【技术领域】
本揭露是有关于一种自动调整方法及应用其的电子装置,且特别是有关于一种自动调整特定声源的方法及应用其的电子装置。
背景技术:
随着科技的发展,各式影音娱乐装置不断推陈出新。在该多个装置中,声音频信号直接影响到使用者的感受。为了提供给使用者更好的感受,研究人员需要针对原始声音频信号中的特定声源进行放大处理。
然而,在传统的技术中,是在检测到特定声源时,直接将整个原始声音频信号进行放大。此种方式虽然增加了临场感,但背景音乐以及其他声源同步被调整和放大,snr的比率并没有改变,对于使用者并没有太大的帮助。因此,研究人员希望能够仅针对特定声源做适当的调整而不影响其他声源,提高snr的比率。
技术实现要素:
本揭露是有关于一种自动调整特定声源的方法及应用其的电子装置,其通过判定声源数量、分离声源等技术自动调整特定声源,而将原始声音频信号转换为调整后声音频信号再输出至耳机,以提供给使用者更好的感受。
根据本揭露的第一方面,提出一种自动调整特定声源的方法。自动调整特定声源的方法包括以下步骤。对一原始声音频信号进行数种特定声源的一机率辨识程序。依据原始声音频信号的机率辨识程序的结果,判断原始声音频信号的声源数量。若原始声音频信号的声源数量大于或等于二,则对原始声音频信号进行一方向性分析程序。依据原始声音频信号的方向分析程序的结果,分离出至少一特定方向子信号。对特定方向子信号进行此些特定声源的机率辨识程序。依据特定方向子信号的机率辨识程序的结果,判断特定方向子信号的声源数量。若特定方向子信号的声源数量等于一,则进行一声源调整程序。
根据本揭露的第二方面,提出一种自动调整特定声源的电子装置。电子装置包括一第一声音信号辨识单元、一第一多声源判定单元、一方向性分析单元、一方向性分离单元、一第二声音信号辨识单元、一第二多声源判定单元及一声音信号调整单元。第一声音信号辨识单元用以对一原始声音频信号进行数种特定声源的一机率辨识程序。第一多声源判定单元用以依据原始声音频信号的机率辨识程序的结果,判断原始声音频信号的声源数量。若原始声音频信号的声源数量大于或等于二,则方向性分析单元对原始声音频信号进行一方向性分析程序。方向性分离单元用以依据原始声音频信号的方向分析程序的结果,分离出至少一特定方向子信号。第二声音信号辨识单元用以对特定方向子信号进行此些特定声源的机率辨识程序。第二多声源判定单元用以依据特定方向子信号的机率辨识程序的结果,判断特定方向子信号的声源数量。若特定方向子信号的声源数量等于一,则声音信号调整单元进行一声源调整程序。
为了对本揭露的上述及其他方面有更佳的了解,下文特举实施例,并配合所附图式详细说明如下:
【附图说明】
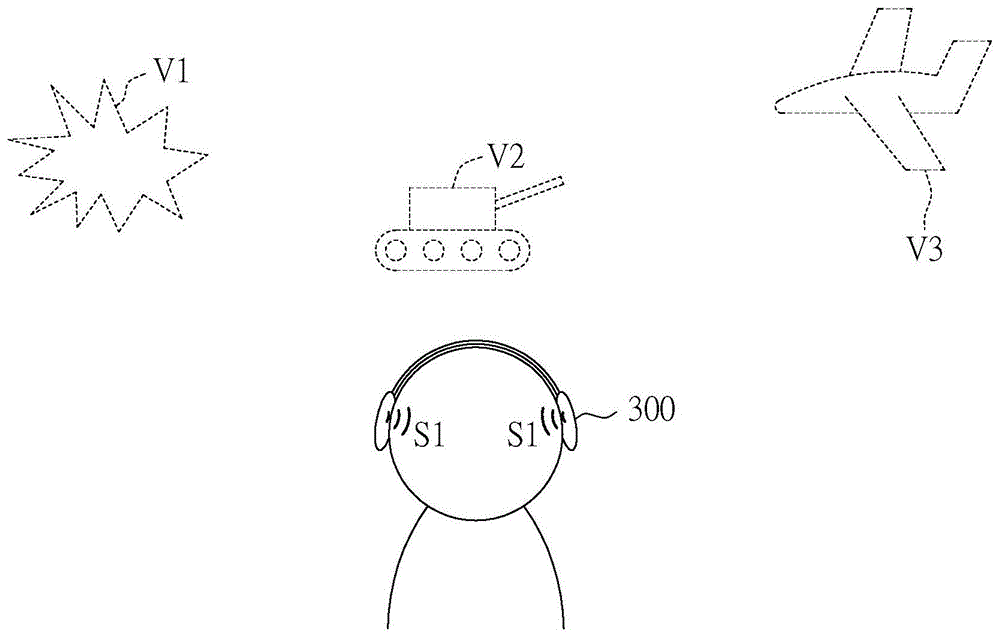
图1绘示原始声音频信号的示意图。
图2绘示根据一实施例的自动调整特定声源的电子装置的示意图。
图3绘示根据一实施例的自动调整特定声源的电子装置的方块图。
图4绘示根据一实施例的自动调整特定声源的方法的流程图。
图5绘示根据一实施例的方向性分布图。
图6绘示对应于一角度的非线性投影遮罩。
图7绘示对应于另一角度的非线性投影遮罩。
【符号说明】
100:电子装置
101:预处理单元
102:第一声音信号辨识单元
103:第一多声源判定单元
104:声音信号调整单元
105:合成单元
106:方向性分析单元
107:方向性分离单元
108:第二声音信号辨识单元
109:第二多声源判定单元
110:特性分离单元
111:次数判断单元
112:特定声源判定单元
200:头戴式显示装置
300:耳机
c:声速
d:双耳距离
f:频率
m11、m12、m13、m21、m22、m23、m31、m32、m33:辨识模型
s1:原始声音频信号
s1’:调整后声音频信号
s11、s12:特定方向子信号
s101、s102、s103、s104、s105、s106、s107、s108、s109、s110、s111、s112:步骤
s(f):频率能量
sn(f):分离信号
