本发明属于大数据技术领域,涉及企业智慧管理技术,具体是一种基于大数据的企业智慧管理系统及方法。
背景技术:
企业管理是对企业生产经营活动进行计划、组织、指挥、协调和控制等一系列活动的总称,是社会化大生产的客观要求。企业管理是尽可能利用企业的人力、物力、财力、信息等资源,实现省、快、多、好的目标,取得最大的投入产出效率。
现有的企业管理层在进行会议时,需要人工进行记录,然后再由管理层将会议内容传达给下属员工,当会议内容较多时,且一边进行记录时,会因为会议内容记录不全导致会议内容传达不准确,同时人工记录费时费力,为此,我们提出一种基于大数据的企业智慧管理系统及方法。
技术实现要素:
针对现有技术存在的不足,本发明目的是提供一种基于大数据的企业智慧管理系统及方法。
本发明所要解决的技术问题为:
如何在企业会议时无需人工记录和人工传达会议内容,解决因会议内容记录不全导致会议内容传达不准确的问题。
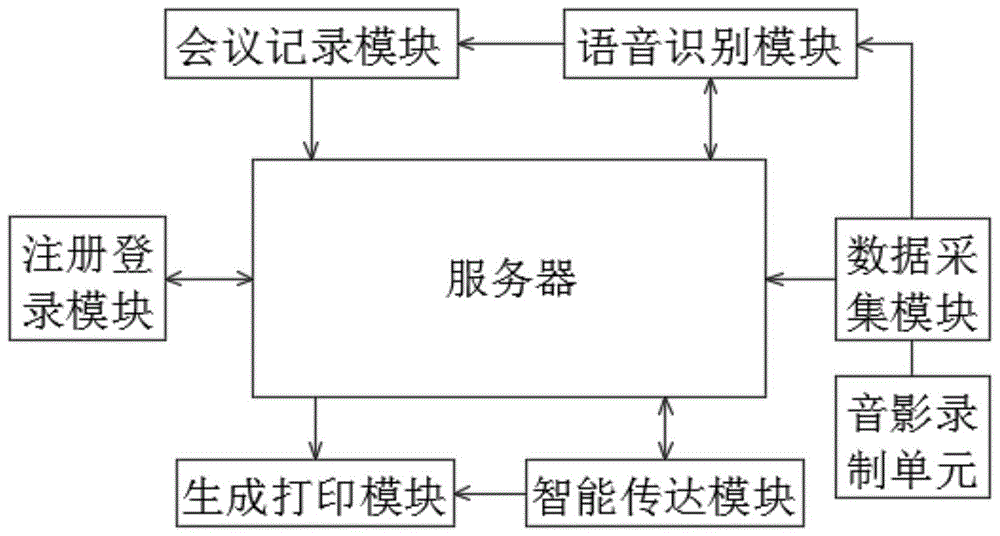
本发明的目的可以通过以下技术方案实现:一种基于大数据的企业智慧管理系统,包括注册登录模块、数据采集模块、语音识别模块、会议记录模块、生成打印模块、智能传达模块以及服务器;
所述数据采集模块将每次企业会议数据对应的语音信息发送至语音识别模块;所述语音识别模块接收到企业会议数据的语音信息,用于对企业会议数据的语音信息进行语音识别,语音识别过程具体如下:
步骤s1:提取企业会议数据中的语音信息,通过中文分词方法将企业会议中语音信息的若干个语音词语yu,u=1,2,……,x;
步骤s2:获取企业会议数据中的会议主题,将会议主题与文本词组进行逐字比对,得到与会议主题重复的文本词组的字数信息并将其标记为h1;将会议主题的总字数标记为h2,利用公式h3=h1/h2得到文本词组的重叠率h3;
步骤s3:对文本词组的重叠率h3进行判定;
步骤s4:将每个语音词语yu与首选识别组中的文本词语进行遍历比对,将首选识别组中的若干个文本词语记为wi,i=1,2,……,x;利用公式xu=wi/yu计算得到每个语音词语的相似率xu;
步骤s5:选取每个语音词语相似率的上限值,得到对应的文本词语;
所述服务器通过互联网与中文词库数据连接,所述中文词库中存储有文本词语之间的匹配分数;所述语音识别模块将企业会议中语音信息识别后的文本词语一一发送至会议记录模块;所述会议记录模块接收到语音识别模块发送的文本词语后,用于将文本词语进行在线拼接记录,在线拼接记录的工作步骤具体如下:
步骤ss1:获取每个文本词语首位字和末位字;
步骤ss2:将首位字的拼音和末位字的拼音分别与中文词库中的文字进行匹配,将文本词语首位字匹配成功对应的中文词库中的文字设置为首候选字,将文本词语末位字匹配成功对应的中文词库中的文字设置为末候选字;
步骤ss3:将首候选字、末候选字按照末候选字在前、首候选字在后的方式排列组成若干个候选词语;
步骤ss4:计算每个候选词语对应的匹配分数,每个候选词语对应的匹配分数降序排列后取前三名,得到每个候选词语前三名所对应的首候选字和末候选字,最后获取首候选字和末候选字分别对应的首位字和末位字;
步骤ss5:首位字所处的文本词语和末位字所处的文本词语相结合组成三组会议内容语句;
步骤ss6:三组会议内容语句发送至用户终端,用户终端的企业管理人员选取最符合企业会议内容的会议内容语句并反馈给服务器。
进一步地,所述注册登录模块用于企业员工通过用户终端输入个人信息后进行注册登录,并将个人信息发送至服务器内存储;
所述个人信息包括企业员工的姓名、性别、年龄、身份证号码、实名认证的手机号码、所属部门和企业工号。
