1.本公开涉及通过最小化噪声下的预期损失来改进私有模型效用。
背景技术:
2.随着机器学习甚至在隐私敏感领域中已变得无处不在,最近的研究已经表明了具体的隐私威胁,以及探索了鲁棒的隐私防御,最值得注意的是差分隐私(differential privacy)。当机器学习算法应用于私有训练数据时,结果得到的模型可能不经意地通过其行为或其结构和参数的细节而泄露关于该数据的信息。
技术实现要素:
3.根据一个或多个说明性示例,一种方法包括执行模型的训练,以最小化噪声下的预期损失(elun)同时维持差分隐私。噪声作为从噪声分布抽取的随机样本被添加到机器学习模型的权重,该噪声是根据隐私预算添加的。通过使用损失函数来最小化elun,该损失函数预计添加到机器学习模型的权重的噪声,以在参数空间中找到一点,对于该点,损失对于权重中的噪声是鲁棒的。噪声的添加和elun的最小化被迭代,直到权重收敛并满足优化约束。针对任意输入利用该模型,同时保护用于训练该模型的训练数据的隐私。
4.根据一个或多个说明性示例,一种用于训练和利用模型以最小化噪声下的预期损失(elun)同时维持差分隐私的系统包括:存储机器学习模型的存储器;和计算设备。计算设备被编程为:将噪声作为从噪声分布抽取的随机样本添加到机器学习模型的权重,该噪声是根据隐私预算添加的;通过使用损失函数来最小化elun,该损失函数预计添加到机器学习模型的权重的噪声,以在参数空间中找到一点,对于该点,损失对于权重中的噪声是鲁棒的;迭代噪声的添加和elun的最小化,直到权重收敛并满足优化约束;以及针对任意输入利用该模型,同时保护用于训练该模型的训练数据的隐私。
5.根据一个或多个说明性示例,一种非暂时性计算机可读介质包括用于训练和利用模型以最小化噪声下的预期损失(elun)同时维持差分隐私的指令,该指令当由处理器执行时,使得处理器执行包括如下各项的操作:将噪声作为从噪声分布抽取的随机样本添加到机器学习模型的权重,该噪声是根据隐私预算添加的;通过使用损失函数来最小化elun,该损失函数预计添加到机器学习模型的权重的噪声,以在参数空间中找到一点,对于该点,损失对于权重中的噪声是鲁棒的;迭代噪声的添加和elun的最小化,直到权重收敛并满足优化约束;以及针对任意输入利用该模型,同时保护用于训练该模型的训练数据的隐私。
附图说明
6.图1提供了非凸损失函数的示例;图2图示了作为权重的函数的简单一维逻辑回归问题的预期损失;图3图示了用于产生差分私有模型的第一算法,该差分私有模型被训练成最小化elun;
图4图示了用于产生差分私有模型的替代算法,该差分私有模型被训练成最小化elun;图5图示了利用不同方法训练的线性模型的训练和测试准确度;图6图示了用于训练和利用模型来最小化噪声下的预期损失同时维持差分隐私的示例过程;和图7图示了示例计算设备。
具体实施方式
7.本文描述了本公开的实施例。然而,应理解,所公开的实施例仅仅是示例,并且其他实施例可以采取各种形式和替代形式。各图不一定是按比例的;一些特征可以被放大或最小化以示出特定组件的细节。因此,本文公开的具体结构和功能细节不应被解释为限制性的,而仅作为用于教导本领域技术人员以不同方式采用实施例的代表性基础。如本领域普通技术人员将理解的那样,参考任何一个图图示和描述的各种特征可以与一个或多个其他图中图示的特征相组合,以产生没有明确图示或描述的实施例。图示特征的组合为典型应用提供了代表性实施例。然而,与本公开的教导一致的特征的各种组合和修改对于特定的应用或实现可以是期望的。
8.机器学习已经变得越来越普遍,包括在隐私受到关注的敏感领域中。先前的工作突出了机器学习模型中的隐私漏洞——特别是,利用对模型的访问权的对手可以学习关于模型在其上被训练的私有数据的敏感信息。
9.为了对抗隐私威胁,已经提出了许多方法,最值得注意的是差分隐私,其给出了可证明的隐私保证。对于线性机器学习模型实现差分隐私的一种典型方式是向模型的权重添加噪声。不幸的是,该噪声可能通常显著地减损模型的效用。
10.虽然该效用权衡在某种程度上可能是不可避免的,但可以通过在参数空间中找到一点来减轻它,对于该点,损失对权重中的噪声是鲁棒的。该直觉可以构建在改进私有模型效用之上。
11.如本文详细讨论的,所描述的方法涉及三个贡献。首先,描述了新颖的损失函数——噪声下的预期损失(elun),它扩展了任意损失函数来预计将被添加到线性模型参数的噪声。第二,对elun的理论分析表明,被训练成最小化elun的模型可以使用将与原始损失函数会需要的相同量的噪声而变得差分私有。这直接暗示了用于利用elun训练线性模型的差分私有算法的存在。第三,供应了实用的算法来获得最小化具有差分隐私的elun的模型。
