1.本发明属于无线移动网络中的通信技术领域,具体涉及一种基于多智能体强化学习的无人机网络协同快跳频方法。
背景技术:
2.面对人们日益增加的通信需求,由于地面通信基础设施在部署成本和灵活性等方面都存在一定的局限性,因此无人机通信网络逐渐受到大家的关注(zeng y,wu q,zhang r.accessing from the sky:a tutorial on uav communications for 5g and beyond[j].proceedings of the ieee,2019,107(12):2327
‑
2375.)。无人机因具有体积小、部署成本低以及高敏捷性和可控性等特点,故可以用于处理紧急搜索与救援任务、充当移动中继以及天气监测和交通监控(gupta l,jain r,vaszkun g.survey of important issues in uav communication networks[j].ieee communications surveys&tutorials,2015,18(2):1123
‑
1152.)。
[0003]
特别地,当无人机对之间直接通信时,所建立的短程视距通信链路可以有效减少信号传输衰落。然而,与地面设备对设备通信一样,无人机对无人机通信也面临着干扰机恶意干扰攻击的威胁。并且由于频谱资源紧缺,用户间的同频道干扰也存在于无人机通信网络中,因此亟需有效的动态资源分配方案以提供通信保障(xu y,ren g,chen j,et al.a one
‑
leader multi
‑
follower bayesian
‑
stackelberg game for anti
‑
jamming transmission in uav communication networks[j].ieee access,2018,6:21697
‑
21709.)。
[0004]
在一些采用了传统优化方法的研究中,学者们为了简化优化问题,人为干预地限制了无人机的特性,如提前设定好无人机的飞行轨迹(zhang s,zhang h,di b,et al.cellular uav
‑
to
‑
x communications:design and optimization for multi
‑
uav networks[j].ieee transactions on wireless communications,2019,18(2):1346
‑
1359.)。而强化学习算法可以应对复杂的无人机通信网络,这是因为智能体可以在与环境交互过程中不断学习以提高无人机通信网络的性能。但是由于单智能体强化学习算法需要中央控制器收集全局信息来进行决策,而中央控制器在无人机通信网络中难以部署,因此学者们引入多智能体强化学习算法来解决无人机通信网络中的资源分配优化问题(cui j,liu y,nallanathan a.multi
‑
agent reinforcement learning
‑
based resource allocation for uav networks[j].ieee transactions on wireless communications,2019,19(2):729
‑
743.)。其中一些学者们所提出基于多智能体独立的资源分配方案虽然较传统方案性能更优,但未考虑采用多智能体协同框架所带来的性能提升(tang j,song j,ou j,et al.minimum throughput maximization for multi
‑
uav enabled wpcn:adeep reinforcement learning method[j].ieee access,2020,8:9124
‑
9132.)。
技术实现要素:
[0005]
本发明提出了一种基于多智能体强化学习的无人机网络协同快跳频方法,提高了所有无人机对的总吞吐量性能,为无人机网络提供了通信保障。
[0006]
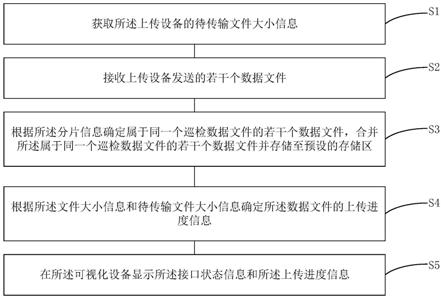
实现本发明目的的技术解决方案为:一种基于多智能体强化学习的无人机网络协同快跳频方法,包括以下步骤:
[0007]
步骤1、输入无人机网络环境,其中每对无人机作为独立的智能体初始化自身q表以及最优先验动作分布估计、互信息惩罚项系数和动作状态对出现次数;
[0008]
步骤2、在当前时隙中,每对无人机根据上一时隙生成的动作选择传输信道,传输完成后得到环境反馈的奖励;
[0009]
步骤3、每对无人机观测环境的当前状态,再与其它无人机对交互当前状态下各个动作的q值以得到全局q值,进而根据互信息正则化soft q
