本发明涉及语音控制技术领域,特别涉及一种饮水机语音控制方法及系统。
背景技术:
目前,当用户使用饮水机冲泡不同类型的饮品(咖啡、茶和奶粉等)时,需要相应适宜温度的水来进行冲泡,用户得通过操作饮水机上的物理按键来设定水温,比较繁琐。
技术实现要素:
本发明目的之一在于提供了一种饮水机语音控制方法及系统,在用户使用饮水机冲泡不同类型的饮品时,只需说出唤醒指令以及想要冲泡的饮品类型即可,饮水机自动准备相应适宜温度的水供用户使用,十分便捷。
本发明实施例提供的一种饮水机语音控制方法,包括:
获取用户输入的第一语音控制指令;
解析第一语音控制指令,若第一语音控制指令为唤醒指令,获取用户输入的第二语音控制指令;
解析第二语音控制指令,确定用户想要冲泡的饮品类型;
确定饮品类型对应的答复语音和目标水温;
播放答复语音,同时控制饮水机将水温调节至目标水温。
优选的,获取用户输入的第一语音控制指令,包括:
获取预设的语音控制记录;
获取预设的第一评估模型,采用第一评估模型对语音控制记录进行评估;
获取第一评估模型对语音控制记录进行评估后输出的多个第一评估值;
基于第一评估值计算第一评估指数,计算公式如下:
其中,θ1为第一评估指数,μ1和μ2为预设的权重值,α1,i为语音控制记录经第一评估模型评估后输出的第i个第一评估值,n1为为语音控制记录经第一评估模型评估后输出的第一评估值的总数目,α1,0为预设的第一评估值阈值,e为自然常数;
获取预设的第二评估模型,采用第二评估模型对语音控制记录进行评估;
获取第二评估模型对语音控制记录进行评估后输出的多个第二评估值;
基于第二评估值计算第二评估指数,计算公式如下:
其中,θ2为第二评估指数,μ1和μ2为预设的权重值,α2,i为语音控制记录经第二评估模型评估后输出的第i个第二评估值,n2为为语音控制记录经第二评估模型评估后输出的第二评估值的总数目,α2,0为预设的第二评估值阈值,e为自然常数;
基于第一评估指数和第二评估指数计算第一判定指数,计算公式如下:
其中,γ1为第一判定指数,σ1和σ2为预设的权重值,θ1为第一评估指数,θ2为第二评估指数;
当第一判定指数大于等于预设的第一判定指数阈值时,获取第一语音控制指令。
优选的,确定饮品类型对应的答复语音和目标水温,包括:
获取预设的配对数据库,配对数据库包括:第一分区和第二分区;
从第一分区内确定与饮品类型对应的答复语音和目标水温;
若确定失败,从第二分区内确定与饮品类型对应的答复语音和目标水温。
优选的,确定饮品类型对应的答复语音和目标水温之前,对第一分区和第二分区进行填充;
第一分区和第二分区的填充步骤如下:
获取预设的配对项列表,从配对项列表中选取任一配对项;
通过预设的第一获取路径获取与配对项相关联的第一关联数据;
获取预设的第一感知模型,采用第一感知模型对第一关联数据进行感知;
获取第一感知模型对第一关联数据进行感知后输出的多个第一感知值;
基于第一感知值计算第一感知指数,计算公式如下:
其中,p1为第一感知指数,j1和j2为预设的权重值,q1,t为第一关联数据经第一感知模型进行感知后输出的第t个第一感知值,z1为第一关联数据经第一感知模型进行感知后输出的第一感知值的总数目,q1,0为预设的第一感知值阈值,e为自然常数;
通过预设的第二获取路径获取与配对项相关联的第二关联数据;
获取预设的第二感知模型,采用第二感知模型对第二关联数据进行感知;
获取第二感知模型对第二关联数据进行感知后输出的多个第二感知值;
基于第二感知值计算第二感知指数,计算公式如下:
其中,p2为第二感知指数,j1和j2为预设的权重值,q2,t为第二关联数据经第二感知模型进行感知后输出的第t个第二感知值,z2为第二关联数据经第二感知模型进行感知后输出的第二感知值的总数目,q2,0为预设的第二感知值阈值,e为自然常数;
基于第一感知指数和第二感知指数计算第二判定指数,计算公式如下:
其中,γ2为第二判定指数,ω1和ω2为预设的权重值,p1为第一感知指数,p2为第二感知指数;
当第二判定指数大于等于预设的第二判定指数阈值时,将配对项填充至第一分区,否则填充至第二分区。
优选的,饮水机语音控制方法,还包括:
获取解析第一语音控制指令的第一用时;
获取解析第二语音控制指令的第二用时;
