本发明属于人工智能语音合成技术领域,具体涉及一种基于生成式对抗网络的语音合成方法。
背景技术:
语音作为最直接快速的沟通方式,在人工智能领域起着非常重要的作用,已广泛应用于机器人,汽车,合成主播等领域。随着人工智能产品的广泛应用,对语音合成的自然度、清晰度、可理解性等要求也越来越高。深度学习让语音合成技术快速发展。
现在常用的基于深度学习的语音合成方案主要分为两个阶段:根据文本信息预测其声学特征,如mel-spectrograms;由声学特征预测其原始音频波形,即声码器模型学习。第一阶段是低维特征间的运算,而第二阶段声学特征到原始音频,通常需要从低纬度映射到高维度,如采样率16000,48000等。wavenet是一种自回归卷积神经网络,作为最早一批被用于语音合成的深度学习算法,大大提升了语音合成质量,但是其模型结构决定了速度非常慢,很难应用到实际产品中。近几年,对语音合成声码器的研究也主要侧重于提升运算速度和降低模型参数,对合成速度并无大的提升。
技术实现要素:
为克服现有技术存在的技术缺陷,本发明公开了一种基于生成式对抗网络的语音合成方法。
本发明所述基于生成式对抗网络的语音合成方法,包括以下步骤:
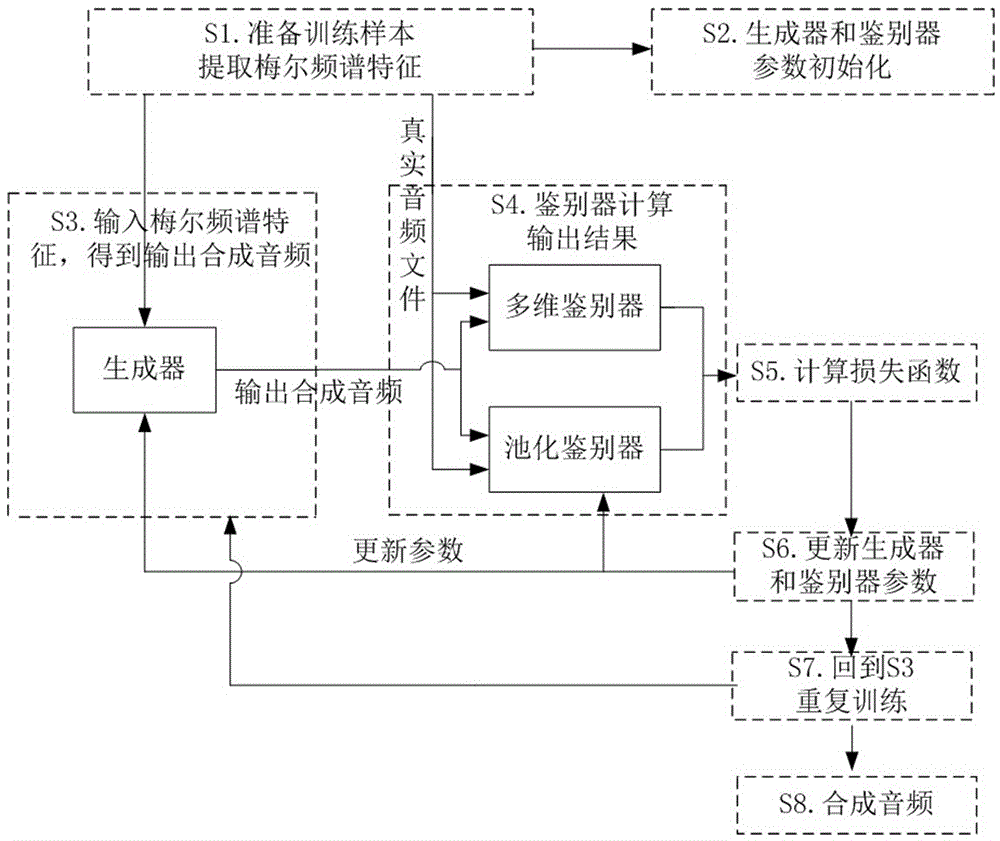
s1.准备训练样本,包括真实音频数据,提取真实音频数据的梅尔频谱特征;
s2.根据梅尔频谱特征的提取方式和采样率,设置初始化的生成器参数组,包括设置一维反卷积参数和一维卷积参数;设置初始化的鉴别器参数组,包括多维鉴别器和池化鉴别器的参数;
s3.输入梅尔频谱特征到生成器,由生成器得到对应的输出合成音频;
s4.将s1中的真实音频数据和s3得到的输出合成音频对应同时输入到多维鉴别器和池化鉴别器;其中真实音频数据和输出合成音频均为一维音频数据;
多维鉴别器将一维音频数据转换为多维矩阵,并对多维矩阵进行二维卷积运算得到输出结果;
池化鉴别器将一维音频数据做池化缩小维度,然后进行一维卷积运算得到输出结果;
s5.将鉴别器的输出结果输入到损失函数公式,分别计算生成器损失函数和鉴别器损失函数;
上式中,loss_d(d;g)表示生成器模型参数固定时的鉴别器损失函数;loss_g(g;d)表示鉴别器参数固定时的生成器损失函数;
d(xm)表示真实音频数据x经过第m次变形后输入鉴别器得到的输出结果,s表示真实音频的梅尔频谱值,e(x,s)表示以x,s为变量进行均值计算;
gm(s)表示生成器输出的输出合成音频第m次变换后的m次第一中间值;d(gm(s))表示将该m次第一中间值输入鉴别器得到的m次第二中间值;
m为设定的音频数据总的变形次数,完成m次变形后,得到本次更新的损失函数;
(1)式表示每一次更新中,计算损失函数需要对输出合成音频进行m次变形,最终得到本次更新的损失函数。
s6.以(1)式得到的生成器损失函数和鉴别器损失函数进行生成器和鉴别器的更新;
s7.每更新一次后,返回步骤s3.并利用更新后的生成器和鉴别器重复s3-s7步骤;直到到达设定的更新次数最大值steps_max;
s8.利用生成器进行语音合成。
具体的,所述一维反卷积参数包括:
生成器的上采样因子[u1,u2...un],上采样因子需要满足条件u1*u2*...*un=hop_size;hop_size为计算梅尔频谱时的滑动步长;
卷积步长stride=[u1,u2...un]
输出特征维数
lout=(lin-1)*stride-2*padding dilation*(kernel_size-1) output_padding 1
----(2)
其中,padding为输入特征边缘扩充值,dilation为卷积核元素间距,kernel_size为卷积核大小,output_padding为输出特征边缘扩充值;
根据卷积步长stride,设计其他参数为:
