1.本发明涉及一种端到端语音识别技术,属于语音识别技术领域。
背景技术:
2.随着深度学习的不断发展,端到端语音识别方法被成功应用于手机、平板电脑、智能家居等多种实际领域中,受到越来越多研究者的关注。在众多端到端语音识别技术中,基于注意力机制的编码器解码器模型,由于其兼顾了输入语音序列和识别文本序列的上下文关系,取得了目前最佳性能。该方法采用注意力机制学习输入语音序列与识别文本序列之间的对齐关系,以减少预测无关信息对解码器预测过程的干扰。然而,因其采用softmax变换函数对注意力得分向量进行归一化,导致生成的瞥向量中包含大量预测无关信息,该信息将严重干扰解码器识别过程,也使得这种方法识别的字错率、词错率相对较高。
技术实现要素:
3.本发明是为了解决现有的基于softmax注意力机制的语音识别方法解码过程中存在大量预测无关信息而导致严重干扰解码器识别过程的问题。
4.基于约束的结构化稀疏注意力机制的端到端语音识别方法,包括以下步骤:
5.将待识别的语音识别样本分割为多个音频帧,提取对数梅尔谱特征,得到帧级特征矩阵;然后将帧级特征矩输入基于约束的结构化稀疏注意力机制的端到端语音识别模型进行识别;所述的基于约束的结构化稀疏注意力机制的端到端语音识别模型的处理过程包括以下步骤:
6.编码器网络对的每个帧级特征矩阵中对应帧提取该帧的高层声学表示,以得到对应的高层声学表示矩阵,第i个样本的高层编码矩阵为其中,t
i
为构成该样本的音频帧数目,d为第t个高层声学表示的维度;编码器网络由多层双向长短时记忆网络组成;
7.同时利用滑动窗对高层编码表示矩阵进行分割,生成音频帧片段,
8.对每一个高层声学编码表示矩阵对应的音频帧片段,利用全连接网络预测匹配分,以得到第i个样本在第n个解码时刻每个音频帧片段对应的匹配分向量进而得到第i个样本在第n个解码时刻的匹配分向量为
9.利用受限的结构化稀疏变换函数对匹配分向量进行归一化:
10.(1)、将匹配分向量进行从大到小排序,记第i个样本在第n个解码时刻排序后的匹配分向量为
11.(2)、利用二分查找法获得匹配分向量所对应的阈值:
12.首先,初始化阈值最小值阈值最大值
13.然后,遍历t=[1,2,...t
i
],计算τ=(τ
min
τ
max
)/2,若s<1则τ
max
=τ,否则τ
min
=τ;
[0014]
其中是音频帧片段的分段标记,λ是超参数;其中(
·
)
表示对向量中的负数全部置为0;k
i
是第i个样本的音频帧片段总数,为第i个样本中第j个音频帧片段对应的约束注意力得分向量;
[0015]
直至利用二分查找法得到最终的阈值τ,并将整合得到向量
[0016]
(3)、对匹配分向量进行归一化:第i个样本在第n个解码时刻的注意力得分向量为
[0017]
根据归一化注意力得分向量对高层声学表示矩阵进行加权求和,以得到当前解码时刻的瞥向量,第i个样本在第n个解码时刻的瞥向量为
[0018]
利用解码器网络对瞥向量进行预测,解码器网络由长短时记忆网络组成;
[0019]
直至解码器完成生成过程得到识别结果序列。
[0020]
进一步地,所述的语音识别样本是针原始语音信号进行采样与量化得到的。
[0021]
进一步地,所述的编码器网络由5层双向长短时记忆网络组成,每层的节点数为320。
[0022]
进一步地,利用滑动窗对高层编码表示矩阵进行分割生成音频帧片段的过程是滑动窗实现的,所述的滑动窗的窗长和窗移均为3。
[0023]
进一步地,利用全连接网络预测匹配分过程中所述的全连接网络包含2层,每层包含1024个节点。
[0024]
进一步地,组成的解码器网络的长短时记忆网络的节点数目为1024。
[0025]
进一步地,对匹配分向量进行归一化的同时,更新约束注意力得分向量
[0026]
进一步地,超参数λ设置为0.1。
[0027]
进一步地,所述的基于约束的结构化稀疏注意力机制的端到端语音识别模型是预先训练好的,训练过程包括以下步骤:
[0028]
步骤1:对训练集中的原始语音信号分别进行采样与量化,得到语音识别样本;
[0029]
步骤2:将每一个语音识别样本分割为多个音频帧,并根据预先指定的梅尔频带数,对这些音频帧提取经典的对数梅尔谱特征,以得到帧级特征矩阵;
[0030]
步骤3:利用编码器网络对每个帧级特征矩阵中对应帧提取该帧的高层声学表示,得到对应的高层声学表示矩阵,第i个样本的高层编码矩阵为其中,t
i
为构成该样本的音频帧数目,d为第t个高层声学表示的维度;
