本公开实施例涉及计算机技术领域,具体涉及语音信号去混响方法、装置和电子设备。
背景技术:
使用传声器采集信号时,如果声源在房间里面,那么采集到的信号会包含直达声和反射声。直达声是原始的信号不经过反射,直接到达传声器处的信号,而反射声是原始信号经过房间壁面和房内物体的反射得到的,这些反射声就被称为混响。早期的反射声能够让声音听起来更加饱满,一定程度上增加了听觉的舒适度。但是晚期混响通常会影响语音的清晰度与可懂度,改变语音的特性。去混响的目的是抑制传声器接收到的信号中的全部反射声或者晚期混响。
技术实现要素:
提供该公开内容部分以便以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。该公开内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。
本公开实施例提供了一种图像处理方法、装置和电子设备,更有效地对语音信号去混响。
第一方面,本公开实施例提供了一种语音信号去混响方法,包括:将时域的混响语音信号转换到频域,得到频域的混响语音信号;对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
第二方面,本公开实施例提供了一种语音信号去混响装置,包括:第一转换单元,用于将时域的混响语音信号转换到频域,得到频域的混响语音信号;延时单元,用于对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;第一确定单元,用于利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;第二确定单元,用于根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;第二转换单元,用于将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
第三方面,本公开实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的语音信号去混响方法。
第四方面,本公开实施例提供了一种计算机可读介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的语音信号去混响方法的步骤。
本公开实施例提供的语音信号去混响方法、装置和电子设备,通过将时域的混响语音信号转换到频域,得到频域的混响语音信号;之后,对上述时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;而后,利用上述频域的混响语音信号和上述频域的延时混响语音信号,确定频域直达声的估计值;然后,根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号;最后,将上述频域的无混响语音信号转换到时域,得到时域的无混响语音信号。通过这种方式,给单通道混响信号一定的延时,构造了双通道信号,然后估计出直达声频谱作为对混响信号去混响的辅助信息,能够更有效地对语音信号去混响。
附图说明
结合附图并参考以下具体实施方式,本公开各实施例的上述和其他特征、优点及方面将变得更加明显。贯穿附图中,相同或相似的附图标记表示相同或相似的元素。应当理解附图是示意性的,原件和元素不一定按照比例绘制。
图1是本公开的各个实施例可以应用于其中的示例性系统架构图;
图2是根据本公开的语音信号去混响方法的一个实施例的流程图;
图3是根据本公开的语音信号去混响方法的一个应用场景的示意图;
图4是根据本公开的语音信号去混响方法的又一个实施例的流程图;
图5是根据本公开的语音信号去混响方法中训练得到增强网络的一个实施例的流程图;
图6是根据本公开的语音信号去混响装置的一个实施例的结构示意图;
图7是适于用来实现本公开实施例的电子设备的计算机系统的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的实施例。虽然附图中显示了本公开的某些实施例,然而应当理解的是,本公开可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例,相反提供这些实施例是为了更加透彻和完整地理解本公开。应当理解的是,本公开的附图及实施例仅用于示例性作用,并非用于限制本公开的保护范围。
应当理解,本公开的方法实施方式中记载的各个步骤可以按照不同的顺序执行,和/或并行执行。此外,方法实施方式可以包括附加的步骤和/或省略执行示出的步骤。本公开的范围在此方面不受限制。
本文使用的术语“包括”及其变形是开放性包括,即“包括但不限于”。术语“基于”是“至少部分地基于”。术语“一个实施例”表示“至少一个实施例”;术语“另一实施例”表示“至少一个另外的实施例”;术语“一些实施例”表示“至少一些实施例”。其他术语的相关定义将在下文描述中给出。
需要注意,本公开中提及的“第一”、“第二”等概念仅用于对不同的装置、模块或单元进行区分,并非用于限定这些装置、模块或单元所执行的功能的顺序或者相互依存关系。
