本发明属于单声道语音分离领域,尤其涉及一种基于时频跨域特征选择的语音分离方法。
背景技术:
语音分离技术是自然语言处理领域的一个分支,用于处理多说话人噪声环境下无法识别有效语音信息的问题。语音分离的目标是把目标语音从背景干扰中分离出来。
随着深度学习的发展,基于神经网络的许多新算法问世,深度聚类(dc)和置换不变性训练(pit)超越了传统方法。基于深度聚类和置换不变性训练,深度吸引网络(danet)通过使用吸引子机制来对每一个说话源做估计掩码的机制取得了空前的成功。和以幅度谱作为特征输入的语音分离网络不同,时域音频分离网络(tasnet)和全卷积时域音频分离网络(conv-tasnet)提出使用时域信号作为网络的输入,是目前表现最突出的模型。tasnet的核心思想是使用一维卷积抓取时域信号的特征来代替对于分离任务来说并不算最优做法的普通变换如短时傅里叶变换。通过端到端训练网络,得到了抓取时域信号特征的最佳卷积编码器。
基于这些直接使用时域信号特征的算法,有学者提出了对时域和频率域特征嵌入和聚类联合做法。在编码阶段,两个域的特征包括卷积提取的时域特征和经过傅里叶变换的幅度谱被并行地计算和在通道维度上拼接。这些特征经过分离网络,得到高维嵌入空间的输出,再经过吸引子机制为每个说话源产生掩码。在解码器部分,两个经过掩码不同域的特征图经过反卷积及反傅里叶变换得到处理后的语音信号。实验表明,将时域和频域特征拼接起来的性能优于仅使用时域特征的性能。
技术实现要素:
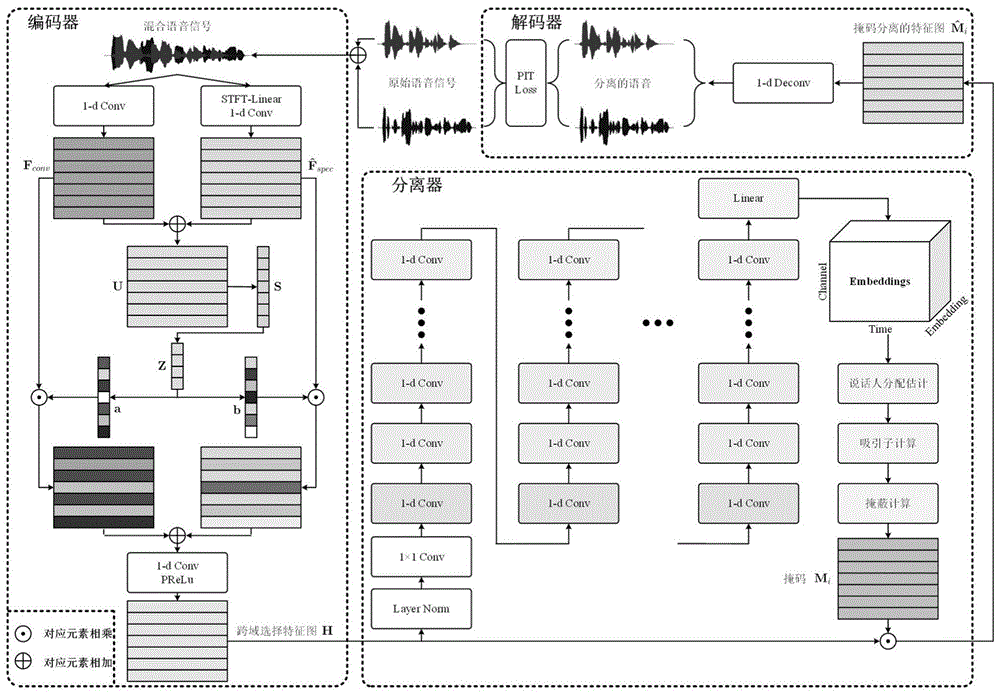
本发明针对现有技术的不足,提出了一种基于时频跨域特征选择的语音分离方法,该方法采用基于时频跨域特征选择的语音分离网络实现,所述基于时频跨域特征选择的语音分离网络主要包括特征编码器、语音分离器和解码器三个部分,所述特征编码器为语音时频域跨域特征编码器;
该方法包括以下步骤:
步骤1.通过单个录音设备对多个说话人的语音进行采样得到含有多个说话人语音的单声道语音,使用语音时频域跨域特征编码器中的一维卷积神经网络与短时傅里叶变换分别对所述单声道语音进行编码,得到使用一维卷积神经网络这种方式编码的特征图与使用短时傅里叶变换这种方式编码的特征图;
步骤2.将得到的使用一维卷积神经网络这种方式编码的特征图与使用短时傅里叶变换这种方式编码的特征图采用时频跨域特征选择方法进行跨域特征融合,得到跨域融合的特征图;
步骤3.根据跨域融合的特征图,采用语音分离器为单声道语音中的每个说话人计算一个掩码,并将掩码作用于跨域融合的特征图上,得到单声道语音中每个说话人的分离特征图;
步骤4.基于单声道语音中每个说话人的分离特征图,采用解码器中的一个一维转置卷积神经网络进行语音信号重构,最终得到单声道语音中每个说话人的语音。
进一步地,所述步骤1中使用语音时频域跨域特征编码器中的一维卷积神经网络与短时傅里叶变换分别对所述单声道语音进行编码的具体过程包括如下步骤:
步骤1-1:使用语音时频域跨域特征编码器中的一维卷积神经网络1对所述单声道语音进行计算得到时域特征图,作为使用一维卷积神经网络这种方式编码的特征图;
步骤1-2:使用语音时频域跨域特征编码器中的短时傅里叶变换对所述单声道语音进行计算得到幅度谱作为时频域特征图;
步骤1-3:使用语音时频域跨域特征编码器中的全连接网络1将时频域特征图线性变换到与时域特征图同一特征维度,得到变换后的时频域特征图,并使用语音时频域跨域特征编码器中的一个一维卷积神经网络2对变换后的时频域特征图进行非线性变换,得到非线性变换后的时频域特征图,将非线性变换后的时频域特征图作为使用短时傅里叶变换这种方式编码的特征图;
