1.本发明涉及歌声合成技术领域,尤其涉及一种保持音高的歌声合成方法及装置。
背景技术:
2.歌声合成是一门将包含歌词和音符的乐谱转换为歌声的合成技术,得益于语音合成技术的快速发展,歌声合成在逼真度上有了巨大提升。该技术已成功地应用在虚拟偶像、语音助手以及智能音乐创作等领域,未来对合成质量要求也越来越高。目前高质量的歌声合成系统均采用端到端的深度学习技术,但依赖大量的标注语料。歌声语料主要包含歌声音频和相应的乐谱,其数据获取成本高昂,对歌声合成效果造成严重阻碍。尤其是语料中音高数据分布差异较大,合成语料中出现次数较少的音高时容易出现走音现象,为此本发明提出一种新颖的歌城合成声学模型。
技术实现要素:
3.本发明的目的在于提供一种保持音高的歌声合成方法及装置,以解决歌声合成音高不准问题。
4.本发明解决上述问题所采取的技术方案是:一种保持音高的歌声合成方法,包括了训练阶段和推理阶段,在训练阶段包括以下步骤:
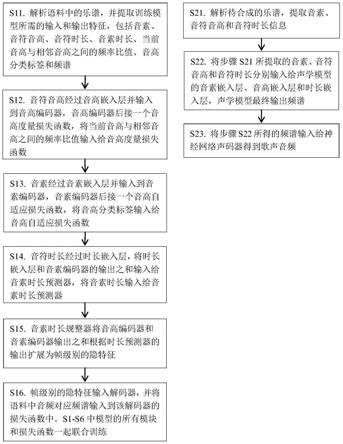
5.s11.解析语料中的乐谱,并提取训练模型所需的输入和输出特征,包括音素、音符音高、音符时长、音素时长、当前音高与相邻音高之间的频率比值、音高分类标签和频谱;
6.s12.音符音高经过音高嵌入层并输入到音高编码器,音高编码器后接一个音高度量损失函数,将当前音高与相邻音高之间的频率比值输入给音高度量损失函数;
7.s13.音素经过音素嵌入层并输入到音素编码器,音素编码器后接一个音高自适应损失函数,将音高分类标签输入给音高自适应损失函数;
8.s14.音符时长经过时长嵌入层,将时长嵌入层和音素编码器的输出之和输入给音素时长预测器,将音素时长输入给音素时长预测器;
9.s15.音素时长规整器将音高编码器和音素编码器输出之和根据时长预测器的输出扩展为帧级别的隐特征;
10.s16.帧级别的隐特征输入解码器,并将语料中音频对应频谱输入到该解码器的损失函数中,s11
‑
s16中模型的所有模块和损失函数一起联合训练;
11.推理阶段包括以下步骤:
12.s21.解析待合成的乐谱,提取音素、音符音高和音符时长信息;
13.s22.将步骤s21所提取的音素、音符音高和音符时长分别输入给声学模型的音素嵌入层、音高嵌入层和时长嵌入层,声学模型最终输出频谱;
14.s23.将步骤s22所得的频谱输入给神经网络声码器得到歌声音频。
15.更进一步的,为了准备从乐谱中提取音素、音符音高、音符时长、音素、音素时长、当前音高与相邻音高之间的频率比值、音高分类标签和频谱信息,步骤s11包括:
16.根据语料中乐谱数据格式,为每张乐谱提取歌词和音符标记;
17.根据歌词的语义,将每张乐谱切分为多个乐句,每个乐句仅包含一句语义完整的歌词。每张乐谱对应单个音频,将音频根据乐句结束位置切分为和多个乐句对应的多个音频段。
18.将每个语句包含的歌词展开为声韵母表示的音素串,音符的音高和时长根据对应的歌词展开成和音素串对应的音符音高串和音符时长串;
19.将音素串和对应的音频段输入语音识别系统,得到每个音素在音频段中起始和结束位置,或者通过人工标注方式获得,根据起始和结束位置的差值求得音素时长,单位为帧。
20.为音符音高串中每个音高计算其与前后相邻两个音高之间的频率之比;
21.使用输入音高串作为音高分类标签,即,标签和输入音高一样;
22.利用librosa工具将音频段转换为频谱。
23.更进一步的,为了创建音高编码器,步骤s12包括:
24.根据语料中不同音高出现的总次数,将音符音高用one
‑
hot编码表示,音高one
‑
hot编码先输入到音高嵌入层进一步学习音高表征,随后将音高嵌入层的输出送入音高编码器;
25.音高编码器后采用音高度量损失函数,该函数设计为:
[0026][0027][0028]
其中n表示每个音素串的总音素个数,p
i
表示音高串中的的当前音高,p
j
表示相邻音高,e
pit
表示音高编码器,r
ij
表示前音高与相邻音高之间的频率比值,该值由步骤s11预先计算得到。
