,其也被称为潜在变量或潜在表征)和(2)概率性模型,其可以无损地压缩来自隐代码空间的代码。该概率模型一般基于经编码视频内容来生成代码集z上可以代表经编码视频的概率分布。深度神经网络还可以包括算术编码器,其基于概率分布和代码集z来生成要输出用于传输的比特流。通过使用一个或多个人工神经网络来压缩(和解压缩)视频内容,本公开的各方面可以提供可通过重新训练该(诸)人工神经网络来适应于各种用例的视频编码和编码机制。此外,本公开的各方面可以提供视频编码器和解码器的自主生成,这些视频编码器和解码器生成经压缩的视频内容,该经压缩的视频内容的比特率和/或质量逼近或超过传统的先验定义的视频压缩算法(例如,mpeg
‑
4)的视频比特率和/或质量。
63.图4解说了包括传送方设备410的系统400,传送方设备410压缩视频内容并且将经压缩的视频内容传送到接收方设备420以供在接收方设备420和/或连接到接收方设备420的视频输出设备上进行解压缩和输出。如所解说的,传送方设备410包括视频压缩流水线,而接收方设备420包括比特流解压缩流水线。根据本公开的各方面,传送方设备410中的视频压缩流水线和接收方设备420中的比特流解压缩流水线一般使用一个或多个人工神经网络来压缩视频内容和/或将接收到的比特率解压缩成视频内容。如所解说的,传送方设备410中的视频压缩流水线包括自编码器401、代码模型404和算术编码器406,而接收方设备420中的视频解压缩流水线包括自编码器421、代码模型424和算术解码器426。
64.如所解说的,自编码器401包括编码器402和解码器403。编码器402一般通过将未压缩视频内容的多个帧中的像素映射到隐代码空间来对所接收的未压缩视频内容执行有损压缩。一般而言,编码器402可被配置以使得代表经编码视频的代码是离散的或二进制的。这些代码可以基于随机扰动技术、软矢量量化或其他可以生成特异代码的技术来生成。在一些方面,自编码器401可以将未压缩的视频映射到具有可压缩(低熵)分布的代码。这些代码的交叉熵可接近于预定义或所学习的先验分布。
65.自编码器401可使用卷积架构来实现。在一些方面,自编码器401可被配置为三维卷积神经网络(cnn),以使得自编码器401学习用于将视频映射到隐代码空间的空
‑
时滤波器。在此类网络中,自编码器401可以按关键帧(例如,标记帧序列的开始的初始帧,其中该
序列中的后续帧被描述为相对于该序列中的初始帧的差)、关键帧和视频中的其他帧之间的扭曲(或差)、以及残差因子的形式来编码视频。在其他方面,自编码器401可被实现为以先前帧、帧之间的残差因子、以及通过堆叠通道来调理或包括回流层为条件的二维神经网络。
66.在一些方面,可以使用训练视频集来训练自编码器401。自编码器401中的编码器402可以获取第一训练视频(指定为x),并且将第一训练视频映射到隐代码空间中的代码z。如所讨论的,编码器402可被实现为三维卷积网络,以使得隐代码空间在每个(x,y,t)位置具有描述以该位置为中心的视频块的向量。x坐标可表示视频块中的水平像素位置,y坐标可表示视频块中的垂直像素位置,而t位置可表示视频块中的时间戳。通过使用水平像素位置、垂直像素位置和时间的三个维度,向量可以描述跨多个帧的图块。然而,在一些方面,自编码器401可以使用二维卷积网络在二维空间中映射视频的帧。自编码器401在二维空间中映射视频帧所使用的代码模型可以利用毗邻帧之间的冗余(例如,包括在相继帧中的相同的或相似的信息)。
67.解码器403可以随后解压缩代码z以获得第一训练视频的重构一般而言,重构可以是未压缩的第一训练视频的近似,并且不需要是第一训练视频x的确切副本。自编码器401可以比较x和以确定第一训练视频和经重构的第一训练视频之间的距离向量或其他差值。基于所确定的距离向量或其他差值,自编码器401可以调整所接收的视频内容(例如,在每帧的基础上)和隐代码空间之间的映射,以减少输入未压缩视频和由自编码器401作为输出所生成的经编码的视频之间的距离。自编码器401可以使用例如随机梯度下降技术来重复该过程,以最小化或以其他方式减少输入视频x和由对所生成的代码z解码所得的经重构视频之间的差。