‑
learning算法中的行为策略生成动作;
[0010]
步骤4、每对无人机根据互信息正则化soft q
‑
learning算法中的更新方式来更新自身q表以及各个参量;
[0011]
步骤5、当达到训练回合的最大步数时,结束当前回合,开始下一回合,重新输入无人机网络环境,重复步骤2~步骤4。
[0012]
进一步地,将连续的训练时间离散化为多个时隙,用正整数来表示第j个时隙;假设网络中有m个无人机对和n个干扰机,分别用集合和来表示。
[0013]
进一步地,步骤1中所述输入无人机网络环境,其中无人机网络环境包含:
[0014]
(1)网络模型:无人机对和干扰机均按照马尔可夫随机移动模型移动,且每对无人机中的接收机与发射机之间的距离受限;
[0015]
(2)信道模型:考虑系统中存在有限个子频带,且信道功率增益由路径损耗和快衰落组成,所述路径损耗只考虑视距情况,快衰落指瑞利衰落;
[0016]
(3)无线传输模型:当实际传输速率小于等于所选信道的可达速率时,吞吐量为此时隙传输时间内传输的比特个数;否则,吞吐量为0;
[0017]
(4)干扰模型:设置干扰机的干扰类型为单音扫频干扰,不同干扰机所干扰的信道不会重叠,且干扰机可干扰信道集即为无人机对可用信道集合。
[0018]
进一步地,步骤2所述每对无人机根据上一时隙生成的动作选择传输信道,传输完成后得到环境反馈的奖励,具体为:
[0019]
(1)无人机对的动作
[0020]
每对无人机的动作包括两部分,第一部分是选择自身下一时隙的传输信道,第二部分是预测其它无人机对下一时隙选择的传输信道,则第m个无人机对在时隙j时的动作表示为:
[0021][0022]
其中,表示第m个无人机对在时隙j 1时的传输信道;
m
′
≠m是第m个无人机对预测其它无人机对在时隙j 1的传输信道向量;实际上,由于每对无人机只能控制自身下一时隙的传输信道,因此所有无人机对在时隙j 1时使用的传输信道向量表示为
[0023]
(2)系统奖励
[0024]
为了最大化所有无人机对的吞吐量,系统奖励设置为所有无人机对的总归一化吞吐量,即第m个无人机对在时隙j时的奖励表示为:
[0025][0026]
其中,是第m个无人机对在时隙j时的吞吐量,c
trans
是每对无人机的实际传输速率,t
r
是每个时隙内的传输时间。
[0027]
进一步地,步骤3所述每对无人机观测环境的当前状态,再与其它无人机对交互当前状态下各个动作的q值以得到全局q值,进而根据互信息正则化soft q
‑
learning算法中的行为策略生成动作,具体为:
[0028]
(1)无人机对的状态
[0029]
每对无人机的状态包括干扰机目前所干扰的信道和所有无人机对当前时隙使用的传输信道向量,因此第m个无人机对在时隙j时的状态表示为:
[0030][0031]
其中,表示每对无人机在时隙j时观测到的被干扰机所干扰的信道;
[0032]
忽略观测过程中的虚警/漏警概率,且假定每对无人机都能够精确观测到当前有哪些信道被干扰机干扰,因此每个时隙中所有无人机对的状态相同;
[0033]
(2)生成行为策略
[0034]
互信息正则化的soft q
‑
learning算法在生成行为策略时采用类似于ε
‑
贪婪策略的方法,且通过最优先验动作分布的估计ρ(a)和动态变化的互信息惩罚项系数β来调节探索与利用的权重;
[0035]
探索时,智能体根据最优先验动作分布的当前估计采样得到下一时隙的动作,其中每个动作的概率是不同的;利用时,智能体直接选择概率最大的动作,但是此概率不仅取决于q值,而且取决于最优先验动作分布的当前估计;因此,第m个无人机对在时隙j时的行为策略为:
[0036][0037]
其中x是在[0,1]区间上服从均匀分布的随机数,ε是贪婪因子,且利用时的当前最优策略为:
[0038][0039]
进一步地,步骤4所述每对无人机根据互信息正则化soft q
‑
learning算法中的更新方式来更新自身q表以及各个参量,具体为:
[0040]
(1)更新最优先验动作分布的估计ρ(a)
[0041]
假设是第m个无人机对在时隙j内生成的策略,表示第m个无人机对在时隙j
‑
1内生成后对最优先验动作分布的当前估计;由于在时隙j时,第m个无人机对根据动作向量中为自身选择的信道,因而对最优先验动作分布当前估计的更新方程如下:
[0042][0043]
其中α
ρ
是学习率,且为均匀分布;
[0044]
(2)更新互信息惩罚项的系数β
[0045]
假设是第m个无人机对在时隙j时的互信息惩罚项的系数,更新公式为:
[0046][0047]
其中,c是一正常数,且