cout(i)=cin(i)/2i;
ku(i)=2*ui;
padding(i)=ui//2 ui%2;
output_padding(i)=ui%2;----(3)
i=1,2,…n;ui为卷积步长stride的单个向量元素u1,u2...un;
其中cout(i)为第i次上采样的输出通道数,cin(i)为第i次上采样的输入通道数,ku(i)为第i次上采样的卷积核大小kernel_size;padding(i)为第i次上采样的输入特征边缘扩充值,output_padding(i)为第i次上采样的输出特征边缘扩充值;
所述一维卷积参数包括多尺度感受野融合模块内每个一维卷积参数。
优选的,所述步骤s6中利用(4)式得到的生成器全面损失函数ld和鉴别器全面损失函数lg替换(1)式得到的生成器损失函数和鉴别器损失函数;进行生成器和鉴别器的更新;
上式中,di表示第i个鉴别器,p表示鉴别器个数;lf(g;d)为特征损失函数,lmel(g)为梅尔频谱损失函数;λf,λmel分别为特征损失函数和梅尔频谱损失函数的经验权重值;(4)式中的loss_d(di;g)loss_g(g,di)由(1)式计算得到。
具体的,所述梅尔频谱损失函数的计算公式如下:
其中
具体的,所述特征损失函数的计算公式如下:
上式中,t表示鉴别器的层数,ni表示第i层的特征数,di(x)表示输入为x时第i层的特征值,x为真实音频数据,g(s)为由生成器合成的输出合成音频,上标m均表示当前的变换次数,m为设定的更新次数最大值;e表示均值计算;e(x,s)表示以x,s为变量进行均值计算。
本发明所述基于生成式对抗网络的语音合成方法,生成器所采用的均为一维卷积运算,模型参数小,速度快。本发明采用两个鉴别器及损失函数中加入梅尔损失函数和特征损失函数,能够有效帮助模型收敛,保证合成音频的清晰度、自然度和可理解性。
附图说明
图1为本发明所述语音合成方法的一个具体实施方式的流程示意图。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述基于生成式对抗网络的语音合成方法,包括以下步骤:
s1.准备训练样本,包括真实音频数据,提取真实音频数据的梅尔频谱特征;
s2.根据梅尔频谱特征的提取方式和采样率,设置初始化的生成器参数组,包括设置一维反卷积参数和一维卷积参数;设置初始化的鉴别器参数组,包括多维鉴别器和池化鉴别器的参数;
s3.输入梅尔频谱特征到生成器,由生成器得到对应的输出合成音频;
s4.将s1中的真实音频数据和s3得到的输出合成音频对应同时输入到多维鉴别器和池化鉴别器;其中真实音频数据和输出合成音频均为一维音频数据;
多维鉴别器将一维音频数据转换为多维矩阵,并对多维矩阵进行二维卷积运算得到输出结果;
池化鉴别器将一维音频数据做池化缩小维度,然后进行一维卷积运算得到输出结果;
s5.将鉴别器的输出结果输入到损失函数公式,分别计算生成器损失函数和鉴别器损失函数;
上式中,loss_d(d;g)表示生成器模型参数固定时的鉴别器损失函数;loss_g(g;d)表示鉴别器参数固定时的生成器损失函数;
d(xm)表示真实音频数据x经过第m次变形后输入鉴别器得到的输出结果,s表示真实音频的梅尔频谱值,e(x,s)表示以x,s为变量进行均值计算;
gm(s)表示生成器输出的输出合成音频第m次变换后的m次第一中间值;d(gm(s))表示将该m次第一中间值输入鉴别器得到的m次第二中间值;
m为设定的音频数据总的变形次数,完成m次变形后,得到本次更新的损失函数;
(3)式表示每一次更新中,计算损失函数需要对输出合成音频进行m次变形,最终得到本次更新的损失函数。
s6.以(1)式得到的生成器损失函数和鉴别器损失函数进行生成器和鉴别器的更新;
