1.本发明涉及语音处理技术领域,具体来说涉及一种音色、口音可控的中英文语音合成方法及装置。
背景技术:
2.语音合成是一种将文本信息转换为语音信息的技术,即将文字信息转换为任意的可听的语音。而今,对于中英文混合文本的语音合成任务在各方面都涌现出大量需求,然而如何在保持说话人一致性的条件下,用单语数据建立多说话人、多语言的语言合成系统,并且对音色变换、口音强弱进行控制一直是一个难题。
3.传统的中英文语音合成系统依赖单人多语的语音数据库(数据录制困难、价格昂贵),并且不能对音色、口音等进行控制。
4.本发明通过输入目标音频,并从中提取说话人识别向量和语音识别向量,通过注意力网络得到了文本相关的最终说话人识别向量及语言识别向量,并通过使两者的格拉姆矩阵接近零来减小音色和语言的空间依赖,本发明可以通过输入不同的目标音频来控制语音合成系统的音色,通过不同的尺度系数来控制口音强弱,能在保持说话人一致性的条件下实现稳定、高音质的中英文语音合成。
技术实现要素:
5.本发明所要解决的技术问题是:提出一种音色、口音可控的中英文语音合成方法及装置,解决中英文的语音合成中音色、口音控制的问题。
6.本发明解决上述问题所采取的技术方案是:
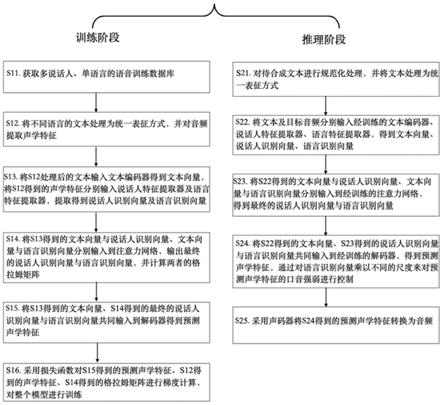
7.一种音色、口音可控的中英文语音合成方法,其特征在于,包括训练阶段和推理阶段,所述训练阶段包括以下步骤:
8.步骤s11、获取多说话人、单语言的语音训练数据库;
9.步骤s12、将不同语言的文本处理为统一表征方式,并对音频提取声学特征;
10.步骤s13、将步骤s12处理后的文本输入文本编码器,得到文本向量;并将步骤s12得到的声学特征分别输入说话人特征提取器及语言特征提取器,得到说话人识别向量及语言识别向量;
11.步骤s14、将步骤s13得到的文本向量与说话人识别向量、文本向量与语言识别向量分别输入到注意力网络,输出最终的说话人识别向量与语言识别向量,并计算两者的格拉姆矩阵grammatrix;
12.步骤s15、将步骤s13得到的文本向量、步骤s14得到的最终的说话人识别向量与语言识别向量共同输入到解码器decoder得到预测声学特征;
13.步骤s16、采用损失函数对步骤s15得到的预测声学特征、步骤s12得到的声学特征、步骤s14得到的格拉姆矩阵进行梯度计算,对整个模型进行训练。
14.进一步的,所述推理阶段包括以下步骤:
15.步骤s21.对待合成文本进行规范化处理,并处理为统一表征方式;
16.步骤s22.将文本及目标音频分别输入经训练的文本编码器、说话人特征提取器、语言特征提取器,得到文本向量、说话人识别向量、语言识别向量;
17.步骤s23.将步骤s22得到的文本向量与说话人识别向量、文本向量与语言识别向量分别输入到经训练的注意力网络,得到最终的说话人识别向量与语言识别向量;
18.步骤s24.将步骤s22得到的文本向量、步骤s23得到的说话人识别向量与语言识别向量共同输入到经训练的解码器,得到预测声学特征,通过对语言识别向量乘以不同的尺度来对预测声学特征的口音强弱进行控制;
19.步骤s25.采用声码器将步骤s24得到的预测声学特征转换为音频。
20.进一步的,为了准备训练数据,所述步骤s11还包括:每种语言各具有一定数量的说话人单语语音训练数据库,并涵盖中英文文本及对应的音频。
21.进一步的,所述步骤s12中的统一表征方式为音素、unicode编码或字符统一的表达方式;提取的声学特征包括梅尔频谱特征、线性预测系数特征lpc、线性频谱特征、基频f0、频谱包络、以及非周期信号参数。
22.进一步的,所述步骤s13中的文本编码器和步骤s15中的解码器为循环神经网络结构rnn或自注意力网络结构transformer。
23.进一步的,为了对音色、口音进行控制,所述步骤s14具体为:在注意力网络中,文本编码向量作为查询向量query,说话人识别向量或语言识别向量作为键值key
