本发明属于zpw-2000a轨道电路发送器、接收器维护领域,尤其涉及一种zpw-2000a轨道电路发送器、接收器故障诊断方法。
背景技术:
轨道电路是利用钢轨线路作为导体,绝缘节作为分割点构成的电路,是铁路信号系统中的重要设备。zpw-2000a轨道电路发送器、接收器的安全监测和维护是铁路维护检修中的重要工作。轨道电路主要用于监督列车的占用,轨道区段的空闲检查。轨道电路发送器产生有特定含义的信号,然后将信号输送到轨道电路中。轨道电路的接收器接收相应发送器的发出的信号,检查并动作本区段轨道电路的轨道继电器。
zpw-2000a型移频轨道电路是对um71型轨道电路的改进与创新,采用电气绝缘节。zpw-2000a型移频轨道电路应用与普速铁路的区间与高速铁路的站内与区间,应用非常广泛。
目前,在现有技术中,轨道电路采用定期检查维修和故障后维修的方式来维护设备的正常运行,发生故障后,往往需要维修人员根据经验逐步排查故障,导致维修人员的工作量大、耗时长、工作效率低。
技术实现要素:
本发明的技术目的是提供一种zpw-2000a轨道电路发送器、接收器故障诊断方法,以解决zpw-2000a轨道电路发送器、接收器故障诊断工作量大、耗时长、工作效率低技术问题。
为解决上述问题,本发明的技术方案为:
一种zpw-2000a轨道电路发送器、接收器故障诊断方法,包括如下步骤:
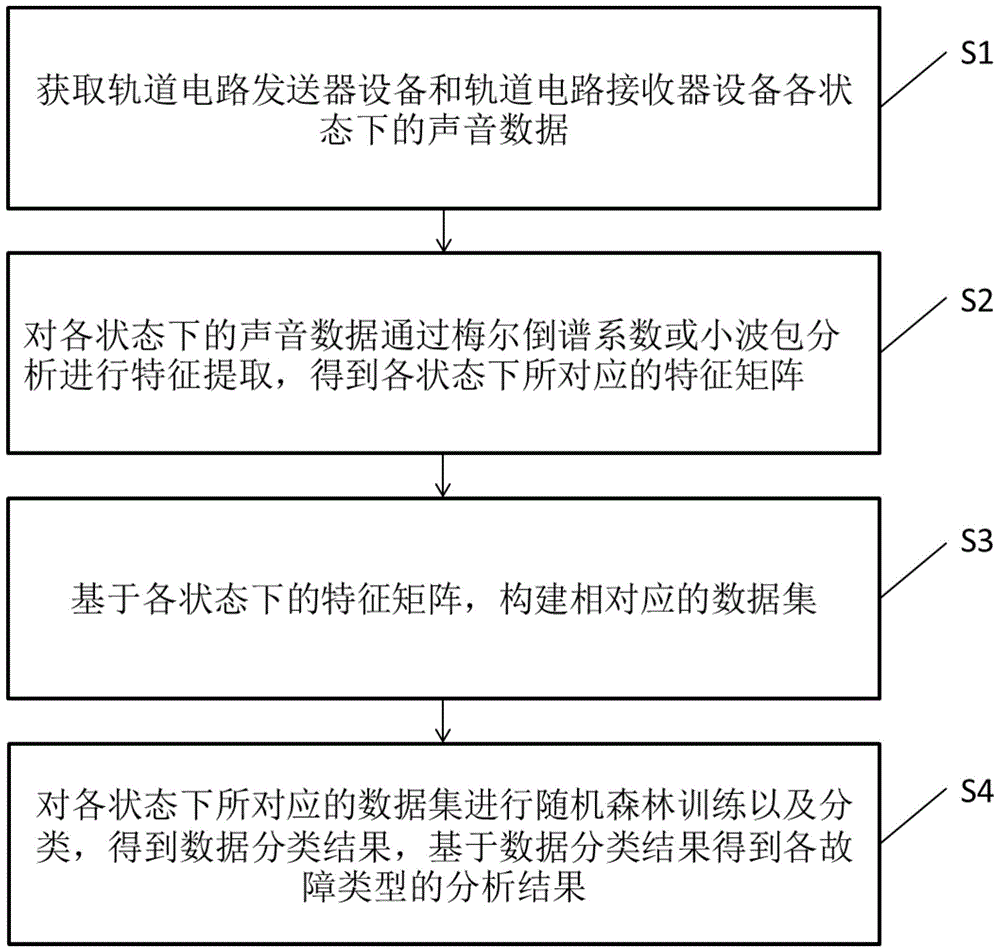
s1:获取轨道电路发送器设备和轨道电路接收器设备各状态下的声音数据;
s2:对各状态下的声音数据通过梅尔倒谱系数或小波包分析进行特征提取,得到各状态下所对应的特征矩阵;
s3:基于各状态下的特征矩阵,构建相对应的数据集;
s4:对各状态下所对应的数据集进行随机森林训练以及分类,得到数据分类结果,基于数据分类结果得到各故障类型的分析结果。
具体地,在步骤s1中,通过录音设备以实现获取轨道电路发送器设备和轨道电路接收器设备各状态下的声音数据。
具体地,在步骤s2中,通过梅尔倒谱系数进行特征提取,选取256个采样点为一帧,梅尔滤波器的个数为12个,进行两次差分处理,得到各状态下所对应的特征矩阵。
进一步优选地,在步骤s2中,通过小波包分析进行特征提取,小波包分析的层数为4层。
其中,数据集包括发送器设备数据集和接收器设备数据集;其中,
发送器设备数据集包括发送器正常状态故障数据、发送器无载频故障数据、发送器无选型故障数据和发送器无低频故障数据;
接收器设备数据集包括接收器正常状态故障数据、接收器无载频故障数据和接收器无选型故障数据。
进一步优选地,在步骤s4中,进一步包括以下步骤:
s41:采用随机有放回的抽样方式从数据集抽取n个样本,生成m个决策树样本集,其中,数据集的数据总数为n,n>n;
s42:依次对m个决策树样本集进行处理,随机选取a个特征作为决策树节点属性进行分裂,得到相对应的决策树,其中,决策树样本集的全部特征数为a,a>a;
s43:将若干决策树组成随机森林模型,利用随机森林模型对数据集进行分类,得到数据分类结果。