[0029]
更进一步的,为了创建音素编码器,步骤s13包括:
[0030]
根据语料中不同音素出现的总次数,将音素用one
‑
hot编码表示,音素one
‑
hot编码先输入到音素嵌入层进一步学习音素表征,随后将音素嵌入层的输出送入音素编码器。
[0031]
将音素编码器的输出和步骤s11中的音高分类标签一起输入给音素编码器的音高自适应损失函数;
[0032]
更进一步的,为了创建音素时长预测器,步骤s14包括:
[0033]
根据语料中不同音符时长出现的总次数,将音符时长用one
‑
hot编码表示,音符时长one
‑
hot编码先输入到音符时长嵌入层进一步学习音符时长表征;
[0034]
将音符时长嵌入层和音素编码器的输出之和输入时长预测器;
[0035]
时长预测器的损失函数包括但不限于均方误差、平均绝对差、交叉熵,将步骤s1中的音素时长作为时长预测器损失函数的标签。
[0036]
更进一步的,为了创建解码以及训练整个声学模型,步骤s15包括:
[0037]
将音高编码器和音素编码器输出相加,总长度与输入音素串的长度一致;
[0038]
根据音素时长(单位为帧),音素时长预测器将音高编码器和音素编码器输出之和扩展为帧级别的隐特征,扩展后的隐特征的总长度为音素串所有音素时长之和。
[0039]
更进一步的,为了给解码器准备帧级别的隐特征,步骤s16包括:
[0040]
将帧级别的隐特征输入解码器,解码器输出长度和输入一致的歌声频谱;
[0041]
将解码器的输出和其对应的真实频谱输入给频谱损失函数,该损失函数包括不限于均方误差和平均绝对误差;
[0042]
联合训练、优化整个声学模型和损失函数。
[0043]
更进一步的,提取待合成乐谱的音素、音符音高、音符时长信息,步骤s21包括:
[0044]
根据歌词语义将乐谱切分为多个乐句,每个乐句仅包含一句完整语义的歌词;
[0045]
按照乐句中歌词出现顺序将歌词转换为声韵母级别的音素串;
[0046]
解析乐句中的音符音高,将歌词对应的音符音高展开成和音素串数量一致的音符音高串;
[0047]
解析乐句中的音符时长,将歌词对应的音符时长展开成和音素串数量一致的音符时长串。
[0048]
更进一步的,为了使得声学模型输出歌声频谱,步骤s22包括:
[0049]
将步骤s21所提取的音素串、音符音高串和音符时长串分别表示为相应的one
‑
hot编码,维度分别为不同音素、音符音高、音符时长在语料中出现次数;
[0050]
将音素、音符音高和音符时长的one
‑
hot编码分别输入给声学模型的音素嵌入层、音高嵌入层和音素时长嵌入层;
[0051]
将音素嵌入层的输出传递给音素编码器,将音符音高嵌入层的输出传递给音符音高编码器,将音符时长嵌入层的输出传递给音符时长编码器;
[0052]
将音素编码器的输出和音符时长嵌入层的输出之和传递给音素时长预测器;
[0053]
根据音素时长预测器的输出,将音素编码器的输出和音符音高编码器的输出之和扩展为帧级别的表征;
[0054]
将帧级别的表征输入声学模型的解码器,解码器输出歌声的频谱。
[0055]
更进一步的,为了将歌声频谱转换为歌声音频,步骤s23包括:
[0056]
利用相同的语料训练神经网络声码器,基于神经网络的声码器选自wavenet、wavernn、lpcnet、waveglow、melgan中的任意一种;
[0057]
将步骤s22所得的每个乐句对应的频谱输入给训练完成的神经网络声码器,由神经网络声码器转换频谱为歌声音频;
[0058]
将各个乐句对应的歌声拼音按照乐句在乐谱中出现顺序拼接成完整的歌声音频。
[0059]
还提出一种保持音高的歌声合成装置,包括:
[0060]
乐谱选择模块,该模块提供可选择的乐谱乐库,以及提供乐谱上传到装置的曲库功能,被选中的待合成乐谱将被后续模块处理;
[0061]
乐谱处理模块,用于提取选中乐谱中的歌词对应的音素串、音符音高串、音符时长串,将它们转换为长度一致的one
‑
hot编码;
[0062]
