本发明涉及计算机应用技术领域,特别是涉及基于对抗训练的端到端的语音识别方法。
背景技术:
随着信息技术的发展,一些领域产生了大量的语音数据,例如客服语音记录。这些语音数据中包含着大量有用信息,分析这些信息关键的一步就是将语音转换为文字,也就是语音识别。语音识别质量的好坏会直接影响下游任务,因此语音识别逐渐成为一个热门的研究任务。语音识别旨在将音频数据转换为对应的文字。音频数据往往会有很多噪音,有些是录制音频时候的环境噪音,有些是存储音频时因为格式问题产生的噪音。这些噪音都会对语音识别造成干扰,影响语音识别的准确率。
传统的语音识别[1,2]系统使用大量的特征工程,包括专门的输入特征、声学模型等等。大量的精力被使用在了特征的选择和调优上。深度学习算法[3,4,5,6,7]的引入提高了语音识别系统的特征提取能力。虽然这一进步是明显的,但语音系统要想保证准确识别带有噪音的音频数据,仍然需要精心设计后面的声学字典等结构。
为了简化设计,近年来最新的研究工作主要关注于如何使用端到端[11,12,13,14]的框架实现语音识别系统。例如graves[8]等人提出基于循环神经网络(recurrentneuralnetwork,rnn)的端到端的语音识别方法,使用循环神经网络搭建端到端的语音识别模型。bahdanau[9]等人提出基于注意力机制的端到端的语音识别方法,该方法使用注意力机制学习语音序列的局部特征,提升语音识别的准确率。miao[10]等人提出基于transformer的端到端的语音识别方法,使用transformer结构实现了在线语音识别。但是目前这些端到端的方法鲁棒性不够强,对有噪音的音频数据识别准确率不够高。
技术实现要素:
本发明的目的是针对现有语音识别技术中对有噪音的音频数据识别准确率不够高的技术缺陷,而提供基于对抗训练的端到端的语音识别方法,在识别过程中,由于频域表示的音频数据受音调、音色影响很小,因此使用频域表示来表示音频数据以降低音调音色影响,提高识别准确度。
为实现本发明的目的所采用的技术方案是:
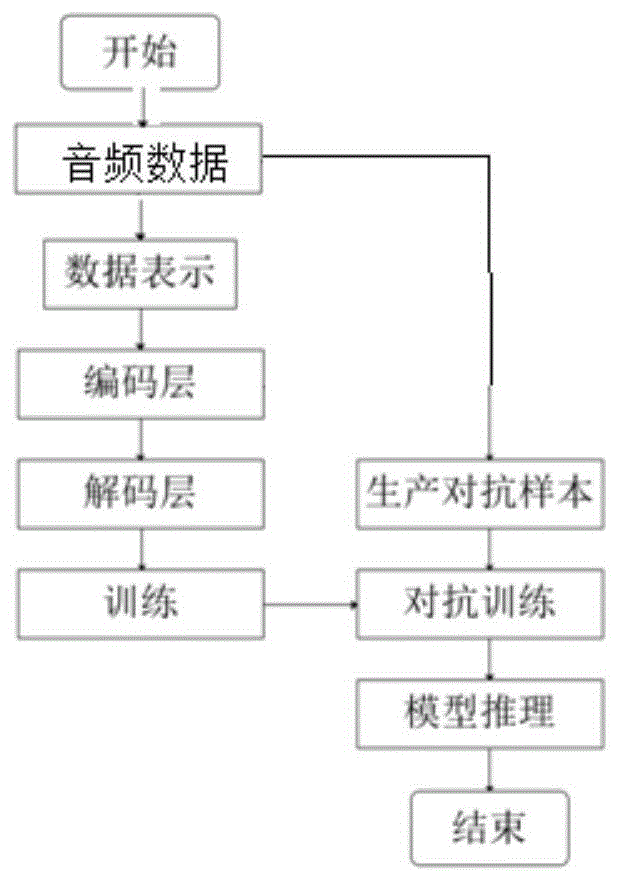
一种基于对抗训练的端到端的语音识别方法,包括按顺序执行的下列步骤:
步骤1:将待转换音频数据经短时傅里叶变换得频域表示;
步骤2:利用语音识别模型识别所述频域表示并解码输出解码文字;
步骤3:利用维特比算法在解码文字中搜索最优的文字序列,完成语音识别;
其中,步骤2中所述语音识别模型包括编码层和解码层,所述编码层包括卷积神经网络和编码自注意力机制,所述解码层为解码自注意力机制;
所述语音识别模型的训练方法包括按顺序执行的下列步骤:
步骤a:准备音频数据样本,将所述音频数据样本中的音频数据经短时傅里叶变换得到频域表示;
步骤b:利用所述语音识别模型提取步骤a所得频域表示中的特征,得到音频特征向量,并解码输出解码文字;
步骤c:利用ctc算法,将步骤b输出的解码文字与音频数据样本中的标签文本对齐;
步骤d:构建损失函数,将所述语音识别模型中的参数修改为损失函数最小值所对应的参数,对语音识别模型进行学习和优化;
步骤e:向步骤a所述音频数据中添加微小扰动生成对抗样本,将所述对抗样本输入步骤d学习优化后的语音识别模型中进行对抗训练,以提升所述语音识别模型的鲁棒性。
在上述技术方案中,步骤1中,将音频数据x={x1,x2,...,xt}中较长的时间信号分成相同长度且较短的信号段序列xw={xw1,xw2,...,xwn},然后在每一所述信号段序列上进行傅里叶变换,得到频域表示xe={xe1,xe2,...,xen};
所述傅里叶变换为离散时间傅里叶变换,计算公式如下:
x(n)代表音频数据,xe代表频域表示,j表示复数。