p11、p12、p13、p21、p22、p23、p31、p32、p33:声源机率值
px:最大者
th1h、th2h:上限门槛值
th1l、th2l:下限门槛值
th3m:中间门槛值
v1、v2、v3:特定声源
v1’:调整后特定声源
θ1、θ2、θn、θf:角度
【具体实施方式】
请参照图1,其绘示原始声音频信号s1的示意图。使用者配戴着耳机300接收原始声音频信号s1(例如是一双声道信号),可以感受到各种特定声源v1、v2、v3来自于不同的方向。举例来说,特定声源v1例如是炮击声,特定声源v2例如是坦克车声,特定声源v3例如是飞机声。传统上如果需要放大炮击声时,则需要在原始声音频信号s1出现炮击声时,放大整个原始声音频信号s1。然而,这样的方式连同背景声音也会放大,而无法真正地凸显炮击声。因此,需要对原始声音频信号s1分离出特定声源v1。
请参照图2~3,图2绘示根据一实施例的自动调整特定声源的电子装置100的示意图,图3绘示根据一实施例的自动调整特定声源的电子装置100的方块图。电子装置100例如是一电脑主机、一游戏主机、一机上盒、一笔记型电脑、或一服务器。电子装置100例如是连接于耳机300与头戴式显示装置200。请参照图3,其绘示根据一实施例的电子装置100的方块图。电子装置100包括一预处理单元101、一第一声音信号辨识单元102、一第一多声源判定单元103、一声音信号调整单元104、一合成单元105、一方向性分析单元106、一方向性分离单元107、一第二声音信号辨识单元108、一第二多声源判定单元109、一特性分离单元110、一次数判断单元111及一特定声源判定单元112。预处理单元101、第一声音信号辨识单元102、第一多声源判定单元103、声音信号调整单元104、合成单元105、方向性分析单元106、方向性分离单元107、第二声音信号辨识单元108、第二多声源判定单元109、特性分离单元110、次数判断单元111及特定声源判定单元112例如是一电路、一芯片、一电路板、数组程序码、或储存程序码的储存装置。本实施例的电子装置100通过判定声源数量、分离声源等技术自动调整特定声源v1为调整后特定声源v1’,并将调整后特定声源v1’合成至原始声音频信号s1,以获得调整后声音频信号s1’。调整后声音频信号s1’输出至耳机300,提供给使用者更好的感受。以下更搭配依流程图详细说明上述各项元件的运作。
请参照图4,其绘示根据一实施例的自动调整特定声源的方法的流程图。在步骤s101中,预处理单元101对原始声音频信号s1进行预处理,以得到适合进行音频辨识的特征函数(例如试过零率、能量、梅尔倒频谱系数等)。
接着,在步骤s102中,第一声音信号辨识单元102对原始声音频信号s1进行数种特定声源v1、v2、v3的机率辨识程序。举例来说,第一声音信号辨识单元102以炮击声训练过的辨识模型m11进行辨识,以获得特定声源v1的声源机率值p11,第一声音信号辨识单元102以坦克车声训练过的辨识模型m12进行辨识,以获得特定声源v2的声源机率值p12,第一声音信号辨识单元102以飞机声训练过的辨识模型m13进行辨识,以获得特定声源v3的声源机率值p13。
然后,在步骤s103中,第一多声源判定单元103依据原始声音频信号s1的机率辨识程序的结果,判断原始声音频信号s1的声源数量。
在原始声音频信号s1仅单纯存在某一种特定声源时,这一特定声源的声源机率值会相当的高,故最大的声源机率值会相当的高。在原始声音频信号s1存在多种特定声源时(背景声源也是一种特定声源),各个特定声源的声源机率值都会降低,故最大的声源机率值不会太高。在原始声音频信号s1根本不存在任何特定声源时,各个特定声源的声源机率值均会相当的低,故最大的声源机率值会相当的低。
也就是说,第一多声源判定单元103可以从特定声源v1、v2、v3的声源机率值p11、p12、p13中取得最大者px,如下式(1)所示。再通过最大者px进行判断,以得知特定声源的数量。
px=maxmpm………………………………………………….(1)