s7.每更新一次后,返回步骤s3.并利用更新后的生成器和鉴别器重复s3-s7步骤;直到到达设定的更新次数最大值steps_max;
s8.利用生成器进行语音合成。
本发明提出的基于生成式对抗网络的语音合成方法,主要用于声码器训练;所基于的生成式对抗网络(gan)包含一个生成器和两个鉴别器,生成器g采用卷积神经网络对梅尔频谱(mel-spectrogram)特征进行上采样,直到上采样维度达到音频时域内的维数。
准备的训练样本用于进行生成式对抗网络的训练,通常需要合成什么样的音色音频,就准备什么样的训练样本,例如希望合成女童声,则准备女童声样本。
对训练样本按照现有技术提取梅尔频谱特征。
根据梅尔特征的提取方式和采样率等信息,确定生成器的上采样因子[u1,u2...un],其中需要满足条件u1*u2*...*un=hop_size。当梅尔频谱特征数为n时,通过生成器生成的音频信号为维数是n*hop_size的一维向量;hop_size为计算梅尔频谱时的滑动步长。
上采样的实现可采用一维反卷积的方式,这里采用torch深度学习框架中的一维反卷积函数进行说明:
输入(bs,cin,lin),输出(bs,cout,lout)
其中bs是单次计算所选取的样本数,即深度学习中的批大小batch_size,cin为输入特征通道数,lin为输入特征维数、cout为输出特征通道数、lout为输出特征维数;
则:
lout=(lin-1)*stride-2*padding dilation*(kernel_size-1) output_padding 1
----(2)
其中卷积步长stride=[u1,u2...un],padding为输入特征边缘扩充值,dilation为卷积核元素间距,kernel_size为卷积核大小,output_padding为输出特征边缘扩充。
根据卷积步长stride参数,设计其他参数为:
cout(i)=cin(i)/2i;
ku(i)=2*ui;
padding(i)=ui//2 ui%2;
output_padding(i)=ui%2;---(3)
//符号表示整除,%表示除运算的余数;
i=1,2,…n;ui为卷积步长stride的单个向量元素u1,u2...un;按照公式(2)设置相应的参数,这样得到lout才是lin的整数倍,整数倍目的是保证最后得到的音频数据是梅尔频谱的整数倍,这样合成的音频采样数才准确。
其中out_channels(i)为第i次上采样的输出通道数,cin(i)为第i次上采样输入特征通道数,ku(i)为第i次上采样的卷积核大小kernel_size;padding(i)为第i次上采样的输入特征边缘扩充值,output_padding(i)为第i次上采样的输出特征边缘扩充值
例如输入(bs,cin,lin)=(32,512,340),u1=8,由公式(2)得到各个参数值,经过一维反卷积(convtransepose1d)(512,256,16,8,4,0)后输出的维度(bs,cout,lout)为(32,256,2720)。
在每个上采样层后,连接一个多尺度感受野融合模块(multi-receptivefieldfusion,以下简称mrf模块;
一个mrf模块包含∣kr∣个resblock层,每个resblock层的卷积核大小kernel_size=kr(i),i=1,2...,∣kr∣;
每一个resblock层包含∣d(i)∣个一维卷积的组合,每个一维卷积的参数为:
卷积核大小kernel_size=kr(i),i=1,2...,∣kr∣,
卷积核元素间距dilation=d(i,j),i=1,2...,∣d(i)∣。
生成器通过输入梅尔特征,输出音频,生成器参数组包括上述一维反卷积和一维卷积层参数。
生成器进行一维反卷积和卷积运算;先对梅尔频谱进行一维卷积运算,然后进行多个循环的上采样卷积和mrf模块运算,再经过一维卷积运算得到对应的输出合成音频。
