本发明属于声纹识别技术领域,特别涉及一种用于说话人验证的深度神经网络模型和训练策略。
技术背景
说话人验证是一种通过验证语音和注册语音来验证说话人身份的过程。由于语音特征采集方便,用户接受度更高,成年人的声音可以在较长时期内保持相对稳定,因此说话人验证在金融、刑侦、民用等领域具有广泛的应用场景和应用需求。
近年来,采用深度神经网络进行说话人验证已成为主流。说话人验证系统使用深度神经网络把语音特征信号转换为可以区分的固定维度的嵌入矢量,如使用dnn、cnn、lstm或残差cnn网络与lstm结合的神经网络等,使用端到端的损失函数来训练神经网络对语音进行区分验证。
当前区分效果较好的模型一类是采用单个神经网络通路提取语音的嵌入矢量特征,根据神经网络计算所得到的结果寻找三元组,计算三元组损失函数来进行训练;另一类是采用两个孪生神经网络通路分别提取验证语音和注册语音的嵌入矢量特征,通过验证语音嵌入矢量和注册语音嵌入矢量的相似性来判断验证语音是否和注册语音属于同一人,采用交叉熵损失函数来训练网络。这两类模型要得到好的性能需要依赖于大的数据集,训练时间也比较长,对于短语音、较小的数据集则准确性不高。
三元组损失函数是目前应用广泛且性能较好的损失函数。形成三元组样本时,样本的数量会急剧上升,会产生大量冗余且信息量低的训练样本。三元组损失函数的一个问题是,只有正例和负例之间的差值大于某一阈值时,才会对梯度有贡献。使用三元组损失函数时,需要在小批量中找出有较多信息量的三元组,一方面,不可能把全部的训练样本放在一个小批量里,因此网络优化只能在一个小批量中进行,无法考虑全局数据分布,会造成局部最优;另一方面,在一个小批量中,信息量多的训练样本比较少,而且经过几次迭代训练后,大部分三元组就不会对梯度有贡献了,造成收敛慢,性能差。
技术实现要素:
1.一种神经网络模型,其特征在于:
1)输入为2m 1条语音声学特征矢量,其中m条来自说话人p1,为
2)来自说话人p1的m条语音声学特征矢量
4)
5)如果锚点语音来自p1,则
6)
7)验证时,可以把
2.根据权利1要求的神经网络模型,其特征在于,其所述神经网络的迭代训练过程和策略为:
1)获取预设数量语音数据样本,把语音数据样本按对应的说话人身份分组,对每个语音数据样本进行活动端点检测(voiceactivitydetection,vad),将非语音的空白部分删去,把语音样本切割或补足为预定长度的标准语音段,得到标准的语音样本;
2)对每个标准的语音样本,按照预设的分帧参数进行分帧处理,获得语音帧组,然后再利用预设的滤波器提取语音帧组中每一个语音帧的预设类型声学特征,形成语音样本的语音声学特征矢量,所述预设滤波器可以是mel滤波器,所述预设类型声学特征可以是mel滤波器组fbank特征矢量或mel倒谱系数mfcc特征矢量,所述滤波器也可以是空的,则所述预设类型声学特征是原始语音形成的矢量;
3)把说话人按预定比例分为训练集和测试集;
4)从训练集中随机抽取n个两说话人组,从每个两说话人组中随机抽取2m 1条语音声学特征矢量,构成一个包含n个三元组的数据子集,按预定比例分为三元组训练集和三元组验证集,从测试集中随机抽取的两说话人组,从每个两说话人组中随机抽取语音声学特征矢量,构成三元组测试集;
5)把三元组数据子集分为b批,送入所述神经网络模型中进行迭代训练,训练次数设定为较小次数,迭代次数完成后,重复步骤4)和步骤5),直到测试达到了预设的损失或准确率;
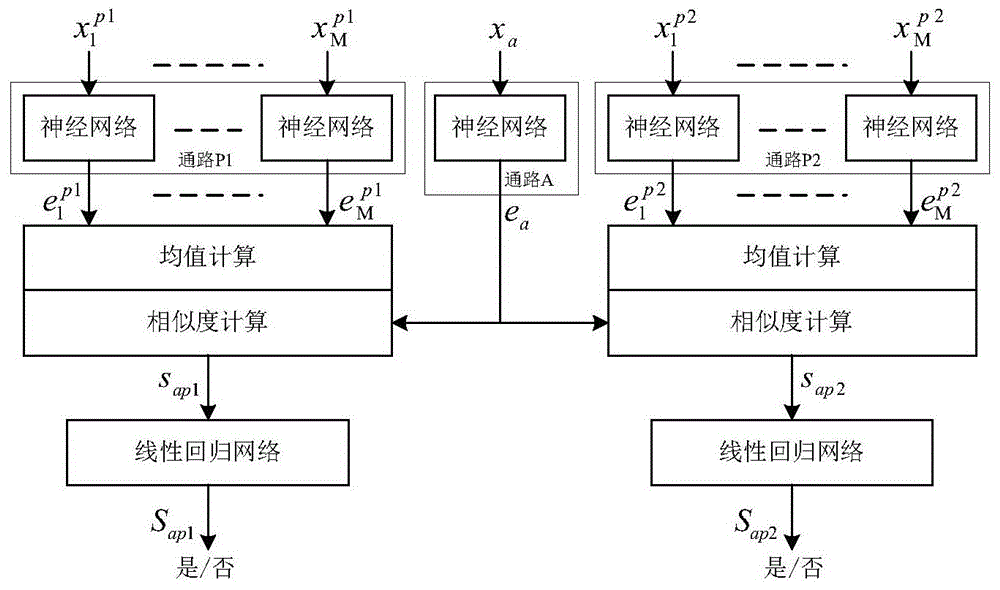
3.一种神经网络模型结构,其特征在于:
1)由三个神经网络通路、说话人相似度计算模块、线性回归模块构成;