在上述技术方案中,步骤2中,首先使用卷积神经网络对步骤1所得的频域表示xe={xe1,xe2,...,xen}进行特征提取,得到特征向量xc={xc1,xc2,...,xcn};然后利用编码自注意力机制进一步学习所述特征向量xc={xc1,xc2,...,xcn}的局部特征得到音频特征向量xa={xa1,xa2,...,xan};最后利用解码自注意力机制解码输出解码文字。
在上述技术方案中,使用卷积神经网络进行特征提取的计算公式如下:
xc=cnn(xe)(2)
其中,xc代表特征向量,cnn代表卷积神经网络,xe代表频域表示;
其中卷积神经网络共有两层,第一层卷积核大小为3*3,第二层卷积核大小为5*5,卷积核移动步长为2;
卷积神经网络中,使用relu函数作为激活函数,选择meanpooling的方法来进行池化操作;其中,relu函数的定义如下所示:
f(x)=max(0,x)(3)
式中x为输入信号,f为输出信号。
在上述技术方案中,利用编码自注意力机制进一步学习局部特征的计算公式如下:
xa=mh_sa(xc)(4)
其中,mha_sa为多头注意力机制;所述多头注意力机制mha_sa的计算方法是,首先做多次单头注意力计算,然后将每次单头注意力计算的结果合并;
所述单头注意力计算公式如下:
其中
将每次单头注意力计算的结果合并的计算公式如下:
其中,
在上述技术方案中,利用解码自注意力机制解码的计算公式如下:
其中y={y1,y2,...,yl}为标签序列,x1:an是音频特征向量。
在上述技术方案中,步骤3中,维特比算法公式如下:
其中,y*代表最优输出,
在上述技术方案中,所述训练方法步骤c中,ctc算法解码的目标函数为pctc(y|xa)。
在上述技术方案中,所述训练方法步骤d中,构建损失函数时使用多目标损失函数,具体计算过程如下:
其中
在上述技术方案中,所述训练方法步骤e中,所述对抗样本是使用梯度上升算法计算所得,计算公式如下:
其中
对抗训练的计算过程如下:
minθe(x,y)~[l(x δx,y;θ)](11)
与现有技术相比,本发明的有益效果是:
1.本发明提供的语音识别模型,该语音势识别模型使用卷积神经网络构建编码层,同时引入自注意力机制,以获取局部特征,提升识别准确度。
2.本发明提供的语音识别模型,其训练方法中生成对抗样本,通过训练对抗样本提高模型的鲁棒性,使模型具有识别带噪音频数据的能力。
3.本发明提供的语音识别方法,在识别过程中,由于频域表示的音频数据受音调、音色影响很小,因此使用频域表示来表示音频数据以降低音调音色影响,提高识别准确度。
附图说明
附图1是语音识别模型的整体系统结构示意图。
附图2是基于对抗训练的端到端的语音识别方法的示意图。
具体实施方式
以下结合具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明主要采用深度学习技术对音频数据进行识别,为了保证系统的正常运行,在具体实施中,要求所使用的计算机平台配备不低于8g的内存,cpu核心数不低于4个且主频不低2.66hz、gpu环境、linux操作系统,并安装python3.6及以上版本、pytorch0.4及以上版本等必备软件环境。
实施例1
一种语音识别模型,包括编码层和解码层,所述编码层包括卷积神经网络和编码自注意力机制,所述解码层为解码自注意力机制。
上述语音识别模型,使用卷积神经网络构建编码层,同时引入编码自注意力机制,以获取局部特征,提升识别准确度。在识别过程中,由于频域表示的音频数据受音调、音色影响很小,因此使用频域表示来表示音频数据以降低音调音色影响,提高识别准确度。
所述语音识别模型的识别方法,包括以下步骤:
步骤a:使用卷积神经网络对音频数据转换所得的频域表示xe={xe1,xe2,...,xen}进行特征提取,得到特征向量xc={xc1,xc2,...,xcn};使用卷积神经网络进行特征提取的计算公式如下:
xc=cnn(xe)(2)
