本发明涉及民用航空空中交通管理领域,特别是一种陆空通话说话人身份识别方法及装置。
背景技术:
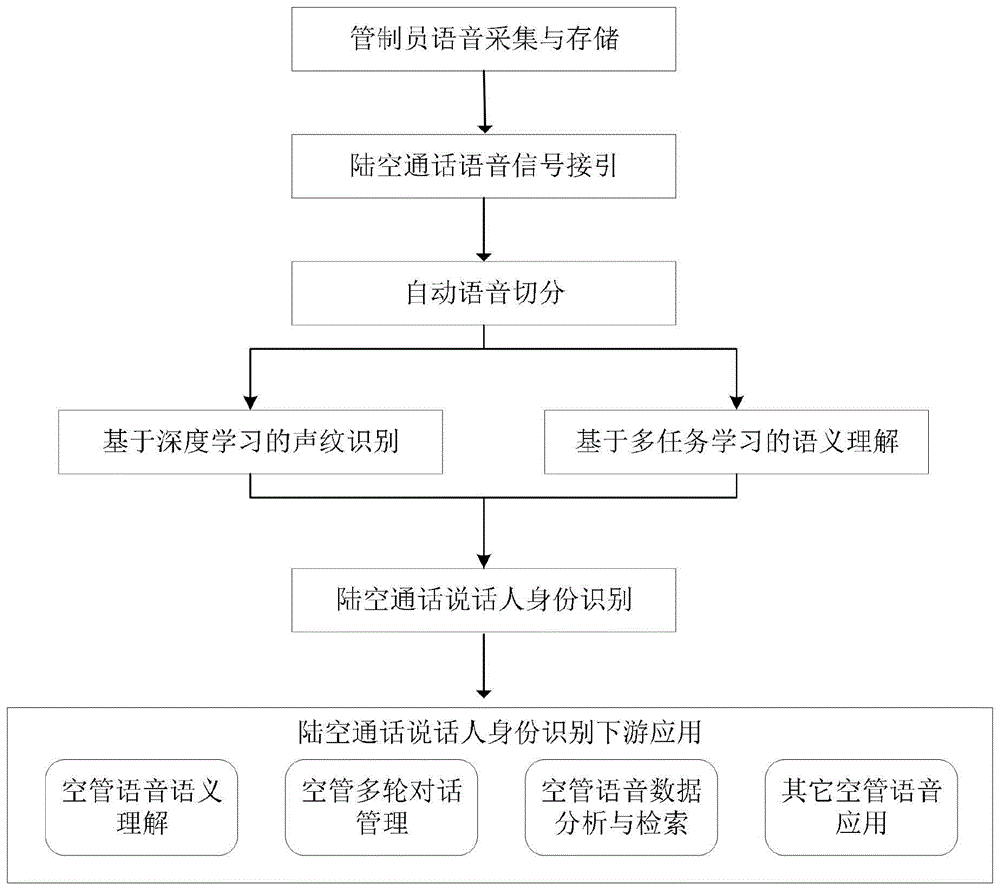
:目前,我国空中交通管理主要是以“人”为主导的管制方式,依靠无线电通话和飞行态势信息实现飞行器的调配,而机器尚不具备直接获取说话人身份信息的手段。同时由于陆空通话为“多人”、“多轮”对话的沟通模式,说话人身份信息的缺失将会导致无法建立当前管制通话与上下文的有机关联,给管制意图理解、多轮对话管理带来了极大的困难,大幅度降低了空管语音安全防护的性能与效率。所以如今需要一种陆空通话说话人身份识别方法及装置来解决陆空通话说话人身份识别的难题,从而提高空管语音安全防护的性能与效率。技术实现要素:本发明的目的在于克服现有技术中存在不能即时自动获取陆空通话中的说话人身份,提供一种陆空通话说话人身份识别方法及装置。为了实现上述发明目的,本发明提供了以下技术方案:一种陆空通话说话人身份识别方法,包括以下步骤:s1:采集管制单位的管制员的语音数据,获取所述管制员的说话人声纹嵌入码,构建包括管制员静态声纹库以及飞行员动态声纹库的声纹数据库,并在所述管制员静态声纹库中对所有所述管制员进行声纹注册;s2:实时采集陆空通话语音信号,对所述陆空通话语音信号进行切分,获取单句语音信号;对所述单句语音信号进行预处理后存入存储设备;s3:将所述单句语音信号输入到陆空通话语义理解模型,提取并输出所述单句语音信号对应的说话人角色和航班号;所述说话人角色包括管制员和飞行员;s4:将所述单句语音信号输入到说话人声纹嵌入码提取模型,获取所述单句语音信号的说话人声纹嵌入码;并将所述说话人声纹嵌入码输入说话人判决模型,在所述声纹数据库中进行匹配,并输出所述单句语音信号的匹配结果;s5:根据所述步骤s3语义理解和所述步骤s4声纹匹配的结果,若所述声纹库有匹配结果,输出说话人身份;若所述声纹库无匹配结果,对所述说话人声纹嵌入码进行声纹注册,并输出说话人身份。本发明基于深度神经网络的声纹识别和语义理解技术,来对陆空通话中的说话人进行身份识别,解决陆空通话中开放环境下“多人”、“多轮”对话中的说话人身份识别问题,建立管制通话上下文的关联,提高机器智能对管制通话的理解能力,为空管安全防护、管制数据分析等应用提供可靠的说话人身份信息,从而提升管制安全系数。此外,本发明还可应用于其它陆空通话下游应用。在事故征候分析场景下,本发明可以实现语音信息的快速检索,精准定位各说话人的通话语音;在管制工作质量评价场景下,本发明可以结合语音识别、大数据等技术,实现管制工作量的精准统计与管制习惯的分析,从而对管制员展开针对性的培训,提高管制效率与安全系数。作为本发明的优选方案,所述步骤s3和所述步骤s4顺序能交换。作为本发明的优选方案,所述管制员的声纹注册内容包括所述管制员的所述说话人声纹嵌入码和背景信息,其中,所述背景信息包括管制员id、性别、年龄、籍贯中的一种或多种;所述飞行员的声纹注册内容包括所述飞行员的所述说话人声纹嵌入码和飞行员id,其中,所述飞行员id为对应的航班号。作为本发明的优选方案,所述步骤s1中所述管制员的所述语音数据满足以下要求:(1)所述语音数据包括识别场景中使用的语种;(2)所述语音数据包括多种发音状态下的语音;所述发音状态包括一般语速、快语速、慢语速、不稳定语速、缓和情绪、紧张情绪中的一种或多种;其中,不稳定语速为语速不定的发音状态,缓和情绪为语调平稳时的发音状态,紧张情绪为语调升高时的发音状态;(3)所述语音数据包括与所述管制员相对应的管制用语。本发明通过录入各个识别场景下、多种发音状态下以及多语种的陆空通话数据,大大的提升了身份识别的准确率,避免了样本过少导致的识别不准的问题。作为本发明的优选方案,所述步骤s2中通过语音帧分类器将所述陆空通话连续语音信号中的音频信号帧分为起始帧、语音帧、非语音帧和结束帧四类,并将起始帧与后一个相邻的结束帧之间的语音帧输出为单句语音信号;所述语音帧为包含语音信息的信号部分,所述非语音帧为未包含语音信息的信号部分,所述起始帧和所述结束帧分别为未包含语音信息的信号部分向包含语音信息的信号部分过渡的音频帧和包含语音信息的信号部分向未包含语音信息的信号部分过渡的音频帧。