需要注意,本公开中提及的“一个”、“多个”的修饰是示意性而非限制性的,本领域技术人员应当理解,除非在上下文另有明确指出,否则应该理解为“一个或多个”。
本公开实施方式中的多个装置之间所交互的消息或者信息的名称仅用于说明性的目的,而并不是用于对这些消息或信息的范围进行限制。
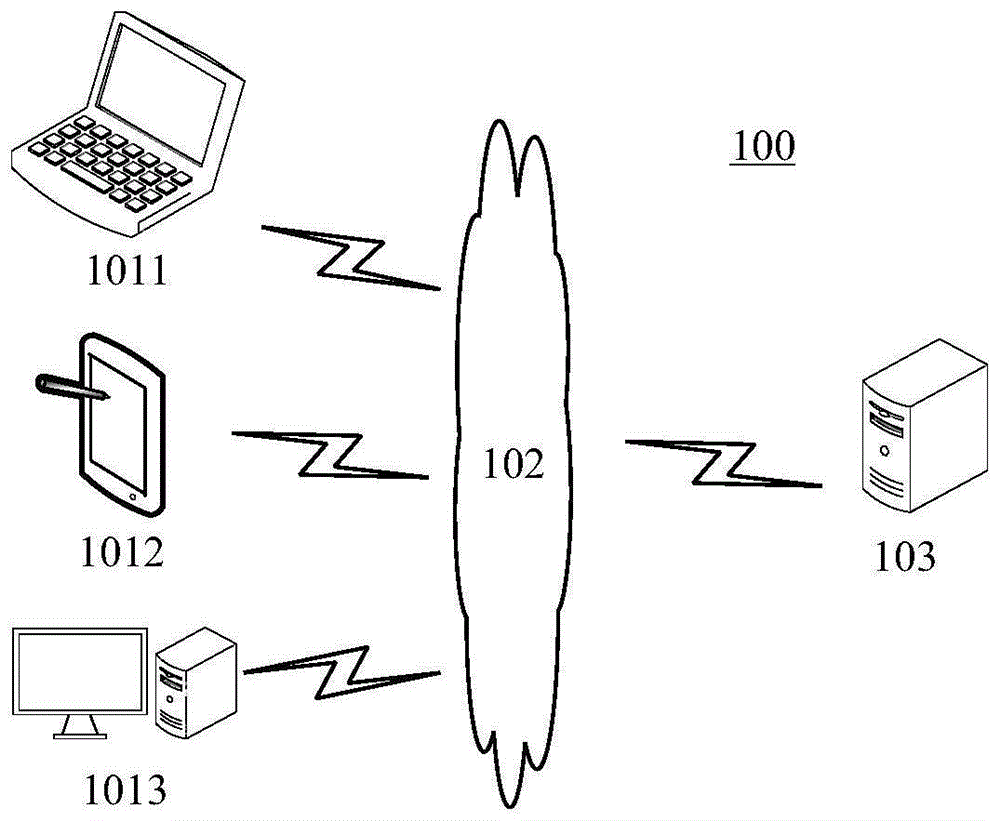
图1示出了可以应用本公开的语音信号去混响方法的实施例的示例性系统架构100。
如图1所示,系统架构100可以包括终端设备1011、1012、1013,网络102和服务器103。网络102用以在终端设备1011、1012、1013和服务器103之间提供通信链路的介质。网络102可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
用户可以使用终端设备1011、1012、1013通过网络102与服务器103交互,以发送或接收消息等,例如,用户可以利用终端设备1011、1012、1013接收混响语音信号,服务器103可以从终端设备1011、1012、1013中获取混响语音信号。终端设备1011、1012、1013上可以安装有各种通讯客户端应用,例如图像处理类应用、即时通讯软件等。
终端设备1011、1012、1013可以首先将时域的混响语音信号转换到频域,得到频域的混响语音信号;之后,可以对上述时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;而后,可以利用上述频域的混响语音信号和上述频域的延时混响语音信号,确定频域直达声的估计值;然后,可以根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号;最后,可以将上述频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
终端设备1011、1012、1013可以是硬件,也可以是软件。当终端设备1011、1012、1013为硬件时,可以是具有话筒并且支持信息交互的各种电子设备,包括但不限于智能手机、平板电脑、膝上型便携计算机等。当终端设备1011、1012、1013为软件时,可以安装在上述所列举的电子设备中。其可以实现成多个软件或软件模块(例如用来提供分布式服务的多个软件或软件模块),也可以实现成单个软件或软件模块。在此不做具体限定。
服务器103可以是提供各种服务的服务器。例如,可以将从终端设备1011、1012、1013获取的时域的混响语音信号转换到频域,得到频域的混响语音信号;之后,可以对上述时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;而后,可以利用上述频域的混响语音信号和上述频域的延时混响语音信号,确定频域直达声的估计值;然后,可以根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号;最后,可以将上述频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
需要说明的是,服务器103可以是硬件,也可以是软件。当服务器103为硬件时,可以实现成多个服务器组成的分布式服务器集群,也可以实现成单个服务器。当服务器103为软件时,可以实现成多个软件或软件模块(例如用来提供分布式服务),也可以实现成单个软件或软件模块。在此不做具体限定。
还需要说明的是,本公开实施例所提供的语音信号去混响方法可以由服务器103执行,此时,语音信号去混响装置通常设置于服务器103中。本公开实施例所提供的语音信号去混响方法也可以由终端设备1011、1012、1013执行,此时,语音信号去混响装置通常设置于终端设备1011、1012、1013中。
还需要说明的是,在本公开实施例所提供的语音信号去混响方法由服务器103执行的情况下,若服务器103的本地存储有混响语音信号,此时示例性系统架构100可以不存在终端设备1011、1012、1013和网络102。
还需要说明的是,在本公开实施例所提供的语音信号去混响方法由终端设备1011、1012、1013执行的情况下,若终端设备1011、1012、1013的本地存储有增强网络,此时示例性系统架构100可以不存在网络102和服务器103。
应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。
继续参考图2,示出了根据本公开的语音信号去混响方法的一个实施例的流程200。该语音信号去混响方法,包括以下步骤:
步骤201,将时域的混响语音信号转换到频域,得到频域的混响语音信号。