本发明中采用两个鉴别器;将真实音频和由生成器合成的音频数据分别送入到两个鉴别器中得到音频特征,将该特征送入公式(1)或(4)的损失函数进行计算,然后通过更新生成器和鉴别器参数,使得公式(1)或(4)所示的损失函数越小越好。
两个鉴别器分别为多维鉴别器d1和池化鉴别器d2。
由于语音是由不同周期的正弦信号组成,所以需要识别音频数据中所隐含的各种周期模式,多维鉴别器d1将一维数据变形到多维,通过设计二维卷积核的大小,可以模拟出不同周期上的音频特征。音频信号一个音素的时长有长有短,如果一个音素的梅尔频谱有10帧,那么其对应的16000采样率的音频信号就有2000的点,池化鉴别器d2通过对音频数据进行不同尺度的池化,就可以有效捕获音频数据的细节和全局特征。
具体实现方式为:多维鉴别器d1将音频数据转换为多维矩阵,然后对该多维矩阵做二维卷积运算。
本发明设置将一维音频数据转换为n1个多维矩阵,每个多维矩阵的维度设置为mi,i=1,2...n1。n1的具体取值可根据经验值决定,例如为了防止变形后的数据每一行的数据有重叠,所以按照经验mi可取[2,3,5,7,11]。
如音频数据为[1,6400]的一维形式,则将音频数据变形为[2,3200],[3,2134],[5,1280]等n1个多维矩阵,转换原则为每一行均按照mi个间隔点依次取;然后依次对变换后的多维矩阵做二维卷积运算,其中二维卷积核列上的卷积核大小需设置为1。
假设一维音频数据的x维数为[1,w],则经过鉴别器d1变换后的矩阵x1i大小为
然后依次对各个多维矩阵进行二维卷积运算得到n1个输出结果d1(x1i),i=1,2...n1。分别对真实音频数据和由生成器g生成的音频数据做上述计算;得到2组,每组都有n1个输出结果。
池化鉴别器d2则将一维音频数据做池化(pool)缩小其维度,然后进行一维卷积运算。本发明中对输入鉴别器d2的音频数据做多尺度池化,如一维音频数据数据x维数为[1,w],则池化后数据x2i为
x2i=[1,|w//2i-1|],i=1,2...n2,
对x2i进行一维卷积计算得到n2个输出结果d2(x2i),i=1,2...n2。
分别对真实音频数据和由生成器g生成的音频数据做上述计算。得到2组,每组都有n2个输出结果。n2的取值需要保证音频数据在进行n2次池化后,送入d2鉴别进行计算后得到的特征维度大于0。
例如原始音频数据大小[1,6400],则对音频数据进行池化后,得到大小[1,3200],[1,1600]等n2个池化结果,分别对这原始音频数据和n2个一维矩阵进行一维卷积运算。
两个鉴别器得到的结果代入公式(1)或(4)计算损失函数。
损失函数用于对鉴别器和生成器模型参数进行修正,本发明中的损失函数(loss)包括生成器损失函数和鉴别器损失函数。
生成式对抗网络模型的训练步骤为先固定生成器模型参数,训练鉴别器参数;然后固定鉴别器参数再训练生成器模型参数;需要设计两个损失函数优化模型参数。其公式为:
上式中,loss_d(d;g)表示生成器g模型参数固定时,鉴别器d的损失函数,d(xm)表示真实音频数据x第m次变形后作为输入时鉴别器的输出,s表示真实音频的梅尔频谱值。e(x,s)表示以x,s为变量进行均值计算;es表示以s为变量进行均值计算。
loss_g(g;d)表示鉴别器d参数固定时,生成器g的损失函数,由梅尔提取方法生成音频数据的特征,然后送到鉴别器进行计算,公式中e表示均值计算;
gm(s)表示生成器输出的输出合成音频第m次变换后的m次第一中间值;d(gm(s))表示将该m次第一中间值输入鉴别器得到的m次第二中间值;
m为设定的音频数据总的变形次数,完成m次变形后,得到本次更新的损失函数;
(1)式表示每一次更新中,计算损失函数需要对输出合成音频进行m次变形,最终得到本次更新的损失函数。