频谱合成模块,用于将以上one
‑
hot编码输入到声学模型,声学模型输出歌声频谱;
[0063]
音频合成模块,用于将频谱合成模块产生的歌声频谱转换为歌声音频,并播放。
[0064]
本发明提出一种保持音高的歌声合成方法和装置,解决基于端到端歌声合成由于训练数据不足导致的音高不准问题。该发明由模型训练和模型推理两部分组成,离线完成
模型训练后将模型推理部署在装置上。根据歌声的特点本发明提出一种有效分离歌声的音高和音素发音的声学模型,使得训练语料中不同音高对应的相同发音单元能够互相弥补,从而提升语料库中出现次数较少的音高的合成准确率。该声学模型由音素编码器、音高编码器、音素时长预测器和解码器构成。音素时长预测器输出每个音素对应的发音时长,然后根据发音时长将音素编码器和音高编码器输出之和按时间维度扩展后送入解码器,最终由神经网络声码器将解码器输出的声学特征合成为歌声。训练声学模型前,首先从乐谱中提取音素、音素对应的音符音高、音素对应的音符时长和音素时长,前三类信息分别经过三个嵌入层提取特征,所有信息随后输入给声学模型。声学模型中,音素编码器后增加一个音高自适应损失函数,用于将不同音高对应的音素映射到同一个特征空间。此外,根据乐理十二平均律本发明专门为音高编码设计了一个新颖的音高度量损失函数,用于迫使不同音素对应的相同音高通过该编码器后的特征能距离更近,从而使得由该特征合成的音高更加准确。所有声学模型和损失函数一起联合训练,而推理阶段输入数据只涉及和模型参数相关的计算。
附图说明
[0065]
图1为本发明实施例所述一种保持音高的歌声合成方法的流程示意图。
[0066]
图2为本发明实施例所述的模型结构示意图。
具体实施方式
[0067]
下面将结合附图对本发明实施方式进行完整、详细地描述。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是本发明的全部实施例。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
[0068]
实施例1
[0069]
本发明提供一种保持音高的歌声合成方法,该方法可有由一个软件装置或者硬件装置实现。图1为本发明实施例提供的保持音高歌声合成方法的流程示意图,图2为本发明提出的声学模型结构和损失函数,在本实施例中模型训练阶段包括以下步骤:
[0070]
s11.解析语料中的乐谱,并提取训练模型所需的输入和输出特征,包括音素、音符音高、音符时长、音素时长、当前音高与相邻音高之间的频率比值、音高分类标签和频谱;
[0071]
歌声语料库制作成本较为昂贵,主要成本在于录制高质量的歌声数据,以及根据歌声标注乐谱。本实施例中,语料库可采取向专业数据公司购买或者自己录制和标注方式获取,大约需要2个小时时长的歌声数据。乐谱采用musicxml格式存储,音频采用wav格式存储。根据<text>文本标签从乐谱文件中提取歌词;根据<step>音级标签、<alter>升降半音标签和<octave>所在八度标签计算音符音高;根据<duration>音符时值标签、<divisions>四分音符的时值标签和<per
‑
minute>每分钟拍数标签计算音符时长。根据每句歌词的词义将乐谱切分为多个乐句,以及将歌声音频文件根据乐句切分为多个音频片段。举例说明,歌词“我从山中来带着兰花草”可根据词义将其切分为“我从山中来”和“带着兰花草”两段。
[0072]
更近一步地,将切分后的音频段和歌词采用语音识别方法获取歌词的声韵母起始和结束时间。可选地,可采用开源工具montreal
‑
forced
‑
aligner、kaldi训练成对的歌词
‑
音频文件获取声韵母音素的时间对齐,也可采取人工标注方式,根据起始和结束位置的差
值求得音素时长,发音时长单位为帧。举例说明,音素“a”的起始和结束时间为“1 1.3”秒,帧移为10毫秒,那么音素“啊”的发音时长为(1.3
‑
1)/10=30帧。
[0073]
当前音高与相邻音高之间的频率比值可根据如下公式计算:
