1.本发明涉及社区数据备份技术领域,特别涉及一种基于路由设备的社区数据备份系统。
背景技术:
2.目前,随着物联网技术的发展,智慧社区和智能社区一直在进行普及,而且普及率越来越高。在新型数字化社区中,数据是最重要的社区资料。所以如何保持数据的全面性,保持数据实时更新,在数据缺失的时候能够从备份数据中找到缺失数据是最重要的,因此,数据备份是非常重要的。现有技术中,数据的备份是通过数据库进行数据划分,划分后一般是全面的进行备份或者增量备份,只能采取单方式备份,如果是全量备份,极大的占用了数据的存储资源;如果是增量备份,那么可能导致关键数据在增量备份的时候,可能存在数据重复或者数据完整性出现问题,使得数据缺失。
技术实现要素:
3.本发明提供一种基于路由设备的社区数据备份系统,用以解决现有技术中,数据的备份是通过数据库进行数据划分,划分后一般是全面的进行备份或者增量备份,只能采取单方式备份,极大的占用了数据的存储资源的情况。
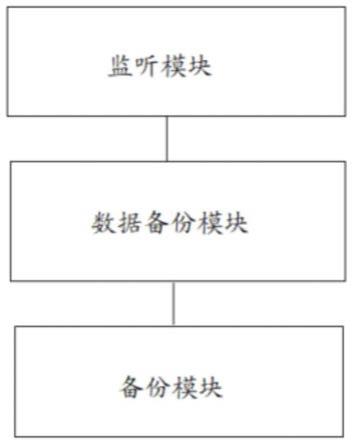
4.一种基于路由设备的社区数据备份系统,包括:
5.监听模块:用于在社区的路由设备中内置数据监听程序,对经过路由设备并授权监听的社区数据进行监听,并生成监听信息;
6.数据判断模块:用于对所述监听信息进行类型划分,并判断每类数据的重要性;
7.备份模块:根据所述重要性,确定每类数据的备份方式,并基于所述备份方式对监听的数据进行备份;其中,
8.所述备份方式包括:增量备份和全量备份。
9.优选的:所述监听模块包括:
10.程序设置单元:用于确定社区内业务路由设备,并在所述业务路由设备上进行安装数据监听程序;
11.授权单元:用于通过后台,预先设置可监听数据的数据类型,并对可监听数据进行监听授权;
12.信息整理单元:用于在监听授权后,确定数据类型,并确定对应的数据判别方式,生成监听信息;其中,
13.所述监听信息包括:数据类型、数据对象、数据属性和历史相关数据状态。
14.优选的:所述监听模块还包括:
15.业主管理层:用于对业主的个人设备进行统计,并生成业设备信息;
16.运维管理层;用于对社区内的硬件设备数据进行提取,并生成设备信息;
17.系统管理层:用于对系统内的运行数据和基础数据进行管理,生成系统信息;
18.逻辑管理层:用于对系统内不同的执行逻辑进行管理,生成执行信息。
19.优选的:所述监听模块还包括:
20.平面地理单元:用于搭建智慧社区的平面地图,并在所述平面地图上标记每个路由设备的位置信息;
21.高程数据单元:用于根据所述位置信息,建立智慧社区的数字高程模型;
22.纹理标记单元:用于在所述数字高程模型中进行纹理标记,建立数字纹理;
23.影像单元:用于在数字纹理生成后,构成社区三维建筑物和环境实体影像;
24.三维显示单元:用于在所述社区三维建筑物和环境实体影像上进行数据流动标注;
25.信息生成单元:用于在所述监听信息生成时,对每份监听信息中数据产生的设备进行标记。
26.优选的:所述数据判断模块包括:
27.数据处理单元:用于通过预设的数据字典,对所述监听信息进行识别处理,确定监听信息的信息内容;其中,
28.所述信息内容包括:数据类型、数据产生设备、数据内容权重、数据范围、数据留存度、数据功能性、数据需求、数据可替代性和原始数据重要性;
29.判断单元:用于根据所述信息内容,确定不同设备产生的数据的数据类型,并通过预设规则,对通过路由设备的数据进行重要性计算,确定重要性值;
30.评估单元:用于根据所述重要性值,对通过路由设备的数据进行期望评估,确定数据评估值。
31.优选的:所述判断单元,确定数据重要性包括如下步骤:
32.步骤1:根据所述信息内容,通过下式确定建立数据的评估模型:
[0033][0034]
其中,a表示数据重要性评估值;d
ic
表示第i份信息内容对应的数据为第c类型时的特征参数;p
ik
表示第i份信息内容对应的数据为第k个数据产生设备的目标参数;a表示数据的预期参数;b表示数据判断系数;d表示数据重要性评估阈值;i=1,2,3
……
n;n表示数据的总份量;k=1,2,3
……
s;s表示数据产生设备的总数量;
[0035]
步骤2:根据所述评估模型,引入预设的判定参数模型,确定重要程度:
[0036][0037]