在本实施例中,语音信号去混响方法的执行主体(例如图1所示的服务器或终端设备)可以将时域的混响语音信号转换到频域,得到频域的混响语音信号。时域是描述数学函数或物理信号对时间的关系。例如一个信号的时域波形可以表达信号随着时间的变化。频域是描述信号在频率方面特性时用到的一种坐标系。在电子学,控制系统工程和统计学中,频域图显示了在一个频率范围内每个给定频带内的信号量。时域和频域是信号的基本性质,这样可以用多种方式来分析信号,每种方式提供了不同的角度。解决问题的最快方式不一定是最明显的方式,用来分析信号的不同角度称为域。时域频域可清楚反应信号与互连线之间的相互影响。
在这里,上述执行主体可以通过stft(short-timefouriertransform或short-termfouriertransform,短时傅里叶变换)将时域的混响语音信号转换到频域。stft的过程是:在信号做傅里叶变换之前乘一个时间有限的窗函数h(t),并假定非平稳信号在分析窗的短时间隔内是平稳的,通过窗函数h(t)在时间轴上的移动,对信号进行逐段分析得到信号的一组局部“频谱”。
在这里,混响语音信号可以为包含混响的语音信号。反射声是原始信号经过房间壁面和房内物体的反射得到的,这些反射声就被称为混响。
步骤202,对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号。
在本实施例中,上述执行主体可以对上述时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号。上述执行主体可以通过stft将延时后的混响语音信号转换到频域。
在这里,上述执行主体通过对单通道的混响语音信号进行一定延时,从而构造了双通道语音信号。
步骤203,利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值。
在本实施例中,上述执行主体可以利用在步骤201中得到的频域的混响语音信号和在步骤202中得到的频域的延时混响语音信号,确定频域直达声的估计值。直达声通常指的是原始的语音信号不经过反射,直接到达传声器处的信号。
作为示例,上述执行主体可以通过wpe(weightedpredictionerror,加权预测误差)算法。wpe算法也被称为mclp(multi-channellinearprediction,多通道线性预测)算法。wpe的主要思路是首先估计语音信号的混响尾部,然后再从观测信号中减去混响尾部,得到对弱混响信号的极大似然意义下的最优估计。
需要说明的是,利用wpe算法对语音信号去混响是本领域的常规技术手段,在此不再赘述。
步骤204,根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号。
在本实施例中,上述执行主体可以根据在步骤201中得到的频域的混响语音信号和在步骤203中得到的频域直达声的估计值,确定频域的无混响语音信号。在这里,上述执行主体可以将上述频域的混响语音信号和上述频域直达声的估计值输入预先训练的无混响语音信号预测模型中,得到对应的频域的无混响语音信号。上述无混响语音信号预测模型用于表征频域的混响语音信号和频域直达声的估计值这两者与频域的无混响语音信号之间的对应关系。
步骤205,将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
在本实施例中,上述执行主体可以将在步骤204中得到的频域的无混响语音信号转换到时域,得到时域的无混响语音信号。上述执行主体可以通过istft(inverseshort-timefouriertransform或inverseshort-termfouriertransform,逆短时傅里叶变换)将频域的无混响语音信号转换到时域。
本公开的上述实施例提供的方法通过将时域的混响语音信号转换到频域,得到频域的混响语音信号;之后,对上述时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;而后,利用上述频域的混响语音信号和上述频域的延时混响语音信号,确定频域直达声的估计值;然后,根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号;最后,将上述频域的无混响语音信号转换到时域,得到时域的无混响语音信号。通过这种方式,给单通道混响信号一定的延时,构造了双通道信号,然后估计出直达声频谱作为对混响信号去混响的辅助信息,能够更有效地对语音信号去混响。
在一些可选的实现方式中,上述执行主体可以通过如下方式根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号:上述执行主体可以根据在步骤201中得到的频域的混响语音信号和在步骤203中得到的频域直达声的估计值,确定无混响语音的掩膜(mask)。语音的掩膜也可以称为掩谱或掩码,通常指的是对语音信号进行遮挡来控制待处理的语音或处理过程。在这里,上述无混响语音的掩膜可以是对语音信号中的混响或噪声进行遮挡的模板。之后,上述执行主体可以将上述掩膜和在步骤201中得到的频域的混响语音信号相乘得到频域的无混响语音信号。