[0074][0075]
其中r表示比值,p表示音高值。比如,有音高序“50 53 49”,53为当前音高,那么根据公式可以算得它和前邻居50、后邻居49的比值分别为2.83和4。使用输入音高串作为音高分类标签,即,标签和输入音高一致。采用开源工具librosa提取音频的频谱,本发明使用梅尔谱。
[0076]
s12.音符音高经过音高嵌入层并输入到音高编码器,音高编码器后接一个音高度量损失函数,将当前音高与相邻音高之间的频率比值输入给音高度量损失函数;
[0077]
根据语料中不同音高出现的总次数,将音符音高用one
‑
hot编码表示。举例说明,语料库中不同的音高总个数为60个,将它们按照音高大小从小到大排列,然后将其映射到0~59编号,那么编号为0的音高对应的one
‑
hot编码为“1 0...0”。音高one
‑
hot编码先输入到音高嵌入层进一步学习音高表征,嵌入层的维度可根据需要自行设定(例如256,1024)。将音高嵌入层的输出送入音高编码器,该编码器的网络包含但不限于多层的卷积网络,编码器维度可根据需要自行设定,但所有的嵌入层和编码器的维度大小保持一致。音高编码器后采用音高度量损失函数,该函数设计为:
[0078][0079][0080]
其中n表示每个音素串的总音素个数,p
i
表示音高串中的的当前音高,p
j
表示相邻音高,e
pit
表示音高编码器,r
ij
表示前音高与相邻音高之间的频率比值,该值通过步骤s11得到。
[0081]
s13.音素经过音素嵌入层并输入到音素编码器,音素编码器后接一个音高自适应损失函数,将音高分类标签输入给音高自适应损失函数;
[0082]
根据语料中不同音素出现的总次数,将音素用one
‑
hot编码表示。举例说明,语料库中不同的音素总个数为80个,将它们按照字母顺序排列,然后将其映射到0~79编号,那么编号为0的音素对应的one
‑
hot编码为“1 0...0”。音素one
‑
hot编码先输入到音素嵌入层进一步学习音素表征,随后将音素嵌入层的输出送入音素编码器。可选地,音素嵌入层和音素编码器的维度大小可根据需要自行设定,但所有嵌入层和编码器层维度大小保持一致。将音素编码器的输出和步骤s11中的音高分类标签一起输入给音素编码器的音高自适应损失函数。
[0083]
s14.音符时长经过时长嵌入层,将时长嵌入层和音素编码器的输出之和输入给音素时长预测器,将音素时长输入给音素时长预测器;
[0084]
根据语料中不同音符时长出现的总次数,将音符时长用one
‑
hot编码表示。举例说明,语料库中不同的音符时长总个数为8个,将它们按照字母顺序排列,然后将其映射到0~7编号,那么编号为0的音符时长对应的one
‑
hot编码为“1 0...0”。音符时长one
‑
hot编码先输入到音符时长嵌入层进一步学习音符时长表征。可选地,音符时长嵌入层和音符时长的
维度大小可根据需要自行设定,但所有嵌入层和编码器层维度大小保持一致。将音符时长嵌入层和音素编码器的输出之和输入时长预测器,时长预测器输出的单位为帧。可选地,时长预测器的损失函数包括但不限于均方误差、平均绝对差、交叉熵,将步骤s1中的音素时长作为时长预测器损失函数的标签。
[0085]
s15.音素时长规整器将音高编码器和音素编码器输出之和根据时长预测器的输出扩展为帧级别的隐特征;
[0086]
具体地,如图2所示,将音高编码器和音素编码器输出相加,总长度为音素串的长度。根据音素的发音时长(单位为帧),音素时长预测器将音高编码器和音素编码器输出之和扩展为帧级别的隐特征,扩展后的总长度为音素串所有音素时长之和。举例说明,设输入音素个为3,音素时长预测器输出为“2 2 1”,音高编码器和音素编码器输出之和表示为“1 2 3”,那么将其扩展之后的帧级别的隐特征为“1 1 2 2 3”。
[0087]
s16.帧级别的隐特征输入解码器,并将语料中音频对应频谱输入到该解码器的损失函数中。s1
‑
s6中模型的所有模块和损失函数一起联合训练。
