本发明涉及计算机技术领域,更具体地,涉及一种信息交互方法、装置及电子设备。
背景技术:
智能硬件随着人工智能的发展已经深度融入了居民生活中。在大多数场景中,语音是最自然的交流方法,因此,基于语音交互的硬件深受用户的喜爱。但是随之而来的便是更严格的交互要求。例如,部分用户采用方言讲话,或者讲话口齿不清、重复、或结巴等,都会对语音识别和语义理解模型产生极大地挑战。同时,部分用户听力不好,需要更加清晰和明亮的语音合成,否则无法进行有效的交互。例如在网约车应用领域中,由于部分用户的记忆力、视力、听力较弱,存在忘记下单或者网约车抵达后无法找到网约车的情况,这给司乘之间带来了一定的麻烦。
技术实现要素:
有鉴于此,本发明实施例提供一种信息交互方法、装置及电子设备,以在任务执行端接近用户时,通过语音方式告知用户任务执行端的信息,以提高任务执行端和用户的碰面效率,进而提高任务执行端和用户的体验感。
第一方面,本发明实施例提供一种信息交互方法,所述方法包括:
获取任务信息,所述任务信息包括任务执行端的位置和用户位置;
响应于所述任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息;
对所述任务执行端的信息进行整合处理,获取对应的辅助识别文本;
对所述辅助识别文本进行语音合成处理,获取对应的语音信息;
将所述语音信息发送至用户终端进行播报。
第二方面,本发明实施例提供一种信息交互装置,所述装置包括:
第一信息获取单元,被配置为获取任务信息,所述任务信息包括任务执行端的位置和用户位置;
第二信息获取单元,被配置为响应于所述任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息;
信息整合单元,被配置为对所述任务执行端的信息进行整合处理,获取对应的辅助识别文本;
语音合成处理单元,被配置为对所述辅助识别文本进行语音合成处理,获取对应的语音信息;
发送单元,被配置为将所述语音信息发送至用户终端进行播报。
第三方面,本发明实施例提供一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现如本发明实施例第一方面所述的方法。
第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现如本发明实施例第一方面所述的方法。
第五方面,本发明实施例提供一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行如本发明实施例第一方面所述的方法。
在本实施例中,获取包括任务执行端的位置和用户位置的任务信息,响应于任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息,对任务执行端的信息进行整合处理,获取对应的辅助识别文本,对辅助识别文本进行语音合成处理,获取对应的语音信息,将所述语音信息发送至用户终端进行播报,由此,可以在任务执行端接近用户时,通过语音方式告知用户任务执行端的信息,以提高任务执行端和用户的碰面效率,进而提高任务执行端和用户的体验感。
附图说明
通过以下参照附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
图1是本发明实施例的信息交互方法的流程图;
图2是本发明实施例的语音合成模型的示意图;
图3是发明实施例中的pre-net模块的预训练过程的示意图
图4是本发明实施例的信息交互过程的示意图;
图5是本发明实施例的信息交互装置的示意图;
图6是本发明实施例的电子设备的示意图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程、元件和电路并没有详细叙述。
此外,本领域普通技术人员应当理解,在此提供的附图都是为了说明的目的,并且附图不一定是按比例绘制的。
除非上下文明确要求,否则在说明书的“包括”、“包含”等类似词语应当解释为包含的含义而不是排他或穷举的含义;也就是说,是“包括但不限于”的含义。
在本发明的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