12.实现用于线性机器学习模型的差分隐私的一种方式是要向模型的权重添加噪声。不幸的是,该噪声可能通常显著地减损模型的效用。虽然该效用权衡在某种程度上可能是不可避免的,但通过在参数空间中找到一点来减轻它可以是可能的,对于该点,损失对权重中的噪声是鲁棒的。
13.更正式地说,可以训练一个模型,该模型使噪声下的预期损失最小化——即,当计及在有噪权重之上的不确定性时实现预期中的最小可能损失。为了做到这点,可以使用以下定义:定义1噪声下的预期损失。令是在模型参数和标记点之上定义的损失函
数;并令是可能模型参数之上的噪声分布,以c为中心。则噪声下的预期损失(elun)由下式给出在差分隐私的上下文中使用的标准分布是拉普拉斯分布,其具有针对中心和尺度b的概率密度函数(pdf)。将该噪声分布应用于定义1,拉普拉斯噪声下的预期损失由等式1给出:(1)备注1最小化预期中的的点不一定与最小化预期中的的点相同。
14.图1提供了非凸损失函数的示例,对于该非凸损失函数,在具有适当大尺度的拉普拉斯噪声下。然而,甚至对于凸损失函数,例如,在逻辑回归中,当使用elun时最佳参数可能不同。
15.例如,考虑一维逻辑回归问题,其中根据数据分布生成数据,数据分布如下:1. y是从{0,1}随机均匀抽取的。2. x是根据——即,具有均值和方差的正态分布——抽取的,其中。
16.对于线性逻辑模型,,令。之上的预期损失可以作为w的函数来计算,因为数据如何生成是已知的;这由等式2给出,当被选择为二元交叉熵时,等式2变为等式3。
17.(2)(3)同时,当使用具有尺度b和二元交叉熵损失的拉普拉斯噪声时,之上的预期elun由等式4给出。
18.(4)其中。
19.图2图示了作为权重w的函数的简单一维逻辑回归问题200的预期损失,对于 = 1, = 1:2(a)、1:0(b)和0:8(c),以及b = 1:0 & 2:0。值得注意的是,最佳权重——即,曲
线达到其最小值的点——在使用elun(等式4)时比简单地使用二元交叉熵(等式3)时更大。
20.这是由于二元交叉熵损失函数中的不对称性;当处于没有噪声的最佳权重时,稍微低估w与稍微高估相比,损失中的成本更高。因此,当噪声将被添加到w时,更优选的是稍微高估权重,以避免噪声的不成比例的高成本导致太小的权重。
21.差分隐私是常用的、强的隐私概念,其在机器学习的上下文中是学习规则的属性,该学习规则声明了任何特定训练点的存在或缺失都不显著影响通过规则学习的特定模型。更正式地说,定义2给出了差分隐私(在ml的上下文中声明)。
22.定义2差分隐私(dwork)。令为(随机化)机制,其在给定数据集的情况下返回模型。如果对于所有以及对于所有邻域,使得,则是
‑
差分隐私,当使用
‑
差分私有机制学习模型f时,可以说f本身就是
‑
差分私有的。
23.实现差分隐私的一种常见方式是要向非私有机制m的输出添加拉普拉斯噪声。在线性机器学习模型的上下文中,这对应于向经训练模型的每个权重添加噪声。(应当注意,线性模型的使用仅仅是一个示例,并且可以附加地或替代地使用其他类型的模型,诸如支持向量机、卷积神经网络(cnn)或深度神经网络(dnn))。噪声的尺度由隐私预算和m的灵敏度——m的输出在相邻输入上可以不同的最大量——确定。
24.wu等人使用关于强一致ro稳定性的变体来限界学习规则的灵敏度,该学习规则在强凸李普希茨连续损失函数上学习线性模型。其结果总结在定理1中。
25.定理1(wu等人)。令m是具有
‑
强凸损失函数的学习规则,,其中对于所有,是调节器,并且是相对于的
‑
李普希茨。则m在大小为n的数据集上的灵敏度以限界。
26.因此,对于
‑
强凸的
‑
李普希茨损失函数,m可以通过添加具有尺度的拉普拉斯噪声而成为
‑
差分私有的。
27.在对于分类问题常用的逻辑回归或softmax回归的情况下,是二元或分类交叉熵,当由范数限界时,其是
‑
李普希茨。在一些情况下,这样的界限可能容易存在,例如,对于像素值在范围[0,1]中的图像;在其他情况下,可以通过预处理步骤来实现它,在预处理步骤中,对值进行限幅(clip)以获得所期望的。可以通过添加调节项来使交叉熵
‑
强凸。
[0028]