[0031]
利用滑动窗对高层编码表示矩阵进行分割,来生成音频帧片段,其中滑动窗的窗
长和窗移均为3;
[0032]
步骤4:初始化约束注意力得分向量其中[1,1,...,1]
t
,表示全1列向量,k
i
是第i个样本的音频帧片段总数,为第i个样本中第j个音频帧片段对应的约束注意力得分向量;
[0033]
步骤5:对步骤3中得到的每一个高层声学编码表示矩阵对应的音频帧片段,利用传统的全连接网络预测匹配分,以得到第i个样本在第n个解码时刻每个音频帧片段对应的匹配分向量进而得到第i个样本在第n个解码时刻的匹配分向量为
[0034]
步骤6:为获得均匀、连续且稀疏的注意力得分向量,利用受限的结构化稀疏变换函数对步骤5中得到的匹配分向量进行归一化,包括以下步骤:
[0035]
步骤6.1:将步骤5中得到的匹配分向量进行从大到小排序,记第i个样本在第n个解码时刻排序后的匹配分向量为
[0036]
步骤6.2:利用二分查找法获得步骤6.1中得到的匹配分向量所对应的阈值:
[0037]
首先,初始化阈值最小值阈值最大值
[0038]
然后,遍历t=[1,2,...t
i
],计算τ=(τ
min
τ
max
)/2,若s<1则τ
max
=τ,否则τ
min
=τ;
[0039]
直至利用二分查找法得到最终的阈值τ,并将整合得到向量
[0040]
步骤6.3:利用步骤6.2中得到的对步骤5中得到的匹配分向量进行归一化,记第i个样本在第n个解码时刻的注意力得分向量为
[0041]
同时更新约束注意力得分向量
[0042]
步骤7:根据步骤6.3中得到的归一化注意力得分向量对步骤3中得到的高层声学表示矩阵进行加权求和,以得到当前解码时刻的瞥向量,记第i个样本在第n个解码时刻的瞥向量为
[0043]
步骤8:利用解码器网络对步骤7中得到的瞥向量进行预测;
[0044]
步骤9:重复步骤5至步骤8,直至解码器完成生成过程,以得到识别结果序列;
[0045]
步骤10:利用训练集中全部语音识别样本,计算经典序列损失,并用其训练模型参数,进而得到训练好的语音识别模型。
[0046]
一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现基于约束的结构化稀疏注意力机制的端到端语音识别方法。
[0047]
有益效果:
[0048]
本发明提供一种基于受限的结构化稀疏注意力机制的端到端语音识别方法,其通过产生受限的结构化稀疏注意力得分,以降低注意力机制生成的瞥向量中预测无关信息占比,最终达到提升识别性能的目的,即本发明提供一种受限的结构化稀疏变换函数,通过产生均匀、连续且稀疏的注意力得分向量,以降低瞥向量中预测无关信息占比,进而达到提升
识别性能的目的。
[0049]
利用本发明进行语音识别时,字错率、词错率能够得到有效降低。
附图说明
[0050]
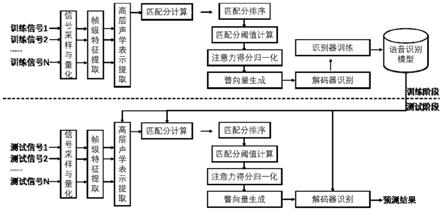
图1是基于约束的结构化稀疏注意力机制的端到端语音识别方法的示意图;
[0051]
图2是基于受限的结构化稀疏注意力机制的端到端语音识别方法与相关方法在librispeech数据集上的准确率对比柱状图。
具体实施方式
[0052]
具体实施方式一:
[0053]
本实施方式为基于约束的结构化稀疏注意力机制的端到端语音识别方法,如图1所示,在训练阶段,首先,对来自训练集的原始信号分别进行采样、量化、帧级特征提取、高层声学表示提取、匹配分计算;然后,通过匹配分排序、匹配分阈值计算、注意力得分归一化、瞥向量生成,来获得其每一解码时刻的瞥向量;最后,利用解码器进行识别,并用以训练识别器,得到语音识别模型。在测试阶段,首先,对测试集中的每一个原始语音信号进行采样、量化、帧级特征提取;然后,利用训练好的语音识别模型,对特征矩阵进行高层声学表示提取、匹配分计算;接下来,通过匹配分排序、匹配分阈值计算、注意力得分归一化、瞥向量生成,来获得其每一解码时刻的瞥向量;最后,利用训练好的语音识别模型,来得到预测结果。
[0054]
其具体过程包括以下步骤:
[0055]
步骤1:对训练集和测试集中的原始语音信号分别进行采样与量化,以得到经上述两个操作处理后的语音识别样本。在一些实施例中,采样率可取16000赫兹,量化位数可为16。
[0056]
