本发明属于语音检测领域,特别涉及一种合成语音检测技术。
背景技术:
随着人工智能的发展,嵌入式设备发生了巨大的变化。图像识别和人脸解锁在嵌入式设备中的应用极大地方便了生产和生活。语音识别作为声学人工智能的代表,在语音助手、语音打印解锁等嵌入式设备中得到了越来越广泛的应用。语音识别技术是指通过识别和分析过程使计算机能够将语音信号转换为相应的文本或命令的技术。自动说话人验证(asv)是一种语音识别技术,通过区分人语音的语音打印特征来识别个体。在许多情况下,asv技术可以取代传统的密码身份验证。成为一种方便有效的认证方法,可以易于应用于远程人员身份验证。
但是,由于表示攻击(pa)以及语音信号比起比其他人类特征(如指纹,虹膜等)更加容易被盗的特性,asv系统容易受到pa的攻击。
现有asv系统欺骗方法中,模仿攻击危害较小,其攻击效果与攻击者和目标受害人语音相似程度以及asv系统鲁棒性有直接关系。重放语音攻击可通过增加语音内容的时效性进行有效防御。合成语音攻击对asv系统威胁程度较大,其不受内容时效性影响。转换语音攻击原理和合成语音攻击相似,对asv系统威胁程度较大。同时这两种攻击也经常出现在其他的语音识别技术的应用场景,如电话诈骗等。本发明正是针对嵌入式语音设备提出的有效检测出合成语音的系统。
目前对合成语音的检测方法主要分为三步,特征提取、模型训练和模型分类。语音特征提取方法大多根据生物结构特征(如人耳识别声波所依靠的结构特征)对语音倒谱系数进行提取。常见的倒谱系数有线性频率倒谱系数(lfcc)、梅尔频率倒谱系数(mfcc)、瞬时频率耳蜗滤波器倒谱系数(cfccif)、无限脉冲响应常数q变换倒谱系数(icqc)、基于恒定q变换(cqt)的倒谱系数cqcc等。模型分类主要有生成法、判别法和基于dnn的端到端分类法等。目前采用生成法的大多数检测系统都采用了gmm分类器,在分类阶段,处理输入语音以获得其相对于自然语音gmm和合成语音gmm的可能性,并通过得分高低判断输入语音是否为合成语音。
技术实现要素:
为解决上述技术问题,本发明提出一种基于语音分割的合成语音检测方法,基于语音分割训练的多个gmm模型为基础来判别输入语音是否为合成语音。
本发明采用的技术方案为:一种基于语音分割的合成语音检测方法,分别将自然语音和合成语音提取到的cqcc特征输入到两个初始化后的gmm模型值中进行训练,采用训练完成的gmm模型对输入的语音进行检测,得到检测结果。
训练具体为训练4个gmm模型,自然语音数据集与合成语音数据集各训练两个gmm模型。
自然语音数据集对应的两个gmm模型的训练过程为:
将自然语音数据集进行预处理得到分割后的语音片段和无声片段,对有声片段进行cqcc特征提取,对无声片段计算其过零率;
将cqcc和过零率分别输入两个gmm模型进行训练,更新其参数;
达到预设的训练次数,最终得到参数训练好的gmm模型。
合成语音数据集对应的两个gmm模型的训练过程为:
将合成语音数据集进行预处理得到分割后的语音片段和无声片段,对有声片段进行cqcc特征提取,对无声片段计算其过零率;
将cqcc和过零率分别输入两个gmm模型进行训练,更新其参数;
达到预设的训练次数,最终得到参数训练好的gmm模型。
所述预处理具体为:
从自然语音数据集或合成语音数据集中获取全部的训练数据,并检查语音识别的采样率;