其中,xc代表特征向量,cnn代表卷积神经网络,xe代表频域表示;
为了提取不同层次的特征,其中卷积神经网络共有两层,第一层卷积核大小为3*3,第二层卷积核大小为5*5,卷积核移动步长为2;
卷积神经网络中,使用relu函数作为激活函数,选择meanpooling的方法来进行池化操作;其中,relu函数的定义如下所示:
f(x)=max(0,x)(3)
式中x为输入信号,f为输出信号;
步骤b:利用编码自注意力机制进一步学习所述特征向量xc={xc1,xc2,...,xcn}的局部特征得到音频特征向量xa={xa1,xa2,...,xan};
利用编码自注意力机制进一步学习局部特征的计算公式如下:
xa=mh_sa(xc)(4)
其中,mha_sa为多头注意力机制;
所述多头注意力机制mha_sa的计算方法是,首先做多次单头注意力计算,然后将每次单头注意力计算的结果合并;
所述单头注意力计算公式如下:
其中
将每次单头注意力计算的结果合并的计算公式如下:
其中,
步骤c:使用解码自注意力机制对所得的音频特征向量xa={xa1,xa2,...,xan}进行解码输出解码文字。利用自注意力机制解码的计算公式如下:
其中y={y1,y2,...,yl}为标签序列,x1:an是音频特征向量。
实施例2
本实施例是介绍实施例1所述的语音识别模型的训练方法。
一种语音识别模型的训练方法,包括按顺序执行的下列步骤:
步骤1:数据表示,准备音频数据样本,将所述音频数据样本中的音频数据经短时傅里叶变换得到频域表示;
具体来说,将音频数据x={x1,x2,...,xt}中较长的时间信号分成相同长度且较短的信号段序列xw={xw1,xw2,...,xwn},然后在每一所述信号段序列上进行傅里叶变换,得到频域表示xe={xe1,xe2,...,xen};
例如,一段长10s的音频数据,将每段的时间设置为25ms,相邻段之间的滑动尺寸设置为10ms,此时相邻段之间的交叠大小为15ms,10s的音频数据可以得到999个长度为25ms的小段。
然后对每一段,进行512点快速傅里叶变换,得到对应的频域表示xe1={0.35,0.68,...,0.25},其长度为512,每个数字代表相应频率的振幅大小。
所述傅里叶变换为离散时间傅里叶变换,计算公式如下:
x(n)代表音频数据,xe代表频域表示,j表示复数。
步骤2:利用实施例1所述的语音识别模型提取步骤1所得频域表示中的特征,得到音频特征向量,并解码输出解码文字;
步骤3:利用ctc算法,将步骤2输出的解码文字与音频数据样本中的标签文本对齐;
其中,ctc解码的目标函数为pctc(y|xa)。
步骤4:构建损失函数,将实施例1所述的语音识别模型中的参数修改为损失函数最小值所对应的参数,对实施例1所述的语音识别模型进行学习和优化;
由于解码层分别使用注意力机制和ctc解码,构建损失函数时使用多目标损失函数,具体计算过程如下:
其中
步骤5:向步骤2所述音频特征向量中添加微小扰动生成对抗样本,进行对抗训练以提升实施例1所述的语音识别模型的鲁棒性。
所述对抗样本是使用梯度上升算法计算所得,计算公式如下:
其中
对抗训练的计算过程如下:
minθe(x,y)~[l(x δx,y;θ)](11)
实施例3
本实施例是介绍一种利用实施例2所述的训练方法训练的语音识别模型进行语音识别的方法。
一种基于对抗训练的端到端的语音识别方法,包括按顺序执行的下列步骤:
步骤1:数据表示,将待转换音频数据经短时傅里叶变换得频域表示;
步骤2:利用实施例1所述的语音识别模型识别所述频域表示并解码输出解码文字;
步骤3:利用维特比算法在解码文字中搜索最优的文字序列,完成语音识别。
维特比算法公式如下:
其中,y*代表最优输出,
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