查询预设的复杂度对照表,分别确定第一用时对应的第一复杂度和第二用时对应的第二复杂度;
获取预设的区间制定规则,根据区间制定规则基于第一复杂度制定第一复杂度区间,根据区间制定规则基于第二复杂度制定第二复杂度区间;
获取预设的复杂度记录数据库,从复杂度记录数据库中确定预设的时间段对应的多个第三复杂度;
将落在第一复杂度区间内的第三复杂度作为第四复杂度;
将落在第二复杂度区间内的第三复杂度作为第五复杂度;
基于第一复杂度、第二复杂度、第四复杂度和第五复杂度计算需求指数,计算公式如下:
其中,ε为需求指数,ar为第r个第四复杂度,x1为第四复杂度的总数目,br为第r个第五复杂度,x2为第五复杂度的总数目,o1为第一复杂度,o2为第二复杂度;
当需求指数大于等于预设的需求指数阈值时,对预设的本地语义识别数据库进行更新,和/或,在下一次解析第一语音控制指令或第二语音控制指令时,调用预设的联网识别模型对其进行解析。
本发明实施例提供的一种饮水机语音控制系统,包括:
获取模块,用于获取用户输入的第一语音控制指令;
第一解析模块,用于解析第一语音控制指令,若第一语音控制指令为唤醒指令,获取用户输入的第二语音控制指令;
第二解析模块,用于解析第二语音控制指令,确定用户想要冲泡的饮品类型;
确定模块,用于确定饮品类型对应的答复语音和目标水温;
控制模块,用于播放答复语音,同时控制饮水机将水温调节至目标水温。
优选的,获取模块执行包括如下操作:
获取预设的语音控制记录;
获取预设的第一评估模型,采用第一评估模型对语音控制记录进行评估;
获取第一评估模型对语音控制记录进行评估后输出的多个第一评估值;
基于第一评估值计算第一评估指数,计算公式如下:
其中,θ1为第一评估指数,μ1和μ2为预设的权重值,α1,i为语音控制记录经第一评估模型评估后输出的第i个第一评估值,n1为为语音控制记录经第一评估模型评估后输出的第一评估值的总数目,α1,0为预设的第一评估值阈值,e为自然常数;
获取预设的第二评估模型,采用第二评估模型对语音控制记录进行评估;
获取第二评估模型对语音控制记录进行评估后输出的多个第二评估值;
基于第二评估值计算第二评估指数,计算公式如下:
其中,θ2为第二评估指数,μ1和μ2为预设的权重值,α2,i为语音控制记录经第二评估模型评估后输出的第i个第二评估值,n2为为语音控制记录经第二评估模型评估后输出的第二评估值的总数目,α2,0为预设的第二评估值阈值,e为自然常数;
基于第一评估指数和第二评估指数计算第一判定指数,计算公式如下:
其中,γ1为第一判定指数,σ1和σ2为预设的权重值,θ1为第一评估指数,θ2为第二评估指数;
当第一判定指数大于等于预设的第一判定指数阈值时,获取第一语音控制指令。
优选的,确定模块执行包括如下操作:
获取预设的配对数据库,配对数据库包括:第一分区和第二分区;
从第一分区内确定与饮品类型对应的答复语音和目标水温;
若确定失败,从第二分区内确定与饮品类型对应的答复语音和目标水温。
优选的,饮水机语音控制系统,还包括:
填充模块,用于在确定模块确定饮品类型对应的答复语音和目标水温之前,对第一分区和第二分区进行填充;
填充模块执行包括如下操作:
获取预设的配对项列表,从配对项列表中选取任一配对项;
通过预设的第一获取路径获取与配对项相关联的第一关联数据;
获取预设的第一感知模型,采用第一感知模型对第一关联数据进行感知;
获取第一感知模型对第一关联数据进行感知后输出的多个第一感知值;
基于第一感知值计算第一感知指数,计算公式如下:
其中,p1为第一感知指数,j1和j2为预设的权重值,q1,t为第一关联数据经第一感知模型进行感知后输出的第t个第一感知值,z1为第一关联数据经第一感知模型进行感知后输出的第一感知值的总数目,q1,0为预设的第一感知值阈值,e为自然常数;
通过预设的第二获取路径获取与配对项相关联的第二关联数据;
获取预设的第二感知模型,采用第二感知模型对第二关联数据进行感知;
获取第二感知模型对第二关联数据进行感知后输出的多个第二感知值;
基于第二感知值计算第二感知指数,计算公式如下:
其中,p2为第二感知指数,j1和j2为预设的权重值,q2,t为第二关联数据经第二感知模型进行感知后输出的第t个第二感知值,z2为第二关联数据经第二感知模型进行感知后输出的第二感知值的总数目,q2,0为预设的第二感知值阈值,e为自然常数;