作为本发明的优选方案,所述语音帧分类器包括卷积模块、循环神经网络模块以及输出模块;所述卷积模块包括一维卷积层、最大池化层、归一化层和剪枝层,用于抽取所述陆空通话语音信号中的起始帧、语音帧、非语音帧和结束帧以及不稳定的噪声的局部特征,增加网络的鲁棒性;所述循环神经网络采用门限循环神经网络,用于捕捉帧内信息短时变化的依赖关系;所述输出模块包括4个神经元的全连接层组成,用于输出四类语音帧的概率分布。作为本发明的优选方案,所述步骤s3包括:s31:通过陆空通话语音识别模型识别出所述单句语音信号中包含的文本信息;s32:构建基于多任务学习的陆空通话语义理解模型;s33:通过标注好的陆空通话文本数据训练所述陆空通话语义理解模型直至网络收敛,并使用测试集测试模型效果,通过预设的模型评估标准后输出所述陆空通话语义理解模型;s34:将所述文本信息输入到所述陆空通话语义理解模型,输出所述单句语音信号对应的说话人角色以及航班号。作为本发明的优选方案,所述陆空通话语义理解模型包括语义信息提取网络和说话人角色识别网络;所述语义信息提取网络为编码器-解码器结构,所述说话人角色识别网络为编码器-分类器结构,且所述语义信息提取网络和所述说话人角色识别网络共用编码器结构;所述编码器包括词嵌入提取层和双向lstm层,所述分类器包括lstm层和2个节点的全连接层,所述解码器包括多层lstm层和n个节点的全连接层,其中n为解码器词汇表的大小。作为本发明的优选方案,所述步骤s4包括:s41:设定分割步长和分割段长,并根据所述分割步长和所述分割段长将所述单句语音信号分割为多个带有重叠部分的语音片段;s42:构建基于深度神经网络的说话人声纹嵌入码提取模型,将所述语音片段输入到所述说话人声纹嵌入码提取模型中,提取所述语音片段的说话人声纹嵌入码;s43:构建多语音片段的说话人声纹嵌入码融合模型,将所述单句语音信号的所有所述语音片段的所述说话人声纹嵌入码输入到所述说话人声纹嵌入码融合模型,得到所述单句语音信号的说话人声纹嵌入码;s44:构建基于bert的说话人判决模型,将所述语音帧的说话人声纹嵌入码输入到所述说话人判决模型中,进行反向传播训练模型,通过预设的模型评估标准后输出所述陆空通话语义理解模型;s45:将所述单句语音信号的说话人声纹嵌入码与声纹数据库中的说话人声纹嵌入码一同输入到所述说话人判决模型进行说话人识别,给出该句语音与声纹库中的嵌入码匹配结果。作为本发明的优选方案,所述说话人声纹嵌入码提取模型包括:正弦卷积神经网络、一维卷积神经网络、长短期记忆模型以及全连接层;所述正弦卷积神经网络用于对所述语音片段进行特征预提取;所述一维卷积神经网络用于凝练所述语音片段中的说话人特征,并对特征向量作降维处理,减少后续网络层的计算量;所述长短期记忆模型用于学习所述语音帧之前的时序关联,从而学习说话人的语速、语调等发声特征;所述全连接层用于将说话人特征空间映射到一个固定维度的向量空间中,并将获取的向量经过l2正则化处理,得到说话人声纹嵌入码。作为本发明的优选方案,所述步骤s5包括以下匹配结果:匹配结果1:所述步骤s4声纹匹配成功,且所述说话人声纹嵌入码对应的所述说话人角色与所述步骤s3语义理解输出一致时,直接输出所述单句语音信号对应的说话人身份;匹配结果2:所述步骤s4声纹匹配成功,且所述说话人声纹嵌入码对应的说话人角色与所述步骤s3语义理解输出的说话人角色不一致时;分别从所述管制员静态声纹库以及所述飞行员动态声纹库中选择概率最高的注册信息,进行概率融合判决后输出所述单句语音信号对应的说话人身份;匹配结果3:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为飞行员,且所述单句语音信号中的航班号不存在于所述飞行员动态声纹库中,则所述单句语音信号属于新增飞行员,将所述飞行员注册至所述飞行员动态声纹库并输出说话人身份;匹配结果4:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为飞行员,且所述单句语音信号中的航班号存在于所述飞行员动态声纹库中,则取出所述航班号对应飞行员id的声纹匹配的概率、所述管制员静态声纹库中声纹匹配概率最高的管制员id以及概率,进行概率融合判决后输出所述单句语音信号对应的说话人身份;匹配结果5:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为管制员,则取出所述管制员静态声纹库中声纹匹配概率最高的管制员id以及概率,所述飞行员动态声纹库中声纹匹配概率最高的飞行员id以及概率,进行概率融合判决后输出所述单句语音信号对应的说话人身份。