本发明属于翻译设备技术领域,尤其涉及一种英语翻译的语音比照系统。
背景技术:
在英语的学习过程中,经常会采用英汉翻译工具进行辅助学习,达到提高学习效率的成果,但是对于现有的翻译设备,缺乏系统的控制,导致英汉翻译的质量参差不齐,甚至出现大的偏差,翻译精准度较低、准确性较差、召回率低。
现有的英汉翻译设备在进行翻译时,缺少系统的比照,导致出现错误的翻译概率增加,尤其是在进行语音翻译时,由于说话时常常带着地方口音,对语音识别的正确率也有很大的影响。
中国专利申请号201520599690.7公开了一种教学用英汉翻译设备,包括文字识别模块,所述文字识别模块与信息输入模块电连接,所述信息输入模块分别与键盘、信息存储单元和英汉识别模块电连接,所述信息存储单元与处理器电连接,所述英汉识别模块与英汉翻译模块电连接,所述英汉翻译模块还与处理器电连接,所述处理器分别与定时器、时钟、显示模块、信息存储模块和信息读取模块电连接;上述技术方案仅依靠处理器单纯的进行数据处理,缺少翻译数据的对比分析,导致翻译精准度较低;同时不能适用于语音翻译。
技术实现要素:
针对现有技术不足,本发明的目的在于提供了一种英语翻译的语音比照系统,通过设置语音识别系统,能够随时进行语音翻译工作,通过对翻译语音进行语义向量之间的翻译相似度进行对比,大大提高了翻译精准度、准确性和召回率;同时通过参数特征提取进行解析和处理,减少其他噪音污染,增加翻译语音的纯净度,减少语音翻译的错误率,从而提高翻译效率和准确率。
本发明提供如下技术方案:
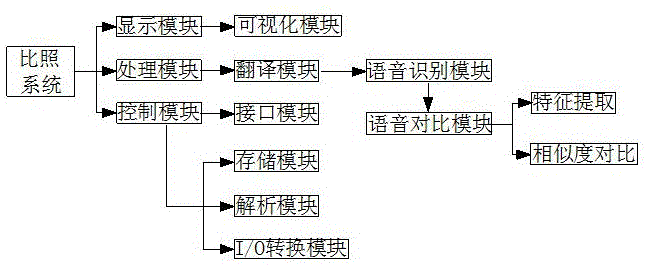
一种英语翻译的语音比照系统;包括显示模块、处理模块、控制模块;所述显示模块、处理模块、控制模块均与单片机连接控制;所述显示模块包括可视化模块,所述可视化模块为显示屏;所述处理模块包括翻译模块,翻译模块包括语音识别模块,所述语音识别包括语音对比模块,所述语音对比模块采用参数特征提取和相似度对比识别翻译语音的准确度;所述控制模块包括接口模块,接口模块采用串行通信模式通信;
所述语音识别模块包括语音参数库的提取和语音识别两个过程,语音参数库提取的过程为,首先将原始的的样本语音依次经过预加重、分帧加窗,之后对其进行端点检测处理,然后对其进行提组合参数,之后对前一次输入的样本语音进行迭代修正,直到经过翻译的样本语音迭代完毕,提供纯净的供语音识别模块使用的参数库。
优选的,所述控制模块还包括存储模块、解析模块、i/o转换模块;所述存储模块对翻译语音样本数据进行存储,所述解析模块用于处理翻译过程中的语音数据;所述i/o转换模块对翻译语音数据进行数字信号和模拟信号的相互转化。
优选的,所述语音识别的过程为,将翻译之后的语音样本首先经过预加重、分帧加窗,完成翻译之后语音的预加重和分帧加窗,之后进行端点测试,再进行参数特征提取,之后根据语音识别算法将形成的参数库码本和的到的参数数据建立匹配规则,找出最佳匹配对象,得到翻译之后语音和原始语音的识别结果。
优选的,所述参数特征提取方法包括以下步骤:
s1:对语音波进行加窗分帧处理得到各帧的语音片段;
s2:分别对各帧语音片段进行提取能量倒谱系数,首先对各帧语音片段用滤波器组队短时各帧语音片段进行滤波,滤波器的中心频率按照erb频率尺度均匀排列;
s3:计算每一个滤波器中心所在的频带的均值。
优选的,所述参数特征提取方法还包括步骤s4:将每个滤波器频带的均值变换到倒谱域中,之后对其进行离散余弦反变换,得到各帧的语音片段能量倒谱系数,存储模块对语音片段能量倒谱系数、滤波器中心所在的频带的均值进行存储。