更新鉴别器参数使loss_d(d;g)变小,即在更新鉴别器参数使真实音频通过鉴别器得到的特征值趋近于1,生成器生成的音频数据通过鉴别器得到的特征趋近于0。而更新生成器参数使loss_g(g;d)变小,使生成器生成的音频数据通过鉴别器得到的特征趋近于1。由此形成生成器和鉴别器的对抗式训练。
采用(1)式计算得到的损失函数对生成器和鉴别器进行更新,更新一次后,回到步骤s3重新开始下一次更新。
一个优选实施方式中,本发明添加梅尔频谱损失函数(mel-spectrogramloss),用于提高生成器的训练效率和音频的保真度。
梅尔频谱损失函数为真实音频的梅尔频谱和由生成器g生成的输出合成音频计算得到的梅尔频谱间的l1距离的均值,l1定义为梅尔频谱间差的绝对值总和,梅尔频谱损失函数lmel(g)的计算公式如下:
其中
(5)式e右边计算符号表示两项相减的绝对值总和,ex,s表示对x和s做均值计算。
采用梅尔频谱损失函数有助于生成器g生成与输入条件相对应的真实音频波形,并从初始阶段就稳定对抗训练过程。
一个优选实施方式中,本发明还添加特征损失函数(featureloss)用于训练生成器g,真实音频数据和生成器g生成的输出合成音频依次送入鉴别器d,分别记录中间层的特征输出,然后对对应的特征数据计算l1距离,然后计算均值。特征损失函数lf(g;d)的计算公式如下:
上式中,t表示鉴别器的层数,ni表示第i层的特征数,di(x)表示输入为x时第i层的特征值,x为真实音频数据,g(s)为由生成器合成的输出合成音频。
考虑上述梅尔频谱损失函数和特征损失函数后,最终,利用生成器全面损失函数ld和鉴别器全面损失函数lg进行生成器和鉴别器的更新,对(1)式进行替换。
生成器全面损失函数ld和鉴别器全面损失函数lg:
本发明采用两个鉴别器,上式中,di表示第i个鉴别器,p表示鉴别器个数,本发明中p=2。
上式中,di下标表示不同的鉴别器;
λf,λmel分别为特征损失函数和梅尔频谱损失函数的经验权重值,用于调节(4)式中各项的权重比值,例如可以取λf和λmel分别为2和45。
采用(4)式计算得到的损失函数对生成器和鉴别器进行更新,更新一次后,回到步骤s3重新开始下一次更新。
具体实施方式例:
准备训练样本,包括原始音频数据,提取其梅尔频谱特征,这里取梅尔频谱特征的维数为80。
输入梅尔频谱特征到生成器,由生成器得到对应的输出音频数据。
假如输入梅尔频谱特征的帧数为32,提取梅尔频谱特征时的步长为200,则通过生成器生成的输出音频数据音频长度为32*200=6400。
设置生成器的上采样步数、上采样初始通道数、上采样卷积步长;其余参数初始化值可以为零或采用其他方法如正态分布法等设定。
具体计算步骤为:设置上采样步数为3,上采样的卷积步长stride设置为[8,5,5],这里需要满足的条件是8*5*5=200=hop_size,hop_size为提取梅尔频谱特征时的步长。设置上采样的初始通道数为512,首先对梅尔频谱特征做一维卷积,使其扩展到512维,初始数据量由[80,32]经过一维卷积到[512,32],然后开始进行一维反卷积计算。
按照公式(3)设置第一次反卷积计算参数为out_channels=256,卷积核大小kernel_size=16,stride=8,out_padding=0,反卷积计算后的值维度为[256,256]。然后连接mrf模块,本实施例中设置mrf模块的参数(1)
∣kr∣=3,[kr(1),kr(2),kr(3)]=[3,7,11],
代表一个mrf模块包括3个resblock层,设置resblock层的参数为
∣d(1)∣=3,dilation=[d(1,1),d(1,2),d(1,3)],其余resblock层d(2)、d(3)参数同d(1)。
