1.本发明属于语音数据隐私保护技术领域,具体涉及一种基于对抗样本的语音数据隐私保护方法。
背景技术:
2.深度学习技术已经应用到日常生活的各个方面,尤其是在语音识别、图片识别、目标检测等方面。但是随着深度学习技术的发展,其带来的隐私问题也受到了用户的不断关注。当用户进行私密谈话时,语音助手可能会偷偷记录下用户的谈话内容,并在未经用户允许的情况下将语音数据上传至服务器,这些私密的语音数据可能会被非法倒卖,或用于训练商业公司的人工智能模型。深度学习技术同样可以从泄露的语音数据中提取用户的私密信息,如:家庭住址、人际关系、个人喜好等,通过这些信息,商业公司就可以给用户推送相应的广告,或进行其他的商业活动。循环神经网络(rnn)在语音识别方面取得了很好的效果,它通过输入的音频信号得到字符的概率分布序列,再通过该概率分布序列推出音频信号所对应的句子,由百度公司研发的基于深度学习技术的deepspeech是当下主流的语音识别系统。
3.在大数据时代,越来越多的语音数据被发布,以用于改善基于语音的服务或学术研究。但在语音数据发布过程中存在着隐私泄露的风险。例如,在语音数据发布中,攻击者如果知道特定用户的语音数据,则可以通过分析语音数据来了解用户的敏感信息。
4.虽然深度学习技术已经取得了广泛的应用,但是越来越多的研究表明这项技术本身存在着许多安全隐患。goodfellow等人提出了快速梯度符号法(fgsm),这是一种针对深度学习模型的对抗样本生成算法,该方法通过在深度学习模型的输入上施加细微的扰动,使得深度学习模型产生错误的预测结果,这是目前主流的对抗样本生成算法之一。本发明提出了一种基于梯度、多次迭代的对抗样本生成方法,构建生成对抗样本的损失函数并进行迭代优化以生成人耳不可察觉的扰动,使得在隐私的语音数据上添加扰动后,用户的私密谈话内容能够被人听清,但是智能设备却无法识别、分析用户的说话内容,在将音频数据上传后也无法对其进行非法利用,以此保护用户的隐私语音数据。
技术实现要素:
5.本发明的主要目的在于提供一种基于对抗样本的语音数据隐私保护方法,其建立了生成对抗样本的损失函数,并设置一定的损失函数阈值,通过多次迭代的方法优化用户的音频数据以生成针对语音识别模型的对抗样本,使得在隐私的语音数据上添加扰动后,用户的私密谈话内容能够被人听清,听觉体验不会受到影响,但是智能设备却无法识别、分析用户的说话内容,在将音频数据上传后也无法对其进行非法利用,从而保护了用户的私密音频数据。
6.本发明的另一目的在于提供一种基于对抗样本的语音数据隐私保护方法,对于非线性程度较高的语音识别系统,一步迭代生成对抗样本的方式效果并不显著,本发明采取
建立生成对抗样本的损失函数,设定损失阈值,通过使用小步长并多次迭代的方法生成对抗样本,相比于采用大步长一步迭代的方法更为高效,同时利用对抗样本的可迁移性,即针对某一模型生成的对抗样本对于其他的模型同样有一定的效果,本发明可更加有效的防止音频数据遭到各种智能设备的窃取。
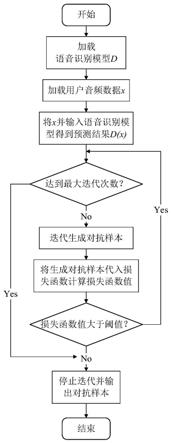
7.为达到以上目的,本发明提供一种基于对抗样本的语音数据隐私保护方法,用于保护用户的隐私语音数据,其特征在于,包括以下步骤:
8.步骤s1:加载语音识别模型d(例如deepspeech);
9.步骤s2:根据语音识别模型d对用户的音频数据x进行预检测,以获得概率分布矩阵d(x)的识别结果,其中:
10.d(x)表示音频数据x的每一帧对应于英文中26个字符的概率分布矩阵;
11.步骤s3:通过公式从概率分布矩阵d(x)中提取出音频数据x对应的字符序列s(x),并且字符序列s(x)为需要保护的用户的隐私语音数据,其中:
12.pr(s|d(x))表示语音识别模型d将语音数据x识别为字符序列s的概率,pr(s|d(x))的值在[0,1]之间;
[0013]
步骤s4:记y=s(x),初始化x0=x,i=0,设置阈值t、迭代步长ε、最大迭代轮数n,并且构建生成对抗样本的损失函数l(x
i
,y)=
‑
log(pr(s(x)|d(x
i
))),通过公式迭代生成语音对抗样本,每轮迭代后重新计算损失函数l(x
i
,y)的值,若l(x
i
,y)>t则继续迭代直到l(x
i
,y)≤t,若l(x
i
,y)≤t则停止迭代并输出x
i
,若当前迭代次数超过所设置的最大迭代轮数则停止迭代并输出x
i
。
[0014]
作为上述技术方案的进一步优选的技术方案,音频数据x是一个k维向量,向量的每一维是16位,代表16khz,采用mfc方法对音频数据x进行预处理。
[0015]
作为上述技术方案的进一步优选的技术方案,步骤s2中,使用0
‑
25这26个数字分别表示26个英文字符a
‑
z。
[0016]
作为上述技术方案的进一步优选的技术方案,步骤s3中,使用torch中的softmax函数将pr(s|d(x))的值映射在[0,1]之间。
[0017]
作为上述技术方案的进一步优选的技术方案,步骤s4中,阈值t设置为0.5,迭代步长ε设置为0.1,最大迭代轮数n设置为40。
[0018]
