本发明涉及中文自定义唤醒与物联交互方法,特别是其中的语音识别算法、意图识别算法和自然语言生成模型。该方法可以脱离云服务平台,保证隐私安全。使用一个浅层神经网络声学模型,实现few-shot甚至zero-shot的本地自定义语音唤醒方案。使用最新的transformer特征提取器代替传统的语言模型 解码器,借助自注意力机制实现拼音转文字的功能。使用nlp流行的预训练模型gpt和bert,分别利用其单向和双向的特点实现自然语言生成和自然语言理解。
背景技术:
随着深度学习、自然语言处理的发展,我们现在随处可见一些智能语音助手。这些语音助手被安装在了我们的手机、智能音箱等设备中,成为了用户与其他智能设备或服务的智能代理(intelligentagent),这种模式如今已经成为智能家居或其他物联交互中的主流方式。但这种通过智能代理传话、云端处理的方式也存在很多问题。目前各大科技公司提供的智能云服务平台都是闭源的,对于开发者来说过于依赖平台提供的接口,限制了产品功能的多样性,缺乏开发的灵活性;而对于使用者来说,其数据都发送至平台云端处理,用户的隐私得不到保障,特别是譬如智能家居这些偏向私密的场景下,数据的保密性和安全性问题尤显严重。因此,为了提高开发的灵活性和使用的安全性,迫切需要一个智能物联交互方法解决方案。
技术实现要素:
本发明要克服现有技术的上述缺点,提供一种基于智能语音芯片的中文自定义唤醒与物联交互方法。
本发明基本内容定位于语音与自然语言处理的实现上,整体的解决方案基于一个pipeline的对话,即语言识别-意图识别-对话管理-自然语言生成-语音合成。对话的每一部分都是本课题所要研究的对象。
本发明的具体内容包括:
(1)自定义中文语音唤醒
目前亚马逊alexa和百度dueros都采用了本地语音唤醒引擎snowboy。snowboy通过用户上传的语音数据训练特定词的识别模型。模型分为personal模型与universal模型,前者只用了极少的训练数据,只能识别特定人的语音(persondependent),后者是收集了大量语音数据后训练出的通用模型(personindependent)。然而,snowboy作为一个闭源的商业平台,对外只暴露了personaldependent模型训练的restfulapi接口。本发明将致力于找到更佳的唤醒词解决方案,第一是保证数据安全性,第二是提升模型的通用性。
(2)识别离线语音
几乎所有的智能语音开放平台都提供了“免费”的在线语音识别接口,用户的语音数据被各大平台收集,在大数据时代下这何尝不是一种隐性的收费模式?不仅如此,如今频繁曝出的大公司泄露用户隐私数据也向我们敲响了警钟,识别离线语音势在必行。如今有许多开源的离线中文语音识别方案,如pocketsphinx。本发明将致力于将识别语音本地化,并解决因此带来的硬件计算速度无法达到要求的问题。
(3)自然语言处理
这是智能语音服务的核心,也是本课题所有研究内容的核心。自然语言处理(naturallanguageprocessing)在这里包括了意图识别(intentionrecognition),槽位填充(slotfilling),对话管理(dialoguemanagement),自然语言生成(naturallanguagegeneration)。自然语言处理的目的是从用户千变万化的表达中,提取出最关键的意图信息和与意图相关的关键字信息,并生成相应的回馈信息。同样的,本发明致力于找到一个本地的自然语言处理解决方案。
本发明的基于智能语音芯片的中文自定义唤醒与物联交互方法,包括:
步骤1:唤醒语音,包括:
步骤1-1:提取语音特征;从麦克风获取语音信号,把语音信号进行分帧、加窗、傅里叶变换;经过傅里叶变换后再取绝对值或平方值得到的是二维的声谱图(spectrogram)。spectrogram再经过mel滤波器和log运算后后得到logmelspectrogram,也就是filterbank特征;
步骤1-2:检测唤醒词
选用cnn-ctc声学模型,神经网络的输入x是步骤1-1中得到的二维的特征序列,其中t为时间维度,输出y是未经对齐的标签,如"xiao3du4xiao3du4"(这里假设用拼音建模,数字代表音调),由于时间维度大于输出标签数,因此输出可以存在多条路径对应标签,如"xiao3xiao3du4du4xiao3du4du4du4"、"xiao3xiao3xiao3du4du4xiao3xiao3du4du4"等;ctc使用极大似然的思想,对应标签y,其关于输入x的后验概率可以表示为所有映射为y的路径之和,ctc的目标就是最大化后验概率,即