进一步地,所述数据采集模块包括音影录制单元;
所述音影录制单元用于对企业会议的音影进行全程录制;所述数据采集模块用于对企业会议数据进行采集,并将采集到的企业会议数据发送至服务器;所述企业会议数据包括企业会议对应的部门、企业会议主题、企业会议对应的视频信息和语音信息;
所述服务器中存储有若干个文本词组,文本词组与会议主题一一对应;每个文本词组对应设置有若干个文本词语,每个文本词组的若干个文本词语组合成对应的语音识别组。
进一步地,文本词语重叠率的判定过程具体为:
当h3大于等于设定值x1时,获取得到重叠率最高的文本词语并将该文本词组对应的语音识别组记为首选识别组,执行步骤s4,其余的语音识别组记为替补识别组;
当h3小于设定值x1时,则判定此时文本词组出现错误,获取替补识别组与会议主题进行逐字比对。
进一步地,所述服务器将会议内容语句加上会议部门和会议主题生成带公司文件号的会议文件,并将带公司文件号的会议文件发送至智能传达模块;所述智能传达模块接收到服务器发送带公司文件号的会议文件,用于根据会议部门将会议文件智能传达至对应的部门;
在需要将会议文件进行生成打印时,所述智能传达模块将带公司文件号的会议文件和打印需求发送至生成打印模块,所述生成打印模块接收到智能传达模块发送的带公司文件号的会议文件和打印需求后,依据打印需求将带公司文件号的会议文件进行生成打印。
进一步地,所述打印需求包括打印份数、打印页面方式、打印规格和打印用纸规格。
一种基于大数据的企业智慧管理方法,企业智慧管理方法包括以下具体步骤:
步骤一,企业员工首先通过注册登录模块注册登录企业智慧管理系统,并将个人信息发送至服务器内存储;当公司在进行各种会议时,通过数据采集模块将企业会议数据进行采集;
步骤二,数据采集模块将每次企业会议数据对应的语音信息发送至语音识别模块,语音识别模块对企业会议数据的语音信息进行语音识别,提取企业会议数据中的语音信息,通过中文分词方法将企业会议中语音信息的若干个语音词语,同时获取企业会议数据中的会议主题,将会议主题与文本词组进行逐字比对,得到与会议主题重复的文本词组的字数信息以及会议主题的总字数,计算得到文本词组的重叠率,文本词组的重叠率大于等于设定值时,将重叠率最高的文本词组对应的语音识别组记为首选识别组,其余的语音识别组记为替补识别组;当文本词语的重叠率小于设定值时,则判定此时文本词组出现错误,获取替补识别组与会议主题进行逐字比对,将每个语音词语与首选识别组中的文本词语进行遍历比对,计算得到每个语音词语的相似率,选取每个语音词语相似率的上限值,得到对应的文本词语;
步骤三,语音识别模块将企业会议中语音信息识别后的文本词语一一发送至会议记录模块,会议记录模块接收到语音识别模块发送的文本词语后用于将文本词语进行在线拼接记录,获取每个文本词语首位字和末位字,将首位字的拼音和末位字的拼音分别与中文词库中的文字进行匹配,将文本词语首位字匹配成功对应的中文词库中的文字设置为首候选字,将文本词语末位字匹配成功对应的中文词库中的文字设置为末候选字,将首候选字、末候选字按照末候选字在前、首候选字在后的方式排列组成若干个候选词语,计算每个候选词语对应的匹配分数,每个候选词语对应的匹配分数降序排列后取前三名,得到每个候选词语前三名所对应的首候选字和末候选字,最后获取首候选字和末候选字分别对应的首位字和末位字,首位字所处的文本词语和末位字所处的文本词语相结合组成三组会议内容语句,三组会议内容语句发送至用户终端,用户终端的企业管理人员选取最符合企业会议内容的会议内容语句并反馈给服务器;