[0088]
具体地,如图2所示,将帧级别的隐特征输入解码器,解码器输出长度和输入一致的歌声频谱,将解码器的输出和其对应的真实频谱输入给频谱损失函数。可选地,解码器的维度可根据需要自行设定,网络包括但不限于深度卷积网络,损失函数包括不限于均方误差和平均绝对误差。
[0089]
更近一步地,联合训练、优化整个声学模型和损失函数。可选地,采用主流的深度学习框架tensorflow或者pytorch实现。
[0090]
推理阶段包括以下步骤:
[0091]
s21.解析待合成的乐谱,提取音素、音符音高和音符时长信息;
[0092]
根据歌词语义将乐谱切分为多个乐句,每个乐句仅包含一句完整语义的歌词。举例说明,歌词“我从山中来带着兰花草”可根据词义将其切分为“我从山中来”和“带着兰花草”两段。
[0093]
更近一步地,按照乐句中歌词出现顺序将歌词转换为声韵母级别的音素串。举例说明,歌词“我从山中来”转换为“w o c ong sh an zh ong l ai”,不带音调。
[0094]
更近一步地,解析乐句中的音符音高,将歌词对应的音符音高展开成和音素串数量一致的音符音高串。举例说明,歌词“我(43,50)爱(60)你(56)”,括号中的数字表示括号前的字对应的音高,如果一个字对应于多个音高,则辅音占第一个音高,元音占所有音高,此时转换扩展后的音高为“w(43)o(43)o(50)ai(60)n(56)i(56)”,即,音素串和音高串分别为“w o o ai n i”和“43 43 5060 56 56”。
[0095]
更近一步地,解析乐句中的音符时长,将歌词对应的音符时长展开成和音素串数量一致的音符时长串。举例说明,歌词歌词“我(4,8)爱(4)你(8)”,括号中的数字表示括号前的字对应的音符时长,4和8分别表示4分音符和8分音符。如果一个字对应于多个音符时长,则辅音占第一个时长,元音占所有时长,此时,音符时长串为“4 4 8 4 8 8”。
[0096]
s22.将步骤s21所提取的音素、音符音高和音符时长分别输入给声学模型的音素嵌入层、音高嵌入层和时长嵌入层,声学模型最终输出频谱;
[0097]
具体地,如图2所示,将步骤s21所提取的音素串、音符音高串和音符时长串分别表示为相应的one
‑
hot编码,维度分别为不同音素、音符音高、音符时长在语料中的数量。举例
说明,语料库中不同的音符时长总个数为8个,将它们按照字母顺序排列,然后将其映射到0~7编号,那么编号为0的音符时长对应的one
‑
hot编码为“1 0...0”。音符音高和音符时长的one
‑
hot编码用类似方法得到。
[0098]
更近一步地,将音素、音符音高和音符时长的one
‑
hot编码分别输入给声学模型的音素嵌入层、音高嵌入层和时长嵌入层,声学模型的参数配置在步骤s11
‑
s16中确定。
[0099]
更近一步地,将音素嵌入层的输出传递给音素编码器,音符音高嵌入层的输出传递给音符音高编码器,音符时长嵌入层的输出传递给音符时长编码器。
[0100]
更进一步地,将音素编码器的输出和音符时长嵌入层的输出之和传递给音素时长预测器。
[0101]
更进一步地,根据音符时长预测器的输出,将音素编码器的输出和音符音高编码器的输出之和扩展为帧级别的表征。
[0102]
更进一步地,将帧级别的表征输入解码器,该解码器输出歌声的频谱。
[0103]
s23.将步骤s22所得的频谱输入给神经网络声码器得到歌声音频。
[0104]
可选地,利用相同的语料训练神经网络声码器,基于神经网络的声码器包括但不限于wavenet、wavernn、lpcnet、waveglow、melgan等。
[0105]
进一步地,将步骤s22所得的每个乐句对应的频谱输入给训练完成的神经网络声码器,由神经网络声码器转换频谱为歌声音频。
[0106]
近一步地,将各个乐句对应的歌声拼音按照乐句在乐谱中出现顺序拼接成完整的歌声音频。
[0107]