判断采样率是否为16khz,若否,则使用工具包sox转换语音采样率为16khz,当语音采样率为16khz时,使用语音强制对齐工具p2fa检测语音信号的端点,以此标记语音句子中每个单词的开始和结束位置;
根据标记的端点进行语音切割,将语音数据分割为单词片段以及无声片段。
所述cqcc特征提取,包括以下分步骤:
将有声片段进行预加重处理;
将预加重处理后的有声片段按10ms分为短段,每段之间有部分重叠;然后进行加窗;
进行恒定q变换,然后将幅度平方取对数获得功率谱,对功率谱进行均匀采样,最后进行离散余弦变换,得到cqcc系数。
还包括对训练好的两个gmm模型进行加权求和,通过分别对两个gmm模型赋予不同的权重并测试准确率,两个gmm模型权重之和为1,选择准确率最大值对应的权重作为两个gmm模型的权重。
检测过程具体为:
将输入的完整语音按照单词进行分片,同时产生无声的静默片段;
对语音片段进行cqcc特征提取,并计算无声部分的过零率;
将cqcc和过零率输入已经训练好的gmm模型进行推断,得出检测结果。
本发明的有益效果:本发明基于语音分割训练的多个gmm模型为基础来判别输入语音是否为合成语音,本发明提取音频中的两种特征:有声片段的cqcc特征,对于音频的无声(静音)片段,计算其平均过零率;然后两个gmm模型分别对两种特征进行了拟合,然后对两个gmm赋予不同的权值并测试,找到最合适的权重;相比于传统检测方法,本发明的方法检测精度更高,本发明的方法具备以下优点:
1.提出了一种模拟感知特征提取方法,用于欺骗语音检测和两种相应的训练方法sw_cqcc和azcr,以提高检测精度;
2.设计bds策略,确定如何对两种训练方法进行综合判断;
3.实验结果表明,与其他方法相比,本发明的方法可达到94.01%的精度提高。
附图说明
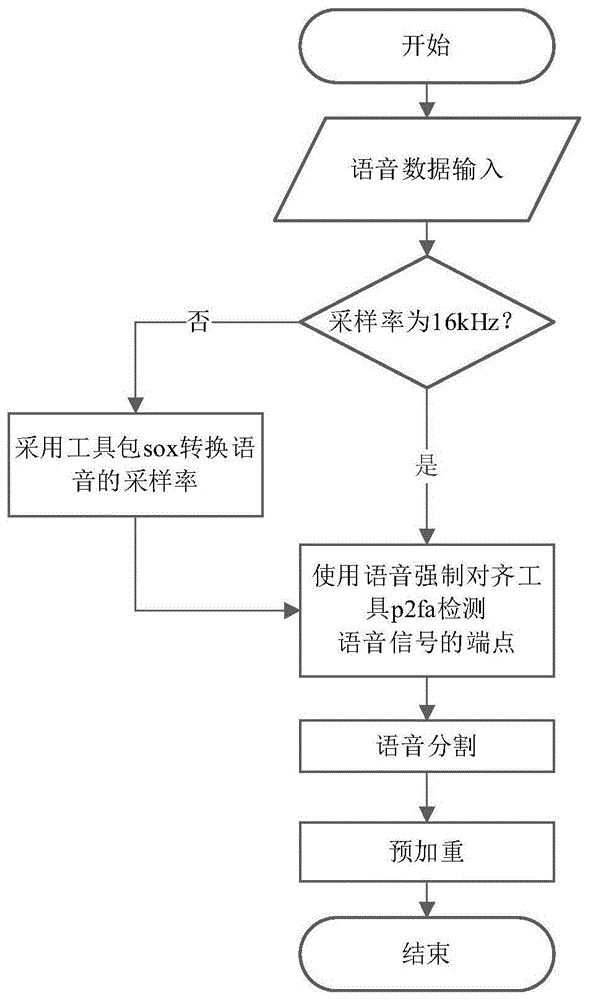
图1是本发明的数据处理模块流程图。
图2是本发明的语音特征提取方法流程图。
图3是本发明模型训练模流程图。
图4是本发明部署阶段流程图。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。
本发明分为训练阶段及部署阶段,训练阶段在服务器上进行,部署阶段在训练阶段完成之后进行,将训练阶段的数据部署到语音设备上。
训练阶段主要包括数据处理和模型训练两部分。
步骤a数据预处理,主要是对输入的原始语音信号进行处理,检测采样率,并进行语音信号的端点检测(找出语音信号的始末)、语音分帧(近似认为在10-30ms内是语音信号是短时平稳的,将语音信号分割为一段一段进行分析)等处理。
如图1所示,步骤a的详细步骤包括:
步骤a1:从训练集中获取全部的训练数据,并检查训练集中语音识别的采样率。
步骤a2:若语音数据的采样率为16khz,跳转至a3,否则使用工具包sox转换语音采样率为16khz。
步骤a3:使用语音强制对齐工具p2fa检测语音信号的端点,以此标记语音句子中每个单词的开始和结束位置。
步骤a4:依照a3步标记的端点进行语音切割,将语音数据分割为单词片段以及无声片段。