步骤四,服务器将会议内容语句加上会议部门和会议主题生成带公司文件号的会议文件,并将带公司文件号的会议文件发送至智能传达模块,智能传达模块根据会议部门将会议文件智能传达至对应的部门,在需要将会议文件进行生成打印时,智能传达模块将带公司文件号的会议文件和打印需求发送至生成打印模块,生成打印模块依据打印需求将带公司文件号的会议文件进行生成打印。
与现有技术相比,本发明的有益效果是:
1、本发明通过语音识别模块对企业会议数据的语音信息进行语音识别,通过中文分词方法将企业会议中语音信息的若干个文本词语,并获取企业会议数据中的会议主题,将会议主题与文本词组进行逐字比对,得到文本词语的重叠率,文本词组的重叠率与设定值进行比对,当文本词组的重叠率大于等于设定值时,将重叠率最高的文本词组对应的语音识别组记为首选识别组,其余的语音识别组记为替补识别组,当文本词组的重叠率小于设定值时,则判定此时文本词组出现错误,获取替补识别组与会议主题进行逐字比对,将每个语音词语与首选识别组中的文本词语进行遍历比对,计算得到每个语音词语的相似率,选取每个语音词语相似率的上限值,得到对应的文本词语;
2、本发明通过会议记录模块将文本词语进行在线拼接记录,通过每个文本词语首位字和末位字,将首位字的拼音和末位字的拼音分别与中文词库中的文字进行匹配得到首候选字和末候选字,计算每个候选词语对应的匹配分数,每个候选词语对应的匹配分数降序排列后取前三名,从而将对应的文本词语相结合组成三组会议内容语句,三组会议内容语句发送至用户终端,用户终端的企业管理人员选取最符合企业会议内容的会议内容语句并反馈给服务器;
3、本发明将会议内容语句加上会议部门和会议主题生成带公司文件号的会议文件发送至智能传达模块,智能传达模块根据会议部门将会议文件智能传达至对应的部门,同时在需要将会议文件进行生成打印时,智能传达模块将带公司文件号的会议文件和打印需求发送至生成打印模块,生成打印模块依据打印需求将带公司文件号的会议文件进行生成打印。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明的整体系统框图。
具体实施方式
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例将是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例一
请参阅图1所示,一种基于大数据的企业智慧管理系统,包括注册登录模块、数据采集模块、语音识别模块、会议记录模块、生成打印模块、智能传达模块以及服务器;
所述注册登录模块用于企业员工通过用户终端输入个人信息后进行注册登录,并将个人信息发送至服务器内存储;所述个人信息包括企业员工的姓名、性别、年龄、身份证号码、实名认证的手机号码、所属部门、企业工号等;
所述数据采集模块包括音影录制单元;所述音影录制单元用于对企业会议的音影进行全程录制;所述数据采集模块用于对企业会议数据进行采集,并将采集到的企业会议数据发送至服务器;所述企业会议数据包括企业会议对应的部门、企业会议主题、企业会议对应的视频信息和语音信息等;
所述服务器中存储有若干个文本词组,文本词组与会议主题一一对应;每个文本词组对应设置有若干个文本词语,每个文本词组的若干个文本词语组合成对应的语音识别组;
所述数据采集模块将每次企业会议数据对应的语音信息发送至语音识别模块;所述语音识别模块接收到企业会议数据的语音信息,用于对企业会议数据的语音信息进行语音识别,语音识别过程具体如下:
步骤s1:提取企业会议数据中的语音信息,通过中文分词方法将企业会议中语音信息的若干个语音词语yu,u=1,2,……,x;