在以下实施例中,主要以通过网约车应用领域进行距离描述,应理解,本实施例并不对应用领域进行限制,其他需要双端之间相互寻找的应用场景,例如快递、外卖等物流应用领域等,均可应用本实施例的信息交互方法。
应理解,在本实施例的任一实施方式中,在获得用户授权后,获取的相关用户信息,例如账户信息、或位置信息等,以便于为用户提供导航或者引导用户寻找任务执行端等。
图1是本发明实施例的信息交互方法的流程图。如图1所示,本发明实施例的信息交互方法包括以下步骤:
步骤s110,获取任务信息。其中,任务信息包括任务执行端的位置和用户位置。可选的,通过获取任务执行端上传的坐标,以获得任务执行端的位置,通过获取用户终端标注的位置或获取用户语音输入的位置,以获得用户位置。
在一种可选的实现方式中,以网约车应用场景为例,任务执行端可以包括网约车、司机和司机终端。在车辆行驶过程中,通过网约车中的车载设备(例如导航仪等)或者司机终端实时上传的坐标信息,确定任务执行端当前的位置信息。
在一种可选的实现方式中,若用户通过用户终端网约车平台app,或者通过用户终端中的任一app中嵌入的网约车小程序创建任务(也即发单),可以在用户终端界面标注上车位置,以在发送创建任务请求时上传标注的上车位置,以使得网约车服务器确定用户位置。在其他情况下,例如老人不习惯使用智能手机或者不习惯使用app,用户可以通过用户终端与网约车平台建立通信连接,例如采用用户终端拨打固定的网约车电话,以口述对应的上车位置,网约车平台通过对用户输入的语音进行语音识别,以获取用户位置。可选的,采用asm方法对用户输入的语音进行识别,获取用户位置的文本表示信息。在其他可选的实现方式中,可以通过其他方式,例如获取用户和电话号码营业方的授权,基于建立通信连接的用户电话号码确定用户位置等。本实施例并不对用户位置的获取方式进行限制。
步骤s120,响应于任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息。在一种可选的方式中,预定条件为任务执行端的位置与用户位置之间的距离小于距离阈值。可选的,距离阈值基于具体应用场景确定,例如网约车领域,距离阈值范围可以为10-100m,应理解,本实施例并不对距离阈值的大小进行限制。
在一种可选的实现方式中,任务执行端的信息至少包括任务执行端的标志信息。可选的,以网约车应用场景为例,任务执行端的标志信息至少包括网约车的车牌号码、车辆品牌、车辆型号、外观颜色、以及司机信息中的至少一项。其中,司机信息可以包括司机年龄、或性别等。可选的,任务执行端的信息还包括任务执行端和用户当前的相对位置信息。例如,根据任务执行端当前的位置坐标和用户位置坐标确定任务执行端相对于用户的距离和方向。
步骤s130,对任务执行端的信息进行整合处理,获取对应的辅助识别文本。
在一种可选的实现方式中,以网约车应用领域为例,假设任务执行端的信息包括车牌号码(axxxx)、车辆品牌(b)、车辆型号(x)、外观颜色(黑色)、以及网约车和用户当前的相对位置信息(东南方50米处),将任务执行端的信息按照预定方式进行整合处理,可以获得对应的辅助识别文本“尊敬的乘客您好,您叫的车牌号为axxxx的黑色bx网约车已经快到您的上车位置,目前车辆在您东南方50米处,请注意来往车辆,安全乘车”。
在一种可选的实现方式中,在本实施例中,通过信息采集器获取任务执行端的信息,并按照具体应用场景中的语句规则将任务执行端的信息进行整合,获取对应的辅助识别文本。可选的,各具体应用场景具有对应的语句模板,例如网约车司乘会面场景中,信息采集器在获取到任务执行端的信息后,基于网约车司乘会面场景对应的语句模板,将任务执行端的信息进行整合,以获取对应的辅助识别文本。在其他可选的实现方式中,可以通过训练数据对信息采集器进行预先训练,将任务执行端的信息输入至训练好的信息采集器中进行处理,以获取信息采集器输出的辅助识别文本。其中,训练数据可以包括多条任务执行端的信息和对应的辅助识别文本。应理解,本实施例并不对任务执行端的整合处理方式进行限制,能够实现将其整合为容易被理解的语句的方式均可应用于本实施例中。
步骤s140,对辅助识别文本进行语音合成处理,获取对应的语音信息。在一种可选的实现方式中,将辅助识别文本输入至预先训练的语音合成模型中进行处理,获取对应的语音信息。可选的,本实施例的语音合成模型基于无监督训练获得。
