1.本发明属于语音处理技术领域,具体涉及一种用于非对称语料的语音转换方法。
背景技术:
2.语音转换技术是指将源说话人的身份信息转换为目标说话人的身份信息,同时保持语音内容不变,在医疗服务、保密通信及生活娱乐的方面有着非常重要的应用。目前,语音转换大致可以分为两类,一类是受监督的,另一类是无监督的。受监督的语音转换已经取得了较好的成果,但是需要源与目标之间帧级对齐,也即需要对称的语料进行训练。如果源语音与目标语音不对称,也即语义内容不同,它们两者之间就有较大的差异,就无法达到较好的转换效果,这就限制了语音转换的应用范围。
3.中国专利号201310146293.x公开了一种基于自适应算法的非对称语料库条件下的语音转换方法,首先通过预先准备的参考说话人语句训练得到背景说话人模型;然后通过map自适应技术,将源说话人和目标说话人的语句分别训练得到源说话人和目标说话人模型;接着通过自适应源说话人和目标说话人模型中的均值和方差训练得到语音转换函数,分别提出了高斯归一化和均值转换的方法,为了进一步提高转换效果,进而提出了高斯归一化和均值转换融合的方法。该专利技术方案虽有其优点,但其语音转换性能有待提高。
技术实现要素:
4.针对上述现状,本发明提出了一种采用表示分离生成对抗网络(representation separation generative adversarial network,rs
‑
gan)的语音转换方法,在rs
‑
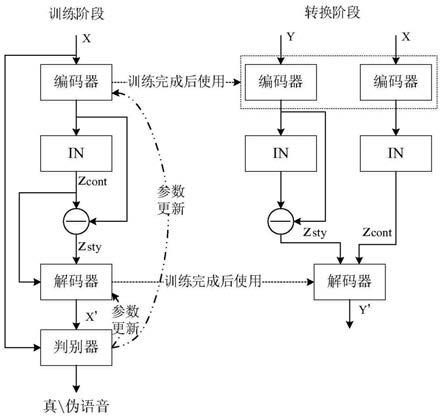
gan网络中使用编码器将语音的内容信息与说话人信息分离。在训练阶段,通过编码器对语音进行特征提取,并在编码器之后使用实例归一化(instance normalization,in)将语音中包含的说话人个性特征去除,从而只保留语音中的内容信息。在转换阶段,将源语音与目标语音输入编码器,分别提取到源语音的内容信息与目标语音的个性特征,通过解码器将其合成便可得到转换后的语音。
5.本发明采取如下技术方案:
6.一种用于非对称语料的语音转换方法,其按如下步骤:
7.一、训练阶段:
8.1.1令x为从训练数据集χ中所有语音段的集合中采样得到的声学矢量序列,enc为编码器,dec为解码器,则编码器生成的潜矢量序列z为
9.z=enc(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
10.得到潜矢量序列z后,通过in算法将潜矢量中包含的说话人个性特征归一化,从而去除说话人的个性特征,得到语音的内容信息z
cont
11.z
cont
=in(z)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
12.假设p(z
cont
|x)是具有单位方差且条件独立的高斯分布,即
13.p(z
cont
|x)=n(z
cont
;0,i)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
14.其中,n表示高斯分布,i表示单位方差;
15.将语音内容信息z
c
o
nt
从潜矢量z中减去,可得说话人的个性特征z
sty
表示为
16.z
sty
=e
t
[z
‑
z
c
o
nt
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0017]
其中,e
t
代表语音序列x的全局信息在潜在表示z上所占长度的期望;
[0018]
1.2解码器对分离后的内容信息表示与说话人个性特征表示进行合成,生成的语音x'为
[0019]
x'=dec(z
c
o
nt
z
sty
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0020]
并通过反向传播计算损失函数梯度,从而最小化重建损失并进行参数更新
[0021][0022]
其中,θ
enc
是编码器更新参数,θ
dec
是解码器更新参数;
[0023]
1.3判别器d用于判别解码器生成的语音是否为真实语音x,并用对抗损失来表示,定义为
[0024]
l
adv
(θ
enc
,θ
dec
,θ
d
)=e
x∈χ
[log(d(x))] e
x∈χ
[log(1
‑
x'] e
x∈χ
[log(1
‑
d(dec(z)))]
ꢀꢀ
(7)
[0025]
其中,θ
enc
是编码器更新的参数,θ
dec
是解码器更新的参数,θ
d
是判别器更新的参数;
[0026]
二、转换阶段
[0027]
将待转换的源语音x与目标语音y分别作为已经训练好的编码器的输入,编码器提取源语音的内容信息z
c
o
nt
和目标语音的个性特征z
sty
,再将两者通过已经训练好的解码器进行合成,生成保留源语音的内容信息并具有目标说话人个性特征的语音y'。
[0028]
优选的,in算法表示为:
[0029][0030]
式中,z
ch
[w]是第ch个通道中的第w个元素;因为应用的是1维卷积而不是2维卷积,所以每个通道是一个数组,而不是矩阵;μ
ch
和σ
ch
是第ch个通道的均值与标准差,表示为
[0031][0032][0033]
式中,w是潜矢量z
ch
的维度,ε是一个很小的值,避免数值的不稳定;经过归一化处理的潜矢量z'
ch
中仅保留了语音的内容信息,说话人的个性特征已被去除。
[0034]
优选的,在编码器中,使用conv1d卷积层和relu激活层的结构来同时处理所有频率信息,并在两个conv1d层之后使用两个resblock残差块,以避免梯度弥散;内容表示是通过in层生成的,说话人个性特征表示是每个时间步长上潜矢量和内容矢量之间差的平均值。
[0035]
优选的,在解码器中,使用norm
‑
1层对输入矢量进行l2范数归一化,最后通过upsample层进行上采样,输出合成语音。
[0036]