作为上述技术方案的进一步优选的技术方案,步骤s4中,在每一轮迭代中,在音频数据x上添加细微的扰动,该扰动使得音频数据x朝着使得损失函数l(x
i
,y)的值增大的方向移动,随着损失函数l(x
i
,y)的不断增大,语音识别模型d将音频数据x识别为y的概率会逐渐减小,直到将音频数据x误判。
[0019]
为达到以上目的,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现一种基于对抗样本的语音数据隐私保护方法的步骤。
[0020]
为达到以上目的,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现一种基于对抗样本的语音数据隐私保护方法的步骤。
附图说明
[0021]
图1是本发明的一种基于对抗样本的语音数据隐私保护方法的示意图。
具体实施方式
[0022]
以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。
[0023]
参见附图的图1,图1是本发明的一种基于对抗样本的语音数据隐私保护方法的示意图。
[0024]
在本发明的优选实施例中,本领域技术人员应注意,本发明所涉及的deepspeech、torch和softmax等可被视为现有技术。
[0025]
优选实施例。
[0026]
本发明公开了一种基于对抗样本的语音数据隐私保护方法,用于保护用户的隐私语音数据,包括以下步骤:
[0027]
步骤s1:加载语音识别模型d(例如deepspeech);
[0028]
步骤s2:根据语音识别模型d对用户的音频数据x进行预检测,以获得概率分布矩阵d(x)的识别结果,其中:
[0029]
d(x)表示音频数据x的每一帧对应于英文中26个字符的概率分布矩阵;
[0030]
步骤s3:通过公式从概率分布矩阵d(x)中提取出音频数据x对应的字符序列s(x),并且字符序列s(x)为需要保护的用户的隐私语音数据,其中:
[0031]
pr(s|d(x))表示语音识别模型d将语音数据x识别为字符序列s的概率,pr(s|d(x))的值在[0,1]之间;
[0032]
步骤s4:记y=s(x),初始化x0=x,i=0,设置阈值t、迭代步长ε、最大迭代轮数n,并且构建生成对抗样本的损失函数l(x
i
,y)=
‑
log(pr(s(x)|d(x
i
))),通过公式迭代生成语音对抗样本,每轮迭代后重新计算损失函数l(x
i
,y)的值,若l(x
i
,y)>t则继续迭代直到l(x
i
,y)≤t,若l(x
i
,y)≤t则停止迭代并输出x
i
,若当前迭代次数超过所设置的最大迭代轮数则停止迭代并输出x
i
。
[0033]
具体的是,音频数据x是一个k维向量,向量的每一维是16位,代表16khz,采用mfc方法对音频数据x进行预处理。
[0034]
更具体的是,步骤s2中,使用0
‑
25这26个数字分别表示26个英文字符a
‑
z。
[0035]
进一步的是,步骤s3中,使用torch中的softmax函数将pr(s|d(x))的值映射在[0,1]之间。
[0036]
更进一步的是,步骤s4中,阈值t设置为0.5,迭代步长ε设置为0.1,最大迭代轮数n设置为40,通过torch中的backward函数求解梯度。
[0037]
优选地,步骤s4中,在每一轮迭代中,在音频数据x上添加细微的扰动,该扰动使得音频数据x朝着使得损失函数l(x
i
,y)的值增大的方向移动,随着损失函数l(x
i
,y)的不断增大,语音识别模型d将音频数据x识别为y的概率会逐渐减小,直到将音频数据x误判。
[0038]
优选地,本方法使用基于梯度的方法,构建生成对抗样本的损失函数并进行迭代优化以生成人耳不可察觉的扰动,使得在隐私的语音数据上添加扰动后,用户的谈话体验不会受到影响,但是智能设备却无法识别用户的谈话内容,从而无法对用户的私密谈话内容进行分析以及进一步的非法利用,以此保护用户的隐私语音数据。相比于采用大步长一步迭代的对抗样本生成方法更为高效。同时利用对抗样本的的可迁移性,本发明可更加有效的防止用户语音遭到各种智能设备的窃取。
[0039]
本发明还公开了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现一种基于对抗样本的语音数据隐私保护方法的步骤。
[0040]
本发明还公开了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现一种基于对抗样本的语音数据隐私保护方法的步骤。
[0041]
值得一提的是,本发明专利申请涉及的deepspeech、torch和softmax等技术特征应被视为现有技术,这些技术特征的具体结构、工作原理以及可能涉及到的控制方式、空间布置方式采用本领域的常规选择即可,不应被视为本发明专利的发明点所在,本发明专利不做进一步具体展开详述。
[0042]
对于本领域的技术人员而言,依然可以对前述各实施例所记载的技术方案进行修改,或对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