‑
value,输出最终的说话人识别向量与语言识别向量与文本编码向量步长一致。
24.进一步的,为了重构声学特征,步骤s15还包括:
25.解码器包括但不限于循环神经网络结构rnn、自注意力网络结构transformer等;
26.进一步的,为了将对音色、口音可控的语音合成模型进行训练,所述步骤s16中的损失函数为均方误差损失函数m步骤se或平均绝对误差损失函数mae。
27.进一步的,所述步骤s16为:通过预测声学特征与真实声学特征之间的损失函数实现对声学特征的重构,格拉姆矩阵与0之间的损失函数保证说话人识别特征与语言识别特征的正交,通过梯度回传对整个模型进行训练。
28.进一步的,为了将预测声学特征转换为音频,所述步骤s25中的声码器为直接将声学特征转换为音频信号的传统信号处理算法或深度学习网络预训练模型。
29.还提出一种音色、口音可控的中英文语音合成的装置,包括:
30.文本处理模块,用于将中英文文本规范化处理,并且将文本转换为统一表征方式;
31.信息编码模块,用于对经过文本处理模块处理后的文本进行编码,得到文本向量;对目标音频进行编码,得到说话人识别向量和语言识别向量;
32.注意力控制模块,用于将信息编码模块得到的文本编码向量作为查询向量,将信息编码模块得到的说话人识别向量以及语言识别向量作为键值,输出注意力加权后的最终说话人识别向量和语言识别向量;
33.信息解码模块,用于输入经信息编码模块得到的文本向量、注意力控制模块得到的最终说话人识别向量及语言识别向量,输出预测声学特征;
34.声码器模块,用于输入信息解码模块得到的预测声学特征,输出音频。
35.本发明的有益效果是:在编码解码的语音合成模型结构中,通过对目标音频提取
与文本向量每个步长相对应的说话人识别向量及语言识别向量,计算格拉姆矩阵来保证两者正交,实现了中英文语音合成中对音色变换、口音强弱的控制。
附图说明
36.图1为本发明实施例所述的一种音色、口音可控的中英文语音合成方法的流程示意图;
37.图2为本发明实施例所述的一种音色、口音可控的中英文语音合成模型的结构及训练流程图。
具体实施方式
38.下面将结合附图对本发明的实施方式进行详细描述。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是本发明的全部实施例,应理解的,本发明不受这里描述的实施例的限制。
39.实施例1
40.如图1所示,本发明实施例的一种音色、口音可控的中英文语音合成的方法,包括训练阶段和推理阶段;
41.其中,训练阶段包括以下步骤:
42.s11.获取多说话人、单语言的语音训练数据库;
43.可选的,英文语音合成数据集可以使用ljspeech、vctk等公开数据集,中文语音合成数据集使用标贝公司的女生语音数据库以及录制的涵盖20多个人声音的语音数据库。
44.可理解的,每种语言各具有一定数量的说话人单语语音训练数据库,涵盖中英文文本及对应的音频;
45.s12.将不同语言的文本处理为统一表征方式,并对音频提取声学特征;
46.可选的,将不同语言的文本处理为音素、unicode编码、字符等统一的表达方式;提取的声学特征包括但不限于梅尔频谱特征、线性预测系数特征lpc、线性频谱特征、基频f0、频谱包络、非周期信号参数等;
47.举例说明,英文文本为“who met him at the door.”,将英文文本转换为音素表达方式,得到“h u1 m ai1 t h i1 m a1 t s i a0 d uo1 r pp4”;中文文本为“我是中国人,我爱中国”,处理为统一的音素表达方式,得到“uo3 sh iii4 pp1 zh ong1 g uo2 r en2 pp3 uo3 ai4zh ong1 g uo2pp4”,再将音素表达通过字符字典转换为对应的id用于训练,对文本对应的音频提取梅尔频谱特征用于训练。