具体地,在步骤s42中,每个决策树节点以不纯度最小为目标,即最小信息熵来选取相应特征进行分裂,信息熵ent(d)的计算公式:
其中,k为样本类别的种类,pk为第k种样本的概率。
本发明由于采用以上技术方案,使其与现有技术相比具有以下的优点和积极效果:
1)本发明设置数据采集方式为录音方式,具有非接触测量、高安全性的优点。
2)本发明采用基于机器学习算法的zpw-2000a轨道电路发送器、接收器故障诊断方法,避免了传统检测方法需要检修人员具有丰富的经验,且检修流程复杂的缺点,提高了检修的效率。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。
图1为本发明的一种zpw-2000a轨道电路发送器、接收器故障诊断方法的流程示意图;
图2为本发明的一种实施例中的梅尔频率倒谱系数的处理流程示意图;
图3为本发明的一种实施例中的随机森林算法的流程示意图;
图4为本发明的一种实施例中的决策树的结构示意图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
以下结合附图和具体实施例对本发明提出的一种zpw-2000a轨道电路发送器、接收器故障诊断方法作进一步详细说明。根据下面说明和权利要求书,本发明的优点和特征将更清楚。
实施例
参看图1,一种zpw-2000a轨道电路发送器、接收器故障诊断方法,包括如下步骤:
首先,在步骤s1中,需要获取轨道电路发送器设备和轨道电路接收器设备各状态下的声音数据。具体地,可通过录音设备一一获取zpw-2000a轨道电路发送器设备、电路接收器设备各故障状态下的声音数据。具体地,发送器设备故障包括正常状态故障、发送器无载频故障、发送器无选型故障和发送器无低频故障;接收器设备故障包括接收器正常状态故障、接收器无载频故障和接收器无选型故障。具体地,采用拔下发送器、接收器背面端子对应连接线的方式模拟各故障的发生。
接着,在步骤s2中,对上述各状态下的声音数据通过梅尔倒谱系数或小波包分析进行特征提取,得到各状态下所对应的特征矩阵。
其中,通过梅尔倒谱系数进行特征提取。现对梅尔倒谱系数进行详细说明,参看图2,首先对采集得到的声音数据通过一个高通滤波器进行预加重处理,预加重的目的是提升高频部分,使声音数据的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿声音数据受到发音系统所抑制的高频部分,也为了突出高频的共振峰。接着,为了方便对声音数据分析,可以将声音数据分成一个个小段,称之为:帧,通过将n个采样点集合成一个观测单位,即可得到帧。在本实施例中,选取256个采样点为一帧。接着,进行加窗处理,由于声音数据在长范围内是不停变动的,没有固定的特性无法做处理,所以将每一帧代入窗函数,窗外的值设定为0,其目的是消除各个帧两端可能会造成的信号不连续性。其次,由于声音数据在时域上的变换通常很难看出信号的特性,对加窗处理后的声音数据进行频域转换,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性,并需要对声音数据的频谱取模平方得到声音数据的功率谱。