68.代码模型404接收表示经编码视频或其部分的代码z,并且生成可被用于表示代码z的经压缩码字集上的概率分布p(z)。例如,代码模型404可以包括概率自回归生成性模型。在一些方面,可以对其生成概率分布的代码可以包括基于自适应算术编码器406来控制比特指派的所学习的分布。例如,通过使用自适应算术编码器,可以单独预测第一个z的压缩码;可以基于第一个z的压缩码来预测第二个z的压缩码;可以基于第一个z和第二个z的压缩码来预测第三个z的压缩码,依此类推。压缩代码一般代表要压缩的给定视频的不同空
‑
时组块。每个代码z
t,c,w,h
(表示由时间、通道以及水平和垂直位置索引的代码)可以基于先前代码来预测,其可以是固定的并且理论上是代码的任意排序。在一些方面,可以通过从头到尾分析给定的视频文件并且以光栅扫描次序来分析每一帧来生成代码。
69.在一些方面,z可被表示为四维张量。张量的四个维度可包括时间维度、通道维度、以及高度和宽度空间维度。在一些实施例中,通道维度可以包括不同的颜色通道(各种rgb颜色空间(诸如adobe rgb、srgb、ntsc、uhd或rec 709颜色空间)中的红色、绿色和蓝色通道)。在一些方面,这些通道可以指无线网络的数个通道(例如,64个通道、128个通道等)。
70.代码模型404可以使用概率自回归模型来学习输入代码z的概率分布。概率分布可以以其先前的值为条件并且可以由下式来表示:
71.72.其中t是从t=0处的视频开始到t=t处的视频结束之间的所有时间的时间索引,其中c是所有通道c的通道索引,其中w是总视频帧宽度w的宽度索引,并且其中h是总视频帧高度h的高度索引。
73.概率分布p(z)可以通过因果卷积的全卷积神经网络来预测。在一些方面,卷积网络的每一层的内核可被掩盖,以使得卷积网络在计算概率分布时知晓之前的值z
0:t,0:c,0:w,0:h
,并且可能不知晓其他值。在一些方面,卷积网络的最末层可以包括softmax函数,该函数确定隐空间中的代码适用于输入值的概率(例如,给定代码可被用于压缩给定输入的可能性)。在训练代码模型404时,softmax函数可以使用独热(one
‑
hot)向量,而在测试时,代码模型404可以选择与最高概率相关联的代码。
74.在一些方面,代码模型404可以使用四维卷积来实现(例如,以使得
[0075][0076]
以此方式来使用四维卷积可能在计算上很昂贵,部分原因在于要计算的参数数目。为了加速概率分布的生成,可以使用不同的依赖性因子分解,如下所示:
[0077][0078]
使用该因子分解,代码模型404被实现为以时间为条件的三维卷积模型。因子分解可以检查给定时间t处的先前代码以及与直到时间t的代码相关联的调理信号可以通过将来自先前时步的代码(例如,z
t:t
‑
1,0:c,0:w,0:w
)传递通过卷积长短期记忆(lstm)层集合来获取调理信号
[0079]
算术编码器406使用由代码模型404所生成的概率分布p(z),并且输出对应于代码z的预测的比特流。代码z的预测可被表示为在可能代码集上生成的概率分布p(z)中具有最高概率得分的代码。在一些方面,算术编码器406可以基于对代码z的预测和由自编码器401所生成的实际代码z的准确度来输出可变长度的比特流。例如,如果预测准确,则比特流可对应于短码字,而随着代码z与对代码z的预测之间的差的幅值增大,比特流可对应于较长的码字。比特流可由算术编码器406输出以供存储在经压缩视频文件中、传送到请求方设备(例如,如图4中所解说的接收方设备420)等等。一般而言,算术编码器406输出的比特流可以无损地编码z,以使得可以在应用于经压缩视频文件上的解压缩过程期间准确地恢复z。