其中,x表示重要程度;z
i
第i份信息内容对应的数据内容权重;w
i
第i份信息内容对应的数据范围;q
i
第i份信息内容对应的社区数据的数据留存度;ρ
i
第i份信息内容对应的社区数据的数据功能性参数;表示第i份信息内容对应的数据在原始数据重要性为ε情况
下的数据可替代性;e
j
表示第i份信息内容对应的社区数据的数据需求参数;
[0038]
优选的:所述备份模块包括:
[0039]
模式确定单元:用于根据所述数据重要性,建立分布式数据备份数据库,确定数据的备份方式;
[0040]
数据库搭建单元:用于根据所述数据类型,判断数据的关联性,并建立并立型分布式数据库;其中,
[0041]
所述并立型分布式数据库包括:增量分布式数据库和全量分布式数据库;
[0042]
增量备份单元:用于在数据属于增量备份时,将所述数据存储至增量分布式数据库;
[0043]
全量备份单元:用于在数据属于全量备份时,将所述数据存储至全量分布式数据库;
[0044]
数据可视化单元:用于根据所述数据类型,确定不同类型的可视化工具,并基于所述可视化工具,确定可视化信息;其中,
[0045]
所述可视化信息包括:可视化图片、可视化图表和可视化文本。
[0046]
优选的:所述备份模块建立并立型分布式数据库包括如下步骤:
[0047]
步骤s1:基于数据树模型,建立对称分布的树形数据库;其中,
[0048]
所述树形数据库一侧为增量分布式数据库,一侧为全量分布式数据库;
[0049]
步骤s2:根据所述树形数据库,建立子数据库;其中,
[0050]
所述子数据库包括设备子数据库、网格子数据库、区域子数据库、建筑物信息子数据库、房屋信息子数据库、住户信息子数据库、物业信息子数据库、运维子数据库;
[0051]
步骤s3:将所述子数据库按照数据关联性对称排布在树形数据库上。
[0052]
优选的:所述数据可视化单元包括:
[0053]
数据源层:用于根据所述并立型分布式数据库,确定监听的数据,并确定监听的数据的产生设备;
[0054]
可视化分类层:用于根据所述监听的数据的产生设备,对所述监听的数据进行分类,确定分类数据;其中,
[0055]
所述分类数据包括:图像数据、文本数据和离散数据;
[0056]
可视化表达层:用于将所述分类数据,确定基于数据映射的可视化工具,并基于所述可视化工具,进行分类数据的实时映射,生成动态的可视化信息;其中,
[0057]
所述可视化工具包括:文本映射模板、图像映射模板和图表映射模板。
[0058]
优选的:所述数据可视化单元生成可视化信息还包括如下步骤:
[0059]
步骤s1:基于所述并立型分布式数据库,确定数据特征:
[0060][0061]
其中,a
l
表示全量分布式数据库中第l份数据的内容参数;b
j
表示增量分布式数据
库中第j份数据的内容参数;l=1,2,3
……
l;l表示全量分布式数据库中数据总份数;j=1,2,3
……
m;m表示增量分布式数据库中数据总份数;q
l
表示全量分布式数据库中第l份数据的数据特征;q
j
表示增量分布式数据库中第j份数据的数据特征;
[0062]
步骤s2:根据所述数据特征,构建基于聚类算法的数据类型划分模型,确定不同数据的隶属度:
[0063][0064][0065]
其中,ψ(q
l
)表示全量分布式数据库中第l份数据的图像隶属度;ξ(q
l
)表示全量分布式数据库中第l份数据的文本隶属度;ζ(q
l
)表示全量分布式数据库中第l份数据的图表隶属度;f(q
l
)表示全量分布式数据库中第l份数据的聚类函数;表示图像归属系数;σ表示文本归属系数;表示图表归属系数;g(q
l
)表示全量分布式数据库中第l份数据的归一化函数;ψ(q
j
)表示增量分布式数据库中第j份数据的图像隶属度;ξ(q
j
)表示增量分布式数据库中第j份数据的文本隶属度;ζ(q
j
)表示增量分布式数据库中第j份数据的图表隶属度;f(q
j
)表示增量分布式数据库中第j份数据的聚类函数;表示图像归属系数;g(q
j
)表示增量分布式数据库中第j份数据的归一化函数;
[0066]
步骤s3:确定并立型分布式数据库中每份数据的最大隶属度,导入对应隶属类型
的可视化工具,生成可视化数据。
[0067]