本发明通过声纹识别和语义理解两者相结合,能够有效提升陆空通话说话人身份识别的准确率,一方面,声纹识别可以在语音中不包含航班号或航班号提取失败的情况下,辨别说话人身份;另一方面语义理解为新增的飞行员提供了id信息,并且比仅基于声纹识别或仅基于语义理解的说话人身份识别系统更加具有鲁棒性。作为本发明的优选方案,所述匹配结果2中融合判决包括以下步骤:令所述单句语音信号为x,则说话人身份满足以下公式:pspker(x)=αprole(x) βpvpr(x),其中,pspker(x)为说话人身份,α、β为预设参数,prole(x)、pvpr(x)分别是所述步骤s3语义理解角色识别和所述步骤s4声纹匹配输出的概率。作为本发明的优选方案,所述匹配结果4中融合判决包括以下步骤:令所述单句语音信号为x,则说话人身份满足以下公式:其中,pspker(x)为说话人身份,pilotid为所述航班号对应飞行员id,其对应的声纹匹配的概率为pvpr_pilot(x),controllerid为所述管制员id,其对应的声纹匹配的概率为pvpr_controller(x),unknown为未知说话人,t1,t2为预设的阈值,且满足0<t2<t1<1。作为本发明的优选方案,所述匹配结果5中融合判决包括以下步骤:令所述单句语音信号为x,则说话人身份满足以下公式:其中,pspker(x)为说话人身份,pilotid为所述飞行员id,其对应的声纹匹配的概率为pvpr_pilot(x),controllerid为所述管制员id,其对应的声纹匹配的概率为pvpr_controller(x),unknown为未知说话人,t3,t4为预设的阈值,且满足0<t4<t3<1。作为本发明的优选方案,所述飞行员动态声纹库能周期性对所述飞行员id进行检测,若所述飞行员id在预设的周期内无活动状态,删除所述飞行员id对应的注册内容。本发明根据管制扇区的特点设定飞行员id的存活时间窗口,并周期性维护飞行员动态声纹库,在提高识别效率的同时降低说话人身份的误识率。作为本发明的优选方案,所述步骤s1为采集管制单位的所有管制员的语音数据。一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述任一项所述的方法。与现有技术相比,本发明的有益效果:。1.本发明基于深度神经网络的声纹识别和语义理解技术,来对陆空通话中的说话人进行身份识别,解决陆空通话中开放环境下“多人”、“多轮”对话中的说话人身份识别问题,建立管制通话上下文的关联,提高机器智能对管制通话的理解能力,为空管安全防护、管制数据分析等应用提供可靠的说话人身份信息,从而提升管制安全系数。此外,本发明还可应用于其它陆空通话下游应用。在事故征候分析场景下,本发明可以实现语音信息的快速检索,精准定位各说话人的通话语音;在管制工作质量评价场景下,本发明可以结合语音识别、大数据等技术,实现管制工作量的精准统计与管制习惯的分析,从而对管制员展开针对性的培训,提高管制效率与安全系数。2.本发明通过录入各个识别场景下、多种发音状态下以及多语种的陆空通话数据,大大的提升了身份识别的准确率,避免了样本过少导致的识别不准的问题。3.本发明通过声纹识别和语义理解两者相结合,能够有效提升陆空通话说话人身份识别的准确率,一方面,声纹识别可以在语音中不包含航班号或航班号提取失败的情况下,辨别说话人身份;另一方面语义理解为新增的飞行员提供了id信息,并且比仅基于声纹识别的说话人身份识别系统更加具有鲁棒性。4.本发明根据管制扇区的特点设定飞行员id的存活时间窗口,并周期性维护飞行员动态声纹库,在提高识别效率的同时降低说话人身份的误识率。