步骤2:将步骤1中得到的每一个语音识别样本分割为多个音频帧,并根据预先指定的梅尔频带数,对这些音频帧提取经典的对数梅尔谱特征,以得到帧级特征矩阵。其中,帧长、帧间交叠、梅尔频带数可分别设置为25毫秒、10毫秒和40。
[0057]
步骤3:考虑到音频帧往往因持续时长过短,而存在包含语义信息不足的局限性。为此,利用一个编码器网络,对步骤2中得到的每个帧级特征矩阵中对应帧提取该帧的高层声学表示,以得到对应的高层声学表示矩阵,记第i个样本的高层编码矩阵为其中,t
i
为构成该样本的音频帧数目,d为第t个高层声学表示的维度。编码器网络由5层双向长短时记忆网络组成,每层的节点数为320。
[0058]
利用滑动窗对高层编码表示矩阵进行分割,来生成音频帧片段,其中滑动窗的窗长和窗移均为3。
[0059]
步骤4:
[0060]
初始化约束注意力得分向量其中[1,1,...,1]
t
,表示全1列向量,k
i
是第i个样本的音频帧片段总数,为第i个样本中第j个音频帧片段对应的约束注意力得分向量。
[0061]
步骤5:为减少预测无关信息对解码器预测过程的干扰,对步骤3中得到的每一个高层声学编码表示矩阵对应的音频帧片段,利用传统的全连接网络预测匹配分,以得到第i个样本在第n个解码时刻每个音频帧片段对应的匹配分向量进而得到第i个样本在第n个解码时刻的匹配分向量为其中,该全连接网络包含2层,每层包含1024个节点。
[0062]
步骤6:为获得均匀、连续且稀疏的注意力得分向量,利用受限的结构化稀疏变换函数对步骤5中得到的匹配分向量进行归一化,包括以下步骤:
[0063]
步骤6.1:将步骤5中得到的匹配分向量进行从大到小排序,记第i个样本在第n个解码时刻排序后的匹配分向量为
[0064]
步骤6.2:利用二分查找法获得步骤6.1中得到的匹配分向量所对应的阈值τ:
[0065]
首先,初始化阈值最小值阈值最大值
[0066]
然后,遍历t=[1,2,...t
i
],计算τ=(τ
min
τ
max
)/2,若s<1则τ
max
=τ,否则τ
min
=τ;
[0067]
其中是音频帧片段的分段标记,λ是超参数,这里设置为0.1;其中(
·
)
表示对向量中的负数全部置为0;
[0068]
直至利用二分查找法得到最终的阈值τ,并将整合得到向量
[0069]
步骤6.3:利用步骤6.2中得到的对步骤5中得到的匹配分向量进行归一化,记第i个样本在第n个解码时刻的注意力得分向量为同时更新约束注意力得分向量
[0070]
步骤7:根据步骤6.3中得到的归一化注意力得分向量对步骤3中得到的高层声学表示矩阵进行加权求和,以得到当前解码时刻的瞥向量,记第i个样本在第n个解码时刻的瞥向量为
[0071]
步骤8:利用解码器网络对步骤7中得到的瞥向量进行预测,其中解码器网络由一层长短时记忆网络组成,其节点数目为1024。
[0072]
步骤9:重复步骤5至步骤8,直至解码器完成生成过程,以得到识别结果序列。
[0073]
步骤10:利用训练集中全部语音识别样本,计算经典序列损失,并用其训练模型参数,进而得到语音识别模型。
[0074]
步骤11:利用测试集中全部语音识别样本,生成测试集的识别结果,以得到预测结果。
[0075]
步骤6中的受限的结构化稀疏归一化函数可以通过产生均匀且结构化稀疏的概率分布,来迫使模型关注少量且连续的输入语音帧片段;而且本发明所提出的方法具有闭式解,无需迭代求解算法,因此求解过程高效。
[0076]
实施例
[0077]
为了验证本发明的效果,利用实施方式一所述的基于受限的结构化稀疏注意力机制的端到端语音识别方法对对librispeech数据集进行处理,并与相关方法(传统的softmax注意力机制的处理方式)在librispeech数据集的处理效果进行对比,如图2所示的准确率对比柱状图所示,其中cer、wer分别表示字错率、词错率,dev和test分别表示开发过程、测试过程的处理准确率。通过对比本发明提出的方法和基于softmax变换函数的端到端语音识别方法的准确率,可以验证受限的结构化稀疏注意力机制在字错率、词错率上得到有效降低,效果更加优秀。
[0078]
具体实施方式二:
[0079]
本实施方式为一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现基于约束的结构化稀疏注意力机制的端到端语音识别方法。
[0080]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

