本发明涉及语音处理和图像处理领域,具体涉及一种无需原始数据存储的持续性学习生成语音特征的方法。
背景技术:
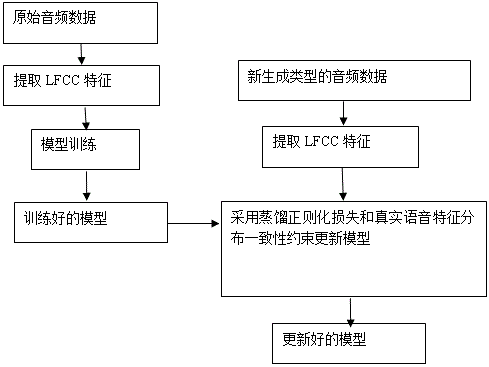
:生成语音检测是判别音频为真实人声还是由录音、语音合成、语音转换技术生成的生成语音。现有的用特定的数据集训练的生成语音鉴别模型对于与训练数据不匹配的未知生成语音检测的能力大大降低,泛化性能较低。同时,随着语音合成、语音转换技术的不断发展,生成语音手段也层出不穷,然而现有的生成语音检测方案均面临着模型泛化性能不足的问题,对于训练数据集中未知的生成类型,没有一种具有高鲁棒性、良好泛化性的模型可以保证将其检测出来,比如在asvspoof2019la数据集上训练的模型,由于没有见过生成类型,所以在asvspoof2019pa数据集上效果大大降低,再比如在由有限语音合成技术进行生成的数据集上训练的模型很难检测出新的合成生成语音。使用现有生成语音数据一次性训练好生成语音鉴别模型并不现实,当有新的语音生成手段出现时,可以将新数据与原有数据混合一起重新训练模型,但是随着数据量的增加,会带来计算和存储资源的线性增长,开销过大;而且由于特殊数据的隐私保护问题,长期存储原有数据可能无法实现;此外对于在线不断更新的生成语音检测模型而言,无法做到联合旧数据重新训练。针对上述问题,使得模型具有持续性学习新型生成语音的能力显得尤为重要。为了提升模型对于未知生成语音的鉴别性能,也可考虑模型微调,联合训练,提取更具泛化性的声学特征等等。采用模型微调,用原有模型在新数据将进行微调会产生“灾难性遗忘”现象,带来在原有数据集上性能的大大降低;联合训练会产生较大的时间、计算资源的开销,在一些特殊情境下,由于隐私保护或者其他涉密原因会导致无法获取原始数据,所以无法联合所有数据一起训练。针对模型对于未知数据集的检测性能明显降低的问题,目前已有一些相关技术研究:1.多模型融合方法:针对每个数据集训练一个生成语音鉴别模型,然后将多个模型进行融合,综合打分。2.双向对抗领域自适应方法:此方法是领域对抗训练的延伸,在网络上加入两个分别针对真实和生成语音的领域鉴别器,采用源域的带标签的数据和目标域无标签数据进行训练,提升对于领域不匹配数据集的性能。3.提取其他泛化性特征:此方法是从传统信号处理角度,设计前端特征提取器,希望采用更具泛化性的特征,如:扩展的cqcc,cqspic系数等。但是上述研究的存在缺陷在于:多模型融合方法需要新旧数据一同训练,会加大训练成本的开销;双向对抗领域自适应方法只关注在新数据上的性能,而忽视掉了训练后的数据在旧数据集上的效果;提取其他特征也无法保证该特征对所有生成语音类型检测的性能。连续学习问题则研究如何克服微调所遇到的“灾难性遗忘”问题,即使模型在学习到新任务的同时保证在旧任务上的记忆能力,可以只利用新数据持续不断地更新。除了上述问题以外,在实际应用中,人们不光需要知道语音的真伪信息,还希望知道具体的生成类型。此时简单的二分类不足以使模型的输出判断具有说服性,所以将原有的真伪二分类改成生成类型多分类更具实际意义。公开号为cn111564163a公开了一种基于rnn的多种伪造操作语音检测方法,包括如下步骤:1)获取原始语音样本,对所述原始语音样本进行m种伪造处理,得到m个伪造操作后的语音和1个未经处理的原始语音,对上述语音进行特征提取,得到训练语音样本的lfcc矩阵,送入rnn分类器网络中进行训练,得到一个多分类的训练模型;2)得到一段测试语音,对该测试语音进行特征提取,得到测试语音数据的lfcc矩阵,送入由步骤1)训练好的rnn分类器中进行分类,每一个测试语音得到一个输出概率,合并所有输出概率作为最后的预测结果:如果预测结果是原始语音,则测试语音被识别为原始语音;如果预测结果是经过某一伪造操作的语音,则测试语音被识别为进行相应伪造操作的伪造语音。