本发明有益效果在于:本发明可以对数据的重要程度进行划分,对于不重要的数据,只备份增量数据,主要是确定设备的实时情况。对于重要设备的数据例如消防安全的设备,进行数据全量备份有利于防止社区出现不安全事故。而且数据的备份,是自动备份,备份日志和备份方式自动选择,而且能够数据可视化。
[0068]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
[0069]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0070]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0071]
图1为本发明实施例中一种基于路由设备的社区数据备份系统的系统组成图;
[0072]
图2为本发明实施例中一种基于路由设备的社区数据备份系统的监听模块层级图;
[0073]
图3为本发明实施例中一种基于路由设备的社区数据备份系统的并立型分布式数据树形图。
具体实施方式
[0074]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0075]
如附图1所示,本发明为一种基于路由设备的社区数据备份系统,包括:
[0076]
监听模块:用于在社区的路由设备中内置数据监听程序,对经过路由设备并授权监听的社区数据进行监听,并生成监听信息;
[0077]
本发明的技术方案中,是通过在路由设备中设置数据监听程序,进而判断经过路由设备的数据的信息,这种方式,可以通过外监测识别的方式对社区内的各种数据进行清楚分析和分类,以及数据状况的监控。
[0078]
数据判断模块:用于对所述监听信息进行类型划分,并判断每类数据的重要性;类型划分,是对社区数据进行按照类型划分,并计算每类数据的重要性。
[0079]
备份模块:根据所述重要性,确定每类数据的备份方式,并基于所述备份方式对监听的数据进行备份;其中,
[0080]
所述备份方式包括:增量备份和全量备份。
[0081]
上述技术方案的原理在于:本发明通过在路由设备中设置监听程序,然后通过监听程序,对数据的信息进行提取,但是只提取数据的信息,不直接提取数据。然后根据监听信息,判断数据的重要性,根据数据的重要性对数据分别通过不同的方式进行备份;本发明中对于数据重要性的判断主要是基于设备产生的数据的特性,这些特性通过监听得到。
[0082]
上述技术方案的有益效果在于:本发明可以对数据的进行划分,判断数据的重要性,然后根据重要性对数据进行备份,对于不重要的数据,只备份增量数据;对于需要连续
提取的数据,例如视频监控数据和对于增量备份的数据和全量备份的数据,根据实际设备的实时情况确定。对于重要设备的数据例如消防安全的设备,进行数据全量备份有利于防止社区出现不安全事故。而且数据的备份,是自动备份,而且能够数据可视化。
[0083]
作为本发明的一种实施例:所述监听模块包括:
[0084]
程序设置单元:用于确定社区内业务路由设备,并在所述业务路由设备上进行安装数据监听程序;
[0085]
授权单元:用于通过后台,预先设置可监听数据的数据类型,并对可监听数据进行监听授权;
[0086]
信息整理单元:用于在监听授权后,确定数据类型,并确定对应的数据判别方式,生成监听信息;其中,
[0087]
所述监听信息包括:数据类型、数据对象、数据属性和历史相关数据状态。
[0088]
上述技术方案的原理在于:本发明因为需要在社区内部的路由设备设置监听程序,所以会先行确定社区内存在执行业务的路由设备,然后在这些执行业务的路由设备上进行安装监听程序。授权单元主要是用于在监听程序的后台设置可以监听的数据,因为,存在一些数据属于个人隐私的交流数据等,或者就是社区内业主的身份信息等,身份信息等就需要授权后才可以进行监听。对于授权可以监听的数据,本发明设置对应的数据判别方式,然后进行监听。
[0089]
上述技术方案的有益效果在于:本发明用于路由设备设置监听程序,对可以监听的数据的数据类型进行设置,在授权后进行数据监听,保证用户的隐私权。
[0090]
作为本发明的一种实施例:如附图2所示,所述监听模块还包括:
[0091]
业主管理层:用于对业主的个人设备进行统计,并生成业务设备信息;
[0092]