在一些可选的实现方式中,上述执行主体可以通过如下方式根据上述频域的混响语音信号和上述频域直达声的估计值,确定无混响语音的掩膜:上述执行主体可以将上述频域的混响语音信号和上述频域直达声的估计值输入预先训练的增强网络中,得到无混响语音的掩膜。上述增强网络可以用于表征频域的混响语音信号和频域直达声的估计值这两者与无混响语音的掩膜之间的对应关系。上述增强网络可以根据实际任务需要和计算资源限制来设计。
在一些可选的实现方式中,上述增强网络可以包括空间可变卷积网络(spatialvariantconvolution,svconv)和/或长短时记忆网络(longshort-termmemory,lstm)。空间可变卷积对输出的每个频率维度学习一个不同的kernel(核),这样使得网络参数量增大(传统卷积层的kernel大小是输出通道数乘以输入通道数×kernel时间维大小×kernel频率维大小,空间可变卷积层的kernel大小是输出通道数×输入通道数×输出频率维大小×kernel时间维大小×kernel频率维大小),但计算量与深度可分离卷积一样。
继续参见图3,图3是根据本实施例的语音信号去混响方法的应用场景的一个示意图。在图3的应用场景中,可以首先通过stft将混响语音信号301转换到频域,得到频域的混响语音信号;之后,可以将混响语音信号301进行延时,再将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;而后,可以利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值302;然后,可以将频域的混响语音信号和频域直达声的估计值302输入预先训练的增强网络303中,得到无混响语音的掩膜。在这里,增强网络303包括空间可变卷积网络(图中的svconv2d)和长短时记忆网络(图中的lstm)。图标3031、3032、3033、3034、3036、3037、3038、3039、30310所示的网络结构为空间可变卷积网络,图标3035所示的网络结构为长短时记忆网络,图标30311所示的网络结构为全连接层。以图标3031为例,kernel:(3,5)表示卷积核的大小为3×5,stride:(1,2)表示在二维平面的竖直方向移动的步长为1、在水平方向移动的步长为2,chanel:4表示通道数为4。而后,可以将增强网络输出的无混响语音的掩膜和频域的混响语音信号点乘得到频域的无混响语音信号;最后,可以通过istft将频域的无混响语音信号转换到时域,得到时域的无混响语音信号304。
进一步参考图4,其示出了语音信号去混响方法的又一个实施例的流程400。该语音信号去混响方法的流程400,包括以下步骤:
步骤401,将时域的混响语音信号转换到频域,得到频域的混响语音信号。
步骤402,对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号。
在本实施例中,步骤401-402可以按照与步骤201-202类似的方式执行,在此不再赘述。
步骤403,根据频域的混响语音信号和频域的延时混响语音信号,确定语音信号的自相关功率谱和互相关功率谱。
在本实施例中,语音信号去混响方法的执行主体(例如图1所示的服务器或终端设备)可以根据在步骤401中得到的频域的混响语音信号和在步骤402中得到的频域的延时混响语音信号,确定语音信号的自相关功率谱和互相关功率谱。相关函数是描述信号x(s)、y(t)(这两个信号可以是随机的,也可以是确定的)在任意两个不同时刻s、t的取值之间的相关程度。两个信号之间的相似性大小可以用相关系数来衡量。自相关函数是描述随机信号x(t)在任意不同时刻t1、t2的取值之间的相关程度。互相关函数是描述随机信号x(t)、y(t)在任意两个不同时刻s、t的取值之间的相关程度。
在这里,上述执行主体可以通过如下公式(1)确定语音信号的自相关功率谱和互相关功率谱:
其中,xi表征频域的混响语音信号,xj表征频域的延时混响语音信号,l表征语音信号中的第l帧,k表征语音信号中的第k个频点,λ表征平滑因子,xi(l,k)分布表征第l帧第k个频点的频域的混响语音信号,xj(l,k)分布表征第l帧第k个频点的频域的延时混响语音信号,上标*表示语音信号的共轭操作。当i=j时,
步骤404,根据自相关功率谱、互相关功率谱和预设的噪声空间相关函数,确定相干扩散能量比。
在本实施例中,上述执行主体可以根据上述第l帧第k个频点的频域的混响语音信号的自相关功率谱、上述第l帧第k个频点的频域的延时混响语音信号的自相关功率谱、上述第l帧第k个频点的频域的混响语音信号与频域的延时混响语音信号的互相关功率谱和预设的噪声空间相关函数,确定相干扩散能量比(coherenttodiffusepowerratio,cdr)。上述相干扩散能量比通常指的是无混响的直达声的能量与噪声的能量之比。
在这里,上述执行主体可以通过如下公式(2)-(4)确定相干扩散能量比:
其中,
需要说明的是,为了书写方便,公式(4)中省略了时间和频率序号,即省略了帧l和频点k。
步骤405,根据相干扩散能量比和频域的混响语音信号,确定频域直达声的估计值。