步骤s2:获取企业会议数据中的会议主题,将会议主题与文本词组进行逐字比对,得到与会议主题重复的文本词组的字数信息并将其标记为h1;将会议主题的总字数标记为h2,利用公式h3=h1/h2得到文本词组的重叠率h3;
步骤s3:对文本词组的重叠率h3进行判定;
当h3大于等于设定值x1时,获取得到重叠率最高的文本词语并将该文本词组对应的语音识别组记为首选识别组,执行步骤s4,其余的语音识别组记为替补识别组;
当h3小于设定值x1时,则判定此时文本词组出现错误,获取替补识别组与会议主题进行逐字比对;
步骤s4:将每个语音词语yu与首选识别组中的文本词语进行遍历比对,将首选识别组中的若干个文本词语记为wi,i=1,2,……,x;利用公式xu=wi/yu计算得到每个语音词语的相似率xu;
步骤s5:选取每个语音词语相似率的上限值,得到对应的文本词语;
举例说明:首选识别组中包括文本词语wi={w1,w2,w3,……,wx},若语音词语y3对应的文本词语为w2时,语音词语y4在与首选识别组进行遍历比对时,语音词语y4则不再与首选识别组中的文本词语w2进行比对,但不排除语音词语y4与语音词语y3存在一定的相似度,相似度也可以设定一个阈值,若语音词语y4与语音词语y3的相似度比值超过这个阈值,语音词语y4则不需要与首选识别组进行遍历比对,直接将语音词语y3对应的文本词语w2披露给语音词语y4;
所述服务器通过互联网与中文词库数据连接,所述中文词库中存储有文本词语之间的匹配分数;所述语音识别模块将企业会议中语音信息识别后的文本词语一一发送至会议记录模块;所述会议记录模块接收到语音识别模块发送的文本词语后,用于将文本词语进行在线拼接记录,在线拼接记录的工作步骤具体如下:
步骤ss1:获取每个文本词语首位字和末位字;
步骤ss2:将首位字的拼音和末位字的拼音分别与中文词库中的文字进行匹配,将文本词语首位字匹配成功对应的中文词库中的文字设置为首候选字,将文本词语末位字匹配成功对应的中文词库中的文字设置为末候选字;
步骤ss3:将首候选字、末候选字按照末候选字在前、首候选字在后的方式排列组成若干个候选词语;
步骤ss4:计算每个候选词语对应的匹配分数,每个候选词语对应的匹配分数降序排列后取前三名,得到每个候选词语前三名所对应的首候选字和末候选字,最后获取首候选字和末候选字分别对应的首位字和末位字;
步骤ss5:首位字所处的文本词语和末位字所处的文本词语相结合组成三组会议内容语句;
步骤ss6:三组会议内容语句发送至用户终端,用户终端的企业管理人员选取最符合企业会议内容的会议内容语句并反馈给服务器;
举例说明:文本词语包括今天晚上、通信部、整体聚餐、地点在、醉高楼、务必、准时到达,则每个文本词语的首位字和末位字分别为:今、上;通、部;整、餐;地、在;醉、楼;务,必;准、达;
个文本词语的首位字和末位字:“:今、上;通、部;整、餐;地、在;醉、楼;务,必;准、达”与中文词库匹配成功后;
需要计算末位字“上”与其他首位字“部”、“整”、“地”、“醉”、“务”、“准”的匹配分数,以此类推计算末位字“部”、“餐”、“在”、“楼”、“必”、“达”与其他首位字的匹配分数;
中文词库中存储有“上”与“部”、“整”、“地”、“醉”、“务”、“准”的匹配分数分别为100、50、20、10、8.5、2;匹配分数通过日常语句整理分析,得到多个汉字之间的语句规律、语句习惯、语句通顺度等得到,可以设定在中午词库中;
此时,取匹配分数前三名的,此时末位字“上”与首位字“部”、“整”、“地”组成的候选词语为上部、上整、上地,分别获取对应的文本词语,即可组成会议内容语句“今天晚上通信部”、“今天晚上整体聚餐”、“今天晚上地点在”,企业管理人员选取“今天晚上通信部”最符合企业会议内容并反馈给服务器;