附图说明图1为本发明实施例1所述的一种陆空通话说话人身份识别方法的原理示意图;图2为本发明实施例1所述的一种陆空通话说话人身份识别方法的流程示意图;图3为本发明实施例1所述的一种陆空通话说话人身份识别方法的陆空通话语音切分工作流程图;图4为本发明实施例1所述的一种陆空通话说话人身份识别方法的语音帧分类器网络结构图;图5为本发明实施例1所述的一种陆空通话说话人身份识别方法的gru神经网络工作原理图;图6为本发明实施例1所述的一种陆空通话说话人身份识别方法的多任务语义理解网络结构图;图7为本发明实施例1所述的一种陆空通话说话人身份识别方法的说话人声纹嵌入码提取模型网络结构图;图8为本发明实施例1所述的一种陆空通话说话人身份识别方法的基于bert的声纹判决模型网络结构图;图9为本发明实施例1所述的一种陆空通话说话人身份识别方法的开放环境下说话人身份识别流程图;图10为本发明实施例1所述的一种陆空通话说话人身份识别方法的声纹识别与语义理解结果融合流程图;图11为本发明实施例1所述的一种陆空通话说话人身份识别方法的陆空通话说话人身份识别效果图;图12为本发明实施例2所述的一种利用了实施例1所述的一种陆空通话说话人身份识别方法的一种电子设备结构图。具体实施方式下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本
发明内容所实现的技术均属于本发明的范围。实施例1如图1所示,本发明提出了一种陆空通话说话人身份识别方法,先对管制员进行语音采集和存储注册,构建声纹数据库,再接引陆空通话语音信号,对其进行语音切分后,基于深度神经网络的声纹识别和语义理解技术,来对陆空通话中的说话人进行身份识别,解决陆空通话中开放环境下“多人”、“多轮”对话中的说话人身份识别问题,为空管安全防护、管制数据分析等应用提供可靠的说话人身份信息,从而提升管制安全系数。同时,在事故征候分析场景下,本发明可以实现语音信息的快速检索,精准定位各说话人的通话语音;在管制工作质量评价场景下,本发明可以结合语音识别、大数据等技术,实现管制工作量的精准统计与管制习惯的分析,从而对管制员展开针对性的培训,提高管制效率与安全系数。如图2所示,本发明方法具体步骤如下:步骤1:采集管制单位的管制员的语音,构建包括管制员静态声纹库以及飞行员动态声纹库的声纹数据库,并对所有管制员进行声纹注册,其中,所述管制员的声纹注册内容包括所述管制员的所述说话人声纹嵌入码和背景信息;所述飞行员的声纹注册内容包括所述飞行员的所述说话人声纹嵌入码和飞行员id(所述飞行员id为对应的航班号)。步骤11:管制员使用专用语音信号采集设备录制语音,该设备包括陆空通话朗读录制软件、陆空通话专用耳麦(pushtotalk,ptt)设备,录制的语音经滤波、采样、pcm编码后形成8k采样率、16bit采样精度的数字语音信号,并将wav格式的语音文件存储到磁盘;步骤12:构建管制员静态声纹库,为每个管制员建立一条记录,记录中主要包括管制员id、性别、年龄、籍贯、语音片段以及语音片段对应的说话人声纹嵌入码等字段等。步骤13:将采集到的管制员语音信号使用基于深度学习的说话人声纹嵌入码提取模型提取说话人声纹嵌入码,并存储到声纹数据库中的说话人声纹嵌入码字段。其中,所述步骤s1为采集管制单位的所有管制员的语音数据,所述管制员的所述语音数据满足以下要求:(1)所述语音数据包括识别场景中使用的语种;(2)所述语音数据包括多种发音状态下的语音;所述发音状态包括一般语速、快语速、慢语速、不稳定语速、缓和情绪、紧张情绪中的一种或多种;其中,不稳定语速为语速不定的发音状态,缓和情绪为语调平稳时的发音状态,紧张情绪为语调升高时的发音状态;(3)所述语音数据包括与所述管制员相对应的管制用语。步骤2:实时监听并采集陆空通话语音信号,利用实时语音切分技术将管制员/飞行员的单句语音信号从连续的陆空通话语音信号中切分出来,并在预处理后转换为pcm编码的wav格式语音文件,存入存储设备;其陆空通话语音信号切分流程图如图3所示。步骤21:使用多路语音信号采集设备从陆空通话语音记录仪实时采集陆空通话语音信号,并进行语音信号归一化等操作存储到磁盘。多路语音信号采集设备是专用于陆空通话语音引接的硬件设备,该采集设备支持两种信号引接模式:数字信号引接模式和模拟信号引接模式。