基于第一感知指数和第二感知指数计算第二判定指数,计算公式如下:
其中,γ2为第二判定指数,ω1和ω2为预设的权重值,p1为第一感知指数,p2为第二感知指数;
当第二判定指数大于等于预设的第二判定指数阈值时,将配对项填充至第一分区,否则填充至第二分区。
优选的,饮水机语音控制系统,还包括:
需求确定模块;
需求确定模块执行包括如下操作:
获取解析第一语音控制指令的第一用时;
获取解析第二语音控制指令的第二用时;
查询预设的复杂度对照表,分别确定第一用时对应的第一复杂度和第二用时对应的第二复杂度;
获取预设的区间制定规则,根据区间制定规则基于第一复杂度制定第一复杂度区间,根据区间制定规则基于第二复杂度制定第二复杂度区间;
获取预设的复杂度记录数据库,从复杂度记录数据库中确定预设的时间段对应的多个第三复杂度;
将落在第一复杂度区间内的第三复杂度作为第四复杂度;
将落在第二复杂度区间内的第三复杂度作为第五复杂度;
基于第一复杂度、第二复杂度、第四复杂度和第五复杂度计算需求指数,计算公式如下:
其中,ε为需求指数,ar为第r个第四复杂度,x1为第四复杂度的总数目,br为第r个第五复杂度,x2为第五复杂度的总数目,o1为第一复杂度,o2为第二复杂度;
当需求指数大于等于预设的需求指数阈值时,对预设的本地语义识别数据库进行更新,和/或,在下一次解析第一语音控制指令或第二语音控制指令时,调用预设的联网识别模型对其进行解析。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种饮水机语音控制方法的流程图;
图2为本发明实施例中一种饮水机语音控制系统的示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
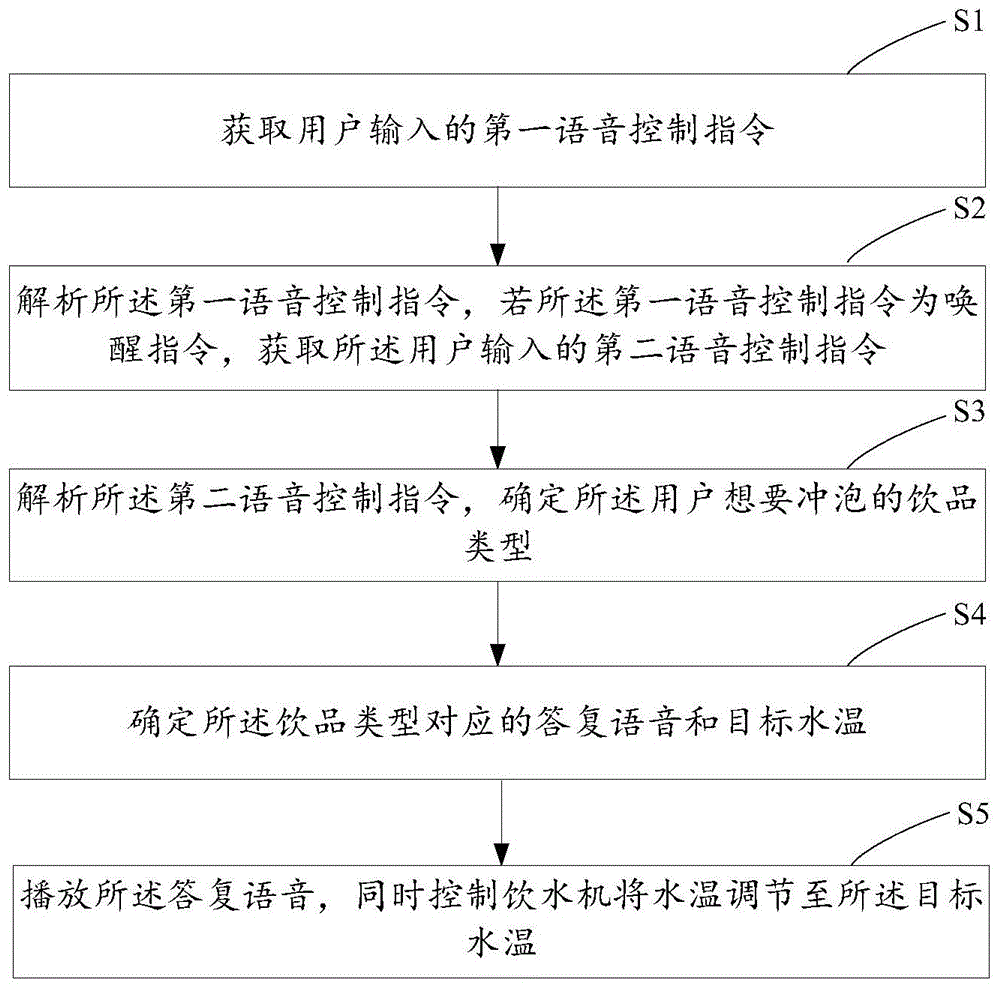
本发明实施例提供了一种饮水机语音控制方法,如图1所示,包括:
s1、获取用户输入的第一语音控制指令;
s2、解析第一语音控制指令,若第一语音控制指令为唤醒指令,获取用户输入的第二语音控制指令;
s3、解析第二语音控制指令,确定用户想要冲泡的饮品类型;
s4、确定饮品类型对应的答复语音和目标水温;
s5、播放答复语音,同时控制饮水机将水温调节至目标水温。
上述技术方案的工作原理及有益效果为:
对用户首次输入的第一语音控制指令进行解析,当该指令为唤醒指令(例如:“您好!饮水机。”)时,获取用户再次输入的第二语音控制指令,对该指令进行解析,确定用户想要冲泡的饮品类型,确定该饮品类型对应的答复语音和目标水温(例如:第二语音控制指令为“我待会想要泡一杯绿茶。”,则饮品类型为绿茶,绿茶对应的答复语音为“好的,冲泡绿茶的适宜温度为85℃,已开始加热。”,绿茶对应的目标水温为85℃),播放答复语音回复用户,同时控制饮水机将水温调至目标水温,调节完毕后,还可以播放调节成功的通知语音(例如:“绿茶冲泡水已准备好,请使用。”)。
本发明实施例在用户使用饮水机冲泡不同类型的饮品时,只需说出唤醒指令以及想要冲泡的饮品类型即可,饮水机自动准备相应适宜温度的水供用户使用,十分便捷。
本发明实施例提供了一种饮水机语音控制方法,获取用户输入的第一语音控制指令,包括:
获取预设的语音控制记录;
获取预设的第一评估模型,采用第一评估模型对语音控制记录进行评估;
获取第一评估模型对语音控制记录进行评估后输出的多个第一评估值;
基于第一评估值计算第一评估指数,计算公式如下:
其中,θ1为第一评估指数,μ1和μ2为预设的权重值,α1,i为语音控制记录经第一评估模型评估后输出的第i个第一评估值,n1为为语音控制记录经第一评估模型评估后输出的第一评估值的总数目,α1,0为预设的第一评估值阈值,e为自然常数;
获取预设的第二评估模型,采用第二评估模型对语音控制记录进行评估;
获取第二评估模型对语音控制记录进行评估后输出的多个第二评估值;
基于第二评估值计算第二评估指数,计算公式如下:
其中,θ2为第二评估指数,μ1和μ2为预设的权重值,α2,i为语音控制记录经第二评估模型评估后输出的第i个第二评估值,n2为为语音控制记录经第二评估模型评估后输出的第二评估值的总数目,α2,0为预设的第二评估值阈值,e为自然常数;