公开号为cn112712809b公开了一种语音检测方法、装置、电子设备及存储介质。从待检测语音中提取出多个语音特征信息;将语音特征信息分别输入至预先训练好的多个语音来源模型中,确定待检测语音与每个语音来源模型的来源类型之间的第一匹配度;针对于每个语音类别模型,基于确定出的第一匹配度,确定待检测语音与该语音类别模型对应的类别类型之间的第二匹配度;基于确定出的多个第一匹配度和多个第二匹配度,确定待检测语音的类别类型和来源类型。现有技术缺点:当有新的生成类型出现,需要模型更新时,有两种常见的解决方案:直接微调、新旧数据混合重新训练,但是会有计算开销大,重头训练时间长的问题。针对未知类型的生成语音,目前有多模型融合和自适应训练的方法,但也存在相应的缺点。1.直接微调:用新数据在已有的模型上进行训练,会让模型在新数据上的效果变好,但是使模型在以前的数据上识别效果大大降低。2.重头训练:将新旧数据重合起来重头训练,当数据不断增加时,会使得一次训练的时间越来越长,增加时间代价和计算开销。3.多模型融合:每次新增一种类型就新增一个模型,会带来存储上的开销。4.领域对抗自适应:需要新旧数据一同训练,在某些情况下,由于隐私安全等因素,旧数据不可获得时,无法使用该方法。此外,现有方法都针对真伪二分类,在实际应用中,人们不光需要知道语音的真伪信息,还希望知道具体的生成类型,所以生成类型多分类具有重要意义。技术实现要素:有鉴于此,本发明提供一种无需原始数据存储的持续性学习生成语音特征的方法,所述方法包括:s1:采集音频数据,提取音频声学特征,得到lfcc特征;s2:应用所述lfcc特征对深度学习网络模型进行训练,得到源域模型;s3:在源域模型的训练损失函数基础上加入了正则化损失,约束模型参数优化的方向,应用新生成类型的音频数据对所述源域模型进行模型参数更新,得到目标域模型。优选的,所述提取音频声学特征,得到lfcc特征的具体方法包括:将采集到的音频数据进行采样,得到原始波形点,然后进行预加重、分帧、加窗和快速傅里叶变换,得到傅里叶功率谱;将所述傅里叶功率谱通过线性滤波器组、取对数、进行dct变换,得到音频的60维lfcc特征;其中窗口长度为25帧,进行512维fft。优选的,所述深度学习网络模型为轻量级卷积神经网络。优选的,其特征在于,所述轻量级卷积神经网络最后通过全连接层输出为n分类结果,包括真实语音和n-1种不同类型的生成语音。优选的,所述n设置为50。优选的,所述正则化损失包括蒸馏正则化损失和真实语音特征分布一致性约束。优选的,目标域模型的训练损失函数l总损失为:其中,l原始:源域模型的训练损失函数;l蒸馏:蒸馏正则化损失;α:蒸馏正则化损失的权重,0.5≤α≤1;l真实:真实语音特征分布一致性约束;β:真实语音特征分布一致性约束的权重,1≤β≤1.5。优选的,所述蒸馏正则化损失的具体公式为:其中,:对于新采集的音频数据,第i个类别的样本,经过源域模型输出的预测概率;:对于新采集的音频数据,源域模型的输出的累加;:第i个类别的样本,经过目标域模型输出的预测概率;:目标域模型的输出的累加;t:温度超参数。优选的,所述温度超参数的参数设置为1≤t≤2。优选的,所述真实语音特征分布一致性约束的具体公式为:其中,:真实语音的总数;:源域模型输出的第k条真实语音的嵌入特征向量;:目标域模型输出的第k条真实语音的嵌入特征向量;:源域模型输出的第k条真实语音的嵌入特征向量的模长;:目标域模型输出的第k条真实语音的嵌入特征向量的模长。本申请实施例提供的上述技术方案与现有技术相比具有如下优点:1、时间、计算、存储开销:每次更新模型只需用到上一次训练好的模型和新数据;2、持续性增量式学习:符合生成手段不断更新的现状,随着生成技术的发展,生成语音鉴别模型也在不断进化;3、模型在旧有数据上的效果不会减低到无法接受:只利用新数据,模型在旧数据的上的效果有一定下降,但是并非灾难性的,效果远优于之际微调模型;4、输出为对分类生成类别,对具体生成类型进行检测。