在本实施例中,上述执行主体可以根据在步骤404中确定出的相干扩散能量比和在步骤401中得到的频域的混响语音信号,确定频域直达声的估计值。
在这里,上述执行主体可以通过如下公式(5)和(6)确定频域直达声的估计值:
其中,μ是一个常数;cdr(l,k)表征第l帧第k个频点的相干扩散能量比;gain(l,k)表征第l帧第k个频点的语音信号的增益;x1(l,k)表征第l帧第k个频点的混响语音信号;
步骤406,根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号。
步骤407,将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
在本实施例中,步骤406-407可以按照与步骤204-205类似的方式执行,在此不再赘述。
从图4中可以看出,与图2对应的实施例相比,本实施例中的语音信号去混响方法的流程400体现了利用确定出的相干扩散能量比确定频域直达声的估计值的步骤。由此,本实施例描述的方案可以提高频域直达声的估计值的准确性。
进一步参考图5,其示出了语音信号去混响方法中训练得到增强网络的一个实施例的流程500。该训练得到增强网络的流程500,包括以下步骤:
步骤501,获取训练样本集合。
在这里,可以获取训练样本集合。其中,上述训练样本集合中的训练样本可以包括频域的样本混响语音信号、频域样本直达声信号,以及与样本混响语音信号和频域样本直达声信号对应的样本无混响语音的掩膜。
在这里,频域样本直达声信号可以为将样本纯净语音信号转换到频域所得到的。可以从纯净语音的数据集中抽取纯净语音信号作为样本纯净语音信号,之后,可以通过stft将样本纯净语音信号转换到频域。频域的样本混响语音信号可以为将目标语音信号转换到频域所得到的。例如,可以通过stft将目标语音信号转换到频域。目标语音信号可以为将样本纯净语音信号与预设的房间冲击响应进行卷积操作所生成的。样本无混响语音的掩膜可以为频域的样本纯净语音信号与频域的样本混响语音信号之比。
步骤502,基于训练样本集合执行以下训练步骤:将训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到至少一个训练样本中的每个训练样本对应的无混响语音的掩膜;将至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较;根据比较结果确定初始神经网络是否达到预设的优化目标;若初始神经网络达到优化目标,将初始神经网络确定为训练完成的增强网络。
在这里,可以基于在步骤501中获取的训练样本集合,执行以下训练步骤。
在本实施例中,训练步骤502可以包括子步骤5021、5022、5023和5024。其中:
步骤5021,将训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到至少一个训练样本中的每个训练样本对应的无混响语音的掩膜。
在这里,可以将上述训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到上述至少一个训练样本中的每个训练样本对应的无混响语音的掩膜。其中,上述初始神经网络可以是能够根据频域的样本混响语音信号和频域样本直达声信号得到无混响语音的掩膜的各种神经网络,例如,卷积神经网络、深度神经网络等等。
步骤5022,将至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较。
在这里,可以将上述至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较。即针对上述至少一个训练样本中的每个训练样本,将该训练样本中的频域的样本混响语音信号和频域样本直达声信号输入上述初始神经网络所得到的无混响语音的掩膜与该训练样本中的样本无混响语音进行比较。
步骤5023,根据比较结果确定初始神经网络是否达到预设的优化目标。
在这里,可以根据比较结果确定初始神经网络是否达到预设的优化目标。作为示例,当一个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜之间的差异小于预设差异阈值时,认为该无混响语音的掩膜的准确率大于预设的准确率阈值。此时,上述优化目标可以是指上述初始神经网络生成的无混响语音的掩膜的准确率大于上述准确率阈值的比例大于预设的比例阈值。若上述初始神经网络达到上述优化目标,则可以执行步骤5024。
在这里,训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜之间的差异可以为均方误差,此时,上述差异阈值可以为预设的最小均方误差。
步骤5024,若初始神经网络达到优化目标,将初始神经网络确定为训练完成的增强网络。
在这里,若在步骤5023中确定出上述初始神经网络达到上述优化目标,可以将初始神经网络确定为训练完成的增强网络。
需要说明的是,上述增强网络可以是语音信号去混响方法的执行主体通过上述方式训练得到的,也可以是其他电子设备训练得到的。