在数字信号引接模式下,从多通道陆空通话语音记录仪的数字信号接口接引语音,即记录仪将模拟语音信号转换为数字语音信号后通过网络包(tcp/ip)的方式发送出来,多路语音信号采集设备通过网络监听的方式获取实时语音信号;在模拟信号引接模式下,从多通道陆空通话语音记录仪的配线架上通过音频线的方式接引模拟语音信号,并通过3.5mm音频接口接入多路语音采集设备。步骤22:将归一化后的语音信号使用语音实时切分算法检测语音信号并丢弃静音部分,切分出单句语音信号。步骤221:对多路语音采集设备采集到的语音实时预处理,包括语音预加重、分帧等,然后使用基于深度学习构建的语音帧分类模型对语音帧进行分类,然后使用语音切分噪声帧平滑算法对连续的语音帧序列做预测标签平滑,得出单句语音的起始点和结束点。步骤222:采集真实陆空通话语音信号,并对采集到的陆空通话语音信号在帧级别上标注,标注分为起始帧、语音帧、非语音帧和结束帧四类;设计基于深度神经网络的语音帧分类器以及模型训练时使用的优化器、损失函数以及模型的评估方法等。使用标注的语音数据和构建的神经网络结构训练语音帧分类模型。陆空通话语音信号将被分为帧长35ms、帧移15ms的音频帧,并经过语音预加重、加窗等操作后提取40维的梅尔倒谱系数特征作为语音帧分类网络的输入。语音帧分类器模型网络结构如图4所示,由3个卷积模块、2个循环神经网络模块、1个输出模块组成。卷积模块由一维卷积层(conv1dlayer)和最大池化层(maxpooling)、归一化层(batchnormalization)、剪枝层(dropout)四个网络层组成,卷积模块可以抽取地空通话语音中的起始帧、语音帧、非语音帧和结束帧以及不稳定的噪声帧的局部特征,增加网络的鲁棒性;循环神经网络采用门限循环神经网络(gatedrecurrentunit,gru)组成,gru门控循环单元能捕捉帧内信息短时变化的依赖关系,并且gru网络结构相较于rnn、lstm等循环神经网络层结构简单,有利于减少计算时延;输出模块由4个神经元的全连接层(fullyconnectionlayer)组成,输出四类语音帧的概率分布。网络采用交叉熵(crossentropy)损失函数进行反向传播训练,并使用随机梯度下降(stochasticgradientdescent,sgd)优化算法优化网络模型。其中gru结构如图5所示。假设给定时间步t的语音高维聚合特征xt和上一时间步的隐藏状态ht-1,重置门rt、更新门zt、候选隐藏状态和隐藏状态ht的假设给定时间步t的语音高维聚合特征xt和上一时间步的隐藏状态ht-1,重置门rt、更新门zt、候选隐藏状态和隐藏状态ht的gru网络推理过程可以由以下的递推式描述,rt=σ(xtwxr ht-1whr br)(1)zt=σ(xtwxz ht-1whz bz)(2)式中σ(x)为sigmoid激活函数,wxr,whr,wxz,whzwxh,whh为权重矩阵,br,bz为偏置矩阵,e代表按元素相乘。网络参数设置如下:3个卷积模块的卷积层统一采用1x3大小的卷积核,卷积核数量分别为16、32、64,并使用elu非线性激活函数;池化层的步长分别为1x3、1x6、1x9;dropout层剪枝节点比例为0.2。2个循环神经网络模块gru层的神经元数量都设置为32,输出模块使用softmax激活函数。语音帧分类器的训练数据集语音时长共50小时,其中包含30小时静音时长、20小时的语音时长。训练集按照90%、5%、5%的比例划分为训练集、验证集、测试集。步骤3:将步骤2切分后的单句语音信号,使用基于多任务学习的陆空通话语义理解模型识别说话人角色(管制员/飞行员),并提取该句语音所包含的航班号,具体为:步骤31:使用已有的陆空通话语音识别模型识别出步骤2切分的语音中包含的文本内容。步骤32:建立基于多任务学习的陆空通话语义理解模型,确定各网络层的组成结构、训练所需的损失函数、网络优化器、网络超参数的初始化策略等。表1陆空通话语义理解模型的输入输出根据国际民用航空组织(icao)标准,一般情况下管制员向飞行器发布指令的通话格式为航班号 指令内容,飞行员复诵指令的通话格式为指令内容 航班号。此标准为陆空通话语义理解模型中的说话人角色识别提供了理论支撑。但实际生产环境下,管制指令的发布与复诵都比较灵活,约有10%的管制通话并没有严格遵守该格式。