第一多声源判定单元103可以设定一上限门槛值th1h(例如是0.95)及一下限门槛值th1l(例如是0.1)。当只有一个特定声源而无其他特定声源时,最大者px会大于上限门槛值th1h。当只有一个特定声源但包含背景音乐时,最大者px会介于上限门槛值th1h和下限门槛值th1l之间。当有两个以上的特定声源时,最大者px会介于上限门槛值th1h和下限门槛值th1l之间。当没有任何特定声源时,最大者px会低下限门槛值th1l。
步骤s103的判断结果为「声源数量为0个」时,流程回至步骤s101,不做调整;步骤s103的判断结果为「声源数量为1个」时,流程进入步骤s104,进行特定声源的调整;步骤s103的判断结果为「声源数量为2个以上」时,流程进入步骤s106,继续进行分离的动作。
在步骤s104中,声音信号调整单元104进行声源调整程序。举例来说,声音信号调整单元104例如是对特定声源v1调整音量大小或是利用等化器(equalizer,eq)改变其频率响应,进而获得调整后特定声源v1’。
在步骤s105中,合成单元105将调整后特定声源v1’合成至原始声音频信号s1,以取得调整后声音频信号s1’。
上述在步骤s103判定出「声源数量为2个以上」时,流程进入步骤s106,需要继续进行分离的动作。
在步骤s106中,方向性分析单元106对原始声音频信号s1进行一方向性分析程序。请参照图5,其绘示根据一实施例的方向性分布图。在进行方向性分析程序中,以一到达方向估测演算法(directionofarrival,doa)对原始声音频信号s1分析出方向性分布图。原始声音频信号s1可以视为左耳声音频信号及右耳声音频信号。原始声音频信号s1转换到频域后,比较每个频率f的相位差
其中,声速c、频率f、双耳距离d均为固定值,影响相位差
接着,在步骤s107中,方向性分离单元107依据原始声音频信号s1的方向分析程序的结果,分离出至少一特定方向子信号。举例来说,方向性分离单元107可以分离出对应于角度θ1的特定方向子信号s11及对应于角度θ2的特定方向子信号s12。
在此步骤中,方向性分离单元107依据方向性分布图的一特定方向,方向性分离单元107以一非线性投影遮罩(nonlinearprojectioncolumnmask,npcm)对源始声音频信号s1进行运算,以获得通过特定方向子信号s11、s12。每个频率f对应一个角度θf,对第n个信号而言,越靠近角度θn时权重越接近0,依不同权重方式来遮蔽远离角度θn的信号,而得到角度θn的方向的分离信号sn(f),即为各频率能量s(f)乘上对应的权重
在步骤s107中,虽然已经从原始声音频信号s1分离出特定方向子信号s11及特定方向子信号s12,但多个特定声源可能位于同一方向上,故特定方向子信号s11未必就是单一特定声源,特定方向子信号s12也未必就是单一特定声源。因此,需要继续进行声源数量的判断。
在步骤s108中,第二声音信号辨识单元108对特定方向子信号s11、s12进行特定声源v1、v2、v3的机率辨识程序。以特定方向子信号s11为例,第二声音信号辨识单元108以炮击声训练过的辨识模型m21进行辨识,以获得特定声源v1的声源机率值p21,第二声音信号辨识单元108以坦克车声训练过的辨识模型m22进行辨识,以获得特定声源v2的声源机率值p22,第二声音信号辨识单元108以飞机声训练过的辨识模型m23进行辨识,以获得特定声源v3的声源机率值p23。
步骤s108的辨识模型m21可以相同于步骤s102的辨识模型m11;或者,步骤s108的辨识模型m21也可以是重新训练的辨识模型。步骤s108的辨识模型m22可以相同于步骤s102的辨识模型m12;或者,步骤s108的辨识模型m22也可以是重新训练的辨识模型。步骤s108的辨识模型m23可以相同于步骤s102的辨识模型m13;或者,步骤s108的辨识模型m23也可以是重新训练的辨识模型。
