本发明涉及信息处理技术领域,特别涉及一种基于神经网络vad算法的人机交互方法。
背景技术:
在人和ai电话机器人交互过程中,ai电话机器人不能像人一样智能,判断对方是否在说话,也不能区分人的声音和背景噪音,如何从输入语音里面提取有用的音频,过滤掉噪音,与人更智能的交互是目前ai电话机器人遇到的普遍问题。
目前使用的技术通常是设置一些vad参数来进行人机交互,但是这种方法普遍交互效果差,而且随着人群和环境的变化,不能动态自适应的调整条件参数,并且随着时间变长,交互效果会明显下降,此时只能通过人为的再次调整vad参数来适应新的变化。
因此,有必要提供一种基于神经网络vad算法的人机交互方法,以解决现有技术中人机交互效果差,需要人为调整vad参数的问题。
技术实现要素:
本发明的目的在于提供一种基于神经网络vad算法的人机交互方法,以解决现有技术中人机交互效果差,需要人为调整vad参数的问题。
为了达到上述目的,本发明提供了一种基于神经网络vad算法的人机交互方法,包括以下步骤:
对输入的音频信号进行预加载,保留有效的音频段;
对所述音频段进行数字化处理,并对所述数字化处理后的音频数字进行分帧和加窗操作;
把加窗操作后的音频数字作为新的样本放入样本集进行样本训练,采用神经网络和人机交互结果自动调整vad参数;
将调整好的vad参数运用于神经网络vad算法,采用神经网络vad算法读取加窗后的音频数字,以读取语音数据;
对读取到的语音数据进行降噪处理和频域滤波处理;
得到人机交互的输出结果。
可选的,在所述基于神经网络vad算法的人机交互方法中,自动调整vad参数的步骤如下:
加载神经网络提前训练得到的vad参数;
把加窗操作后的音频数字放入已有的样本集中;
在神经网络中,根据特征值将已有的样本集划分为不同节点,各节点对输入的新样本集进行后验概率向量降维;
将后验概率向量降维后的新样本集输入混合型神经网络中,混合型神经网络输出结果;
存储混合型神经网络的输出结果;
比较混合型神经网络的输出结果和人机交互的输出结果;
根据比较结果自动训练并调整vad参数。
可选的,在所述基于神经网络vad算法的人机交互方法中,所述混合型神经网络由深层神经网络和隐马尔科夫模型组成。
可选的,在所述基于神经网络vad算法的人机交互方法中,在得到调整后的vad参数后,递归所述vad参数。
可选的,在所述基于神经网络vad算法的人机交互方法中,降噪处理的方式为:对读取到的带噪音的语音数据进行平滑处理,公式为:
可选的,在所述基于神经网络vad算法的人机交互方法中,频域滤波处理的公式为:
在本发明所提供的基于神经网络vad算法的人机交互方法中,通过神经网络把新的音频数字作为新的样本放入样本集进行训练,在大量通话和相同背景下,结合利用人机交互的输出结果纠正vad参数,从而不断优化vad参数,以不断优化人机交互质量。
附图说明
图1为本发明实施例提供的人机交互方法的流程图;
图2为本发明实施例提供的训练并调整vad参数的示意图;
图3为本发明实施例提供的音素绑定过程图。
具体实施方式
下面将结合示意图和实施例对本发明进行更详细的描述。根据下列描述,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
并且,在下文中,如果本文所述的方法包括一系列步骤,则本文所呈现的这些步骤的顺序并非必须是可执行这些步骤的唯一顺序,且一些所述的步骤可被省略和/或一些本文未描述的其他步骤可被添加到该方法中。