优选的,控制模块对提取的参数特征进行解析,包括a,建立数据库;b,对新数据集分层处理;c,得出新参数结果。
优选的,一种英语翻译的语音比照系统的比照方法,包括以下步骤:a1,预处理翻译语音数据库,提取翻译端语义向量和被译端语义向量;
a2,根据语义向量映射模型,实现翻译端到被译端的语义空间映射;
a3,根据翻译相似度对比得出统一环境下不同语义向量的相似度;
a4,选择翻译相似度作为特征向量,并将其进行翻译解码获取翻译对比结果。
优选的,语音识别模块的语音识别的方法为,步骤1,初始化待测语音的起点与终点,以及翻译端语音信号的起点和初始最小失真测度;步骤2,根据约束条件,计算截止到被译端语音信号和翻译端语音信号匹配点的最小失真测度;步骤3,递推求出所有匹配点后计算被译端语音与翻译端语音之间的最小失真测度,依次循环语音参数库,找出距离最小是测度所对应的语音,即得到精确的语音比对识别结果。
优选的,控制模块对提取的参数特征进行解析过程为,a建立数据库,根据翻译端语义向量的数据特征信号分层,对每一层利用聚类算法找出每一层的聚类中心,得出较少的语义向量类型集合,在对每一小类进行分类器训练,就能提取比较好的分类和训练结果;b对新数据集进行分层,对于新的数据集首先通过聚类计算出其每一簇的数据中心,然后再与a中建立的数据库的每一层聚类中心求取欧氏距离,再把新的数据集的每个聚类中心的距离相加;距离和最小的归为一类,对新数据实现分层;c,得出新的语义向量结果,b中的数据到了某一层后用a的方法判断其属于更小的集合一直到最底层,再将已经训练好的分类器进行语义向量相似度对比。语义向量相似度对比时,采用余弦相似度函数度量统一翻译环境下翻译端语义向量u和被译端语义向量v之间的相似度s,相似度s满足:s=cosθ=(uv)/(||u||·||v||);若翻译端语义向量u和被译端语义向量v的相似度越高,则s的值越接近竖直1,则两个语义向量越接近。
另外,在语音识别的过程中,需要对翻译端原始语音进行处理,由于受到口鼻辐射影响,语音波频谱中高频部分功率谱幅值大量跌落,直接进行处理的话语音波信号较弱,会影响语音识别的精确性,导致错误率升高,所以,要对语音波信号进行预加重,预加重采用一个一阶高通滤波器,满足滤波器系统函数h=1-mz-1;上式中h为频率,m为调节关系,取值范围为0.9-0.999;z为幅值为零的位置;在对语音波进行分帧加窗时,由于语音波矩阵窗的频谱平滑,主瓣宽度铰窄,旁瓣高度较高,容易产生语音波泄漏;使用汉明窗主瓣宽度铰宽,旁瓣高度较低,具有良好的通特性,有效克服语音波泄漏现象,增加语音识别的准确性。
在进行语音波端点检测时,语音与噪声最大的区别在于噪声频域频带之间变化平缓,语音波频谱各段变化比较激烈,所以基于频带方差进行端点检测,包括以下步骤,(1),对分帧加窗后的语音波进行短时傅里叶变换,求得各帧语音的傅里叶值x,x={x(w0),x(w1),…,x(wn)};(2),计算各帧语音的均值e满足下列公式,e=(x(wn) …x(w1))/(n 1);(3),计算其对应的频带方差d满足下列公式:d=((x(wn)-e)2 … (x(w1)-e)2)/(n 1),对频带方差取对数;(4),根据无声段设置检测门限m,m=λ·d,λ为调整系数,取值范围为2.8-3.5;检测过程中将高于检测门限m的声音帧段做为声音端点;系统能够从语音波中分割真正的翻译语音片段作为识别对象,节省参数特征语音识别的时间,提高语音翻译效率。