实施例1中采用的音高编码器和音素分别独立地表征歌声的音高和音色,使得该方法在音高和音素组合较少的歌声数据库上具有鲁棒性。音高编码器将不同音素对应的相同音高聚类在一起,有利于提升最终合成歌声的音高准确度。在保证基于端到端的歌声合成自然度和音质的前提下,本实施例能提升合成歌声的音高正确度,尤其对于音符音高在语料库中出现次数较少的样本。
[0108]
实施例2
[0109]
本发明实施例所述的一种保持音高的歌声合成装置,包括:
[0110]
乐谱选择模块,该模块提供可选择的乐谱乐库,以及提供乐谱上传到装置曲库的功能,被选中的待合成乐谱将被后续模块处理。
[0111]
具体地,该模块具有乐谱存储功能,并默认提供多张乐谱可供用户界面选择。用户界面包含但不限于乐谱选择和乐谱上传功能。可选择地,乐谱上传可利用外部存储介质或网络传输方式实现。乐谱格式为musicxml,包含文字和音符标记。
[0112]
乐谱处理模块,该模块提取选中乐谱中的歌词对应的音素串、音符音高串、音符时长串,将它们转换为长度一致的one
‑
hot编码。
[0113]
近一步地,根据歌词语义将乐谱切分为多个乐句,每个乐句仅包含一句完整语义的歌词。举例说明,歌词“我从山中来带着兰花草”可根据词义将其切分为“我从山中来”和“带着兰花草”两段。
[0114]
更近一步地,按照乐句中歌词出现顺序将歌词转换为声韵母级别的音素串。举例说明,歌词“我从山中来”转换为“w o c ong sh an zh ong l ai”,不带音调。
[0115]
更近一步地,解析乐句中的音符音高,将歌词对应的音符音高展开成和音素串数
量一致的音符音高串。举例说明,歌词“我(43,50)爱(60)你(56)”,括号中的数字表示括号前的字对应的音高,如果一个字对应于多个音高,则辅音占第一个音高,元音占所有音高,此时转换扩展后的音高为“w(43)o(43)o(50)ai(60)n(56)i(56)”,即,音素串和音高串分别为“w o o ai n i”和“43 43 5060 56 56”。
[0116]
更近一步地,解析乐句中的音符时长,将歌词对应的音符时长展开成和音素串数量一致的音符时长串。举例说明,歌词歌词“我(4,8)爱(4)你(8)”,括号中的数字表示括号前的字对应的音符时长,4和8分别表示4分音符和8分音符。如果一个字对应于多个音符时长,则辅音占第一个时长,元音占所有时长,此时,音符时长串为“4 4 8 4 8 8”。
[0117]
频谱合成模块,用于将以上one
‑
hot编码输入到声学模型,声学模型输出歌声频谱。
[0118]
具体地,将上个模块提取的音素串、音符音高串和音符时长串分别表示为相应的one
‑
hot编码,维度分别为不同音素、音符音高、音符时长在语料中的数量。举例说明,语料库中不同的音符时长总个数为8个,将它们按照字母顺序排列,然后将其映射到0~7编号,那么编号为0的音符时长对应的one
‑
hot编码为“1 0...0”。音符音高和音符时长的one
‑
hot编码用类似方法得到。
[0119]
近一步地,如图2所示,将音素、音符音高、音符时长的one
‑
hot编码输入到已训练好的声学模型,声学模型输出帧级别的频谱。
[0120]
音频合成模块,用于将频谱合成模块产生的歌声频谱转换为歌声音频,并播放。
[0121]
具体地,将s23中训练好的神经网络声码器部署在装置中,基于神经网络的声码器包括但不限于wavenet、wavernn、lpcnet、waveglow、melgan等。
[0122]
进一步地,将上个模块所得的每个乐句对应的频谱输入给神经网络声码器,由神经网络声码器转换频谱为歌声音频。
[0123]
近一步地,将各个乐句对应的歌声拼音按照乐句在乐谱中出现顺序拼接成完整的歌声音频。
[0124]
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本技术公开的原则范围和精神之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