本公开的上述实施例提供的方法通过在确定出初始神经网络达到预设的优化目标时,将初始神经网络确定为训练完成的增强网络,从而可以使得增强网络更加准确地预测出掩膜。
在一些可选的实现方式中,训练得到上述增强网络的步骤还可以包括以下步骤:若上述初始神经网络未达到上述优化目标,可以调整初始神经网络的网络参数,以及使用未用过的训练样本组成训练样本集合,使用调整后的初始神经网络作为初始神经网络,继续执行上述训练步骤502(即子步骤5021-5024)。作为示例,可以采用反向传播算法(backpropgationalgorithm,bp算法)和梯度下降法(例如小批量梯度下降算法)对上述初始神经网络的网络参数进行调整。需要说明的是,反向传播算法和梯度下降法是目前广泛研究和应用的公知技术,在此不再赘述。
进一步参考图6,作为对上述各图所示方法的实现,本公开提供了一种语音信号去混响装置的一个实施例,该装置实施例与图2所示的方法实施例相对应,该装置具体可以应用于各种电子设备中。
如图6所示,本实施例的语音信号去混响装置600包括:第一转换单元601、延时单元602、第一确定单元603、第二确定单元604和第二转换单元605。其中,第一转换单元601用于将时域的混响语音信号转换到频域,得到频域的混响语音信号;延时单元602用于对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;第一确定单元603用于利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;第二确定单元604用于根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;第二转换单元605用于将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
在本实施例中,语音信号去混响装置600的第一转换单元601、延时单元602、第一确定单元603、第二确定单元604和第二转换单元605的具体处理可以参考图2对应实施例中的步骤201、步骤202、步骤203、步骤204和步骤205。
在一些可选的实现方式中,上述第二确定单元604可以进一步用于通过如下方式根据上述频域的混响语音信号和上述频域直达声的估计值,确定频域的无混响语音信号:上述第二确定单元604可以根据上述频域的混响语音信号和上述频域直达声的估计值,确定无混响语音的掩膜,之后,可以将上述掩膜和上述频域的混响语音信号相乘得到频域的无混响语音信号。
在一些可选的实现方式中,上述第一确定单元603可以进一步用于通过如下方式利用上述频域的混响语音信号和上述频域的延时混响语音信号,确定频域直达声的估计值:上述第一确定单元603可以根据上述频域的混响语音信号和上述频域的延时混响语音信号,确定语音信号的自相关功率谱和互相关功率谱;之后,可以根据上述自相关功率谱、上述互相关功率谱和预设的噪声空间相关函数,确定相干扩散能量比;最后,可以根据上述相干扩散能量比和上述频域的混响语音信号,确定频域直达声的估计值。
在一些可选的实现方式中,上述第二确定单元604可以进一步用于通过如下方式根据上述频域的混响语音信号和上述频域直达声的估计值,确定无混响语音的掩膜:上述第二确定单元604可以将上述频域的混响语音信号和上述频域直达声的估计值输入预先训练的增强网络中,得到无混响语音的掩膜。
在一些可选的实现方式中,上述增强网络可以是通过如下步骤训练得到的:获取训练样本集合,其中,训练样本包括:频域的样本混响语音信号、频域样本直达声信号和样本无混响语音的掩膜,频域样本直达声信号为将样本纯净语音信号转换到频域所得到的,频域的样本混响语音信号为将目标语音信号转换到频域所得到的,目标语音信号为将样本纯净语音信号与预设的房间冲击响应进行卷积操作所生成的,样本无混响语音的掩膜为频域的样本纯净语音信号与频域的样本混响语音信号之比;基于训练样本集合执行以下训练步骤:将训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到上述至少一个训练样本中的每个训练样本对应的无混响语音的掩膜;将上述至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较;根据比较结果确定初始神经网络是否达到预设的优化目标;若初始神经网络达到上述优化目标,将初始神经网络确定为训练完成的增强网络。
在一些可选的实现方式中,训练得到上述增强网络的步骤还可以包括:若初始神经网络未达到上述优化目标,调整初始神经网络的网络参数,以及使用未用过的训练样本组成训练样本集合,使用调整后的初始神经网络作为初始神经网络,继续执行上述训练步骤。
在一些可选的实现方式中,上述增强网络可以包括空间可变卷积网络和/或长短时记忆网络。