如背景技术中所述的,目前使用的技术通常是设置一些vad参数来进行人机交互,但是这种方法普遍交互效果差,而且随着人群和环境的变化,不能动态自适应的调整条件参数,并且随着时间变长,交互效果会明显下降,此时只能通过人为的再次调整vad参数来适应新的变化。
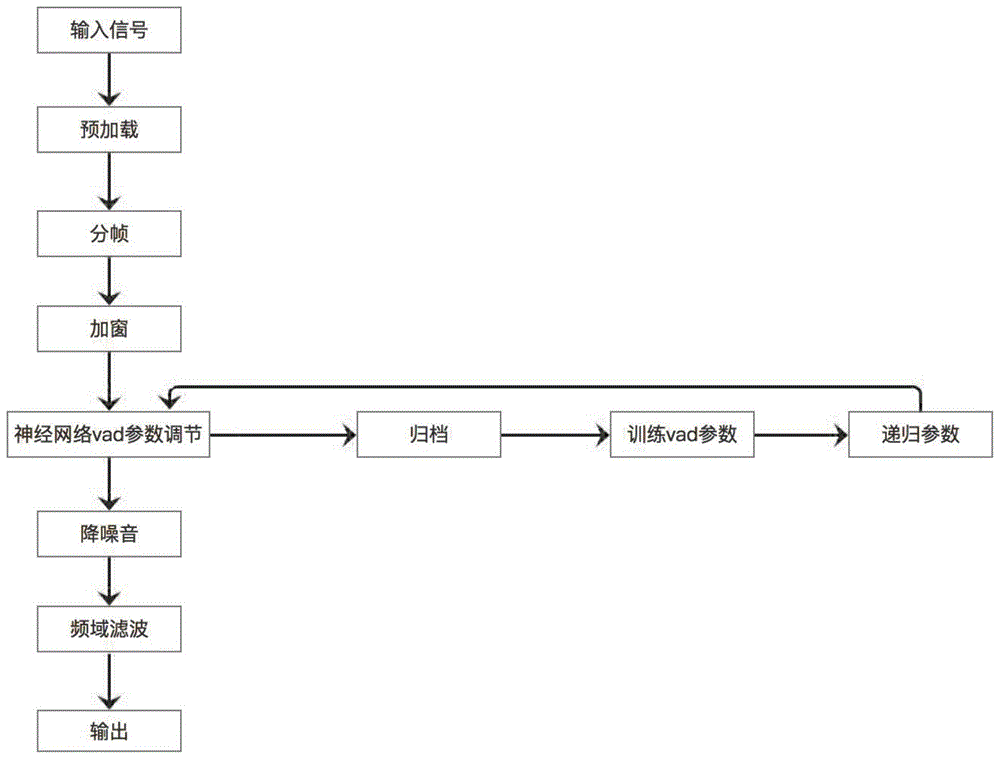
为了解决现有技术中存在的问题,本发明提供了一种基于神经网络vad算法的人机交互方法,如图1所示,图1为本发明实施例提供的人机交互方法的流程图,所述人机交互方法包括以下步骤:
对输入的音频信号进行预加载,保留有效的音频段,并对过高或者过低的音频段过滤掉;
对所述音频段进行数字化处理,并对所述数字化处理后的音频数字进行分帧和加窗操作;
把加窗操作后的音频数字作为新的样本放入样本集进行样本训练,采用神经网络和人机交互结果自动调整vad参数;
将调整好的vad参数运用于神经网络vad算法,采用神经网络vad算法读取加窗后的音频数字,以读取语音数据;
对读取到的语音数据进行降噪处理和频域滤波处理;
得到人机交互的输出结果。
其中,在一个实施例中,进行分帧和加窗操作方式如下:对所述音频段进行数字化处理,通过音频采样,进行分帧操作;并通过对声压大小和声波波形后音频数字进行判断,将所述音频数字切分为不同时间段,进行加窗操作。
本发明通过声压传输语音信号中的语音帧,在通信中区分语音和静默段,能够区分传输语音信号中的语音信号和背景噪音,并能够将语音信号转换为计算机能够处理的语音特征向量,然后通过神经网络训练的vad参数,对语音特征向量进行调节,增强语音信号,抑制非语音信号,为人机交互提供智能决策。
进一步的,自动调整vad参数的步骤如下:
加载神经网络提前训练得到的vad参数;
把加窗操作后的音频数字放入已有的样本集中;
在神经网络中,根据特征值将已有的样本集划分为不同节点,各节点对输入的新样本集进行后验概率向量降维;
将后验概率向量降维后的新样本集输入混合型神经网络中,混合型神经网络输出结果;
存储混合型神经网络的输出结果;
比较混合型神经网络的输出结果和人机交互的输出结果;
根据比较结果自动训练并调整vad参数。
再进一步的,请参考图2,图2为本发明实施例提供的训练并调整vad参数的示意图,图2中,其中w表示是词组;q表示是monophone(单音素);l表示是triphone(根据左右音素来确定的);p表示是聚类或者状态绑定之后的triphone。其中,音素绑定的方式如图3所示,图3为本发明实施例提供的音素绑定过程图。
可选的,在所述基于神经网络vad算法的人机交互方法中,所述混合型神经网络由深层神经网络和隐马尔科夫模型组成。
较佳的,在得到调整后的vad参数后,递归所述vad参数。
可选的,在所述基于神经网络vad算法的人机交互方法中,降噪处理的方式为:对读取到的带噪音的语音数据进行平滑处理,公式为:
进一步的,频域滤波处理的公式为:
综上,在本发明所提供的基于神经网络vad算法的人机交互方法中,通过神经网络把新的音频数字作为新的样本放入样本集进行训练,在大量通话和相同背景下,结合利用人机交互的输出结果纠正vad参数,从而不断优化vad参数,以不断优化人机交互质量。
上述实施例仅用于示例性地说明发明的原理及其功效,而非用于限制本发明。任何所属技术领域的技术人员,在不违背本发明的精神及范畴下,均可对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,而仍属于本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