在一种可选的实现方式中,本实施例的语音合成模型为基于无监督训练的tts(texttospeech)模型。可选的,语音合成模型为基于无监督训练的tts模型。可选的,在本实施例中,tts模型的无监督训练方法可以为mpc(maskedpredictivecoding,masked预测编码)。可选的,在tts模型的解码器中的pre-net模块采用mpc无监督训练以增强语音特征的表达能力,从而提高了语音合成的准确性。
图2是本发明实施例的语音合成模型的示意图。在一种可选的实现方式中,预先对辅助识别文本进行处理,获取服务识别文本的字符嵌入向量(characterembeddings)。可选的,基于bert模型或者其他模型对辅助识别文本进行处理,获取辅助识别文本对应的字符嵌入向量。在其他可选的实现方式中,可以基于对应的应用场景的语料库构造对应的字典,构造的字典中的每个字具有对应的标识,通过遍历构造的字典确定辅助识别文本中的各个字标识,并基于网络模型的词嵌入层(embedlayer)对辅助识别文本中的各个字标识进行处理,以获取辅助识别文本中的字符嵌入向量。应理解,本实施例并不对辅助识别文本的向量获取方法进行限制。
如图2所示,在本实施例中,tts模型2包括编码器21、基于注意力机制的解码器22和后处理网络23。
本实施例通过编码器21对辅助识别文本的字符嵌入向量v1进行编码处理,获取文本向量v3。其中,编码器21包括前网模块(pre-net)和cbhg模块212。其中,将获取的辅助识别文本的字符嵌入向量v1输入至pre-net模块211中进行非线性变换处理,获取文本向量v2,将文本向量v2输入至cbhg模块中进行处理,以通过提取序列的特征表达获取文本向量v3。可选的,pre-net模块可以采用dropout的瓶颈层(bottlenecklayer),以帮助收敛并提高泛化能力。cbhg通过非因果卷积、批标准化、残差连接以及最大池化处理,来提取序列的特征表达,提高了模型的泛化能力。由此,本实施例采用基于cbhg的编码器21可以减少错音的产生,提高语音合成的准确性。
在本实施例中,解码器22为基于注意力机制的解码器。如图3所示,解码器22是基于循环神经网络rnn的解码器。在解码器22中包括一个有状态的循环层在每个时间步骤上都产生依次注意点查询。其中,将辅助识别文本对应的初始输入帧222经pre-net模块223中进行处理后输入至attentionrnn模块进行处理,将编码器21输出的文本向量v3经注意力模块221处理后和attentionrnn模块的输出进行拼接后输入至解码器rnn(decoderrnn)中,获取解码后的数据。
在一种可选的实现方式中,解码器22中的pre-net模块223采用语音无监督预训练方法以提升语音特征的表达能力,以在解码器22的解码过程中合成更准确的上下文语音播报信息。可选的,pre-net模块223采用了mpc无监督训练(maskedpredictivecoding)方法以增强语音特征的表达。
图3是发明实施例中的pre-net模块的预训练过程的示意图。如图3所示,在pre-net模块223的训练过程中,将语音训练数据帧(x1~x8、x9~x16、xt-7~xt等)分别经过z1层、mask层、…、zt层处理后,再经过神经元33的前向传播和反向传播处理,以对pre-net模块进行预训练,获取训练后的pre-net模块。由此,本实施例中的pre-net模块的无监督预训练过程中,采用mask层对语音训练数据帧进行mask掩码操作,从而可以增强语音特征的表达能力。
后处理网络23用于解码器22的输出转化为可以被合成为波形的目标表达。本实施例采用cbhg模块231作为后处理网络预测对应的声谱图v4,以减少语音合成的错误,并提高模型的泛化能力。可选的,本实施例采用griffin-lim算法根据预测出的声谱图v4合成对应的语音波形。
由此,本实施例通过基于无监督训练的tts模型进行语音合成,以提高语音特征的表达能力,提高语音播报信息的准确性。
步骤s150,将语音信息发送至用户终端进行播报。在一种可选的实现方式中,根据用户通信信息建立与用户终端的通信连接,响应于与用户终端建立通信连接,将语音信息发送至用户终端进行播报。可选的,步骤s150具体可以为:将语音信息发送至用户终端,控制用户终端将语音信息播报预定次数或者持续播报预定时间。可选的,预定次数或预定时间可以为默认次数(例如3次)或默认时间(例如1分钟),也可以为用户预先设置的次数或时间,本实施例并不对此进行限制。进一步可选的,用户可以通过用户终端随时停止语音播报,例如在找到任务执行端后可以控制停止语音播报。