下面参考图7,其示出了适于用来实现本公开的实施例的电子设备(例如图1中的服务器或终端设备)700的结构示意图。本公开的实施例中的终端设备可以包括但不限于诸如移动电话、笔记本电脑、数字广播接收器、pda(个人数字助理)、pad(平板电脑)、pmp(便携式多媒体播放器)、车载终端(例如车载导航终端)等等的移动终端以及诸如数字tv、台式计算机等等的固定终端。图7示出的电子设备仅仅是一个示例,不应对本公开的实施例的功能和使用范围带来任何限制。
如图7所示,电子设备700可以包括处理装置(例如中央处理器、图形处理器等)701,其可以根据存储在只读存储器(rom)702中的程序或者从存储装置708加载到随机访问存储器(ram)703中的程序而执行各种适当的动作和处理。在ram703中,还存储有电子设备700操作所需的各种程序和数据。处理装置701、rom702以及ram703通过总线704彼此相连。输入/输出(i/o)接口705也连接至总线704。
通常,以下装置可以连接至i/o接口705:包括例如触摸屏、触摸板、键盘、鼠标、摄像头、麦克风、加速度计、陀螺仪等的输入装置706;包括例如液晶显示器(lcd)、扬声器、振动器等的输出装置707;包括例如磁带、硬盘等的存储装置708;以及通信装置709。通信装置709可以允许电子设备700与其他设备进行无线或有线通信以交换数据。虽然图7示出了具有各种装置的电子设备700,但是应理解的是,并不要求实施或具备所有示出的装置。可以替代地实施或具备更多或更少的装置。图7中示出的每个方框可以代表一个装置,也可以根据需要代表多个装置。
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信装置709从网络上被下载和安装,或者从存储装置708被安装,或者从rom702被安装。在该计算机程序被处理装置701执行时,执行本公开的实施例的方法中限定的上述功能。需要说明的是,本公开的实施例所述的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本公开的实施例中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开的实施例中,计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读信号介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:电线、光缆、rf(射频)等等,或者上述的任意合适的组合。
上述计算机可读介质可以是上述电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被该电子设备执行时,使得该电子设备:将时域的混响语音信号转换到频域,得到频域的混响语音信号;对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
可以以一种或多种程序设计语言或其组合来编写用于执行本公开的实施例的操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c ,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)——连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
附图中的流程图和框图,图示了按照本公开各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
根据本公开的一个或多个实施例,提供了一种语音信号去混响方法,包括:将时域的混响语音信号转换到频域,得到频域的混响语音信号;对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
根据本公开的一个或多个实施例,根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号,包括:根据频域的混响语音信号和频域直达声的估计值,确定无混响语音的掩膜,将掩膜和频域的混响语音信号相乘得到频域的无混响语音信号。
根据本公开的一个或多个实施例,利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值,包括:根据频域的混响语音信号和频域的延时混响语音信号,确定语音信号的自相关功率谱和互相关功率谱;根据自相关功率谱、互相关功率谱和预设的噪声空间相关函数,确定相干扩散能量比;根据相干扩散能量比和频域的混响语音信号,确定频域直达声的估计值。
根据本公开的一个或多个实施例,根据频域的混响语音信号和频域直达声的估计值,确定无混响语音的掩膜,包括:将频域的混响语音信号和频域直达声的估计值输入预先训练的增强网络中,得到无混响语音的掩膜。