[0048]
(3)更新q表
[0049]
q表更新需要用到最优先验动作分布的估计ρ(a)和互信息惩罚项的系数β,第m个无人机对在时隙j时的q表更新公式为:
[0050][0051]
其中是soft q值的计算公式,γ是折扣因子;是第m个无人机对在时隙j时的学习率,随着第m个无人机对动作状态对的出现次数而变化,具体计算公式为:
[0052][0053]
其中ω是一正常数,是第m个无人机对在时隙j时动作状态对的出现次数。
[0054]
本发明与现有技术相比,其显著优点为:(1)多个无人机对相互协作,通过信息交互的方式避免干扰以实现系统总吞吐量性能的最大化;(2)采用了基于互信息正则化的soft q
‑
learning算法,面对高动态的无人机网络环境,收敛速度更快,吞吐量性能更好且更稳定;(3)利用多智能体协同框架解决了动态变化无人机网络中的抗干扰通信问题,优化
了探索与利用,为无人机网络提供了通信保障。
附图说明
[0055]
图1是本发明基于多智能体强化学习的无人机网络协同快跳频方法的流程图。
[0056]
图2为本发明实施例的无人机网络拓扑结构示意图。
[0057]
图3为本发明实施例中平均无人机对的吞吐量性能随训练回合数的变化图。
[0058]
图4为本发明实施例中平均无人机对的吞吐量性能随干扰机数目的变化图。
[0059]
图5为本发明实施例中平均无人机对的吞吐量性能随可用信道数目的变化图。
[0060]
图6为本发明实施例中平均无人机对的吞吐量性能随无人机对数目的变化图。
具体实施方式
[0061]
本发明提出了一种基于多智能体强化学习的无人机网络协同快跳频方法,通过交互q表,多个无人机对相互协作以避免内部同信道干扰和干扰机的恶意干扰,提高了所有无人机对的总吞吐量性能,结合图1~图2,包括以下步骤:
[0062]
步骤1:输入无人机网络环境,其中每对无人机作为独立的智能体初始化自身q表以及最优先验动作分布估计、互信息惩罚项系数和动作状态对出现次数;
[0063]
步骤2:在当前时隙中,每对无人机根据上一时隙生成的动作选择传输信道,传输完成后得到环境反馈的奖励;
[0064]
步骤3:每对无人机观测环境的当前状态,再与其它无人机对交互当前状态下各个动作的q值以得到全局q值,进而根据互信息正则化soft q
‑
learning算法中的行为策略生成动作;
[0065]
步骤4:每对无人机根据互信息正则化soft q
‑
learning算法中的更新方式来更新自身q表以及各个参量。
[0066]
步骤5:当达到训练回合的最大步数时,结束当前回合,开始下一回合,重新输入无人机网络环境,重复步骤2~步骤4。
[0067]
本发明将连续的训练时间离散化为多个时隙,用正整数来表示第j个时隙。假设网络中有m个无人机对和n个干扰机,分别用集合和来表示。
[0068]
进一步地,步骤1所述输入无人机网络环境,其中每对无人机作为独立的智能体初始化自身q表以及最优先验动作分布估计、互信息惩罚项系数和动作状态对出现次数,具体为:
[0069]
无人机网络环境包含:
[0070]
(1)网络模型:无人机对和干扰机均按照马尔可夫随机移动模型移动,且每对无人机中的接收机与发射机之间的距离受限。
[0071]
(2)信道模型:考虑系统中存在有限个子频带,且信道功率增益由路径损耗(只考虑视距情况)和快衰落(瑞利)组成。
[0072]
(3)无线传输模型:当实际传输速率小于等于所选信道的可达速率时,吞吐量为此时隙传输时间内传输的比特个数;否则,吞吐量为0。
[0073]
(4)干扰模型:设置干扰机的干扰类型为单音扫频干扰,不同干扰机所干扰的信道不会重叠,且干扰机可干扰信道集即为无人机对可用信道集合。
[0074]
进一步地,步骤2所述每对无人机根据上一时隙生成的动作选择传输信道,传输完成后得到环境反馈的奖励,具体为:
[0075]
1)无人机对的动作
[0076]
每对无人机的动作包括两部分,第一部分是选择自身下一时隙的传输信道,第二部分是预测其它无人机对下一时隙选择的传输信道。则第m个无人机对在时隙j时的动作可以表示为:
[0077][0078]
其中,表示第m个无人机对在时隙j 1时的传输信道;m
′
≠m是第m个无人机对预测其它无人机对在时隙j 1的传输信道向量。实际上,由于每对无人机只能控制自身下一时隙的传输信道,因此所有无人机对在时隙j 1时使用的传输信道向量可表示为
[0079]
(2)系统奖励
[0080]
为了最大化所有无人机对的吞吐量,系统奖励设置为所有无人机对的总归一化吞吐量,即第m个无人机对在时隙j时的奖励可以表示为:
[0081][0082]
其中,是第m个无人机对在时隙j时的吞吐量,c