[0080]
在接收方设备420处,由算术编码器406生成并且从传送方设备410传送的比特流可被接收方设备420接收。传送方设备410和接收方设备420之间的传输可以经由各种合适的有线或无线通信技术中的任一者发生。传送方设备410和接收方设备420之间的通信可以是直接的或者可以通过一个或多个网络基础设施组件(例如,基站、中继站、移动站、网络中枢等)来执行。
[0081]
如所解说的,接收方设备420可以包括算术解码器426、代码模型424和自编码器421。自编码器421可以包括编码器422和解码器423,并且可以使用与用于训练自编码器401相同或不同的训练数据集来训练,以使得解码器423对于给定输入可以产生与解码器403相同的或至少类似的输出。虽然自编码器421被解说为包括编码器422,但在解码过程期间不需要使用编码器422从代码z(接收自传送方设备410)获取(例如,在传送方设备410处被压缩的原始视频x的近似)。
[0082]
所接收的比特流可被输入到算术解码器426以从该比特流中获取一个或多个代码
z。如所解说的,算术解码器426可以基于由代码模型424在可能代码集上所生成的概率分布p(z)和将每个所生成的代码z与比特流相关联的信息来提取经解压缩的代码z。更具体地,给定比特流的收到部分和下一代码z的概率预测,算术解码器426可以产生新代码z,因为它是由传送方设备410处的算术编码器406来编码的。使用新代码z,算术解码器426可以对相继代码z进行概率预测,读取比特流的附加部分,并且解码相继代码z直到整个收到比特流被解码。经解压缩的代码z可被提供给自编码器421中的解码器423,其将代码z解压缩并且输出视频内容x的近似接收方设备420处对视频内容x的近似可被恢复并且被显示在与接收方设备420通信地耦合或集成的屏幕上。
[0083]
图5解说了根据本文所描述的各方面的用于在深度神经网络中压缩视频内容的示例操作500。操作500可由具有实现深度神经网络的一个或多个处理器(例如,cpu、dsp、gpu等)的系统来执行。例如,该系统可以是传送方设备410。
[0084]
如所解说的,操作500开始于框502,在框502,该系统接收供压缩的视频内容。例如,该视频内容可以包括未压缩视频内容,该未压缩视频内容包括具有给定高度和宽度并且与给定帧速率相关联的数个帧。
[0085]
在框504,系统通过自编码器将所接收的视频内容编码到隐代码空间中。如所讨论的,将所接收的未压缩视频内容x编码到隐代码空间可以导致一个或多个代码z的生成,以使得对该一个或多个代码z的解码结果得到对未压缩视频x的近似
[0086]
在框506,该系统通过概率模型来生成经编码视频的经压缩版本。如所讨论的,可以基于能用于压缩经编码视频z的代码的概率分布来生成经编码视频的经压缩版本,其中较高概率的代码具有较短的码字,而较低概率的代码具有较长的码字。
[0087]
在框508,该系统输出经编码视频的经压缩版本以供传输。经压缩版本可被输出以供传输至与该系统相同或不同的设备。例如,经压缩版本可被输出以供传输至存储设备(例如,本地存储或远程存储)、远程服务(例如,视频托管服务)、请求方设备(例如,接收方设备420)等等。
[0088]
根据某些方面,自编码器是通过以下操作来训练的:接收第一视频内容;将第一视频内容编码到隐代码空间中;通过解码经编码第一视频内容来生成第一视频内容的经重构版本;将第一视频内容的经重构版本与所接收的第一视频内容进行比较;以及基于该比较来调整自编码器。对于某些方面,调整自编码器涉及执行梯度下降。
[0089]
根据某些方面,自编码器被配置成将所接收的视频内容编码到隐代码空间中。将所接收的视频内容编码到隐代码空间中可以基于三维滤波器。三维滤波器的维度可包括视频帧的高度、视频帧的宽度和视频帧的时间。