所述服务器将会议内容语句加上会议部门和会议主题生成带公司文件号的会议文件,并将带公司文件号的会议文件发送至智能传达模块;所述智能传达模块接收到服务器发送带公司文件号的会议文件,用于根据会议部门将会议文件智能传达至对应的部门;
在需要将会议文件进行生成打印时,所述智能传达模块将带公司文件号的会议文件和打印需求发送至生成打印模块,所述生成打印模块接收到智能传达模块发送的带公司文件号的会议文件和打印需求后,依据打印需求将带公司文件号的会议文件进行生成打印;
所述打印需求包括:打印份数、打印页面方式(单面打印、双面打印)、打印规格、打印用纸规格等。
实施例二
基于同一发明的另一构思,一种基于大数据的企业智慧管理方法,企业智慧管理方法包括以下具体步骤:
步骤一,企业员工首先通过注册登录模块注册登录企业智慧管理系统,并将个人信息发送至服务器内存储;当公司在进行各种会议时,通过数据采集模块将企业会议数据进行采集;
步骤二,数据采集模块将每次企业会议数据对应的语音信息发送至语音识别模块,语音识别模块对企业会议数据的语音信息进行语音识别,提取企业会议数据中的语音信息,通过中文分词方法将企业会议中语音信息的若干个语音词语,同时获取企业会议数据中的会议主题,将会议主题与文本词组进行逐字比对,得到与会议主题重复的文本词组的字数信息以及会议主题的总字数,计算得到文本词组的重叠率,文本词组的重叠率大于等于设定值时,将重叠率最高的文本词组对应的语音识别组记为首选识别组,其余的语音识别组记为替补识别组;当文本词语的重叠率小于设定值时,则判定此时文本词组出现错误,获取替补识别组与会议主题进行逐字比对,将每个语音词语与首选识别组中的文本词语进行遍历比对,计算得到每个语音词语的相似率,选取每个语音词语相似率的上限值,得到对应的文本词语;
步骤三,语音识别模块将企业会议中语音信息识别后的文本词语一一发送至会议记录模块,会议记录模块接收到语音识别模块发送的文本词语后用于将文本词语进行在线拼接记录,获取每个文本词语首位字和末位字,将首位字的拼音和末位字的拼音分别与中文词库中的文字进行匹配,将文本词语首位字匹配成功对应的中文词库中的文字设置为首候选字,将文本词语末位字匹配成功对应的中文词库中的文字设置为末候选字,将首候选字、末候选字按照末候选字在前、首候选字在后的方式排列组成若干个候选词语,计算每个候选词语对应的匹配分数,每个候选词语对应的匹配分数降序排列后取前三名,得到每个候选词语前三名所对应的首候选字和末候选字,最后获取首候选字和末候选字分别对应的首位字和末位字,首位字所处的文本词语和末位字所处的文本词语相结合组成三组会议内容语句,三组会议内容语句发送至用户终端,用户终端的企业管理人员选取最符合企业会议内容的会议内容语句并反馈给服务器;
步骤四,服务器将会议内容语句加上会议部门和会议主题生成带公司文件号的会议文件,并将带公司文件号的会议文件发送至智能传达模块,智能传达模块根据会议部门将会议文件智能传达至对应的部门,在需要将会议文件进行生成打印时,智能传达模块将带公司文件号的会议文件和打印需求发送至生成打印模块,生成打印模块依据打印需求将带公司文件号的会议文件进行生成打印。
上述公式均是去量纲取其数值计算,公式是由采集大量数据进行软件模拟得到最近真实情况的一个公式,公式中的预设参数由本领域的技术人员根据实际情况进行设置。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