附图说明图1为本发明实施例提供的无需原始数据存储的持续性学习生成语音特征的方法流程图;图2为本发明实施例提供的相比于直接微调,连续学习的优势示意图。具体实施方式这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。如图1所示,本申请实施例提供的无需原始数据存储的持续性学习生成语音特征的方法,包括:s1:采集音频数据,提取音频声学特征,得到lfcc特征,具体方法包括:将采集到的音频数据进行采样,得到原始波形点,然后进行预加重、分帧、加窗和快速傅里叶变换,得到傅里叶功率谱;将所述傅里叶功率谱通过线性滤波器组、取对数、进行dct变换,得到音频的60维lfcc特征;其中窗口长度为25帧,进行512维fft;s2:应用所述lfcc特征对深度学习网络模型进行训练,得到源域模型;所述深度学习网络模型为轻量级卷积神经网络,包括卷积层、最大池化层、最大特征映射输出、批归一化操作等操作,最后得到80维度的嵌入特征向量,最后通过全连接层输出为n分类结果,包括真实语音和n-1种不同类型的生成语音(不同录音设备、不同声码器、不同方式的生成语音),为了给未来而可能出现的生成语音提供预留的分类输出头,预先设定n=50;对深度学习网络模型进行训练的具体方法为:模型训练150轮,选择自适应矩估计优化器,初始学习率设为0.001,每一批数据大小为128个;模型更新是基于前一步训练好的源域模型,在前一步训练好的源域模型的基础上采用新数据进行进一步训练,即利用上一步训练好的源域模型参数对目标域模型初始化;常见的模型微调的操作为:用新数据,使用交叉熵或者其他损失函数直接进行模型参数优化;本方法基于连学习,在原有的损失函数基础上加入了正则化约束,约束模型参数优化的方向;如图2所示,相比于直接微调,连续学习的优势在于:模型微调常常伴随着微调后的模型对原有数据知识的“灾难性遗忘”,即单纯采用微调策略,会导致最终的模型优化结果很容易落入与原任务差异显著的区域,而带来在原任务上,模型的性能大大下降;但是采用连续学习方法后,可以使得更新后的模型参数仍在原有模型最优参数区域附近,从而保证模型在学习到新任务的同时保证在旧任务上的记忆能力;s3:在源域模型的训练损失函数基础上加入了正则化损失,约束模型参数优化的方向,所述正则化损失包括蒸馏正则化损失和真实语音特征分布一致性约束,应用新生成类型的音频数据,提取新数据的相应声学特征(lfcc),然后同样选择自适应矩估计优化器,初始学习率设为0.0001,批数据大小为64,训练20轮,对所述源域模型进行模型参数更新,得到目标域模型;所述目标域模型的训练损失函数l总损失为:其中,l原始:源域模型的训练损失函数;l蒸馏:蒸馏正则化损失;α:蒸馏正则化损失的权重,α=0.7;l真实:真实语音特征分布一致性约束;β:真实语音特征分布一致性约束的权重,β=1.2;所述蒸馏正则化损失的具体公式为:其中,:对于新采集的音频数据,第i个类别的样本,经过源域模型输出的预测概率;:对于新采集的音频数据,源域模型的输出的累加;:第i个类别的样本,经过目标域模型输出的预测概率;:目标域模型的输出的累加;t:温度超参数,t=2;所述真实语音特征分布一致性约束的具体公式为:其中,:真实语音的总数;:源域模型输出的第k条真实语音的嵌入特征向量;:目标域模型输出的第k条真实语音的嵌入特征向量;:源域模型输出的第k条真实语音的嵌入特征向量的模长;:目标域模型输出的第k条真实语音的嵌入特征向量的模长。