[0090]
根据某些方面,经训练的概率模型包括四维张量上的概率分布的自回归模型。概率分布一般解说不同代码可被用于压缩经编码视频内容的可能性。对于某些方面,概率模型基于四维张量来生成数据。在此情形中,四维张量的维度可以包括例如视频内容的时间、通道和空间维度。对于某些方面,概率分布是基于依赖性的因子分解来生成的。在此情形中,依赖性的因子分解可以表示基于与视频内容中的当前时间片和调理信号相关联的代码的概率分布。例如,调理信号可以包括由递归神经网络针对与视频内容中除当前时间片之外的先前时间片相关联的代码的输入所生成的输出。对于某些方面,递归神经网络包括卷
积长短期记忆(lstm)层集。
[0091]
使用深度生成性模型的示例视频解压缩
[0092]
图6解说了根据本文中所描述的各方面的用于在深度神经网络中将经编码视频(例如,所接收的比特流)解压缩为视频内容的示例操作600。操作600可由具有实现深度神经网络的一个或多个处理器(例如,cpu、dsp、gpu等)的系统来执行。例如,该系统可以是接收方设备420。
[0093]
如所解说的,操作600开始于框602,在此,该系统(例如,从传送方设备)接收经编码视频内容的经压缩版本。经编码视频内容的经压缩版本可以例如作为包括一个或多个码字的比特流来接收,该一个或多个码字对应于代表经压缩视频或其部分的一个或多个代码z。
[0094]
在框604,该系统基于概率模型来将经编码视频内容的经解压缩版本生成到隐代码空间中。该系统可以基于可能已被用于压缩经编码视频的代码的概率分布来标识与所接收的经编码视频内容的经压缩版本相对应的一个或多个代码z。在一些情形中,该系统可以基于每个码字的长度来标识一个或多个代码,其中较高概率的代码具有较短的码字,而较低概率的代码具有较长的码字。
[0095]
在框606,该系统使用自编码器从隐代码空间中解码出经编码视频内容的经解压缩版本。如所讨论的,可以训练自编码器以使得对经编码视频的经解压缩版本中该一个或多个代码z的解码结果得到代表未压缩视频x的近似每个代码z可以代表隐代码空间的一部分,从该部分可以生成代表未压缩视频x的近似
[0096]
在框608,该系统输出经解码视频内容以供回放。该系统可以输出经解码视频内容以供在与该系统通信地耦合的或集成的一个或多个显示设备上回放。
[0097]
根据某些方面,自编码器是通过以下操作来训练的:接收第一视频内容;将第一视频内容编码到隐代码空间中;通过解码经编码第一视频内容来生成第一视频内容的经重构版本;将第一视频内容的经重构版本与所接收的第一视频内容进行比较;以及基于该比较来调整自编码器。
[0098]
根据某些方面,自编码器被配置成从隐代码空间解码出经编码视频内容。从隐代码空间解码出所接收的视频内容可以基于三维滤波器。三维滤波器的维度可包括视频帧的高度、视频帧的宽度和视频帧的时间。
[0099]
根据某些方面,该概率模型包括四维张量上的概率分布的自回归模型。概率分布一般解说不同代码可被用于解压缩经编码视频内容的可能性。对于某些方面,概率模型基于四维张量来生成数据。在此情形中,四维张量的维度可以包括例如视频内容的时间、通道和空间维度。对于某些方面,概率分布是基于对依赖性的因子分解来生成的。在此情形中,对依赖性的因子分解可以代表基于与视频内容中的当前时间片和调理信号相关联的代码的概率分布。对于某些方面,调理信号包括由递归神经网络针对与视频内容中除当前时间片之外的先前时间片相关联的代码的输入所生成的输出。递归神经网络可包括卷积长短期记忆(lstm)层集。
[0100]
图7是解说可使人工智能(ai)功能模块化的示例性软件架构700的框图。根据本公开的各方面,使用架构700,应用可被设计成可使得soc 720的各种处理块(例如,cpu 722、