与现有技术相比,本发明具有以下有益效果:
(1)本发明一种英语翻译的语音比照系统,通过设置语音识别系统,能够随时进行语音翻译工作,通过对翻译语音进行语义向量之间的翻译相似度进行对比,大大提高了翻译精准度、准确性和召回率。
(2)本发明一种英语翻译的语音比照系统,同时通过参数特征提取进行解析和处理,减少其他噪音污染,增加翻译语音的纯净度,减少语音翻译的错误率,从而提高翻译效率和准确率。
(3)本发明一种英语翻译的语音比照系统,对语音波进行预加重的过程中,通过限定频率、幅值为零的位置之间的关系,进一步增加语音识别的精确性,降低语音识别的错误率。
(4)本发明一种英语翻译的语音比照系统,在对语音波进行分帧加窗时,由于语音波矩阵窗的频谱平滑,主瓣宽度铰窄,旁瓣高度较高,容易产生语音波泄漏;使用汉明窗主瓣宽度铰宽,旁瓣高度较低,具有良好的通特性,有效克服语音波泄漏现象,增加语音识别的准确性。
(5)本发明一种英语翻译的语音比照系统,检测过程中将高于检测门限m的声音帧段做为声音端点;系统能够从语音波中分割真正的翻译语音片段作为识别对象,节省参数特征语音识别的时间,提高语音翻译效率。
(6)本发明一种英语翻译的语音比照系统,通过对提取的参数特征进行解析,解析之后得到的语义向量相似度对比,提升被译端和翻译端语义向量的准确性,从而进一步提升比照系统的精确程度。
附图说明
为了更清楚地说明本发明实施方式的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1是本发明的系统框架结构图。
图2是本发明的语音识别模块框架图。
图3是本发明的语音识别参数库训练流程图。
图4是本发明的语音识别的流程图。
图5是本发明的语音比照方法流程图。
具体实施方式
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述。显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
因此,以下对在附图中提供的本发明的实施方式的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
实施例一:
如图1所示,一种英语翻译的语音比照系统;包括显示模块、处理模块、控制模块;所述显示模块、处理模块、控制模块均与单片机连接控制;所述显示模块包括可视化模块,所述可视化模块为显示屏;所述处理模块包括翻译模块,翻译模块包括语音识别模块,所述语音识别包括语音对比模块,所述语音对比模块采用参数特征提取和相似度对比识别翻译语音的准确度;所述控制模块包括接口模块,接口模块采用串行通信模式通信;
所述语音识别模块包括语音参数库的提取和语音识别两个过程,语音参数库提取的过程为,首先将原始的的样本语音依次经过预加重、分帧加窗,之后对其进行端点检测处理,然后对其进行提组合参数,之后对前一次输入的样本语音进行迭代修正,直到经过翻译的样本语音迭代完毕,提供纯净的供语音识别模块使用的参数库。
所述控制模块还包括存储模块、解析模块、i/o转换模块;所述存储模块对翻译语音样本数据进行存储,所述解析模块用于处理翻译过程中的语音数据;所述i/o转换模块对翻译语音数据进行数字信号和模拟信号的相互转化。
实施例二:
如图2-4所示,在实施例一的基础上,所述语音识别的过程为,将翻译之后的语音样本首先经过预加重、分帧加窗,完成翻译之后语音的预加重和分帧加窗,之后进行端点测试,再进行参数特征提取,之后根据语音识别算法将形成的参数库码本和的到的参数数据建立匹配规则,找出最佳匹配对象,得到翻译之后语音和原始语音的识别结果。