关于限幅的注意。应针对数据集进行适当选择,然而,应关注关于基于数据选择的隐私影响。如果可以先验选择,或者可以假设为公开,则不存在隐私问题。如果选择,例如,作为数据的最大范数,则可能合期望的是以差分私有方式选择,并将其作为因素计入隐私分析。
[0029]
命题1如果损失函数对于所有相对于是
‑
李普希茨,则对于所有也相对于是
‑
李普希茨。
[0030]
证明。令是以c为中心的可能模型参数之上的噪声分布的pdf。可以假设对于所有相对于是
‑
李普希茨,因此。令是elun。这给出了:因此,对于所有::
ꢀꢀꢀꢀꢀ
(5)
ꢀꢀ
(6)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)通过重新索引跟随有等式5,因为而跟随有等式6,通过假设是
‑
李普希茨跟随有等式7,并且因为是概率测度而跟随有等式8。因此,对于所有相对于是
‑
李普希茨。
[0031]
因此,定理1可以应用于elun,,它对应于要添加到原始损失函数的噪声的尺度。这给出了一种产生差分私有模型的方式,该差分私有模型被训练来最小化elun,如图3中所示的算法1中详细描述的。由于灵敏度以及因此必须添加的噪声的尺度对于和两者是相同的,因此由算法1学习的模型预计添加到其中的噪声的确切量。因此,结果得到的模型是用于原始损失函数的最佳后噪声模型。
[0032]
一般来说,对于拉普拉斯噪声的elun(等式1)不是解析可求解的。数值解是可能的,然而,在高维中,计算积分变得难以处理,因为计算积分的工作量随着维度成指数缩放。这意味着不总是可能高效地直接应用算法1。因此,在实践中,elun是近似的,其可以经由采样高效地实现。
[0033]
图4图示了elun算法2,其描述了对elun算法1的实用替代方案。本质上,选择分辨率r,并且经由从拉普拉斯分布抽取的r随机样本来近似在噪声之上的预期。在实践中,可以
经由例如梯度下降的标准优化算法找到argmin。
[0034]
注意,在极限中,和收敛于概率密度函数之上的积分,并且命题1仍然经由本质上相同的证明而适用(通过利用和替换积分,并且利用替换)。因此,算法2返回的模型也是
‑
差分私有的。
[0035]
如备注1说明的,elun允许我们指定可能比使用原始损失函数训练的后噪声模型后噪声更好的模型(例如,如wu等人所做的)。现在示出了该潜在优势可以在实践中实现的证据;利用elun训练的差分私有模型的效用趋向于超过利用交叉熵训练的差分私有模型的效用,特别是对于的小值(更大的隐私保证)。
[0036]
图5图示了利用不同方法训练的线性模型的训练和测试准确度。如所示,各图指示了在各种数据集上,针对各种值,在没有差分隐私(黑色,点虚线)的情况下、具有输出扰动(红色,虚线)的情况下、通过使用算法2(蓝色,实线)的训练和测试准确度。结果在每个数据集上对100次试验取平均,其中=0.05,=2.0,并且r = 50。
[0037]
对于的小值(在那里隐私保证是最好的),算法2持续地、并且经常以显著的余裕而优于在先的工作。对于大,两种差分私有模型都接近非私有模型的性能,然而,重要的是要注意,对于大,隐私保证变得毫无意义,如yeom等人中所示。
[0038]
值得注意的是,利用elun学习的参数很好地推广;尽管在训练数据上elun被最小化的事实,算法2在测试数据上也优于在先的工作。
[0039]
因此,对于小(对应于强的隐私保证),差分私有训练机制产生了比目前可比较的最先进方法表现更好的模型。
[0040]
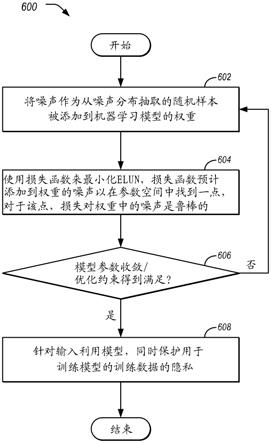
图6图示了用于训练和利用模型来最小化噪声下的预期损失(elun)同时维持差分隐私的示例过程600。在示例中,过程600可以由一个或多个计算设备、诸如本文描述的计算设备700来执行。
[0041]
在操作602,噪声作为从噪声分布抽取的随机样本被添加到机器学习模型的权重。在示例中,可以根据隐私预算来添加噪声。噪声可以是根据正态分布的概率密度函数抽取的拉普拉斯噪声,其中噪声经由从拉普拉斯分布抽取的随机样本来近似。应当注意,这仅仅是一个示例,并且可以使用其他噪声分布,诸如高斯噪声。机器学习模型可以是线性模型。
[0042]
在操作604,通过使用损失函数来最小化elun,该损失函数预计添加到机器学习模型的权重的噪声,以在参数空间中找到一点,对于该点,损失对于权重中的噪声是鲁棒的。最小化elun可以包括使用标准优化算法,诸如梯度下降。