因此,语义理解输出需与声纹识别结果相融合以提升说话人角色识别的准确率。陆空通话语义理解模型中的语义信息提取网络负责提取与转换为统一的表示格式。如表1所示,航班号转换为航空公司三字码(国航/airchina→cca) 阿拉伯数字(幺两三拐/onetwotreeseven→1237);高度统一转换为阿拉伯数字(八幺/八千一/eightthousandonehundredmeters→8100)。陆空通话语义理解模型的结构图如图6所示,本发明将说话人角色识别定义为文本分类问题,将语义信息提取定义为序列转换问题。因此,说话人角色识别网络采用编码器-分类器结构,语义信息提取网络采用编码器-解码器(encoder-decoder)结构,二者编码器的网络层相同且参数共享;编码器由词嵌入提取层(wordembeddinglayer)、双向lstm层组成,分类器由lstm层、2个节点的全连接层组成,解码器由多层lstm层和n个节点的全连接层组成,其中n为解码器词汇表的大小。步骤33:使用标注好的陆空通话文本数据训练陆空通话语义理解模型,直至网络收敛;选择模型评估标准并使用测试集测试模型效果,直至选出较优模型。其中,模型使用交叉熵损失函数,随机梯度下降优化器;标注好的陆空通话数据约20万条,按照90%、5%、5%的比例划分为训练集、验证集、测试集。步骤34:将步骤31中识别出的文本信息输入陆空通话语义理解模型,预测该句语音的说话人角色以及航班号。步骤4:将步骤2切分后的单句语音信号,使用基于深度学习的声纹识别模型提取语音中的说话人声纹嵌入码,具体为:步骤41:对切分好的语音进行标准化处理,根据预先设定好语音步长和段长,将单句语音分割为带重叠的语音片段;在本装置中语音段长设置为2s、步长设置为0.5s。如一条3s的语音片段将被分割为0.0s-2s、0.5s-2.5s、1.0s-3.0s三个语音片段。步骤42:建立基于深度神经网络的说话人嵌入码提取模型,将分隔好的语音片段传入说话人嵌入码提取模型中,提取所有语音片段的说话人声纹嵌入码。基于深度神经网络的说话人声纹嵌入码提取模型如图6所示,原始语音信号作为模型输入馈入正弦卷积神经网络(sincconv),对语音信号进行特征预提取,sincconv网络使用了信号处理中滤波器的特性,具有网络收敛更快、学习参数少、计算高效、可解释性强等特点,比传统cnn更适合做音频信号特征预提取。然后将提取到的高维特征馈入卷积神经网络模块中,进一步凝练语音信号中的说话人特征,并对特征向量作降维处理,减少后续网络层的计算量。此后,将提取到的特征馈入长短期记忆神经网络模块(lstm)中,学习语音帧之前的时序关联,从而学习说话人的语速、语调等发声特征。最后,lstm输出的将经过一个仿射层,将说话人特征空间映射一个固定维度的向量空间中。该向量经过l2正则化处理,即可得到对应的说话人声纹嵌入码。说话人特征提取网络使用度量学习优化神经网络,损失函数为基于余弦距离的三元组损失(tripletloss)函数,使用随机梯度下降算法作为网络的优化器。三元组其中的三元为图7所示的anchor、negative、positive三段语音,通过tripletloss的学习后使得positive元和anchor元之间的声纹嵌入码余弦距离最小,而和negative之间距离最大。其中anchor为训练数据集中随机选取的一个语音样本,positive为和anchor来自同一说话人的语音样本,而negative则来自与anchor不同说话人的语音样本。sincconv原理如以下递推公式:y[n]=x[n]*g[n,θ](5)g[n,f1,f2]=2f2sinc(2πf2n)-2f1sinc(2πf1n)(7)其中x[n]是语音信号,y[n]是滤波器的输出,g[n,θ]是一个矩形带通滤波器,其频域特性如式(6)所示,f1,f2分别为低截止频率和高截止频率,与θ一样是可学习的参数,其时域形式如式(7)所示。网络参数设置如下:sincconv截止频率随机初始化为[0,fs/2],fs为语音信号的采样率。卷积神经网络模块使用conv1d网络,卷积核大小和数量分别为1x11和128。lstm网络的神经元个数为256。