所述参数特征提取方法包括以下步骤:
s1:对语音波进行加窗分帧处理得到各帧的语音片段;
s2:分别对各帧语音片段进行提取能量倒谱系数,首先对各帧语音片段用滤波器组队短时各帧语音片段进行滤波,滤波器的中心频率按照erb频率尺度均匀排列;
s3:计算每一个滤波器中心所在的频带的均值。
所述参数特征提取方法还包括步骤s4:将每个滤波器频带的均值变换到倒谱域中,之后对其进行离散余弦反变换,得到各帧的语音片段能量倒谱系数,存储模块对语音片段能量倒谱系数、滤波器中心所在的频带的均值进行存储。
控制模块对提取的参数特征进行解析,包括a,建立数据库;b,对新数据集分层处理;c,得出新参数结果。
语音识别模块的语音识别的方法为,步骤1,初始化待测语音的起点与终点,以及翻译端语音信号的起点和初始最小失真测度;步骤2,根据约束条件,计算截止到被译端语音信号和翻译端语音信号匹配点的最小失真测度;步骤3,递推求出所有匹配点后计算被译端语音与翻译端语音之间的最小失真测度,依次循环语音参数库,找出距离最小是测度所对应的语音,即得到精确的语音比对识别结果。
控制模块对提取的参数特征进行解析过程为,a建立数据库,根据翻译端语义向量的数据特征信号分层,对每一层利用聚类算法找出每一层的聚类中心,得出较少的语义向量类型集合,在对每一小类进行分类器训练,就能提取比较好的分类和训练结果;b对新数据集进行分层,对于新的数据集首先通过聚类计算出其每一簇的数据中心,然后再与a中建立的数据库的每一层聚类中心求取欧氏距离,再把新的数据集的每个聚类中心的距离相加;距离和最小的归为一类,对新数据实现分层;c,得出新的语义向量结果,b中的数据到了某一层后用a的方法判断其属于更小的集合一直到最底层,再将已经训练好的分类器进行语义向量相似度对比。语义向量相似度对比时,采用余弦相似度函数度量统一翻译环境下翻译端语义向量u和被译端语义向量v之间的相似度s,相似度s满足:s=cosθ=(uv)/(||u||·||v||);若翻译端语义向量u和被译端语义向量v的相似度越高,则s的值越接近竖直1,则两个语义向量越接近。
实施例三:
如图5所示,一种英语翻译的语音比照系统;包括显示模块、处理模块、控制模块;所述显示模块、处理模块、控制模块均与单片机连接控制;所述显示模块包括可视化模块,所述可视化模块为显示屏;所述处理模块包括翻译模块,翻译模块包括语音识别模块,所述语音识别包括语音对比模块,所述语音对比模块采用参数特征提取和相似度对比识别翻译语音的准确度;所述控制模块包括接口模块,接口模块采用串行通信模式通信;
所述语音识别模块包括语音参数库的提取和语音识别两个过程,语音参数库提取的过程为,首先将原始的的样本语音依次经过预加重、分帧加窗,之后对其进行端点检测处理,然后对其进行提组合参数,之后对前一次输入的样本语音进行迭代修正,直到经过翻译的样本语音迭代完毕,提供纯净的供语音识别模块使用的参数库。
所述控制模块还包括存储模块、解析模块、i/o转换模块;所述存储模块对翻译语音样本数据进行存储,所述解析模块用于处理翻译过程中的语音数据;所述i/o转换模块对翻译语音数据进行数字信号和模拟信号的相互转化。
一种英语翻译的语音比照系统的比照方法,包括以下步骤:a1,预处理翻译语音数据库,提取翻译端语义向量和被译端语义向量;
a2,根据语义向量映射模型,实现翻译端到被译端的语义空间映射;