48.s13.将s12处理后的文本输入文本编码器得到文本向量,并将s12得到的声学特征分别输入说话人特征提取器及语言特征提取器,提取得到说话人识别向量及语言识别向量;
49.可选的,文本编码器包括但不限于循环神经网络结构rnn、自注意力网络结构transformer等;说话人特征提取器及语言特征提取器包括但不限于分别从音频中提取韵律向量,同时辅以说话人分类网络、语言分类网络来提取说话人识别向量、语言识别向量;
50.举例说明,将处理后的文本经字典转化为id再输入transformer结构的文本编码器得到文本向量,说话人特征提取器与语言特征提取器采用卷积加双向lstm的网络结构,
提取器的网络结构相同,但是分别加入了说话人分类与语言分类的辅助网络,将s12提取的梅尔频谱声学特征分别输入说话人特征提取器与语言特征提取器,得到了说话人识别向量与语言识别向量;
51.s14.将s13得到的文本向量与说话人识别向量、文本向量与语言识别向量分别输入到注意力网络,输出最终的说话人识别向量与语言识别向量,并计算两者的格拉姆矩阵grammatrix;
52.可理解的,在注意力网络中,文本编码向量作为查询向量query,说话人识别向量或语言识别向量作为键值key
‑
value,输出与文本编码向量步长一致的最终的说话人识别向量与语言识别向量;
53.s15.将s13得到的文本向量、s14得到的最终的说话人识别向量与语言识别向量共同输入到解码器decoder得到预测声学特征;
54.可选的,解码器包括但不限于循环神经网络结构rnn、自注意力网络结构transformer等。
55.s16.采用损失函数对s15得到的预测声学特征、s12得到的声学特征、s14得到的格拉姆矩阵进行梯度计算,对整个模型进行训练;
56.可选的,损失函数包括但不限于均方误差损失函数mse、平均绝对误差损失函数mae等;可理解的,预测声学特征与真实声学特征之间的损失函数实现了对声学特征的重构,gram矩阵与0之间的损失函数保证说话人识别特征与语言识别特征的正交;通过梯度回传对整个模型进行训练;
57.推理阶段包括以下步骤:
58.s21.对待合成文本进行规范化处理,并将文本处理为统一表征方式;
59.s22.将文本及目标音频分别输入经训练的文本编码器、说话人特征提取器、语言特征提取器,得到文本向量、说话人识别向量、语言识别向量;
60.s23.将s22得到的文本向量与说话人识别向量、文本向量与语言识别向量分别输入到经训练的注意力网络,得到最终的说话人识别向量与语言识别向量;
61.s24.将s22得到的文本向量、s23得到的说话人识别向量与语言识别向量共同输入到经训练的解码器,得到预测声学特征,通过对语言识别向量乘以不同的尺度来对预测声学特征的口音强弱进行控制;
62.可选的,推理阶段的文本处理方式与训练阶段基本一致;推理阶段的文本编码器、说话人特征提取器、语言特征提取器、解码器的参数由训练阶段得到,并且网络结构保持一致;可理解的,推理阶段可以根据需要输入不同的目标音频来控制音色;可理解的,推理阶段可以根据需要指定语言识别向量的尺度系数,通过尺度系数来控制语言口音强弱;
63.举例说明,带合成文本为“我爱china”,经处理为统一的音素表达,得到“uo3 ai4 ch ai1 n a0 pp4”,再通过字符字典转换为相应的id,这里假设为“3,21,4,30,7,10,50”,再输入文本编码器输出文本向量,对目标音频提取梅尔频谱并输入说话人特征提取器与语言特征提取器,输出说话人识别向量与语言识别向量,将文本向量作为查询向量,通过注意力网络输出最终的说话人识别向量与语言识别向量,再将最终的语言识别向量乘上尺度系数与说话人向量、文本向量一同输入解码器得到预测的声学特征;
64.s25.采用声码器将s24得到的预测声学特征转换为音频。
65.可选的,所述声码器包括但不限于直接将声学特征转换为音频信号的传统信号处理算法(如word、griffin