步骤43:使用标注好的样本训练说话人声纹嵌入码提取网络,训练使用的有效语音总时长共50个小时,涉及了我国民航空中交通管制中区调、进近、塔台等业务范围内的70位说话人。根据研究需要本文将语音数据分为训练集和测试集两个子集。训练集语音时长约45小时,包含60位说话人,其中女性12人、男性48人;测试集语音总时长约5个小时,包含10位说话人,其中女性2人、男性8人。此时采用的硬件环境为:cpu为8×intelcorei7-6800k,显卡为4×nvidiageforcegtx2080ti,显卡为4×11gb,内存为64gb,操作系统为ubuntulinux16.04。步骤44:确定多语音片段的说话人声纹嵌入码融合策略,将多语音片段的说话人声纹嵌入码融合,得到单句语音的唯一说话人声纹嵌入码。说话人声纹嵌入码融合可以使用均值法和拼接法,随后将验证两种方法对说话人识别系统的影响。步骤45:使用基于深度学习的说话人判决模型判别当前语音的说话人身份;步骤451:将说话人识别定义为二分类问题,设计基于bert的说话人判决模型,以及确定各网络层的组成结构、训练所需的损失函数、网络优化器、网络超参数的初始化策略等。其中,基于bert的说话人判决模型网络结构如图8所示。将两个512维的说话人声纹嵌入码使用[sep]标签分隔作为网络输入,[cls]标签为分类标签,该位置能够通过transformer网络,学习两段说话人声纹嵌入码之间的关系,若两段说话人声纹嵌入码来自同一个说话人则输出1,否则输出0。步骤452:根据语音的说话人标注信息,组成训练样本语音对并使用步骤3中的说话人声纹嵌入码提取模型提取说话人声纹嵌入码,并输入到说话人判决神经网络中训练模型,并使用反向传播算法优化深度神经网络;当网络收敛后,选择模型评估标准并使用测试集测试模型效果,选出较优模型。步骤453:给定一句语音,使用步骤4中的说话人声纹嵌入码提取模型提取说话人声纹嵌入码,与声纹数据库中的说话人声纹嵌入码一同输入到步骤5-2训练好的说话人判决模型进行说话人识别,给出该句语音与声纹数据库中的说话人声纹嵌入码匹配结果。如表2所示,为确定说话人声纹嵌入码提取网络中不同的lstm层对说话人识别系统结果的影响。表2不同lstm层数说话人声纹嵌入码提取网络结构说话人识别系统的结果实验序号lstm层数eer(%)1118.42314.8359.4466.5575.8使用等错误率(eer)作为评价指标,该值越小说话人识别系统性能越好。从实验结果来看,lstm层数堆叠越多eer值不断下降,7层lstm的网络eer下降到了5.8%。如表3所示,为确定不同说话人声纹嵌入码融合策略对说话人识别系统结果的影响。表3最优说话人识别声纹嵌入码提取模型下不同说话人声纹嵌入码融合策略下说话人识别系统的结果实验序号融合策略eer(%)1均值5.82拼接6.0使用等错误率(eer)作为评价指标,该值越小说话人识别系统性能越好。从实验结果来看,采用均值策略融合多段说话人声纹嵌入码较好,eer值为5.8%。如表4所示,为了证明基于bert的说话人判决模型的有效性,与其他说话人识别后端判决算法进行比较,如plda、svm、dnn等。表4不同说话人判决模型的结果实验序号说话人判决模型eer(%)1plda9.52svm7.53dnn6.24bert5.8如表5所示,为了证明该说话人识别系统的有效性,与其他说话人识别算法进行比较,如kaldi平台下的i-vector、pyannote平台下的sincnet、谷歌提出的d-vector等框架。表5不同说话人识别系统的结果实验序号说话人识别框架eer(%)1i-vector18.92d-vector12.73sincnet6.54本发明5.8使用等错误率(eer)作为评价指标,该值越小识别效果越好。与i-vector、d-vector、sincnet等说话人识别框架相比,本发明提出的方法eer最低,效果最好。其中,步骤3和步骤4的执行顺序可交换或同时进行。步骤5:采用静态-动态双注册模式构建开放环境下的说话人身份识别系统,完成连续“多人”、“多轮”场景下的说话人身份自动识别,并与步骤2中的语音文件建立说话人身份映射;开放环境下说话人身份识别流程如图9所示。