优选的,判别器d最大化该对抗损失,区分合成语音与真实语音;编码器、解码器最小化对抗损失,从而使合成的语音与真实语音无法区分。
[0037]
本发明具有如下技术效果:
[0038]
(1)本发明采用表示分离生成对抗网络进行语音转换,有效地提升了非对称语料情况下的语音转换性能。
[0039]
(2)本发明利用编码器以及in算法对语音的内容信息与说话人个性特征进行解离,再通过解码器将源语音的内容信息与目标语音的个性特征进行合成,使得生成语音的个性特征更加接近特定目标说话人的个性特征。
[0040]
(3)本发明提出的语音转换方法有效地克服了转换后语音中不能较好保留输入语音成分的问题。
附图说明
[0041]
图1是一种优选实施例用于非对称语料的语音转换方法的流程框图。
[0042]
图2是编码器的结构图。
[0043]
图3是解码器的结构图。
[0044]
图4是判别器的结构图。
具体实施方式
[0045]
下面结合附图对本发明的优选实施例做详细说明。
[0046]
在本实施例一种用于非对称语料的语音转换方法的整个过程中,无论是训练阶段还是转换阶段,都不需要对称的语料,完整的语音转换过程如图1所示:
[0047]
步骤一,训练阶段
[0048]
编码器:
[0049]
1.1本发明使用编码器
‑
解码器结构,并且仅使用一个编码器提取语音的内容信息与说话人个性特征。令x为从训练数据集χ中所有语音段的集合中采样得到的声学矢量序列,enc为编码器,dec为解码器,则编码器生成的潜矢量序列z为
[0050]
z=enc(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0051]
得到潜矢量序列z后,通过in算法将潜矢量中包含的说话人个性特征归一化,从而去除说话人的个性特征,得到语音的内容信息z
cont
[0052]
z
cont
=in(z)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0053]
假设p(z
cont
|x)是具有单位方差且条件独立的高斯分布,即
[0054]
p(z
cont
|x)=n(z
cont
;0,i)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0055]
其中,n表示高斯分布,i表示单位方差。
[0056]
将语音内容信息z
c
o
nt
从潜矢量z中减去,可得说话人的个性特征z
sty
表示为
[0057]
z
sty
=e
t
[z
‑
z
c
o
nt
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0058]
其中,e
t
代表语音序列x的全局信息在潜在表示z上所占长度的期望。
[0059]
在编码器中,使用conv1d卷积层和relu激活层的结构来同时处理所有频率信息,并在两个conv1d层之后使用两个resblock残差块,来避免梯度弥散。内容表示是通过in层生成的,说话人个性特征表示是每个时间步长上潜矢量和内容矢量之间差的平均值。编码器结构如图2所示。图2中,conv1d是卷积层,relu是激活层,resblock是残差块。
[0060]
1.2在训练阶段,解码器对分离后的内容信息表示与说话人个性特征表示进行合
成,生成的语音x'为
[0061]
x'=dec(z
c
o
nt
z
sty
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0062]
并通过反向传播计算损失函数梯度,从而最小化重建损失并进行参数更新
[0063][0064]
其中,θ
enc
是编码器更新参数,θ
dec
是解码器更新参数。
[0065]
在解码器网络中使用norm
‑
1层对输入矢量进行l2范数归一化,最后通过upsample层进行上采样,输出合成语音,其结构如图3所示。图3中,norm为归一化层,upsample为上采样层,conv1d与resblock与编码器一致。
[0066]
1.3判别器d:其作用是用于判别解码器生成的语音是否为真实语音x,并用对抗损失来表示,定义为
[0067]
l
adv
(θ
enc
,θ
dec
,θ
d
)=e
x∈χ
[log(d(x))] e
x∈χ
[log(1
‑
x'] e
x∈χ
[log(1
‑
d(dec(z)))]
ꢀꢀ
(7)
[0068]
其中,θ
enc
是编码器更新的参数,θ
dec
是解码器更新的参数,θ
d
是判别器更新的参数。
[0069]
判别器d试图最大化该对抗损失,尽可能区分合成语音与真实语音。编码器、解码器尽可能最小化对抗损失,从而使合成的语音与真实语音无法区分。判别器结构如图4所示。图4中,glu为线性门控单元,fc为全连接层,gsp为全局池化层。
[0070]
实例归一化:
[0071]
将编码器的输出潜矢量z通过in算法进行归一化处理后可以有效地保留内容信息,同时去除说话人的个性特征。in算法可以表示为:
[0072][0073]
式中,z
ch
[w]是第ch个通道中的第w个元素。因为应用的是1维卷积而不是2维卷积,所以每个通道是一个数组,而不是矩阵。μ
ch
和σ
ch
是第ch个通道的均值与标准差,表示为
[0074][0075][0076]
式中,w是潜矢量z
ch
的维度,ε是一个很小的值,来避免数值的不稳定。经过归一化处理的潜矢量z'
ch
中仅保留了语音的内容信息,说话人的个性特征已被去除。
[0077]
二、转换阶段
[0078]
将待转换的源语音x与目标语音y分别作为已经训练好的编码器的输入,编码器提取源语音的内容信息z
c
o
nt
和目标语音的个性特征z
sty
,再将两者通过解码器进行合成,就可以生成保留源语音的内容信息并具有目标说话人个性特征的语音y'。
[0079]
以上所述仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