运维管理层;用于对社区内的硬件设备数据进行提取,并生成设备信息;
[0093]
系统管理层:用于对系统内的运行数据和基础数据进行管理,生成系统信息;
[0094]
逻辑管理层:用于对系统内不同的执行逻辑进行管理,生成执行信息。
[0095]
上述技术方案的原理在于:本发明的监听模块包括三个运行层,业主管理层是为了对业主的个人设备信息进行提取,判断哪些是业主自己的设备,这是为了不对业主设备进行数据监听,这数据属于业主的私有信息。而对于社区内公共设备,例如电梯数据和消防数据等,这类数据属于公共数据才会进行监听,主要是为了维护社区安全。运维管理层,就是确定社区内公共使用的硬件设备,并会提取这些设备的数据,而进行监听的就是这些数据。系统管理层,是为了确定社区内部存在哪些系统,例如:消防系统、楼宇监控系统,会对这些系统的数据进行管理。而逻辑管理层是为了判断不同系统内的执行逻辑,并对执行逻辑进行管理。
[0096]
上述技术方案的有益效果在于:为了实现对社区数据和设备等数据的监听,本发明将这个备份系统划分为多层,根据每层生成不同的层次信息,实现社区的全面监听。
[0097]
作为本发明的一种实施例:所述监听模块还包括:
[0098]
平面地理单元:用于搭建智慧社区的平面地图,并在所述平面地图上标记每个路由设备的位置信息;例如:通过高程数字地图显示整个社区。
[0099]
高程数据单元:用于根据所述位置信息,建立智慧社区的数字高程模型;
[0100]
纹理标记单元:用于在所述数字高程模型中进行纹理标记,建立数字纹理;文理标
记包含不同楼层的高低和地理位置的高低等。
[0101]
影像单元:用于在数字纹理生成后,构成社区三维建筑物和环境实体影像;实体影像是为了实现社区监控。
[0102]
三维显示单元:用于在所述社区三维建筑物和环境实体影像上进行数据流动标注;数据传输的标记,例如:火灾数据从任意一个楼层传输到物业。
[0103]
信息生成单元:用于在所述监听信息生成时,对每份监听信息中数据产生的设备进行标记。
[0104]
上述技术方案的原理在于:本发明在进行监听的时候会构建社区地图,标记每个路由设备的位置信息。高程数据单元是为了将小区地形进行数字化模拟,进而可以实现社区内部数据的纹理标记,这个纹理标记基于小区内建筑物产生的数据量,数据量高的化,就可以将生成纹理标记。进而判断小区内部的数据传输状况。影像单元是为了基于建筑物的模型,确定建筑物产生数据的状况实现数据的流动性标注,确定监听的数据的走向,数据的走向也是数据重要性判断的标准之一,其可以确定数据的产生设备和数据的接收设备。
[0105]
上述技术方案的有益效果在于:构建社区的平面地图,是为了判断路由设备是不是正常,是不是完整,是不是正在进行监听等。基于数字高程模型,实现监听数据的立体化、可视化。
[0106]
作为本发明的一种实施例:所述数据判断模块包括:
[0107]
数据处理单元:用于通过预设的数据字典,对所述监听信息进行识别处理,确定监听信息的信息内容;其中,
[0108]
所述信息内容包括:数据类型、数据产生设备、数据内容权重、数据范围、数据留存度、数据功能性、数据需求、数据可替代性和原始数据重要性;
[0109]
判断单元:用于根据所述信息内容,确定不同设备产生的数据的数据类型,并通过预设规则,对通过路由设备的数据进行重要性计算,确定重要性值;
[0110]
评估单元:用于根据所述重要性值,对通过路由设备的数据进行期望评估,确定数据评估值。
[0111]
上述技术方案的原理在于:在进行数据处理的时候本发明基于数据字典,即,数据的识别字典,其可以识别监听的信息的信息内容,也可以控制监听程序监听需要的信息内容。在进行重要性计算的过程中,本发明根据数据类型和预设规则实现重要性计算。数据类型可以确定数据属于那一类,进而确定对应的数据产生设备。而预设规则,属于计算规则,这个计算规则因为是预先设置,所以会以数据类型为主要的判断因素,这个数据类型不是数据的格式类型,而是数据产生的设备的类型,基于设备判断数据是不是重要。当然,也需要其他因素,例如数据内容权重,数据留存,数据功能和数据需求等进行参数化,进行综合计算;在实际实施的时候,会通过将监听信息的信息内容分别设置其相对于社区数据中总体数据的权重,进而通过权重的均值计算,然后设定一定的权重阀值,判断数据是否重要。而最后的期望评估,是为了判断每个数据在重要性确定之后,对数据进行期望评估,期望是备份的评估,主要是要判断数据存储去要多少内存。