基于第一评估指数和第二评估指数计算第一判定指数,计算公式如下:
其中,γ1为第一判定指数,σ1和σ2为预设的权重值,θ1为第一评估指数,θ2为第二评估指数;
当第一判定指数大于等于预设的第一判定指数阈值时,获取第一语音控制指令。
上述技术方案的工作原理及有益效果为:
预设的语音控制记录具体为:饮水机投入使用后,接收到的语音控制指令及执行相应操作的记录;预设的第一评估模型具体为:利用机器学习算法对大量儿童语音控制乱操作的记录进行学习后生成的模型,该评估模型可以基于语音控制记录评估最近一短时间(例如:5分钟)内是否存在儿童乱操作(例如:模仿成人频繁说出唤醒指令和/或冲泡饮品类型指令等)的现象发生,评估后,自动输出第一评估值,第一评估值越小,说明发生儿童乱操作的可能性越大;预设的第二评估模型具体为:利用机器学习算法对大量成人语音控制乱操作的记录进行学习后生成的模型,该评估模型可以基于语音控制记录评估最近一短时间(例如:5分钟)内是否存在成人乱操作(例如:重复说出相同的冲泡饮品类型指令等)的现象发生,评估后,自动输出第二评估值,第二评估值越小,说明发生成人乱操作的可能性越大;评估整个语音控制记录的目的是使各模型结合最近出现的指令所表征的特征(例如:声纹等)是否在之前出现过综合进行评估,例如:若偶然出现,则乱操作的可能性较大;为避免偶然性误差问题,第一评估模型和第二评估模型会进行多次评估,输出多个评估值;基于各第一评估值计算第一评估指数,第一评估指数越小,说明发生儿童乱操作的总体可能性越大;基于各第二评估值计算第二评估指数,第二评估指数越小,说明发生成人乱操作的总体可能性越大;基于第一评估指数和第二评估指数计算第一判定指数,当第一判定指数大于等于预设的第一判定指数阈值(例如:85)时,才能获取第一语音控制指令;预设的第一评估值阈值具体为:例如,85;预设的第二评估值阈值具体为:例如,86。
本发明实施例使用第一评估模型和第二评估模型对语音控制记录进行评估,智能化地忽略儿童乱操作和/或成人乱操作,降低了使用功耗,提升了用户体验。
本发明实施例提供了一种饮水机语音控制方法,确定饮品类型对应的答复语音和目标水温,包括:
获取预设的配对数据库,配对数据库包括:第一分区和第二分区;
从第一分区内确定与饮品类型对应的答复语音和目标水温;
若确定失败,从第二分区内确定与饮品类型对应的答复语音和目标水温。
上述技术方案的工作原理及有益效果为:
预设的配对数据库具体为:多个配对项,每个配对项包括:饮品类型、答复语音和目标水温;该配对数据库划分为两个分区即第一分区和第二分区;该配对数据库包含多种饮品类型(例如:绿茶、茉莉花茶、白茶、乌龙茶、红茶、普洱茶、黄茶、青茶、奶粉、咖啡、奶茶、可可粉、果珍、椰子粉、抹茶粉和姜茶等)对应的适宜水温;在确定饮品类型对应的答复语音和目标水温时,优先从第一分区内确定与饮品类型对应的答复语音和目标水温,确定失败时,再从第二分区内确定与饮品类型对应的答复语音和目标水温。
本发明实施例的配对数据库包含多种饮品类型对应的适宜水温,可以最大程度满足用户的需求,提升了用户体验。
本发明实施例提供了一种饮水机语音控制方法,确定饮品类型对应的答复语音和目标水温之前,对第一分区和第二分区进行填充;
第一分区和第二分区的填充步骤如下:
获取预设的配对项列表,从配对项列表中选取任一配对项;
通过预设的第一获取路径获取与配对项相关联的第一关联数据;
获取预设的第一感知模型,采用第一感知模型对第一关联数据进行感知;
获取第一感知模型对第一关联数据进行感知后输出的多个第一感知值;
基于第一感知值计算第一感知指数,计算公式如下:
其中,p1为第一感知指数,j1和j2为预设的权重值,q1,t为第一关联数据经第一感知模型进行感知后输出的第t个第一感知值,z1为第一关联数据经第一感知模型进行感知后输出的第一感知值的总数目,q1,0为预设的第一感知值阈值,e为自然常数;
通过预设的第二获取路径获取与配对项相关联的第二关联数据;
获取预设的第二感知模型,采用第二感知模型对第二关联数据进行感知;
获取第二感知模型对第二关联数据进行感知后输出的多个第二感知值;
基于第二感知值计算第二感知指数,计算公式如下:
其中,p2为第二感知指数,j1和j2为预设的权重值,q2,t为第二关联数据经第二感知模型进行感知后输出的第t个第二感知值,z2为第二关联数据经第二感知模型进行感知后输出的第二感知值的总数目,q2,0为预设的第二感知值阈值,e为自然常数;
基于第一感知指数和第二感知指数计算第二判定指数,计算公式如下:
其中,γ2为第二判定指数,ω1和ω2为预设的权重值,p1为第一感知指数,p2为第二感知指数;
当第二判定指数大于等于预设的第二判定指数阈值时,将配对项填充至第一分区,否则填充至第二分区。
上述技术方案的工作原理及有益效果为:
预设的配对项列表具体为:多个配对项,每个配对项包括:饮品类型、答复语音和目标水温;预设的第一获取路径具体为:与本地饮品类型选择记录数据库(用于记录用户选择饮品类型记录的数据库)连接,用于获取本地饮品类型选择记录数据;第一关联数据即为本地饮品类型选择记录数据中与选取的配对项相关联的数据;预设的第一感知模型具体为:利用机器学习算法对大量本地饮品类型选择记录数据和人工评判偏好记录进行学习后生成的模型,该模型可以对第一关联数据进行感知,感知用户选择该配对项的偏好度,输出第一感知值,第一感知值越大,说明用户越偏好该配对项;预设的第二获取路径具体为:与互联网连接,通过该路径可以获取各个用户饮品类型选择记录数据的数据,即大数据;第二关联数据即为该大数据中与选取的配对项相关联的数据;预设的第二感知模型具体为:利用机器学习算法对大量饮品类型选择记录数据和人工评判偏好记录进行学习后生成的模型,该模型可以基于大数据中某数据来源的可信度来进行数据剔除等操作,还可以对第二关联数据进行感知,感知不同用户选择该配对项的偏好度,输出第二感知值,第二感知值越大,说明大多用户越偏好该配对项;基于各第一感知值计算第一感知指数,第一感知指数越大,说明该饮水机的用户偏好该配对项的总体程度越高;基于各第二感知值计算第二感知指数,第二感知指数越大,说明大多用户偏好该配对项的总体程度越高;基于第一感知指数和第二感知指数计算第二判定指数,当第二判定指数大于等于预设的第二判定指数阈值(例如:90)时,说明该配对被选择的可能性很大,应将其列入第一分区,以供优先确定;在计算第二判定指数阈值时,因着重结合用户本地选择记录数据,因此,ω1应大于ω2;预设的第一感知值阈值具体为:例如,88;预设的第二感知值阈值具体为:例如,89。
本发明实施例可以智能化地基于第一关联数据和第二关联数据决定选取的配对项应填充至第一分区还是第二分区,可以快速将被选取可能性很大的配对项列入第一分区,以供优先确定,大幅度减少了在确定饮品类型对应的答复语音和目标水温时的确定时间,提升了系统的工作效率,减少了系统回复用户以及采取温度调节控制的延迟,提升了用户体验。
本发明实施例提供了一种饮水机语音控制方法,还包括:
获取解析第一语音控制指令的第一用时;
获取解析第二语音控制指令的第二用时;
查询预设的复杂度对照表,分别确定第一用时对应的第一复杂度和第二用时对应的第二复杂度;
获取预设的区间制定规则,根据区间制定规则基于第一复杂度制定第一复杂度区间,根据区间制定规则基于第二复杂度制定第二复杂度区间;
获取预设的复杂度记录数据库,从复杂度记录数据库中确定预设的时间段对应的多个第三复杂度;
将落在第一复杂度区间内的第三复杂度作为第四复杂度;
将落在第二复杂度区间内的第三复杂度作为第五复杂度;
基于第一复杂度、第二复杂度、第四复杂度和第五复杂度计算需求指数,计算公式如下:
其中,ε为需求指数,ar为第r个第四复杂度,x1为第四复杂度的总数目,br为第r个第五复杂度,x2为第五复杂度的总数目,o1为第一复杂度,o2为第二复杂度;
当需求指数大于等于预设的需求指数阈值时,对预设的本地语义识别数据库进行更新,和/或,在下一次解析第一语音控制指令或第二语音控制指令时,调用预设的联网识别模型对其进行解析。
上述技术方案的工作原理及有益效果为:
预设的复杂度对照表具体为:多个对照项,每个对照项包括:用时区间和复杂度;查询该复杂度对照表时,当用时落在某用时区间内时即可确定对应的复杂度;解析用时越长,复杂度越高;预设的区间制定规则具体为:数值增加一定值作为区间上限,数值减小一定值作为区间下限;预设的复杂度记录数据库具体为:历史上依据解析用户确定的复杂度的记录;预设的时间段为:前60分钟;一般在解析用户输入的语音控制指令时,调用本地语义识别数据库(内存有大量用于语义识别的数据的数据库)对语音控制指令进行识别即可,但是当饮水机应用在一些特殊场景时(例如:用户普通话不是很标准等),系统解析时长会增加,基于各复杂度计算需求指数,需求指数越大,说明解析的困难性越大,当需求指数大于等于预设的需求指数阈值(例如:95)时,控制系统对本地语义识别数据库进行更新,提升其语义识别能力;还可以再下一次解析时,调用联网识别模型即可,该模型可以结合网络语义识别数据对一些特殊语音(例如:方言等)进行识别。
本发明实施例可以自行确定本地语义识别数据库的现行能力是否足够,在不足时,自动对其进行更新或调用联网识别模型对语音控制指令进行解析,无需时刻联网,降低了设备功耗,同时,也更加智能化。
本发明实施例提供了一种饮水机语音控制系统,如图2所示,包括:
获取模块1,用于获取用户输入的第一语音控制指令;
第一解析模块2,用于解析第一语音控制指令,若第一语音控制指令为唤醒指令,获取用户输入的第二语音控制指令;
第二解析模块3,用于解析第二语音控制指令,确定用户想要冲泡的饮品类型;
确定模块4,用于确定饮品类型对应的答复语音和目标水温;
控制模块5,用于播放答复语音,同时控制饮水机将水温调节至目标水温。
上述技术方案的工作原理及有益效果为:
对用户首次输入的第一语音控制指令进行解析,当该指令为唤醒指令(例如:“您好!饮水机。”)时,获取用户再次输入的第二语音控制指令,对该指令进行解析,确定用户想要冲泡的饮品类型,确定该饮品类型对应的答复语音和目标水温(例如:第二语音控制指令为“我待会想要泡一杯绿茶。”,则饮品类型为绿茶,绿茶对应的答复语音为“好的,冲泡绿茶的适宜温度为85℃,已开始加热。”,绿茶对应的目标水温为85℃),播放答复语音回复用户,同时控制饮水机将水温调至目标水温,调节完毕后,还可以播放调节成功的通知语音(例如:“绿茶冲泡水已准备好,请使用。”)。
本发明实施例在用户使用饮水机冲泡不同类型的饮品时,只需说出唤醒指令以及想要冲泡的饮品类型即可,饮水机自动准备相应适宜温度的水供用户使用,十分便捷。
本发明实施例提供了一种饮水机语音控制系统,获取模块1执行包括如下操作:
获取预设的语音控制记录;
获取预设的第一评估模型,采用第一评估模型对语音控制记录进行评估;
获取第一评估模型对语音控制记录进行评估后输出的多个第一评估值;
基于第一评估值计算第一评估指数,计算公式如下:
其中,θ1为第一评估指数,μ1和μ2为预设的权重值,α1,i为语音控制记录经第一评估模型评估后输出的第i个第一评估值,n1为为语音控制记录经第一评估模型评估后输出的第一评估值的总数目,a1,0为预设的第一评估值阈值,e为自然常数;
获取预设的第二评估模型,采用第二评估模型对语音控制记录进行评估;
获取第二评估模型对语音控制记录进行评估后输出的多个第二评估值;
基于第二评估值计算第二评估指数,计算公式如下:
其中,θ2为第二评估指数,μ1和μ2为预设的权重值,α2,i为语音控制记录经第二评估模型评估后输出的第i个第二评估值,n2为为语音控制记录经第二评估模型评估后输出的第二评估值的总数目,α2,0为预设的第二评估值阈值,e为自然常数;
基于第一评估指数和第二评估指数计算第一判定指数,计算公式如下:
其中,γ1为第一判定指数,σ1和σ2为预设的权重值,θ1为第一评估指数,θ2为第二评估指数;
当第一判定指数大于等于预设的第一判定指数阈值时,获取第一语音控制指令。
上述技术方案的工作原理及有益效果为:
预设的语音控制记录具体为:饮水机投入使用后,接收到的语音控制指令及执行相应操作的记录;预设的第一评估模型具体为:利用机器学习算法对大量儿童语音控制乱操作的记录进行学习后生成的模型,该评估模型可以基于语音控制记录评估最近一短时间(例如:5分钟)内是否存在儿童乱操作(例如:模仿成人频繁说出唤醒指令和/或冲泡饮品类型指令等)的现象发生,评估后,自动输出第一评估值,第一评估值越小,说明发生儿童乱操作的可能性越大;预设的第二评估模型具体为:利用机器学习算法对大量成人语音控制乱操作的记录进行学习后生成的模型,该评估模型可以基于语音控制记录评估最近一短时间(例如:5分钟)