本发明涉及语音识别技术领域,更具体地说,本发明涉及一种基于实时人脸辅助的语音端点检测方法。
背景技术:
在语音信号处理中,强噪声环境下准确的语音端点检测(voiceactivitydetection,vad)对后期的信号处理尤为重要。vad用于从一段语音信号中检测出语音段的起止点,是语音识别系统中一个关键的预处理步骤,也被广泛应用于语音定位、去噪增强等方面。
端点检测时语音识别的重要环节之一,是其不可或缺的一部分,并且其好坏会直接影响到语音识别的准确率。一个表现好且优秀的端点检测技术,既不能检测过少,也不能检测过多。检测的少了,会使得语音信息丢失,造成漏识别;检测的多了,会使得语音首位包含噪声,在可能造成误识别或多识别的同时也会增加语音识别的实时率。由此可见端点检测对于语音识别的整体流程是至关重要的。
现有的语音的端点检测一般是提取语音的特征对提取得到的特征进行判断进而判断其中的语音或者非语音,或者建立声学模型对声音进行二分类或者进行解码得到的全局信息来判断其中的语音或者非语音。但是这两种方法在进行语音处理时效率低,需要处理的语音信息量大,获取语音端点的速率差。
技术实现要素:
为了克服现有技术的上述缺陷,本发明的实施例提供一种基于实时人脸辅助的语音端点检测方法,通过在用户出现面部语言动作时启动,在用户停止面部语言动作时停止,减少了获取语音信息中不必要的语音帧,极大的降低了进行语音端点检测过程中的操作程序,也使进行处理的语音信息总量得到了减少,从而提升了语音端点检测的速率,提高了实用性。
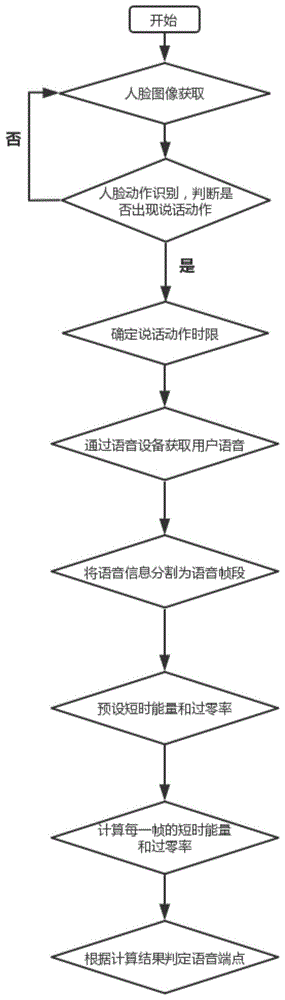
为实现上述目的,本发明提供如下技术方案:一种基于实时人脸辅助的语音端点检测方法,包括以下步骤:
步骤一,通过实时图像录取设备,获取用户面部的实时影像信息,并将影像信息传输至后台的控制中心,利用图像处理技术,对影像信息进行特征提取,获取影像信息中与用户面部相关的动作帧;
步骤二,提取用户面部特征,根据面部特征,确定数量不同的基准点,利用基准点构建用户的面部动作数据库,每个特定的面部动作由数个基准点组成,将步骤一中获取的动作帧与面部动作数据库中的面部特征进行对比,获取用户是否进行语言动作的信息;
步骤三,当获取用户进行语言动作的确定信息后,实时计算用户开始进行语言动作的时间和结束语言动作的时间,从而获取语言动作的两个时间端点和时间累计信息;
步骤四,设定语音获取设备的工作时限,将语音获取设备的启动单元与后台的控制中心连接,控制中心基于步骤三中语言动作的两端时间端点对语音获取设备进行启动和关闭,获取与用户相关的语音信息;
步骤五,将步骤四中获取的语音信息分割为多段语音帧段,并预设语音帧段的短时能量和过零率,然后计算每一帧的短时能量和过零率,根据计算结果判定语音端点。
在一个优选地实施方式中,所述步骤五中分割的语音帧段包括静音段、过度段、语音段和结束段。
在一个优选地实施方式中,将语音帧段的短时能量预设两个门限值α1和α2,将语音帧段的过零率预设两个门限值β1和β2;
其中,α2>α1,β1>β2。
在一个优选地实施方式中,连续计算每一帧的短时能量α和过零率β;
若α>α1&&β>β1,进入过渡段;
若α>α2&&β>β2,判定语音尚未开始,语音端点未确定;
继续计算下一帧的短时能量和过零率,若α<α2&&β<β2,判定语音开始,确定语音端点。
本发明的技术效果和优点:
在用户出现面部语言动作时启动,在用户停止面部语言动作时停止,减少了获取语音信息中不必要的语音帧,极大的降低了进行语音端点检测过程中的操作程序,也使进行处理的语音信息总量得到了减少,从而提升了语音端点检测的速率,提高了实用性。
附图说明
图1为本发明的方法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示的一种基于实时人脸辅助的语音端点检测方法,包括以下步骤:
通过实时图像录取设备,获取用户面部的实时影像信息,并将影像信息传输至后台的控制中心,利用图像处理技术,对影像信息进行特征提取,获取影像信息中与用户面部相关的动作帧;
提取用户面部特征,根据面部特征,确定数量不同的基准点,利用基准点构建用户的面部动作数据库,每个特定的面部动作由数个基准点组成,将上述获取的动作帧与面部动作数据库中的面部特征进行对比,获取用户是否进行语言动作的信息;
当获取用户进行语言动作的确定信息后,实时计算用户开始进行语言动作的时间和结束语言动作的时间,从而获取语言动作的两个时间端点和时间累计信息;
基于上述的内容,设定用户语言动作开始的时间为a,语言动作结束的时间为b,则该段语言动作的两个端点分别为a和b,时间累积信息为(b-a);
设定语音获取设备的工作时限,将语音获取设备的启动单元与后台的控制中心连接,控制中心基于上述语言动作的两端时间端点对语音获取设备进行启动和关闭,获取与用户相关的语音信息;
进一步的,即控制语音获取设备在a时启动,获取用户发出的语音信息,在b时关闭语音获取设备,将该段语音信息标记为(b-a),存储于系统内;
每段的语音信息设置不同的标记进行区分,进行后续的处理;
将上述获取的语音信息分割为多段语音帧段,并预设语音帧段的短时能量和过零率,然后计算每一帧的短时能量和过零率,根据计算结果判定语音端点;
上述分割的语音帧段包括静音段、过度段、语音段和结束段;
将语音帧段的短时能量预设两个门限值α1和α2,将语音帧段的过零率预设两个门限值β1和β2;
其中,α2>α1,β1>β2;
连续计算每一帧的短时能量α和过零率β;
若α>α1&&β>β1,进入过渡段;
若α>α2&&β>β2,判定语音尚未开始,语音端点未确定;
继续计算下一帧的短时能量和过零率,若α<α2&&β<β2,判定语音开始,确定语音端点;
在上述的基础上,由于获取的语音信息已经经过预先的处理,即语音获取设备的工作时间是经过控制的,在用户出现面部语言动作时启动,在用户停止面部语言动作时停止,减少了获取语音信息中不必要的语音帧,极大的降低了进行语音端点检测过程中的操作程序,也使进行处理的语音信息总量得到了减少,从而提升了语音端点检测的速率,提高了实用性。
最后应说明的几点是:首先,在本申请的描述中,需要说明的是,除非另有规定和限定,术语“安装”、“相连”、“连接”应做广义理解,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变,则相对位置关系可能发生改变;
其次:本发明公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计,在不冲突情况下,本发明同一实施例及不同实施例可以相互组合;
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