trans
是每对无人机的实际传输速率,t
r
是每个时隙内的传输时间。
[0083]
进一步地,步骤3所述每对无人机观测环境的当前状态,再与其它无人机对交互当前状态下各个动作的q值以得到全局q值,进而根据互信息正则化soft q
‑
learning算法中的行为策略生成动作,具体为:
[0084]
(1)无人机对的状态
[0085]
每对无人机的状态包括干扰机目前所干扰的信道和所有无人机对当前时隙被执行的通信信道向量,因此第m个无人机对在时隙j时的状态可以表示为:
[0086][0087]
其中,表示每对无人机在时隙j时观测到的被干扰机所干扰的信道。需要注意的是,本发明未考虑观测过程中的虚警/漏警概率,且假定每对无人机都可以精确观测到当前有哪些信道被干扰机干扰,因此每个时隙中所有无人机对的状态相同。
[0088]
(2)生成行为策略
[0089]
互信息正则化的soft q
‑
learning算法在生成行为策略时采用类似于ε
‑
贪婪策略的方法,且通过最优先验动作分布的估计ρ(a)和动态变化的互信息惩罚项系数β来调节探索与利用的权重。具体来说,探索时,智能体根据最优先验动作分布的当前估计采样得到下一时隙的动作,其中每个动作的概率是不同的;利用时,智能体直接选择概率最大的动作,但是此概率不仅取决于q值,而且取决于最优先验动作分布的当前估计。因此,第m个无人机
对在时隙j时的行为策略为:
[0090][0091]
其中x是在[0,1]区间上服从均匀分布的随机数,ε是贪婪因子,且利用时的当前最优策略为:
[0092][0093]
进一步地,步骤4所述每对无人机根据互信息正则化soft q
‑
learning算法中的更新方式来更新自身q表以及各个参量,具体为:
[0094]
(1)更新最优先验动作分布的估计ρ(a)
[0095]
假设是第m个无人机对在时隙j内生成的策略,表示第m个无人机对在时隙j
‑
1内生成后对最优先验动作分布的当前估计。由于在时隙j时,第m个无人机对根据动作向量中为自身选择的信道,因而对最优先验动作分布当前估计的更新方程如下:
[0096][0097]
其中α
ρ
是学习率,且为均匀分布。
[0098]
(2)更新互信息惩罚项的系数β
[0099]
假设是第m个无人机对在时隙j时的互信息惩罚项的系数,其更新公式为:
[0100][0101]
其中,c是一正常数,且
[0102]
(3)更新q表
[0103]
q表更新需要用到最优先验动作分布的估计ρ(a)和互信息惩罚项的系数β,第m个无人机对在时隙j时的q表更新公式为:
[0104][0105]
其中
[0106][0107]
是soft q值的计算公式,γ是折扣因子,是第m个无人机对在时隙j时的学习率,它会随着第m个无人机对动作状态对的出现次数而变化。具体计算公式为:其中ω是一正常数,是第m个无人机对在时隙j时动作状
态对的出现次数。
[0108]
下面结合附图及具体实施例对本发明做进一步详细说明。
[0109]
实施例
[0110]
本发明的一个实施例具体描述如下,仿真采用python编程,参数设定不影响一般性。与所述方法进行对比的方法有:(1)随机快跳频方法;(2)基于传统q
‑
learning的多智能体协同无人机快跳频方法。
[0111]
如图2所示,所有的无人机对和干扰机都在一个高度固定的长方形区域内移动,其中无人机对和干扰机会根据各自的飞行方向以一定的速度飞行。并且假设在通信过程,每对无人机中的接收机与发射机之间的距离d满足d≤d
max
,其中d
max
是每个无人机对的通信范围,设为100m。除此之外,所有无人机对中接收机或发射机的角色在训练过程中不会改变,但接收机与发射机会在每个回合的开始重新组对。
[0112]
在训练过程中,训练回合设为1000,每个回合的最大步数设为1000。此外,无人机的速度从[10m/s,20m/s]内随机取值,无人机的飞行方向有1/3的概率会改变。设置贪婪因子ε的初始值为1,之后随着训练步数不断减小。表1列出了其它的仿真参数。
[0113]
表1主要仿真参数
[0114][0115]
如图3所示,与基线方法相比,所述方法得益于高效的探索与利用机制,收敛后的吞吐量性能更好,收敛速度更快,训练过程更稳定。
[0116]
如图4~图6所示,在干扰机数目变化,可用信道数目变化以及无人机对数目变化
时,所述方法的性能均明显优于基线方法。这是因为其引入了自适应的最优先验动作分布的估计以及更好的q值更新方式和行为策略生成方式,因而可以更快地学习到动作的优先级。
[0117]
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。