步骤b语音特征提取,相较于mfcc(mel-frequencycepstralcoefficients,梅尔频率倒谱系数)等传统倒谱系数,本发明系统采用的sw-cqcc(splitedwordconstantqcepstralcoefficients,分词常数q变换倒谱系数)更加考虑到了人耳的听力特征,采用了中心频率按指数规律分布,滤波带宽不同、但中心频率与带宽比为常量q的滤波器组。这样的选择避免了时频分辨率均匀的缺点,对于低频的波,它的带宽十分小,但有更高的频率分辨率来分解相近的音符;但是对于高频的波,它的带宽比较大,在高频有更高的时间分辨率来跟踪快速变化的泛音。
如图2所示,步骤b的详细步骤包括:
步骤b1:将语音数据进行预加重处理,增强语音的高频成分,以补偿高频分量在传输过程中的过大衰减。因为预加重对噪声并没有影响,因此语音信噪比能得到很好的提高。
yn=xn-a*xn-1
其中,xn表示当前时刻n的语音信号,α表示预加重系数,xn-1表示上一时刻n-1的语音信号,yn表示预加重处理之后的信号。
步骤b2:将语音数据按10ms分为短段,每段之间应有部分重叠。语音信号在宏观上是不平稳的,在微观上是平稳的,具有短时平稳性(10—30ms内可以认为语音信号近似不变)。然后进行加窗,即与一个窗函数相乘,加窗之后是为了进行傅里叶展开。
汉明窗,因为傅里叶展开需要对信号进行分帧,加窗是为了防止在分帧后,在帧起点和帧终点因为高度的不连续性出现吉布斯现象,所以会将较大的权重赋予靠近窗中心的信号,将接近零的权重赋值给靠近窗边缘的信号,以减轻分帧时的不连续性,汉明窗的权重函数为:
步骤b3:进行恒定q变换(cqt),然后将幅度平方取对数获得功率谱,对功率谱进行均匀采样,最后进行离散余弦变换,得到cqcc系数,特征提取完毕。
训练阶段如图3所示,一共训练4个高斯混合模型(gmm),自然语音数据集与合成语音数据集各训练两个。
步骤c:自然语音数据集训练gmm,本发明采用gmm(gaussianmixturemodel,混合高斯模型)来实现合成语音的检测,混合高斯模型是指多个高斯分布函数的线性组合,理论上gmm可以拟合出任意类型的分布,通过分别将自然语音和合成语音提取到的cqcc特征输入到两个初始化后的gmm模型值中进行训练,就可以拟合出两种语音的cqcc特征的分布,本发明在拟合之前进行了一定的实验,选取了256维作为gmm的维数,除此之外,本发明还对两种语音提取到的平均过零率azcr(averagezerocrossrate,平均过零率)也进行了训练,同样是用gmm来进行拟合;详细步骤如下:
步骤c1:将自然语音数据集进行上述数据处理得到分割后的语音片段和无声片段,对有声片段进行cqcc特征提取,对无声片段计算其平均过零率。
步骤c2:将cqcc和平均过零率分别输入两个gmm模型进行训练,更新其参数,gmm模型为现有已知技术,其参数更新为现有技术,本发明中不做详细阐述。
步骤c3:继续输入自然语音,重复步骤a1、a2,进行100轮(可指定轮数)训练,最终得到参数训练好的gmm模型。
步骤c4:bds(biaseddecisionstrategy,偏执决策策略)策略的制定:对训练好的两个gmm模型进行加权求和,通过分别对两个gmm模型赋予不同的权重并测试,通过测试准确率来寻找到最合适的权重。具体的:两个gmm模型的权重之和为1,通过对两个gmm模型设置不同的权重并进行测试,选择准确率最高的作为最合适的权重,实验中是分别设置0.1gmm1 0.9gmm2,0.2gmm1 0.8gmm2...等10组实验来寻找最合适的权重分配。