其中,一维卷积神经网络1与一维卷积神经网络2的输入输出通道数不相同。
进一步地,所述步骤2中进行跨域特征融合的具体过程包括如下步骤:
步骤2-1:将非线性变换后的时频域特征图与时域特征图进行对应元素相加,得到加和特征图;
步骤2-2:基于加和特征图,采用全局池化,沿着时间维度对每个特征通道进行均值计算,得到一个全局特征描述子,该全局特征描述子的通道数与加和特征图的通道数相同;
步骤2-3:采用语音时频域跨域特征编码器中的全连接网络2对步骤2-2中得到的全局特征描述子进行压缩,降低其特征维度,得到一个压缩特征描述子;
步骤2-4:使用语音时频域跨域特征编码器中的全连接网络3和全连接网络4分别对压缩特征描述子进行扩张,还原到全局特征描述子的特征维度,分别得到时域特征描述子和时频域特征描述子,其中,全连接网络3和全连接网络4这两个全连接网络的参数数量相同,但参数的值不相同;
步骤2-5:将时域特征描述子按对应元素相乘的形式乘到时域特征图上,并将时频域特征描述子按对应元素相乘的形式乘到非线性变换后的时频域特征图上,完成跨域特征选择,得到跨域特征选择后的两个特征图,最后再将跨域特征选择后的两个特征图按对应元素进行相加,完成跨域特征融合,得到跨域融合的特征图。
进一步的,所述步骤3具体包括如下步骤:
步骤3-1:采用语音分离器中的一个堆叠的卷积神经网络,对跨域融合的特征图进行进一步的特征提取,得到变换后的跨域融合特征图;
步骤3-2:采用语音分离器中的全连接网络5将变换后的跨域融合特征图进行升维,将其变换为时间、特征与嵌入三个维度的张量;
步骤3-3:基于变换得到的时间、特征与嵌入三个维度的张量,采用吸引子机制计算单声道语音中每个说话人的掩码;
步骤3-4:将单声道语音中每个说话人的掩码以对应元素相乘的形式分别与步骤2-5中得到的跨域融合的特征图相乘,得到单声道语音中每个说话人的分离特征图。
进一步地,所述步骤4中进行语音信号重构具体为:
采用解码器中的一个一维转置卷积神经网络,将单声道语音中每个说话人的分离特征图转化为对应说话人的语音信号,完成语音分离。
全连接网络1-5的结构以及参数值都不相同。
本发明主要将语音分离中的特征选择经过跨域混合,时域和频率域特征相互补充,在多说话人噪声环境下也能准确捕捉语音的特征信号,克服了业界内对于时域以及时频域特征利用不充分的问题,构建了一种新型的特征编码器,能够有效提取语音的有效信息。经过堆叠的卷积神经网络提取语音信号高维特征,并通过吸引子网络深度聚类构建说话人语音信号集群,自适应过滤非对应说话人的语音信号,提升了模型的鲁棒性,克服了以往在不平稳噪声环境下分离不佳的问题。
附图说明
图1为基于时频跨域特征选择的语音分离网络的整体结构示意图。
具体实施方式
下面将结合附图对本发明实施例中的技术方案进行清楚、完整地描述。
本发明提出了一种基于时频跨域特征选择的语音分离方法,主要用于多说话人环境下的语音分离问题,能够有效混合时频域特征。
如图1所示,本发明采用基于时频跨域特征选择的语音分离网络实现,所述基于时频跨域特征选择的语音分离网络主要包括特征编码器、语音分离器和解码器三个部分。