[0112]
作为本发明的一种实施例:所述判断单元,确定数据重要性包括如下步骤:
[0113]
步骤1:根据所述信息内容,通过下式确定建立数据的评估模型:
[0114][0115]
其中,a表示数据重要性评估值;d
ic
表示第i份信息内容对应的数据为第c类型时的特征参数;d
ij
表示第i份信息内容对应的数据内容权重为j时的特征参数;p
ik
表示第i份信息内容对应的数据为第k个数据产生设备的目标参数;a表示数据的预期参数;b表示数据判断系数;d表示数据重要性评估阀值;i=1,2,3
……
n;n表示数据的总份量;k=1,2,3
……
s;s表示数据产生设备的总数量;
[0116]
步骤2:根据所述评估模型,引入预设的判定参数模型,确定重要程度:
[0117][0118]
其中,x表示重要程度;z
i
第i份信息内容对应的数据内容权重;w
i
第i份信息内容对应的数据范围;q
i
第i份信息内容对应的社区数据的数据留存度;ρ
i
第i份信息内容对应的社区数据的数据功能性参数;表示第i份信息内容对应的数据在原始数据重要性为ε情况下的数据可替代性;e
ij
表示第i份信息内容权重为j时的数据功能参数。
[0119]
上述技术方案的原理在于:本发明在步骤1中建立数据的评估模型,主要是对数据的重要性进行评估,ad
ic
p
ik
是为了去判断任意一份信息内容在设定权重的请胯下的数据重要性的第一评估值;ad
ij
p
ik
[1
‑
a]b∏[1
‑
d]是为了计算预期情况下数据的重要性的第二评估值。然后通过两个评估值之和,确定重要性的综合评估值。在步骤2中,本发明在数据综合评估值确定之后,会通过监听信息中信息内容来判断数据的重要性在这个过程中,本发明引入数据内容权重、数据范围的范围参数;数据留存度(数据在社区总体数据中的留存状况)数据功能性参数,数据可替代性,去确定数据的重要性值。
[0120]
上述技术方案的有益效果在于:本发明通过先评估后带入数据的特性参数对数据的重要性进行计算,能够清楚的确定每份数据的重要性,进而判断数据是不是应该进行存储。
[0121]
作为本发明的一种实施例:所述备份模块包括:
[0122]
模式确定单元:用于根据所述数据重要性,建立分布式数据备份数据库,确定数据的备份方式;
[0123]
数据库搭建单元:用于根据所述数据类型,判断数据的关联性,并建立并立型分布式数据库;其中,
[0124]
所述并立型分布式数据库包括:增量分布式数据库和全量分布式数据库;
[0125]
增量备份单元:用于在数据属于增量备份时,将所述数据存储至增量分布式数据库;
[0126]
全量备份单元:用于在数据属于全量备份时,将所述数据存储至全量分布式数据库;
[0127]
数据可视化单元:用于根据所述数据类型,将数据进行线性化,生成线性线段,并基于所述线性线段的相关性进行曲线相关进行聚类可视化。
[0128]
上述技术方案的原理在于:本发明在进行数据备份的时候会建立分布式的数据备份数据库,本发明在进行数据库搭建的时候,判断数据的关联性,这个关联性是数据和增量备份数据的关联性或者数据和全量数据的关联性,进而建立并立式分布式数据库。最后本发明通过增量备份数据库和全量备份数据库进行数据备份。数据可视化单元是为了实现数据可视化,因为社区数据在进行可视化的时候更加便于社区居民的对社区的了解和信息想社区居民的及时传输。
[0129]
上述技术方案的有益效果在于:本发明是社区数据,社区数据属于空间数据更加适合分布式存储。本发明建立的并立型分布式数据库,解决了只能全量备份和增量备份的缺点。而最后的可是化单元是为了便于社区居民知道社区数据。
[0130]
作为本发明的一种实施例:如附图3所示,所述备份模块建立并立型分布式数据库包括如下步骤:
[0131]
步骤s1:基于数据树模型,建立对称分布的树形数据库;其中,
[0132]
所述树形数据库一侧为增量分布式数据库,一侧为全量分布式数据库;
[0133]
步骤s2:根据所述树形数据库,建立子数据库;其中,
[0134]