采用合成语音数据集训练gmm,详细步骤同自然语音数据集训练方法c1至c3,将输入数据集换成合成语音数据集即可。
部署阶段主要目的就是将参数已经训练好的模型放入设备上的合成语音检测推断模块,以达到对输入语音的快速检测效果。
使用训练好的模型进行推断检测。推断检测主要分为三个部分,数据处理部分、推断部分和输出部分,已经训练好的模型可以直接放入推断部分进行使用,输出结果。在高精确度要求下,系统的输入语音将按照单词进行分片,同时产生无声的静默片段,系统对前者进行cqcc特征提取,对后者计算其平均过零率,经过推断部分最终得到检测结果。在有快速检测要求的环境下,输入语音数据的分割从检测到声音的时刻开始截取按照用户提前设定好的时长的片段(默认时长为经过实验后在时长和精确度之间的一个平衡点2.5s),分割好的片段按顺序直接送入系统进行检测,并实时反馈检测结果。
如图4所示部署阶段分为高精度要求检测效果部署和快速检测部署。
步骤d:高精度推断部署阶段。详细步骤如下:
步骤d1:将完整的待检测语音进行步骤a的数据处理,得到包含语音信息的单词片段和无声部分。
步骤d2:对语音片段进行cqcc特征提取,并计算无声部分的平均过零率。
步骤d3:将cqcc和平均过零率输入已经训练好的模型进行推断,得出检测结果,返回给用户。
步骤e:快速检测部署。详细步骤如下:
步骤e1:输入语音分割的时间(默认为2.5秒),将持续输入的语音数据按分割时间分为片段。
步骤e2:按照时间顺序将语音片段进行cqcc特征提取,并计算平均过零率。
步骤e3:将cqcc和平均过零率输入已经训练好的模型进行推断,得出检测结果,并实时返回给用户。本领域技术人员应知,这里的检测结果为该语音数据是否为合成语音。
在同一数据集上,相较于最经典的仅用cqcc作为前端特征的检测方法所达到的85.49%的准确率,本发明的方法的准确率达到了94.01%,通过提升训练数据量,测试准确率可以达到95.77%。
对于同一数据集,分别用mfcc(梅尔频率倒谱系数mel-frequencycepstralcoefficients),cfccif(瞬时耳蜗基底膜倒谱系数cochlearfiltercepstralcoefficientsinstantaneousfrequency)以及cqcc作为前端特征进行训练与测试,得到这三种方法(mfcc、cfccif、cqcc)测试准确率分别达到的76.45%、80.49%、85.49%,而本发明的方法的测试准确率则达到了94.01%。
本发明的方法尤其适用于以下场景:
1.具有语音识别(解锁)功能的高精度设备,该类设备受到合成语音威胁较大,在使用了本发明所提出的方法后,能有效检测出合成语音;尤其是语音解锁功能的设备,即使攻击者知道了解锁口令并采用合成语音技术合成受害者的语音,也无法通过检测。
2.具有快速识别要求的场合,如在实时通信设备中,本发明所提供的方法可以用来实时检测对方是否使用合成语音进行了通话。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