特征编码器采用的是一种语音时频域跨域特征编码器,该语音时频域跨域特征编码器分别通过一维卷积神经网络1与短时傅里叶变换提取含有多个说话人语音的单声道语音的时域特征图和时频域特征图,时域特征图作为使用一维卷积神经网络这种方式编码的特征图;使用语音时频域跨域特征编码器中的全连接网络1将时频域特征图线性变换到与时域特征图同一特征维度,得到变换后的时频域特征图,并使用语音时频域跨域特征编码器中的一个一维卷积神经网络2对变换后的时频域特征图进行非线性变换,得到非线性变换后的时频域特征图,将非线性变换后的时频域特征图作为使用短时傅里叶变换这种方式编码的特征图;将非线性变换后的时频域特征图与时域特征图进行对应位置元素相加,得到加和特征图;加和特征图经过全局池化以及三个全连接网络(全连接网络2、全连接网络3和全连接网络4)的压缩与还原后得到时域特征描述子与时频域特征描述子,将时域特征描述子按对应元素相乘的形式乘到时域特征图上,并将时频域特征描述子按对应元素相乘的形式乘到非线性变换后的时频域特征图上,得到跨域特征选择后的两个特征图,最后再将跨域特征选择后的两个特征图按对应元素进行相加,得到跨域融合的特征图。
给出包括n个说话人的混合语音信号(即含有n个说话人语音的单声道语音)x,n为大于1的正整数,x通过短时傅里叶变换得到时频域特征图,同时,x通过一维卷积神经网络1的一维卷积操作得到时域特征图,公式如下所示:
fspec=s(x),fconv=f(x)
其中s(·)表示短时傅里叶变换操作,f(·)表示一维卷积操作,fspec表示使用短时傅里叶变换得到的时频域特征图,fconv表示使用一维卷积神经网络编码得到的时域特征图。
之后fspec先通过一个全连接网络1进行线性变换,将时频域特征图线性变换到与时域特征图同一特征维度,得到变换后的时频域特征图;然后再使用一个卷积核大小为3的一维卷积神经网络2对变换后的时频域特征图进行非线性变换,将变换后的时频域特征图编码转换到与时域特征相同的潜在表示空间,得到非线性变换后的时频域特征图
其中,一维卷积神经网络1与一维卷积神经网络2的输入输出通道数不相同。
将非线性变换后的时频域特征图
其中,
通过对加和特征图进行全局池化得到全局特征描述子
通过一个全连接网络2压缩全局特征描述子
z=δ(n(wg))
再使用两个全连接层(全连接网络3和全连接网络4)将压缩特征描述子进行特征维度还原,分别得到时域特征描述子
aj表示时域特征描述子a位于时域特征图中第j个通道的特征选择值,bj表示时频域特征描述子b位于非线性变换后的时频域特征图
其中
跨域融合的特征图(即跨域选择特征图)h通过以下公式计算:
其中⊙代表对应元素相乘操作。
语音分离器通过一个堆叠的卷积神经网络对跨域融合的特征图进行进一步的特征提取,得到变换后的跨域融合特征图,采用一个全连接网络5对变换后的跨域融合特征图提取高维跨域融合特征(即时间、特征与嵌入三个维度的张量),基于高维跨域融合特征,通过吸引子机制得到单声道语音中每个说话人的掩码,并将每个说话人的掩码分别与跨域融合的特征图按对应元素相乘,得到单声道语音中每个说话人的分离特征图。
通过由8-32个一维卷积神经网络堆叠而成的堆叠的卷积神经网络对跨域融合的特征图h进行进一步的特征提取,得到变换后的跨域融合特征图,并采用一个全连接网络5将变换后的跨域融合特征图映射到高维空间,由以下公式表示:
v=wembts(h)
其中
之后,基于吸引子机制得到单声道语音中每个说话人的掩码,其中mi表示由语音分离器得到的第i个说话人的掩码,i=1,2,…,n,将每个说话人的掩码分别与跨域融合的特征图h进行对应元素相乘得到
解码器使用一个一维转置卷积神经网络来重构语音信号,将单声道语音中每个说话人的分离特征图转化为对应说话人的语音信号,完成语音分离。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