[0043]
在操作606,评估模型以标识模型参数是否已经收敛以及给定的优化约束是否得到满足。如果不是,则控制返回到操作602以执行另外的迭代。如果是,则该模型被认为是完整的,并且控制转到操作608。
[0044]
在操作608,针对任意输入利用该模型,同时保护用于训练该模型的训练数据的隐私。在操作606之后,过程600结束。
[0045]
图7图示了示例计算设备700。本文讨论的一个或多个实施例的算法和/或方法技术可以使用这样的计算设备来实现。计算设备700可以包括存储器702、处理器704和非易失性存储装置706。处理器704可以包括从高性能计算(hpc)系统选择的一个或多个设备,包括高性能核心、微处理器、微控制器、数字信号处理器、微型计算机、中央处理单元、现场可编
程门阵列、可编程逻辑设备、状态机、逻辑电路、模拟电路、数字电路或基于驻留在存储器702中的计算机可执行指令操纵信号(模拟或数字)的任何其他设备。存储器702可以包括单个存储器设备或多个存储器设备,包括但不限于随机存取存储器(ram)、易失性存储器、非易失性存储器、静态随机存取存储器(sram)、动态随机存取存储器(dram)、闪存、高速缓冲存储器或能够存储信息的任何其他设备。非易失性存储装置706可以包括一个或多个持久数据存储设备,诸如硬盘驱动器、光学驱动器、磁带驱动器、非易失性固态设备、云存储装置或能够持久存储信息的任何其他设备。
[0046]
处理器704可以被配置为读入存储器702并执行驻留在非易失性存储装置706的程序指令708中并且体现一个或多个实施例的算法和/或方法技术的计算机可执行指令。程序指令708可以包括操作系统和应用。程序指令708可以从使用多种编程语言和/或技术创建的计算机程序编译或解释,多种编程语言和/或技术在没有限制的情况下并且单独或组合地包括java、c、c 、c#、objective c、fortran、pascal、java script、python、perl和pl/sql。在一个实施例中,作为python编程语言的包的pytorch可以用于实现一个或多个实施例的机器学习模型的代码。
[0047]
在由处理器704执行时,程序指令708的计算机可执行指令可以使得计算设备700实现本文公开的一个或多个算法和/或方法技术。非易失性存储装置706还可以包括支持本文描述的一个或多个实施例的功能、特征和过程的数据710。作为一些示例,该数据710可以包括训练数据、模型、采样噪声、模型输入和模型输出。
[0048]
本文公开的过程、方法或算法可以被可递送到处理设备、控制器或计算机/由处理设备、控制器或计算机实现,处理设备、控制器或计算机可以包括任何现有的可编程电子控制单元或专用电子控制单元。类似地,过程、方法或算法可以以多种形式存储为可由控制器或计算机执行的数据和指令,包括但不限于永久存储在诸如rom设备的不可写存储介质上的信息和可变更地存储在诸如软盘、磁带、cd、ram设备以及其他磁性和光学介质之类的可写存储介质上的信息。过程、方法或算法也可以在软件可执行对象中实现。替代地,可以使用合适的硬件组件(诸如,专用集成电路(asic)、现场可编程门阵列(fpga)、状态机、控制器)或其他硬件组件或设备,或者硬件、软件和固件组件的组合,来整体或部分地体现过程、方法或算法。
[0049]
虽然上面描述了示例性实施例,但是不意图这些实施例描述权利要求所涵盖的所有可能的形式。说明书中使用的词语是描述性而不是限制性的词语,并且应理解,在不脱离本公开的精神和范围的情况下,可以进行各种改变。如先前所述,各种实施例的特征可以被组合以形成可能没有被明确描述或图示的本发明的另外实施例。虽然各种实施例可能已经被描述为在一个或多个期望的特性方面提供了优于其他实施例或现有技术实现的优点或比其他实施例或现有技术实现优选,但是本领域的普通技术人员认识到,一个或多个特征或特性可以被折衷以实现期望的总体系统属性,这取决于具体的应用和实现。这些属性可以包括但不限于成本、强度、耐用性、生命周期成本、适销性、外观、包装、尺寸、适用性、重量、可制造性、组装容易性等。照此,在任何实施例被描述为在一个或多个特性方面不如其他实施例或现有技术实现合期望的程度上,这些实施例不在本公开的范围之外,并且对于特定应用可以是合期望的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。