a3,根据翻译相似度对比得出统一环境下不同语义向量的相似度;
a4,选择翻译相似度作为特征向量,并将其进行翻译解码获取翻译对比结果。
实施例四:
在实施例一的基础上,所述语音识别模块包括语音参数库的提取和语音识别两个过程,语音参数库提取的过程为,首先将原始的的样本语音依次经过预加重、分帧加窗,之后对其进行端点检测处理,然后对其进行提组合参数,之后对前一次输入的样本语音进行迭代修正,直到经过翻译的样本语音迭代完毕,提供纯净的供语音识别模块使用的参数库;在语音识别的过程中,需要对翻译端原始语音进行处理,由于受到口鼻辐射影响,语音波频谱中高频部分功率谱幅值大量跌落,直接进行处理的话语音波信号较弱,会影响语音识别的精确性,导致错误率升高,所以,要对语音波信号进行预加重,预加重采用一个一阶高通滤波器,满足滤波器系统函数h=1-mz-1;上式中h为频率,m为调节关系,取值范围为0.9-0.999;z为幅值为零的位置;在对语音波进行分帧加窗时,由于语音波矩阵窗的频谱平滑,主瓣宽度铰窄,旁瓣高度较高,容易产生语音波泄漏;使用汉明窗主瓣宽度铰宽,旁瓣高度较低,具有良好的通特性,有效克服语音波泄漏现象,增加语音识别的准确性。
在进行语音波端点检测时,语音与噪声最大的区别在于噪声频域频带之间变化平缓,语音波频谱各段变化比较激烈,所以基于频带方差进行端点检测,包括以下步骤,(1),对分帧加窗后的语音波进行短时傅里叶变换,求得各帧语音的傅里叶值x,x={x(w0),x(w1),…,x(wn)};(2),计算各帧语音的均值e满足下列公式,e=(x(wn) …x(w1))/(n 1);(3),计算其对应的频带方差d满足下列公式:d=((x(wn)-e)2 … (x(w1)-e)2)/(n 1),对频带方差取对数;(4),根据无声段设置检测门限m,m=λ·d,λ为调整系数,取值范围为2.8-3.5;检测过程中将高于检测门限m的声音帧段做为声音端点;系统能够从语音波中分割真正的翻译语音片段作为识别对象,节省参数特征语音识别的时间,提高语音翻译效率。
通过上述技术方案得到的装置是一种英语翻译的语音比照系统,通过设置语音识别系统,能够随时进行语音翻译工作,通过对翻译语音进行语义向量之间的翻译相似度进行对比,大大提高了翻译精准度、准确性和召回率;同时通过参数特征提取进行解析和处理,减少其他噪音污染,增加翻译语音的纯净度,减少语音翻译的错误率,从而提高翻译效率和准确率;对语音波进行预加重的过程中,通过限定频率、幅值为零的位置之间的关系,进一步增加语音识别的精确性,降低语音识别的错误率;在对语音波进行分帧加窗时,由于语音波矩阵窗的频谱平滑,主瓣宽度铰窄,旁瓣高度较高,容易产生语音波泄漏;使用汉明窗主瓣宽度铰宽,旁瓣高度较低,具有良好的通特性,有效克服语音波泄漏现象,增加语音识别的准确性;检测过程中将高于检测门限m的声音帧段做为声音端点;系统能够从语音波中分割真正的翻译语音片段作为识别对象,节省参数特征语音识别的时间,提高语音翻译效率;通过对提取的参数特征进行解析,解析之后得到的语义向量相似度对比,提升被译端和翻译端语义向量的准确性,从而进一步提升比照系统的精确程度。
本发明中未详细阐述的其它技术方案均为本领域的现有技术,在此不再赘述。
以上所述仅为本发明的优选实施方式而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化;凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