实施例在asvspoof2019la数据集中,选择其中的a13,a17,a10,a19四种生成语音类型和真实语音,采用最终输出类别数为50的轻量级卷积神经网络;先用a13和真实语音一同训练网络,真实语音标签为0,a13的标签为1,得到模型1;然后在此基础上使用a17和真实语音,真实语音标签为0,a17的标签为2,进一步进行模型更新,此时模型训练的损失函数为l总损失=l原始 αl蒸馏 βl真实,α=0.7,β=1.2,得到模型2;与之对比的为模型1在a17和真实语音直接微调得到的微调2;然后在此基础上使用a10和真实语音,真实语音标签为0,a10的标签为3,进一步进行模型更新,此时模型训练的损失函数l总损失=l原始 αl蒸馏 βl真实,α=0.7,β=1.2,得到模型3;与之对比的为微调2在a10和真实语音直接微调得到的微调3;然后在此基础上使用a19和真实语音,真实语音标签为0,a10的标签为3,进一步进行模型更新,此时模型训练的损失函数为l总损失=l原始 αl蒸馏 βl真实,α=0.7,β=1.2,得到模型4;与之对比的为微调3在a19和真实语音直接微调得到的微调4;分别测试模型1对a13,a17,a10,a19检测的eer,取平均得到avg_eer1;分别测试模型2对a13,a17,a10,a19检测的eer,取平均得到avg_eer2;分别测试模型3对a13,a17,a10,a19检测的eer,取平均得到avg_eer3;分别测试模型4对a13,a17,a10,a19检测的eer,取平均得到avg_eer4;分别测试微调2对a13,a17,a10,a19检测的eer,取平均得到avg_eer_2;分别测试微调3对a13,a17,a10,a19检测的eer,取平均得到avg_eer_3;分别测试微调4对a13,a17,a10,a19检测的eer,取平均得到avg_eer_4;下表的评价指标是平均eer(平均等错误率),平均等错误率越低,效果越好,结果如下:加入a13加入a17加入a10加入a19本方法0.8113.8344.3128.032微调0.81114.42214.40443.719可以看到本方法优于直接微调。在本发明使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。应当理解,尽管在本发明可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本发明范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。虽然本说明书包含许多具体实施细节,但是这些不应被解释为限制任何发明的范围或所要求保护的范围,而是主要用于描述特定发明的具体实施例的特征。本说明书内在多个实施例中描述的某些特征也可以在单个实施例中被组合实施。另一方面,在单个实施例中描述的各种特征也可以在多个实施例中分开实施或以任何合适的子组合来实施。此外,虽然特征可以如上所述在某些组合中起作用并且甚至最初如此要求保护,但是来自所要求保护的组合中的一个或多个特征在一些情况下可以从该组合中去除,并且所要求保护的组合可以指向子组合或子组合的变型。类似地,虽然在附图中以特定顺序描绘了操作,但是这不应被理解为要求这些操作以所示的特定顺序执行或顺次执行、或者要求所有例示的操作被执行,以实现期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分离不应被理解为在所有实施例中均需要这样的分离,并且应当理解,所描述的程序组件和系统通常可以一起集成在单个软件产品中,或者封装成多个软件产品。由此,主题的特定实施例已被描述。其他实施例在所附权利要求书的范围以内。在某些情况下,权利要求书中记载的动作可以以不同的顺序执行并且仍实现期望的结果。此外,附图中描绘的处理并非必需所示的特定顺序或顺次顺序,以实现期望的结果。在某些实现中,多任务和并行处理可能是有利的。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