再以特定方向子信号s12为例,第二声音信号辨识单元108以炮击声训练过的辨识模型m31进行辨识,以获得特定声源v1的声源机率值p31,第二声音信号辨识单元108以坦克车声训练过的辨识模型m32进行辨识,以获得特定声源v2的声源机率值p32,第二声音信号辨识单元108以飞机声训练过的辨识模型m33进行辨识,以获得特定声源v3的声源机率值p33。
步骤s108的辨识模型m31可以相同于步骤s102的辨识模型m11;或者,步骤s108的辨识模型m31也可以是重新训练的辨识模型。步骤s108的辨识模型m32可以相同于步骤s102的辨识模型m12;或者,步骤s108的辨识模型m32也可以是重新训练的辨识模型。步骤s108的辨识模型m33可以相同于步骤s102的辨识模型m13;或者,步骤s108的辨识模型m33也可以是重新训练的辨识模型。
接着,在步骤s109中,第二多声源判定单元109依据特定方向子信号s11、特定方向子信号s12的机率辨识程序的结果,判断特定方向子信号s11的声源数量、特定方向子信号s12的声源数量。
第二多声源判定单元109可以设定新的上限门槛值th2h(例如是0.99)及新的下限门槛值th2l(例如是0.05)。步骤s109的判断结果为「声源数量为1」时,流程进入步骤s104,进行特定声源的调整;步骤s109的判断结果为「声源数量为2个」时,流程进入步骤s110,继续进行分离的动作。举例来说,当特定方向子信号s11的声源数量为1个时,通过步骤s104来调整特定方向子信号s11;当特定方向子信号s11的声源数量为2个时,通过步骤s110来分离特定方向子信号s11。
在步骤s110中,特性分离单元110对特定方向子信号s12进行一频带稀疏特性分析程序(sca)、一独立成分分析程序(ica)、或一非负矩阵分解程序。经过步骤s107在方向性的分离,此时的特定方向子信号s12的声源都在同一方向上,基本上不会有太多声源,为了避免不必要的失真,此次我们只将特定方向子信号s12分离成2个子信号即可。我们可以依据个别子信号之间声音频带的稀疏特性采用稀疏成分分析法(sca),或是声源之间的独立特性采用独立成分分析法(ica),亦或是将信号区分为各种不同基底对应适当系数的非负矩阵分解法。
步骤s110分离出来2个子信号后,进入步骤s111。
在步骤s111中,次数判断单元111判断步骤s110是否已执行超过k次。若超过k次,则进入步骤s112;若尚未超过k次,则回至步骤s108。也就是说,若在执行步骤s110的分离的动作多次后,仍然无法准确地确定子信号为1个声源时,则直接离开回圈,进入步骤s112。
在步骤s112中,特定声源判定单元112依据特定方向子信号s12的机率辨识程序的结果,直接分别判断特定方向子信号s12的各个特定声源v1、v2、v3是否存在。特定声源判定单元112设定一中间门槛值th3m为0.5。若特定声源v1的声源机率值p31大于中间门槛值th3m,则直接判定具有此特定声源v1,并进入步骤s104进行调整;若特定声源v1的声源机率值p31不大于中间门槛值th3m,则直接判定不具有此特定声源v1,不做调整。若特定声源v2的声源机率值p32大于中间门槛值th3m,则直接判定具有此特定声源v2,并进入步骤s104进行调整;若特定声源v2的声源机率值p32不大于中间门槛值th3m,则直接判定不具有此特定声源v2,不做调整。若特定声源v3的声源机率值p33大于中间门槛值th3m,则直接判定具有此特定声源v3,并进入步骤s104进行调整;若特定声源v3的声源机率值p33不大于中间门槛值th3m,则直接判定不具有此特定声源v3,不做调整。
通过上述实施例,特定声源能够被分离出来,并据以进行调整,使得此特定声源能够被凸显出来,提供给使用者更好的感受。
综上所述,虽然本揭露已以实施例揭露如上,然其并非用以限定本揭露。本揭露所属技术领域中具有通常知识者,在不脱离本揭露的精神和范围内,当可作各种的更动与润饰。因此,本揭露的保护范围当视后附的申请专利范围所界定者为准。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