路径数量与时间长度t呈指数型关系,ctc使用动态规划思想对查找路径剪枝;预测过程和训练过程相似,计算上述后验概率p(y=唤醒词|x=特征序列),根据这个概率判断是否唤醒;
步骤2:识别离线语音;包括:
步骤2-1:运用cnn-ctc声学模型,将输入的语音转换为拼音;声学模型与步骤1-2中的模型类似,但因为没有功耗、运行速度上的限制,网络更加复杂,因此能达到更高的准确率;具体模型如图2所示;对比语音唤醒的声学模型,使用拼音作为建模单位,且使用二维卷积和二维池化层取代一维卷积核一维池化层,提高网络的特征提取能力;网络的输出的shape为200x1424;不同于语音唤醒的声学模型预测时使用动态规划法计算损失值,语音识别的声学模型预测时使用解码算法(贪婪搜索、集束搜索)得到最有可能的拼音序列;本实验使用集束宽度为10的集束搜索算法,集束搜索不同于贪婪算法只找最高概率的,而是找最高的若干个概率作为下一次的输入,依次迭代;
步骤2-2:运用transformer语言模型;
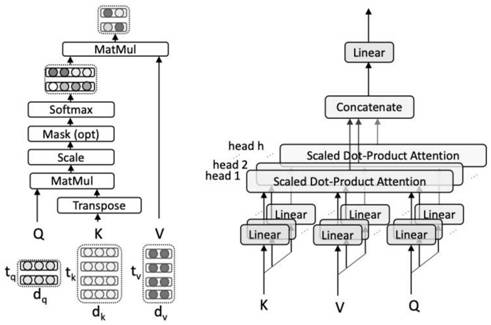
transformer语言模型的输入是cnn-ctc声学模型得到的拼音,输出是拼音转化成的文字;transformer作为近年来新提出的特征提取器,在自然语言处理和语音方面的许多领域都取得了优于rnn和cnn的表现;transformer的结构如图4所示,包含左边一个encoder和右边一个decoder,这里作为一个序列解码模型,只需要用到左边的encoder部分;transformerencoder由若干个transformerblock堆叠而成,每一个block由两个sublayers构成,第一个sublayer是multi-headattention多头自注意力结构,另一个sublayer是一个position-wisefeedforward网络,两个sublayer都使用了残差结构和layernormalization;自注意力机制学习到了输入序列内部的依赖关系,而不受限于距离,使输入序列学习到上下文相关的特征;如图3所示,自注意力机制仅仅是输入的线性组合,而使用非线性前馈全连接神经网络提高了模型的非线性表征能力;残差结构的加入有效地缓解了网络退化,layernormalization可以加速模型收敛;由于transformer的自注意力机制不考虑输入序列的顺序,但事实上语言的顺序也是一个重要的特征因素,因此除了对输入的内容进行embedding外,额外对输入加入了positionalencoding位置编码,使模型能学到输入之间的相对位置信息;
基于transformer的拼音解码模型在transformerencoder的最后连接一个全连接层,并使用softmax进行多分类;
步骤3:意图识别和槽填充,使用基于bert的联合意图识别和槽填充;
bert模型的输入是上一步骤中得到的文字,输出是文字所代表的意图;通过识别出的意图,可以进行天气查询和音乐播放的功能;
bert(bidirectionalencoderrepresentationsfromtransformer)是google在2018年提出的一种新的预训练自然语言处理模型。如图5所示,模型的主要结构是多个transformerencoders的堆叠;模型分为pre-train和fine-tuning两个阶段;pre-train的目标之一是训练一个双向语言模型,挖掘词的上下文信息;transformerencoder的自注意力机制将上下文的词编码到当前模型中,可以作为双向语言模型的特征提取器;但也正由于自注意力机制,多个transformerencoders堆叠来做词预测任务时存在标签泄露问题;因此使用maskedlanguagemodel,即将预测的词变为<mask>标签,但fine-tuning阶段输入不会出现<mask>标签,为了防止模型过分依赖于<mask>标签,只会将预测词的80%变为<mask>标签,10%变为随机token,10%不变;pre-train阶段的另外一个任务是nextsentenceprediction,目的是让模型理解两个句子之间的联系;fine-tuning阶段面向下游任务,根据不同的任务进行监督训练;