所述子数据库包括设备子数据库、网格子数据库、区域子数据库、建筑物信息子数据库、房屋信息子数据库、住户信息子数据库、物业信息子数据库、运维子数据库;
[0135]
步骤s3:将所述子数据库按照数据关联性对称排布在树形数据库上。
[0136]
上述技术方案的原理和有益效果在于:本发明建立并立型分布式数据库包括三个步骤,首先是基于数据树的模型搭建。实现并立数据的构建。然后通过建立子数据库,相当于为不同设备建立不同数据库。然后进行属性排布,也符合分布式数据库的方式。但是本发明因为是进行数据搭建,数据库之间可以不相关,所以搭建树形分布式数据库。
[0137]
所述数据可视化单元包括:
[0138]
数据源层:用于根据所述并立型分布式数据库,确定监听的数据,并确定监听的数据的产生设备;
[0139]
可视化分类层:用于根据所述监听的数据的产生设备,对所述监听的数据进行分类,确定分类数据;其中,
[0140]
所述分类数据包括:图像数据、文本数据和离散数据;
[0141]
可视化表达层:用于将所述分类数据,确定基于数据映射的可视化工具,并基于所述可视化工具,进行分类数据的实时映射,生成动态的可视化信息;其中,
[0142]
所述可视化工具包括:文本映射模板、图像映射模板和图表映射模板。
[0143]
上述技术方案的原理和有益效果在于:本发明的数据可视化单元在进行数据可视化的过程中,本发明也采用了分层可是画的方式,分别为确定数据源,数据可视化分类,这个分类是将数据划分为图像、文本和离散三类能够进行可视化的数据。最后将不同类型的数据通过预设的可视化工具进行数据映射,确定可视化信息。
[0144]
作为本发明的一种实施例:
[0145]
所述数据可视化单元生成可视化信息还包括如下步骤:
[0146]
步骤s1:基于所述并立型分布式数据库,确定数据特征:
[0147][0148]
其中,a
l
表示全量分布式数据库中第l份数据的内容参数;b
j
表示增量分布式数据库中第j份数据的内容参数;l=1,2,3
……
l;l表示全量分布式数据库中数据总份数;j=1,2,3
……
m;m表示增量分布式数据库中数据总份数;q
l
表示全量分布式数据库中第l份数据的数据特征;q
j
表示增量分布式数据库中第j份数据的数据特征;
[0149]
步骤s2:根据所述数据特征,构建基于聚类算法的数据类型划分模型,确定不同数据的隶属度:
[0150][0151][0152]
其中,ψ(q
l
)表示全量分布式数据库中第l份数据的图像隶属度;ξ(q
l
)表示全量分布式数据库中第l份数据的文本隶属度;ζ(q
l
)表示全量分布式数据库中第l份数据的图表
隶属度;f(q
l
)表示全量分布式数据库中第l份数据的聚类函数;表示图像归属系数;σ表示文本归属系数;表示图表归属系数;g(q
l
)表示全量分布式数据库中第l份数据的归一化函数;ψ(q
j
)表示增量分布式数据库中第j份数据的图像隶属度;ξ(q
j
)表示增量分布式数据库中第j份数据的文本隶属度;ζ(q
j
)表示增量分布式数据库中第j份数据的图表隶属度;f(q
j
)表示增量分布式数据库中第j份数据的聚类函数;表示图像归属系数;g(q
j
)表示增量分布式数据库中第j份数据的归一化函数;
[0153]
步骤s3:确定并立型分布式数据库中每份数据的最大隶属度,导入对应隶属类型的可视化工具,生成可视化数据。
[0154]
上述技术方案的原理在于:本发明在进行数据可视化的时候,首先根据并立型分布式数据库,确定数据特征,这个数据特征本发明分别对全量分布式数据库和增量分布式数据进行分别计算建模,在这个计算过程中,本发明通过乘积累加运算,确定不同分布式数据的分布特征。在步骤2中,本发明基于数据特征通过聚类算法计算每一份数据的隶属度,根据隶属度匹配对应的可视化工具实现数据可视化。在这个过程中,本发明分别引入了图像归属系数、图表归属系数和文本归属系数,通过这些归属系数在数据的聚类函数,以及数据映射函数中进行并行计算,实现对数据隶属度的计算。在步骤3种本发明基于最大隶属度,就表示数据更适合采用什么样的可视化方式。当然,在最大隶属度相同时,表示数据三种可视化方式都可以实施,进而通过对应的可视化工具实现数据可视化。
[0155]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。