内是否存在成人乱操作(例如:重复说出相同的冲泡饮品类型指令等)的现象发生,评估后,自动输出第二评估值,第二评估值越小,说明发生成人乱操作的可能性越大;评估整个语音控制记录的目的是使各模型结合最近出现的指令所表征的特征(例如:声纹等)是否在之前出现过综合进行评估,例如:若偶然出现,则乱操作的可能性较大;为避免偶然性误差问题,第一评估模型和第二评估模型会进行多次评估,输出多个评估值;基于各第一评估值计算第一评估指数,第一评估指数越小,说明发生儿童乱操作的总体可能性越大;基于各第二评估值计算第二评估指数,第二评估指数越小,说明发生成人乱操作的总体可能性越大;基于第一评估指数和第二评估指数计算第一判定指数,当第一判定指数大于等于预设的第一判定指数阈值(例如:85)时,才能获取第一语音控制指令;预设的第一评估值阈值具体为:例如,85;预设的第二评估值阈值具体为:例如,86。
本发明实施例使用第一评估模型和第二评估模型对语音控制记录进行评估,智能化地忽略儿童乱操作和/或成人乱操作,降低了使用功耗,提升了用户体验。
本发明实施例提供了一种饮水机语音控制系统,确定模块4执行包括如下操作:
获取预设的配对数据库,配对数据库包括:第一分区和第二分区;
从第一分区内确定与饮品类型对应的答复语音和目标水温;
若确定失败,从第二分区内确定与饮品类型对应的答复语音和目标水温。
上述技术方案的工作原理及有益效果为:
预设的配对数据库具体为:多个配对项,每个配对项包括:饮品类型、答复语音和目标水温;该配对数据库划分为两个分区即第一分区和第二分区;该配对数据库包含多种饮品类型(例如:绿茶、茉莉花茶、白茶、乌龙茶、红茶、普洱茶、黄茶、青茶、奶粉、咖啡、奶茶、可可粉、果珍、椰子粉、抹茶粉和姜茶等)对应的适宜水温;在确定饮品类型对应的答复语音和目标水温时,优先从第一分区内确定与饮品类型对应的答复语音和目标水温,确定失败时,再从第二分区内确定与饮品类型对应的答复语音和目标水温。
本发明实施例的配对数据库包含多种饮品类型对应的适宜水温,可以最大程度满足用户的需求,提升了用户体验。
本发明实施例提供了一种饮水机语音控制系统,还包括:
填充模块,用于在确定模块4确定饮品类型对应的答复语音和目标水温之前,对第一分区和第二分区进行填充;
填充模块执行包括如下操作:
获取预设的配对项列表,从配对项列表中选取任一配对项;
通过预设的第一获取路径获取与配对项相关联的第一关联数据;
获取预设的第一感知模型,采用第一感知模型对第一关联数据进行感知;
获取第一感知模型对第一关联数据进行感知后输出的多个第一感知值;
基于第一感知值计算第一感知指数,计算公式如下:
其中,p1为第一感知指数,j1和j2为预设的权重值,q1,t为第一关联数据经第一感知模型进行感知后输出的第t个第一感知值,z1为第一关联数据经第一感知模型进行感知后输出的第一感知值的总数目,q1,0为预设的第一感知值阈值,e为自然常数;
通过预设的第二获取路径获取与配对项相关联的第二关联数据;
获取预设的第二感知模型,采用第二感知模型对第二关联数据进行感知;
获取第二感知模型对第二关联数据进行感知后输出的多个第二感知值;
基于第二感知值计算第二感知指数,计算公式如下:
其中,p2为第二感知指数,j1和j2为预设的权重值,q2,t为第二关联数据经第二感知模型进行感知后输出的第t个第二感知值,z2为第二关联数据经第二感知模型进行感知后输出的第二感知值的总数目,q2,0为预设的第二感知值阈值,e为自然常数;
基于第一感知指数和第二感知指数计算第二判定指数,计算公式如下:
其中,γ2为第二判定指数,ω1和ω2为预设的权重值,p1为第一感知指数,p2为第二感知指数;
当第二判定指数大于等于预设的第二判定指数阈值时,将配对项填充至第一分区,否则填充至第二分区。
上述技术方案的工作原理及有益效果为:
预设的配对项列表具体为:多个配对项,每个配对项包括:饮品类型、答复语音和目标水温;预设的第一获取路径具体为:与本地饮品类型选择记录数据库(用于记录用户选择饮品类型记录的数据库)连接,用于获取本地饮品类型选择记录数据;第一关联数据即为本地饮品类型选择记录数据中与选取的配对项相关联的数据;预设的第一感知模型具体为:利用机器学习算法对大量本地饮品类型选择记录数据和人工评判偏好记录进行学习后生成的模型,该模型可以对第一关联数据进行感知,感知用户选择该配对项的偏好度,输出第一感知值,第一感知值越大,说明用户越偏好该配对项;预设的第二获取路径具体为:与互联网连接,通过该路径可以获取各个用户饮品类型选择记录数据的数据,即大数据;第二关联数据即为该大数据中与选取的配对项相关联的数据;预设的第二感知模型具体为:利用机器学习算法对大量饮品类型选择记录数据和人工评判偏好记录进行学习后生成的模型,该模型可以基于大数据中某数据来源的可信度来进行数据剔除等操作,还可以对第二关联数据进行感知,感知不同用户选择该配对项的偏好度,输出第二感知值,第二感知值越大,说明大多用户越偏好该配对项;基于各第一感知值计算第一感知指数,第一感知指数越大,说明该饮水机的用户偏好该配对项的总体程度越高;基于各第二感知值计算第二感知指数,第二感知指数越大,说明大多用户偏好该配对项的总体程度越高;基于第一感知指数和第二感知指数计算第二判定指数,当第二判定指数大于等于预设的第二判定指数阈值(例如:90)时,说明该配对被选择的可能性很大,应将其列入第一分区,以供优先确定;在计算第二判定指数阈值时,因着重结合用户本地选择记录数据,因此,ω1应大于ω2;预设的第一感知值阈值具体为:例如,88;预设的第二感知值阈值具体为:例如,89。
本发明实施例可以智能化地基于第一关联数据和第二关联数据决定选取的配对项应填充至第一分区还是第二分区,可以快速将被选取可能性很大的配对项列入第一分区,以供优先确定,大幅度减少了在确定饮品类型对应的答复语音和目标水温时的确定时间,提升了系统的工作效率,减少了系统回复用户以及采取温度调节控制的延迟,提升了用户体验。
本发明实施例提供了一种饮水机语音控制系统,还包括:
需求确定模块4;
需求确定模块4执行包括如下操作:
获取解析第一语音控制指令的第一用时;
获取解析第二语音控制指令的第二用时;
查询预设的复杂度对照表,分别确定第一用时对应的第一复杂度和第二用时对应的第二复杂度;
获取预设的区间制定规则,根据区间制定规则基于第一复杂度制定第一复杂度区间,根据区间制定规则基于第二复杂度制定第二复杂度区间;
获取预设的复杂度记录数据库,从复杂度记录数据库中确定预设的时间段对应的多个第三复杂度;
将落在第一复杂度区间内的第三复杂度作为第四复杂度;
将落在第二复杂度区间内的第三复杂度作为第五复杂度;
基于第一复杂度、第二复杂度、第四复杂度和第五复杂度计算需求指数,计算公式如下:
其中,ε为需求指数,ar为第r个第四复杂度,x1为第四复杂度的总数目,br为第r个第五复杂度,x2为第五复杂度的总数目,o1为第一复杂度,o2为第二复杂度;
当需求指数大于等于预设的需求指数阈值时,对预设的本地语义识别数据库进行更新,和/或,在下一次解析第一语音控制指令或第二语音控制指令时,调用预设的联网识别模型对其进行解析。
上述技术方案的工作原理及有益效果为:
预设的复杂度对照表具体为:多个对照项,每个对照项包括:用时区间和复杂度;查询该复杂度对照表时,当用时落在某用时区间内时即可确定对应的复杂度;解析用时越长,复杂度越高;预设的区间制定规则具体为:数值增加一定值作为区间上限,数值减小一定值作为区间下限;预设的复杂度记录数据库具体为:历史上依据解析用户确定的复杂度的记录;预设的时间段为:前60分钟;一般在解析用户输入的语音控制指令时,调用本地语义识别数据库(内存有大量用于语义识别的数据的数据库)对语音控制指令进行识别即可,但是当饮水机应用在一些特殊场景时(例如:用户普通话不是很标准等),系统解析时长会增加,基于各复杂度计算需求指数,需求指数越大,说明解析的困难性越大,当需求指数大于等于预设的需求指数阈值(例如:95)时,控制系统对本地语义识别数据库进行更新,提升其语义识别能力;还可以再下一次解析时,调用联网识别模型即可,该模型可以结合网络语义识别数据对一些特殊语音(例如:方言等)进行识别。
本发明实施例可以自行确定本地语义识别数据库的现行能力是否足够,在不足时,自动对其进行更新或调用联网识别模型对语音控制指令进行解析,无需时刻联网,降低了设备功耗,同时,也更加智能化。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