步骤51:设计飞行员动态声纹库,每一条记录包括动态id、注册时间、注册语音以及注册语音对应的说话人声纹嵌入码。步骤52:根据陆空通话“多人”、“多轮”对话的特点,融合声纹识别与语义理解的结果,设计开放环境下的静态-动静双注册模式说话人身份识别策略,其中管制员以工号作为id,飞行员以航班号作为id。如图10所示,给定一句管制语音,语义理解模块输出该管制语音中所指挥航班的航班号、说话人角色(管制员/飞行员)以及对应的概率;声纹识别系统则匹配声纹数据库,若匹配成功,则给出该语音对应的说话人角色、id以及对应的概率,否则匹配失败;其融合策略如下:匹配结果1:所述步骤s4声纹匹配成功,且所述说话人声纹嵌入码对应的所述说话人角色与所述步骤s3语义理解输出一致时,直接输出所述单句语音信号对应的说话人身份。匹配结果2:所述步骤s4声纹匹配成功,且所述说话人声纹嵌入码对应的说话人角色与所述步骤s3语义理解输出的说话人角色不一致时;分别从所述管制员静态声纹库以及所述飞行员动态声纹库中选择概率最高的注册信息,进行概率融合判决后输出所述单句语音信号对应的说话人身份。其融合判决包括以下步骤:令所述单句语音信号为x,则说话人身份满足以下公式:pspker(x)=αprole(x) βpvpr(x),其中,pspker(x)为说话人身份,α、β为预设参数,prole(x)、pvpr(x)分别是所述步骤s3语义理解角色识别和所述步骤s4声纹匹配输出的概率。匹配结果3:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为飞行员,且所述单句语音信号中的航班号不存在于所述飞行员动态声纹库中,则所述单句语音信号属于新增飞行员,将所述飞行员注册至所述飞行员动态声纹库并输出说话人身份。匹配结果4:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为飞行员,且所述单句语音信号中的航班号存在于所述飞行员动态声纹库中,则取出所述航班号对应飞行员id的声纹匹配的概率、所述管制员静态声纹库中声纹匹配概率最高的管制员id以及概率,进行概率融合判决后输出所述单句语音信号对应的说话人身份。其融合判决包括以下步骤:其中,pspker(x)为说话人身份,pilotid为所述航班号对应飞行员id,其对应的声纹匹配的概率为pvpr_pilot(x),controllerid为所述管制员id,其对应的声纹匹配的概率为pvpr_controller(x),unknown为未知说话人,t1,t2为预设的阈值,且满足0<t2<t1<1。匹配结果5:所述步骤s4声纹匹配失败、所述步骤s3语义理解输出的说话人角色为管制员,则取出所述管制员静态声纹库中声纹匹配概率最高的管制员id以及概率,所述飞行员动态声纹库中声纹匹配概率最高的飞行员id以及概率,进行概率融合判决后输出所述单句语音信号对应的说话人身份。其融合判决包括以下步骤:其中,t3,t4为预设的阈值,且满足0<t4<t3<1。步骤53:根据管制扇区的特点设定飞行员id的存活时间窗口,并周期性维护动态声纹数据库,在提高识别效率的同时降低说话人身份的误识率。如图11所示,将一段连续的陆空通话语音信号,经本发明一种陆空通话说话人身份识别方法后输出的每段语音对应的说话人身份。实施例2如图12所示,一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述实施例所述的一种陆空通话说话人身份识别方法。所述输入输出接口可以包括显示器、键盘、鼠标、以及usb接口,用于输入输出数据;电源用于为电子设备提供电能。本领域技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(readonlymemory,rom)、磁碟或者光盘等各种可以存储程序代码的介质。当本发明上述集成的单元以软件功能单元的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、rom、磁碟或者光盘等各种可以存储程序代码的介质。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