‑
lim等)以及深度学习网络预训练模型(如wavernn、wavenet等)。
66.通过本实施例1所提供的一种音色、口音可控的中英文语音合成方法,对目标音频提取说话人识别向量、语言识别向量,同时通过注意力网络将其与文本步长进行对齐,得到与文本位置对应的最终说话人识别向量与语言识别向量,将语言识别向量乘以尺度系数,与说话人识别向量、文本向量共同输入解码器得到预测声学特征,通过声码器将其转换为了音频,实现了对音色、口音强弱的控制。训练过程只需要使用多说话人的单语数据,并且语音合成速度极快,合成的语音音质高,稳定性好,能在保持说话人音色一致性的条件下实现不同语言间的流利转换。
67.实施例2
68.本发明实施例提供一种音色、口音可控的中英文语音合成装置,包括:
69.文本处理模块,用于将中英文文本规范化处理,并且将文本转换为统一的表达方式;
70.可选的,对带合成文本进行正则化等前处理,将不同语言的文本处理为音素、unicode编码、字符等统一的表达方式,再通过字符字典转化为数字id;
71.信息编码模块,用于对经过文本处理模块处理后的文本进行编码,得到文本向量,对目标音频进行编码,得到说话人识别向量和语言识别向量;
72.可选的,通过文本编码器对文本处理模块的处理结果输出文本编码向量,通过说话人特征提取器与语言特征提取器对目标音频提取得到说话人识别向量、语言识别向量
73.注意力控制模块,用于将信息编码模块得到的文本编码向量作为查询向量,将信息编码模块得到的说话人识别向量以及语言识别向量作为键值,输出注意力加权后的最终说话人识别向量和语言识别向量;
74.可理解的,在注意力网络中,文本编码向量作为查询向量(query),说话人识别向量或语言识别向量作为键值(key
‑
value),输出与文本编码向量步长一致的最终的说话人识别向量与语言识别向量;
75.信息解码模块,用于输入经信息编码模块得到的文本向量、注意力控制模块得到的最终说话人识别向量及语言识别向量,输出预测声学特征;
76.可理解的,通过选取不同的目标音频可以对音色进行控制,通过乘以不同的尺度系数,可以对口音强弱进行控制;
77.声码器模块,用于输入信息解码模块得到的预测声学特征,输出音频。
78.可选的,声码器包括但不限于直接将声学特征转换为音频信号的传统信号处理算法(如word、griffin
‑
lim等)以及深度学习网络预训练模型(如wavernn、wavenet等)。
79.通过本实施例2所提供的一种音色、口音可控的中英文语音合成装置,文本处理模块将中英文文本转换为统一表征方式,信息编码模块分别从文本和音频提取了文本向量、说话人识别向量与语言识别向量,注意力控制模块得到了文本对应的说话人识别向量与语言识别向量,信息解码、声码器模块得到了合成音频。本专利可通过选取不同目标音频对音色进行控制,通过乘以不同的尺度系数对口音强弱进行控制,训练过程只需要使用多说话人的单语数据,并且语音合成速度极快,合成的语音音质高,稳定性好,能在保持说话人音色一致性的条件下实现不同语言间的流利转换。
80.综上所述,在阅读本详细公开内容之后,本领域技术人员可以明白,前述详细公开内容可以仅以示例的方式呈现,并且可以不是限制性的。尽管这里没有明确说明,本领域技术人员可以理解本技术意图囊括对实施例的各种合理改变,改进和修改。这些改变,改进和修改旨在由本技术提出,并且在本技术的示例性实施例的精神和范围内。
81.最后,应理解,本文公开的申请的实施方案是对本技术的实施方案的原理的说明。其他修改后的实施例也在本技术的范围内。因此,本技术披露的实施例仅仅作为示例而非限制。本领域技术人员可以根据本技术中的实施例采取替代配置来实现本技术中的申请。因此,本技术的实施例不限于申请中被精确地描述过的实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