以网约车应用场景为例,网约车平台通过网约车app中的通信方式、或者任一app中嵌入的网约车小程序中的通信方式、或者拨打用户信息中的电话号码以建立与用户终端的通信连接,响应于用户终端接听通话,将上述语音信息发送至用户终端进行播报,以便于提醒用户相关信息,例如提醒用户车辆即将到达,并将车辆特征及其相对位置告知用户,以便于用户能够尽快找到对应的网约车,避免司机由于长时间未找到乘客取消订单的情况,从而提高司乘的体验感。
在本实施例中,获取包括任务执行端的位置和用户位置的任务信息,响应于任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息,对任务执行端的信息进行整合处理,获取对应的辅助识别文本,对辅助识别文本进行语音合成处理,获取对应的语音信息,将所述语音信息发送至用户终端进行播报,由此,可以在任务执行端接近用户时,通过语音方式告知用户任务执行端的信息,以提高任务执行端和用户的碰面效率,进而提高任务执行端和用户的体验感。
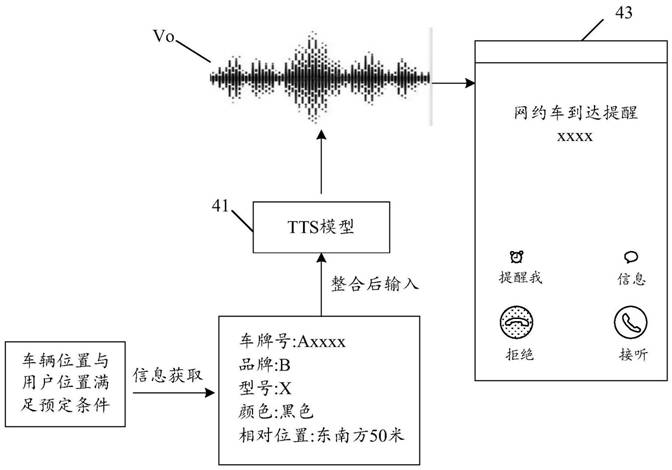
图4是本发明实施例的信息交互过程的示意图。以网约车应用场景为例,如图4所示,在用户通过网约车app、或app中嵌入的网约车小程序、或拨打固定网约车电话下单后,网约车平台获取用户标注或通过语音描述的用户位置,并实时获取接单的网约车的车辆位置信息,在网约车的车辆位置与用户位置满足预定条件,例如在网约车的车辆位置与用户位置之间的距离小于距离阈值时,获取车辆信息。车辆信息包括车牌号:axxxx、车辆品牌:b、车辆型号:x、颜色:黑色、以及网相对位置:东南方50米处。信息采集器将获取的车辆信息进行按照预定方式进行整合处理,可以获得对应的辅助识别文本“尊敬的乘客您好,您叫的车牌号为axxxx的黑色bx网约车已经快到您的上车位置,目前车辆在您东南方50米处,请注意来往车辆,安全乘车”。
如图4所示,将获取的辅助识别文本“尊敬的乘客您好,您叫的车牌号为axxxx的黑色bx网约车已经快到您的上车位置,目前车辆在您东南方50米处,请注意来往车辆,安全乘车”输入至tts模型41中进行语音合成,获取对应的语音信息vo。在获取对应的语音信息vo后,网约车平台通过网约车app中的通信方式、或者任一app中嵌入的网约车小程序中的通信方式、或者拨打用户信息中的电话号码以建立与用户终端的通信连接。其中,建立通信连接的过程中,用户终端界面如图4中的界面43所示。在用户选择接听通话后,网约车平台成功建立与用户终端的通信连接,将上述语音信息发送至用户终端进行播报,以便于提醒用户相关信息,例如提醒用户车辆即将到达,并将车辆特征及其相对位置告知用户,以便于用户能够尽快找到对应的网约车,避免司机由于长时间未找到乘客取消订单的情况,从而提高司乘的体验感。
在本实施例中,获取包括任务执行端的位置和用户位置的任务信息,响应于任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息,对任务执行端的信息进行整合处理,获取对应的辅助识别文本,对辅助识别文本进行语音合成处理,获取对应的语音信息,将所述语音信息发送至用户终端进行播报,由此,可以在任务执行端接近用户时,通过语音方式告知用户任务执行端的信息,以提高任务执行端和用户的碰面效率,进而提高任务执行端和用户的体验感。
图5是本发明实施例的信息交互装置的示意图。如图5所示,本发明实施例的信息交互装置5包括第一信息获取单元51、第二信息获取单元52、信息整合单元53、语音合成处理单元54以及发送单元55。
第一信息获取单元51被配置为获取任务信息,所述任务信息包括任务执行端的位置和用户位置。
在一种可选的实现方式中,第一信息获取单元51包括第一位置获取子单元和第二位置获取子单元。第一位置获取子单元被配置为获取所述任务执行端上传的坐标,以获得所述任务执行端的位置。第二位置获取子单元被配置为获取用户终端标注的位置或获取用户语音输入的位置,以获得所述用户位置。