dsp 724、gpu 726和/或npu 728)支持使用深度生成性模型的视频压缩和/或解压缩。
[0101]
ai应用702可被配置成调用在用户空间704中定义的功能,这些功能可例如使用深度生成性模型来压缩和/或解压缩视频信号(或其经编码版本)。例如,ai应用702可以取决于所识别的场景是办公室、演讲厅、餐厅、还是诸如湖泊之类的室外环境来不同地配置话筒和相机。ai应用702可以作出编译与在ai功能应用编程接口(api)706中定义的库相关联的程序代码的请求。该请求可最终依赖于被配置成基于例如视频和定位数据来提供推断响应的深度神经网络的输出。
[0102]
运行时引擎708(其可以是运行时框架的经编译代码)可进一步可由ai应用702访问。例如,ai应用702可使得运行时引擎按特定时间区间或由应用的用户接口检测到的事件触发地来请求推断。在使得运行时引擎提供推断响应时,运行时引擎可进而将信号发送到在soc 720上运行的操作系统(os)空间710(诸如linux内核712)中的操作系统。操作系统进而可使得要在cpu722、dsp 724、gpu 726、npu 728、或其某种组合上执行使用深度生成性模型的视频压缩和/或解压缩。cpu 722可由操作系统直接访问,而其他处理块可通过驱动器(诸如分别用于dsp 724、gpu 726、或npu 728的驱动器714、716或718)来访问。在示例性示例中,深度神经网络可被配置成在处理块(诸如cpu 722、dsp 724和gpu 726)的组合上运行,或可在npu 728上运行。
[0103]
结合本文中所描述的各方面所描述的各种解说性电路可以在集成电路(ic)(诸如,处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其他可编程逻辑设备)中实现或与其实现。处理器可以是微处理器,但在替换方案中,处理器可以是任何常规处理器、控制器、微控制器或状态机。处理器还可以被实现为计算设备的组合,例如,dsp与微处理器的组合、多个微处理器、与dsp核心协同的一个或多个微处理器、或任何其他此类配置。
[0104]
还注意到,本文任何示例性方面中所描述的操作步骤是为了提供示例而被描述的。所描述的操作可按除了所解说的顺序之外的众多不同顺序来执行。此外,在单个操作步骤中描述的操作实际上可在多个不同步骤中执行。另外,可组合示例性方面中讨论的一个或多个操作步骤。将理解,如对本领域技术人员将显而易见的,可对在流程图中解说的操作步骤进行众多不同的修改。将理解,如对本领域技术人员将显而易见地,在流程图中解说的操作步骤可进行众多不同的修改。例如,贯穿上面说明始终可能被述及的数据、指令、命令、信息、信号、比特、码元和码片可由电压、电流、电磁波、磁场或磁粒子、光场或光粒子、或其任何组合来表示。
[0105]
如本文中所使用的,引述一列项目中的“至少一者”的短语是指这些项目的任何组合,包括单个成员。作为示例,“a、b或c中的至少一者”旨在涵盖:a、b、c、a
‑
b、a
‑
c、b
‑
c、和a
‑
b
‑
c,以及具有多重相同元素的任何组合(例如,a
‑
a、a
‑
a
‑
a、a
‑
a
‑
b、a
‑
a
‑
c、a
‑
b
‑
b、a
‑
c
‑
c、b
‑
b、b
‑
b
‑
b、b
‑
b
‑
c、c
‑
c、和c
‑
c
‑
c,或者a、b和c的任何其他排序)。
[0106]
提供本公开是为使得本领域任何技术人员能够制作或使用本公开的各方面。对本公开的各种修改对本领域技术人员而言将容易是显而易见的,并且本文中所定义的普适原理可被应用到其他变型而不会脱离本公开的精神或范围。由此,本公开并非旨在被限定于本文中所描述的示例和设计,而是应被授予与本文中所公开的原理和新颖特征一致的最广义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。