根据本公开的一个或多个实施例,增强网络是通过如下步骤训练得到的:获取训练样本集合,其中,训练样本包括:频域的样本混响语音信号、频域样本直达声信号和样本无混响语音的掩膜,频域样本直达声信号为将样本纯净语音信号转换到频域所得到的,频域的样本混响语音信号为将目标语音信号转换到频域所得到的,目标语音信号为将样本纯净语音信号与预设的房间冲击响应进行卷积操作所生成的,样本无混响语音的掩膜为频域的样本纯净语音信号与频域的样本混响语音信号之比;基于训练样本集合执行以下训练步骤:将训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到至少一个训练样本中的每个训练样本对应的无混响语音的掩膜;将至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较;根据比较结果确定初始神经网络是否达到预设的优化目标;若初始神经网络达到优化目标,将初始神经网络确定为训练完成的增强网络。
根据本公开的一个或多个实施例,训练得到增强网络的步骤还包括:若初始神经网络未达到优化目标,调整初始神经网络的网络参数,以及使用未用过的训练样本组成训练样本集合,使用调整后的初始神经网络作为初始神经网络,继续执行训练步骤。
根据本公开的一个或多个实施例,增强网络包括空间可变卷积网络和/或长短时记忆网络。
根据本公开的一个或多个实施例,一种语音信号去混响装置,包括:第一转换单元,用于将时域的混响语音信号转换到频域,得到频域的混响语音信号;延时单元,用于对时域的混响语音信号进行延时,将延时后的混响语音信号转换到频域,得到频域的延时混响语音信号;第一确定单元,用于利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值;第二确定单元,用于根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号;第二转换单元,用于将频域的无混响语音信号转换到时域,得到时域的无混响语音信号。
根据本公开的一个或多个实施例,第二确定单元进一步用于通过如下方式根据频域的混响语音信号和频域直达声的估计值,确定频域的无混响语音信号:根据频域的混响语音信号和频域直达声的估计值,确定无混响语音的掩膜,将掩膜和频域的混响语音信号相乘得到频域的无混响语音信号。
根据本公开的一个或多个实施例,第一确定单元进一步用于通过如下方式利用频域的混响语音信号和频域的延时混响语音信号,确定频域直达声的估计值:根据频域的混响语音信号和频域的延时混响语音信号,确定语音信号的自相关功率谱和互相关功率谱;根据自相关功率谱、互相关功率谱和预设的噪声空间相关函数,确定相干扩散能量比;根据相干扩散能量比和频域的混响语音信号,确定频域直达声的估计值。
根据本公开的一个或多个实施例,第二确定单元进一步用于通过如下方式根据频域的混响语音信号和频域直达声的估计值,确定无混响语音的掩膜:将频域的混响语音信号和频域直达声的估计值输入预先训练的增强网络中,得到无混响语音的掩膜。
根据本公开的一个或多个实施例,增强网络是通过如下步骤训练得到的:获取训练样本集合,其中,训练样本包括:频域的样本混响语音信号、频域样本直达声信号和样本无混响语音的掩膜,频域样本直达声信号为将样本纯净语音信号转换到频域所得到的,频域的样本混响语音信号为将目标语音信号转换到频域所得到的,目标语音信号为将样本纯净语音信号与预设的房间冲击响应进行卷积操作所生成的,样本无混响语音的掩膜为频域的样本纯净语音信号与频域的样本混响语音信号之比;基于训练样本集合执行以下训练步骤:将训练样本集合中的至少一个训练样本的频域的样本混响语音信号和频域样本直达声信号输入初始神经网络,得到至少一个训练样本中的每个训练样本对应的无混响语音的掩膜;将至少一个训练样本中的每个训练样本对应的无混响语音的掩膜与对应的样本无混响语音的掩膜进行比较;根据比较结果确定初始神经网络是否达到预设的优化目标;若初始神经网络达到优化目标,将初始神经网络确定为训练完成的增强网络。
根据本公开的一个或多个实施例,训练得到增强网络的步骤还包括:若初始神经网络未达到优化目标,调整初始神经网络的网络参数,以及使用未用过的训练样本组成训练样本集合,使用调整后的初始神经网络作为初始神经网络,继续执行训练步骤。
根据本公开的一个或多个实施例,增强网络包括空间可变卷积网络和/或长短时记忆网络。
描述于本公开的实施例中所涉及到的单元可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的单元也可以设置在处理器中,例如,可以描述为:一种处理器包括第一转换单元、延时单元、第一确定单元、第二确定单元和第二转换单元。其中,这些单元的名称在某种情况下并不构成对该单元本身的限定,例如,第一转换单元还可以被描述为“将时域的混响语音信号转换到频域,得到频域的混响语音信号的单元”。
以上描述仅为本公开的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本公开的实施例中所涉及的范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离本公开构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本公开的实施例中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