2)三个神经网络通路:包括2m 1个相同结构的预设孪生神经网络,其中m个构成用于说话人p1的m条语音声学特征矢量
3)说话人相似度计算模块:包括两个相同的相似度计算模块,每个模块包括一个均值计算模块和一个相似度计算模块,两个均值计算模块分别计算语音嵌入矢量
4)线性回归模块:是两个相同的线性回归网络,每一个都是由一个全连接层和激活函数组成,
有益效果
本发明对比已有技术具有以下创新点:
1.提出了一种三元组神经网络模型,使用了三个神经网络通路分别对锚点语音、p1说话人语音和p2说话人语音进行特征提取。
2.采用多损失函数进行多任务训练优化,加速神经网络的收敛,提高验证性能。
3.对语音数据处理,形成语音声学特征数据集,对数据集多次采样构成多个数据子集,用多个数据子集对神经网络进行小迭代次数渐进式训练,克服局部最优,加速神经网络收敛。
本发明对比现有技术具有以下显著优点:
1.使用三元组神经网络模型,采用多损失函数对网络进行多任务训练优化,可以加快收敛速度,提高说话人验证的准确性。
2.采用多数据子集、小迭代次数渐进式训练策略,可以加快收敛速度,缩短训练时间,克服局部最优的问题。
附图说明
图1为本发明神经网络模型结构的示意图;
图2为本发明实施例的示意图;
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
本发明的基本思想是用三元组深度神经网络实现说话人验证,用多损失函数训练优化三元组神经网络,用多数据子集、小迭代次数渐进式训练策略,加快收敛速度,缩短训练时间,提高说话人验证的准确性,克服局部最优。
实施例1
采用附图2所示的神经网络结构对本发明的原理和特征进行描述,所举实施例只用于解释本发明,并非用于限定本发明的范围。
本实施例的神经网络结构包括:
1)三个神经网络通路:包括2m 1个相同结构的孪生神经网络,m个用于说话人p1的m条语音声学特征矢量
2)两个相似度计算模块:每个模块包括一个均值计算模块和一个相似度计算模块,两个均值计算模块分别计算语音嵌入特征矢量
3)两个线性回归网络:每个线性回归网络是一个全连接层,输出连接激活函数,激活函数为sigmoid函数,一个线性回归网络把
4)采用两个交叉熵损失函数对网络进行优化。
本实施例中的深度神经网络模型的训练过程和策略为:
1)获取预设数量语音数据样本,把语音数据样本按对应的说话人身份分组,对每个语音样本进行活动端点检测(voiceactivitydetection,vad),删去语音样本中无话音的部分,把语音样本切割或补足为预定长度的标准语音段,得到标准的语音样本;
2)对每个标准语音样本按照预设的分帧参数进行分帧处理(预设的分帧参数例如:帧长为25ms,帧移为10ms),获得对应于语音样本的语音帧组,对每一帧用预设的滤波器,如mel滤波器,提取出声学特征,如40维mel滤波器组fbank特征,形成声学特征样本;
3)把声学特征样本按说话人以预定比例分为训练集和测试集;
4)从训练集中随机抽取的n个两说话人组,从每个两说话人组中随机抽取2m 1条语音声学特征矢量,构成一个包含n个三元组的数据子集,按预定比例分为三元组训练集和三元组验证集,从测试集中随机抽取的二说话人组,从每个二说话人组中随机抽取语音声学特征矢量,构成三元组测试集;
5)把三元组数据子集分为b批,送入到所述神经网络中进行迭代训练,训练次数设定为较小次数,迭代次数完成后,重复步骤4)和步骤5),直到测试达到了预设的损失或准确率;
采用本实施例的深度神经网络模型和采样训练策略,可以加快收敛速度,缩短训练时间,提高说话人验证的准确性,克服局部最优的问题。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