第二信息获取单元52被配置为响应于所述任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息。可选的,所述预定条件为所述任务执行端的位置与所述用户位置之间的距离小于距离阈值。可选的,所述任务执行端的信息包括任务执行端的标志信息、以及所述任务执行端和所述用户之间的相对位置。
信息整合单元53被配置为对所述任务执行端的信息进行整合处理,获取对应的辅助识别文本。
语音合成处理单元54被配置为对所述辅助识别文本进行语音合成处理,获取对应的语音信息。在一种可选的实现方式中,所述语音合成处理单元进一步被配置为将所述辅助识别文本输入至预先训练的语音合成模型中进行处理,获取对应的语音信息。可选的,所述语音合成模型基于无监督训练获得。
发送单元55被配置为将所述语音信息发送至用户终端进行播报。在一种可选的实现方式中,发送单元55包括通信连接建立子单元和第一发送子单元。通信连接建立子单元被配置为根据所述用户通信信息建立与所述用户终端的通信连接。第一发送子单元被配置为响应于与所述用户终端建立通信连接,将所述语音信息发送至用户终端进行播报。
在一种可选的实现方式中,发送单元55包括第二发送子单元和控制子单元。第二发送子单元被配置为将所述语音信息发送至用户终端。控制子单元被配置为控制所述用户终端将所述语音信息播报预定次数或者持续播报预定时间。
在本实施例中,获取包括任务执行端的位置和用户位置的任务信息,响应于任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息,对任务执行端的信息进行整合处理,获取对应的辅助识别文本,对辅助识别文本进行语音合成处理,获取对应的语音信息,将所述语音信息发送至用户终端进行播报,由此,可以在任务执行端接近用户时,通过语音方式告知用户任务执行端的信息,以提高任务执行端和用户的碰面效率,进而提高任务执行端和用户的体验感。
图6是本发明实施例的电子设备的示意图。如图6所示,电子设备6为通用数据处理装置,其包括通用的计算机硬件结构,其至少包括处理器61和存储器62。处理器61和存储器62通过总线63连接。存储器62适于存储处理器61可执行的指令或程序。处理器61可以是独立的微处理器,也可以是一个或者多个微处理器集合。由此,处理器61通过执行存储器62所存储的指令,从而执行如上所述的本发明实施例的方法流程实现对于数据的处理和对于其它装置的控制。总线63将上述多个组件连接在一起,同时将上述组件连接到显示控制器64和显示装置以及输入/输出(i/o)装置65。输入/输出(i/o)装置65可以是鼠标、键盘、调制解调器、网络接口、触控输入装置、体感输入装置、打印机以及本领域公知的其他装置。典型地,输入/输出装置65通过输入/输出(i/o)控制器66与系统相连。
本领域的技术人员应明白,本申请的实施例可提供为方法、装置(设备)或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品。
本申请是参照根据本申请实施例的方法、装置(设备)和计算机程序产品的流程图来描述的。应理解可由计算机程序指令实现流程图中的每一流程。
这些计算机程序指令可以存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现流程图一个流程或多个流程中指定的功能。
也可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程中指定的功能的装置。
本发明的另一实施例涉及一种计算机程序产品,当该计算机程序产品在计算机上运行时,使得计算机执行上述部分或全部的方法实施例。
本发明的另一实施例涉及一种非易失性存储介质,用于存储计算机可读程序,所述计算机可读程序用于供计算机执行上述部分或全部的方法实施例。
即,本领域技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指定相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明实施例公开了ts1、一种信息交互方法,所述方法包括:
获取任务信息,所述任务信息包括任务执行端的位置和用户位置;
响应于所述任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息;