bert的自注意力机制在面对语义理解相关问题时具有天然优势,许多自然语言处理的下游任务都开始采用bert作为预训练模型,再在自己的task上进行fine-tuning;基于bert的联合意图识别和槽填充模型,如图6所示,[cls]标签经由bert后输出文本语义特征,特征经过一个dnn分类器后输出意图类别;token经由bert后输出上下文相关词义特征,特征经过dnn分类器后输出标签类别;假设意图类别和n个时间步上的标签在给定输入序列下互相条件独立,则联合模型可以由下式表示:
fine-tuning的目标函数是最大化上述概率,等价于最小化交叉熵损失;实际计算中分别计算意图识别和槽位填充的交叉熵损失值,他们之和就是联合模型的总体损失值;
步骤4:生成对话文本,使用基于gpt模型的对话文本生成;
gpt模型的输入是步骤2中得到的文字,输出是文字代表对话的文本,提供闲聊功能;
gpt模型是一种预训练 微调模型;如图7所示,gpt模型使用transformer的decoder部分作为特征提取器(没有与encoderattention的部分),面对下游任务时在gpt基础上扩展模型结构进行finetune;
使用最大化互信息(maximummutualinformation)作为训练目标,即使用
训练两个模型,一个正向的从输入到输出文本的dialoguemodel,对应于公式的logp(t|s)部分,一个逆向的从输出到输入文本的mmimodel,对应于公式的logp(s|t)部分;对话预处理时,将每一组对话数据(包含若干轮对话文本)合并成一句文本,使用[sep]标识符分割,最后在文本头添加[cls]标识符,尾部添加[sep]标识符,比如某个训练数据是:[cls]唉支持他的决定吧[sep]支持他是我对他的态度,接不接受是我个人的问题[sep]是这样的[sep]尽力吧[sep];这样,根据gpt-2的思想,只要数据量足够,模型是可以学到[sep]标识符左右的文本是一问一答的特征;训练时,借助语言模型根据前文预测下一个字的特点,将n个token文本的前n-1个token输入gpt,对应的label为后n-1个token,使用交叉熵作为损失函数,最大化公式的后验概率,逆向模型同理;预测时,dialoguemodel输入为历史对话数据和当前文本,然后逐个预测下一个字直到遇到[sep]标识符,正向模型可以生成多个候选回复,然后输入到mmimodel中,计算loss,选取loss最小的作为最终的回复文本。
优选地,时间维度t的取值是8。
与现有技术相比,本发明的优点在于:
1.cnn-ctc声学模型可以自定义唤醒词;
2.transformer语言模型对比使用hmm建模的声学符号转文本的生成模型,预测阶段不用进行非常耗时的解码运算。并且hmm假设观测变量(声学符号)之间条件独立于隐变量(文本序列),具有一定的不合理性,transformer结构恰恰捕捉到了输入之间的依赖关系,因此具有更好的表现;
3.对比bert模型使用双向语言模型作为预训练任务,gpt使用传统的自回归单向语言模型,即最大化下一个词出现的概率。单向语言模型具有只能看到前文信息、无法提取上下文特征的局限性,但也因此能够胜任自然语言生成的任务,因为自然语言生成就是仅需要前文信息,这一点bert模型不占优势。
附图说明
图1为本发明的整体流程示意图;
图2为本发明的语音识别声学模型图;
图3为多头自注意力结构图;
图4为本发明的transformerencoder-decoder模型图;
图5为本发明的bert两个阶段的模型图;
图6为本发明的基于bert的联合意图识别和槽填充模型图;
图7为本发明的gpt模型结构以及下游任务图。
具体实施方式
为了能够更容易理解本发明的流程,结合图1的流程图进行以下的具体介绍:
具体而言包括以下步骤:
本发明的基于智能语音芯片的中文自定义唤醒与物联交互方法的流程图如图1所示,包括:
步骤1:唤醒语音,包括:
步骤1-1:提取语音特征;
以16000hz的采样率获取语音数据,用25ms的分帧窗口大小和12.5ms的帧移进行分帧,即相邻两帧间有50%的重叠部分,加窗使用汉明窗;再做短时傅里叶变换之后取绝对值获得特征数据;