然后,由于人耳对不同频率的敏感程度不同,且成非线性关系,因此我们将频谱按人耳敏感程度分为多个梅尔滤波器组,在梅尔刻度范围内,各个滤波器的中心频率是相等间隔的线性分布,但在频率范围不是相等间隔的,在本实施例中,梅尔滤波器的个数为12个。然后进行对数能量计算,并进行离散余弦变换,离散余弦变换用于对声音数据进行有损数据压缩,离散余弦变换具有很强的能量集中特性,能将声音数据的能量都集中在离散余弦变换后的低频部分,实际就是对每帧数据在进行一次降维。后续再进行两次差分处理,获取差分参数,最终得到各状态下所对应的特征矩阵。
另外,步骤s2还可以通过小波包分析进行特征提取,小波包分析(waveletpacketanalysis)在多分辨率分析基础上进行了改进,能对声音数据进行更加精细的分析,将频带进行多层次划分,对每个分解后的频带均进行再次的将半划分,并根据被分析信号的特征选择相应频带,使之与信号频谱相匹配,从而得到了比二进离散小波变换更精细的信号分解。小波包分解第一次分解后得到了两个部分(高频部分和低频部分),再次分解时不单单只对低频部分进行分解,而是对低频和高频两个部分同时进行将半分解。而在本实施例中,小波包分析的层数共有4层。
然后,在步骤s3中,基于各状态下的特征矩阵,对各特征矩阵进行标记,进而构建相对应的数据集。具体地,数据集包括发送器设备数据集和接收器设备数据集;其中,发送器设备数据集包括发送器正常状态故障数据、发送器无载频故障数据、发送器无选型故障数据和发送器无低频故障数据;接收器设备数据集包括接收器正常状态故障数据、接收器无载频故障数据和接收器无选型故障数据。
最后,在步骤s4:对各状态下所对应的数据集进行随机森林训练以及分类,得到数据分类结果,基于数据分类结果得到各故障类型的分析结果。
较优地,参看图3和图4,步骤s4具体包括以下步骤:
s41:采用随机有放回的抽样方式从数据集抽取n个样本,抽取m次,生成m个决策树样本集,其中,数据集的数据总数为n,每个决策树样本量为m,n>n。
s42:依次对m个决策树样本集进行处理,随机选取a个特征作为决策树节点属性进行分裂,得到相对应的决策树,其中,决策树样本集的全部特征数为a,a>a。
s43:将若干决策树组成随机森林模型,利用随机森林模型对数据集进行分类,得到数据分类结果。
具体地,在步骤s42中,决策树的形状与树型相似,由根节点、中间节点和叶子节点构成,根节点表示样本集,叶子节点表示样本经过特征分类后的结果,较优地,参看图4。
具体地,在步骤s42中,每个决策树节点以不纯度最小为目标,即最小信息熵来选取相应特征进行分裂,信息熵ent(d)的计算公式:
其中,k表示样本类别的种类,pk表示第k种样本的概率。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式。即使对本发明作出各种变化,倘若这些变化属于本发明权利要求及其等同技术的范围之内,则仍落入在本发明的保护范围之中。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