对所述任务执行端的信息进行整合处理,获取对应的辅助识别文本;
对所述辅助识别文本进行语音合成处理,获取对应的语音信息;
将所述语音信息发送至用户终端进行播报。
ts2、根据ts1所述的方法,所述预定条件为所述任务执行端的位置与所述用户位置之间的距离小于距离阈值。
ts3、根据ts1或ts2所述的方法,所述任务执行端的信息包括任务执行端的标志信息、以及所述任务执行端和所述用户之间的相对位置。
ts4、根据ts1所述的方法,获取任务信息包括:
获取所述任务执行端上传的坐标,以获得所述任务执行端的位置;
获取用户终端标注的位置或获取用户语音输入的位置,以获得所述用户位置。
ts5、根据ts1所述的方法,所述任务信息包括用户通信信息,将所述语音信息发送至用户终端进行播报包括:
根据所述用户通信信息建立与所述用户终端的通信连接;
响应于与所述用户终端建立通信连接,将所述语音信息发送至用户终端进行播报。
ts6、根据ts1所述的方法,对所述辅助识别文本进行语音合成处理,获取对应的语音信息包括:
将所述辅助识别文本输入至预先训练的语音合成模型中进行处理,获取对应的语音信息。
ts7、根据ts6所述的方法,所述语音合成模型基于无监督训练获得。
ts8、根据ts6或ts7所述的方法,所述语音合成模型为基于mpc无监督训练的tts模型。
ts9、根据ts1-ts8中任一项所述的方法,将所述语音信息发送至用户终端进行播报包括:
将所述语音信息发送至用户终端;
控制所述用户终端将所述语音信息播报预定次数或者持续播报预定时间。
本发明实施例公开了ts10、一种信息交互装置,所述装置包括:
第一信息获取单元,被配置为获取任务信息,所述任务信息包括任务执行端的位置和用户位置;
第二信息获取单元,被配置为响应于所述任务执行端的位置和用户位置满足预定条件,获取任务执行端的信息;
信息整合单元,被配置为对所述任务执行端的信息进行整合处理,获取对应的辅助识别文本;
语音合成处理单元,被配置为对所述辅助识别文本进行语音合成处理,获取对应的语音信息;
发送单元,被配置为将所述语音信息发送至用户终端进行播报。
ts11、根据ts10所述的装置,所述预定条件为所述任务执行端的位置与所述用户位置之间的距离小于距离阈值。
ts12、根据ts10或ts11所述的装置,所述任务执行端的信息包括任务执行端的标志信息、以及所述任务执行端和所述用户之间的相对位置。
ts13、根据ts10所述的装置,所述第一信息获取单元包括:
第一位置获取子单元,被配置为获取所述任务执行端上传的坐标,以获得所述任务执行端的位置;
第二位置获取子单元,被配置为获取用户终端标注的位置或获取用户语音输入的位置,以获得所述用户位置。
ts14、根据ts10所述的装置,所述发送单元包括:
通信连接建立子单元,被配置为根据所述用户通信信息建立与所述用户终端的通信连接;
第一发送子单元,被配置为响应于与所述用户终端建立通信连接,将所述语音信息发送至用户终端进行播报。
ts15、根据ts10所述的装置,所述语音合成处理单元进一步被配置为将所述辅助识别文本输入至预先训练的语音合成模型中进行处理,获取对应的语音信息。
ts16、根据ts17所述的装置,所述语音合成模型基于无监督训练获得。
ts17、根据ts15或ts16所述的装置,所述语音合成模型为基于mpc无监督训练的tts模型。
ts18、根据ts10-ts17中任一项所述的装置,所述发送单元包括:
第二发送子单元,被配置为将所述语音信息发送至用户终端;
控制子单元,被配置为控制所述用户终端将所述语音信息播报预定次数或者持续播报预定时间。
本发明实施例公开了ts19、一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现如ts1-ts9中任一项所述的方法。
本发明实施例公开了ts20、一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现如ts1-ts9任一项所述的方法。
本发明实施例公开了ts21、一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行如ts1-ts9中任一项所述的方法。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