经过mrf模块计算后的特征维数仍然为[256,256],然后依次修改上采样的out_channels及其它参数,计算上采样和mrf模块,两轮迭代计算后模型输出维数为[64,6400],然后接一个一维卷积层conv1d层,输出维数[1,6400],即完成梅尔频谱特征到音频数据的转换。
然后进行鉴别器特征计算,其实施方式为:
多维鉴别器d1的计算,取大小为64000的音频数据,设置mi=[2,3,5,7,11],即将音频数据变形为
本实施例中多维鉴别器1采用六层二维卷积,输出通道分别为[32,128,512,1024,1204,1],每一层的卷积核大小kernel_size=[3,1],卷积步长stride=[3,1],waveform经上述一系列二维卷积计算后的维数为[1,40,2]。其余通过mi变形后的数据进行同样的二维卷积计算。分别对真实音频和生成器生成的输出合成音频做如上计算,得到的输出特征即可用于计算鉴别器的损失函数。
池化鉴别器d2的计算:取大小为[1,6400]的音频数据,本实施例中鉴别器2设置8层一维卷积;输出通道、卷积核大小、卷积步长和输入特征边缘扩充值分别为:
out_channels=[128,128,256,512,1024,1024,1024,1]kernel_size=[15,41,41,41,41,41,5,3],
stride=[1,2,2,4,4,1,1,1],
padding=(kernel_size-1)/2。
输入数据进行8层一维卷积后维数大小为[1,100],即为鉴别器d2的输出。
将[1,6400]的音频进行池化计算,实施例中采用均值池化(averagepooling),池化层的卷积核大小kernel_size=4,卷积步长stride=2,池化后的数据维数为[1,3200],对该数据进行同样的8层一维卷运算,得到最后的输出特征维数为[1,51]。然后用同样的池化参数对[1,3200]的数据进行计算得到数据维数为[1,1600],进行8层一维卷积运算得到的特征维数为[1,26],鉴别器d2三次的特征输出用于损失函数的计算。
完成鉴别器特征计算后进行模型训练。
设置公式(4)中的λf=2,λmel=45,learning_rate=0.0001。
初始化生成器g的参数集θg,鉴别器d的参数集θd
其中参数集θg表示生成器g中全部参数,包括进行一维卷积,一维反卷积及mrf模块所用到的参数;参数集θd表示鉴别器d里所有的模型参数。
更新次数iteration=1,2...,steps_max,steps_max为设定的更新次数最大值,通常取值在10万次以上;对每一次迭代执行如下操作:
由通过训练样本的真实音频数据x得到的梅尔频谱的真实值s,通过生成器g得到输出合成音频g(s)
将真实的音频数据x和输出合成音频g(s)分别送入鉴别器d1,得到d1(x)、d1(g(s));送入鉴别器d2,得到d2(x)、、d2(g(s));
固定参数θg,根据(4)式计算ld并更新参数集θd,使ld变小;完成更新一次。
按照公式(5)计算真实音频数据提取的梅尔频谱特征和生成器生成的输出合成音频提取的梅尔频谱特征的l1距离lmel(g)作为梅尔频谱损失函数;
鉴别器模型的参数集θd完成更新后,再次将真实的音频数据x和输出合成音频g(s)分别送入鉴别器d1,d2,得到d1(x)、d2(x)、d1(g(s))、d2(g(s))和各中间层特征。
利用公式(4)计算损失函数lg,固定参数集θd,更新参数集θg使得lg变小。
参数集θd,更新参数集θg均完成一次更新后,即完成一次更新,直到完成所有更新。
训练完成后得到生成器g,利用生成器实现梅尔频谱到音频数据的转换。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