步骤1-2:检测唤醒词;
如图2所示,以音素建模,如“浙江工业大学”可以表示为“zhe4jiang1gong1iiie4da4xve2”网络的输入为624x200的logspectrogram,使用cnn深度神经网络提取声学特征,网络的输出shape为78x202,表示长度为78序列的202类分类问题。由于深度神经网络带来的计算时间、功耗问题,实验中加入vad语音活动检测算法,只会在检测到达到一定声音强度阈值时进行模型预测;预测阶段,计算后验概率p(y=唤醒词|x=特征序列),实际上等价于计算ctcloss,比如唤醒词为“gong1da4gong1da4”,则只需要计算标签为“gong1da4gong1da4”的ctcloss,得到的损失值是负对数概率,即-log(p(y=“gong1da4gong1da4”|x=特征序列)),只需要设定一个阈值,当负对数概率小于阈值时设备被唤醒。实验中为了提高模型的鲁棒性,设置了3个标签以及对应的权重作为唤醒词模型,每轮预测需要计算三次损失;
步骤2:识别语音;
步骤2-1:运用cnn-ctc声学模型;
训练集使用st-cmds语音数据集,包含10w多条不同人的语音数据和标签,由于训练设备资源受限,实验只取其中2w条语音数据,其中1.6w用于训练,0.4w条用于验证集。语音识别声学模型使用二维卷积模型,如图2所示;
cnn-ctc声学模型实验结果如表1所示:
表1语音识别声学模型性能及准确率测试表(在树莓派4上测试)
步骤2-2:运用transformer语言模型;
拼音转文字的序列分类模型在aishell-1训练集(只提取文本部分,使用pypinyin自动标注拼音)共12w条左右数据上训练,模型设置num_heads=8,num_blocks=4,hidden_units=512,batch_size=128,使用adam作为优化器,初始学习率0.001,训练时dropout率设为0.3。训练80个epochs在验证集上达到94.16%的准确率。表2展示了一些拼音转文本的测试,标红的表示转化错误;
表2transformer序列分类模型测试
步骤3:意图识别和槽填充,使用基于bert的联合意图识别和槽填充;
由于中文意图识别和槽位填充标准数据集较少,因此实验使用的数据集主要从不同来源的数据集拼凑而成,其中也有本人自己构造的部分,包括前文提到的共三种意图和多个槽位标签。数据划分为两部分,80%的训练集和20%的验证集;
使用bert softmax模型进行联合意图识别和槽位填充测试,训练时设置batchsize为32,使用adam作为优化器,初始学习率为0.00005;针对样本标签数量不均衡问题,如“b-scene”标签在训练集中只出现20次,而“o”标签出现了50000多次,对样本数量少的标签增大loss权重以缓解问题;在训练集上训练8000个steps,从表3中可以看出在训练完成后,模型已经在验证集上达到了较高的准确率;
表3bert softmax意图识别与槽填充测试
步骤4:生成对话文本,使用基于gpt模型的对话文本生成;
dialogpt的正向和逆向模型各自在nlpcc2018multi-turnhuman-computerconversations的50万轮对话数据上训练40轮,batch_size=16,使用adam作为优化器,初始学习率设置为0.00015;最终在训练集上达到0.5左右的准确率,在验证集上达到0.35左右的准确率;下表4测试了几组对话数据,由正向模型产生5个候选回复输入逆向模型中,最终回复取逆向模型损失值最小的一个;注意,由于使用的是采样解码,因此相同输入生成的回复是一个随机变量。
表4dialogpt对话生成测试
本发明已经通过上述实例进行了说明,但应当注意的是实例只是解释说明的目的,而非将本发明局限于该实例范围内。尽管参照前述实例本发明进行了详尽的说明,本领域研究人员应当能够理解:其依然可以随前述各实例所记载的技术方案进行修改,或者对其部分技术特征进行同等替换;二这些修改或替换,并不使相应的技术方案脱离本发明的保护范围。本发明的保护范围由附属的权力要求书机器等效范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

